磁共振成像(MRI)影像心脏组织分割
前言
记录一下最近课设做的心脏组织分割的工作。
一、数据集
数据是分为三类(HCM) (DCM) (NOR) 的心脏MRI图像。每类十五组,一组8~10张图片。前两类是患有心脏疾病的,后一类是正常人的心脏。(其实在对心脏分割完后还有一个在分割基础上对三类心脏病分类的任务),但我做的效果实在是太差了,就不记录了。

原图像

分割后的图像(中间白色的是左心室(像素为0),白色外面一层是心肌(像素为85)
深灰色是右心室(像素为170),黑色是背景(255) 大概,记不清了)
其实数据是被我们老师处理过的,原数据是一种三维的切片,老师可能从里面挑出了一些图片作为数据。
二、模型
我是采用了一位俄罗斯程序猿写的一个分割的库的unet++模型。(基于pytorch的)
import segmentation_models_pytorch as smp
model = smp.UnetPlusPlus(
in_channels=1, #这里因为我们的数据是灰度图,所以是单通道。
classes=4, #输出的分割后的图像像素是四种,0,85,170,255.
#其实我感觉这本质上就是一种分类。
)
这个库的详情可以看看这个博客。
PyTorch图像分割模型——segmentation_models_pytorch库的使用
虽然讲的不全,但算一个启蒙。
三、数据处理
做了一些深度学习的作业,我觉得都数据的处理算是最有挑战的部分了。因为模型我现在也写不出来自己构建的模型,都是调用一些现成的模型,有些甚至都不明白模型的原理。在用了一些模型后,发现模型之间的区别不是很大,你数据处理的不好,特征不明显,用什么模型效果都不好。所以之后在做完cv方面一些常见的问题后,我也要试着去搭建一些自己的模型。
数据处理的思路:
1、标签的像素只有四种,首先就要将标签对应的四种像素设置成0,1,2,3。还要进行one-hot处理,因为标签有四类,最后模型产生的output格式是(c,4,h,w),不进行one-hot的话,标签是(c,1,h,w)这样无法计算loss。(交叉熵loss除外,因为交叉熵loss可以自动将标签转成one-hot形式的)
2、对于图片的话,他的像素分布是从0~255的,没有固定的几种。处理的话看下面。
self.image_transform = transforms.Compose([
transforms.CenterCrop(image_size),
#中心裁剪,因为要分割的心脏大部分在中心位置。
transforms.PILToTensor(),
#将PIL数据转化为tensor类型,不要用transforms.ToTensor(),
#因为这会将0~255的数值映射到0~1,虽然我不知道图片映射到0~1对计算会不会有什么不好的影响。
#但是在下面对标签处理时,标签映射到0·1,但我不知道,所以接下来依然是对标签中像素值为
#0,85,170,255分别赋值0,1,2,3。但标签中已经没有85,170,255了。所以他们还都是原值。
#接下来在训练时,发现训练出来的图片只有两种颜色,不是白就是黑。
#不知道是不是这四个像素之间差距过大导致的。毕竟他们很0,1,2,3之间的区别就是他们之间的差距过大。
transforms.Lambda(lambda y: y.to(dtype=torch.float32)),
#转成flaot32格式的,因为下面计算要这种格式,如果报错了,转成它提示成的格式就行。
])
self.label_transform = transforms.Compose([
transforms.CenterCrop(image_size),
transforms.PILToTensor(),
transforms.Lambda(lambda y: y.to(dtype=torch.int64).squeeze())
#.squeeze()处理是将多余的维或指定的维度压缩掉,正常来说这里不需要。
#因为标签被PIL读出来是两维的(h,w)不需要这处理。但如果读出来是三维的(h,w,1)就需要压缩了
])
对应的图片和数据处理完后就可以分割数据,设置模型参数进行训练了。
还有一个地方就是图片从模型出来是4通道的,我想把它显示出来看看,所以就需要把四通道的原图转回一通道灰度图,再显示。下面就是我写的转换函数。
#将预测后的四通道图片转化为一通道并还原像素 用来显示图片。
def onehot_to_mask(mask):
num0 = 0
num1 = 0
num2 = 0
num3 = 0
x = np.zeros([mask.shape[0],mask.shape[1]])
for i in range (mask.shape[0]):
for j in range (mask.shape[1]):
if (np.argmax(mask[i][j])==0):
x[i][j] = 0
num0 = num0 + 1
elif (np.argmax(mask[i][j])==1):
x[i][j] = 80
num1 = num1 + 1
elif (np.argmax(mask[i][j])==2):
x[i][j] = 170
num2 = num2 + 1
elif (np.argmax(mask[i][j])==3):
x[i][j] = 255
num3 = num3 + 1
# print("0:{},1:{},2:{},3:{}".format(num0,num1,num2,num3))
return x
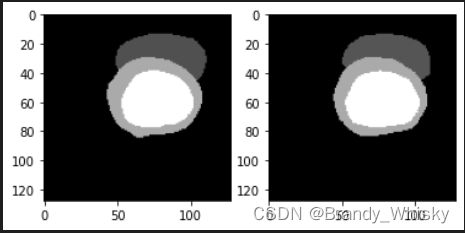
转回来的图片数据格式是numpy,我使用了plt来显示
#这里第几个是 先行后列,比如第二行第一列,就是第三个。
plt.figure(1) #设置显示1
plt.subplot(121) #一行两列,第一个
plt.imshow(outimage, cmap ='gray') #传上去
plt.subplot(122) #第二个
plt.imshow(target, cmap ='gray') #传上去
plt.show() #显示
四、划分数据
MyData = Train_Dataset(data_dir=r"./data")
train_size = int(0.8 * len(MyData)) #8:2划分
test_size = len(MyData) - train_size
train_data, test_data = torch.utils.data.random_split(MyData, [train_size, test_size])
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
这里主要就是,torch.utils.data.random_split()划分数据集。
五、评价函数:
我们使用的是macro-f1,我没调用现成的f1,因为不会用。
所以我自己写了一个,但好像不太对,就没贴上来,反正以后不同的任务还要写不同的f1函数。
总结
训练什么的和之前的任务差不多。没什么特点。
奥,感谢fsb同学的铺垫工作。
