spring boot集成canal实现数据库同步,且mysql主库宕机canal自动切换到从库
canal
简介:详情可查看:https://github.com/alibaba/canal
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
此处主要记录一次使用canal做数据库近实时备份的需求,以及主库宕机后自动连接从库继续备份方案。
方案:
canal监听mysql主库数据,产生update(insert、update、delete都算update)时,处理binary log日志,转成sql语句,发送给kafka生产者产生消息,各个子模块(需要同步数据的模块)作为消费者订阅kafka自行消费sql入库。如果mysql主库宕机,采用canal自带的自行切换到从库。
前提准备:
- mysql环境(至少四个库(主库、从库、子模块一、子模块二),可在同一服务器创建多个数据库模拟)
- zookeeper环境(kafka的前提)
- kafka环境
- canal环境
环境的安装这里不做介绍,太多了说不清。网上自行百度,可参考下方链接,这篇博客给的比较全面
https://www.cnblogs.com/throwable/p/12483983.html
canal本地配置可参考这篇博客:
https://blog.csdn.net/yehongzhi1994/article/details/107880162?spm=1001.2014.3001.5501
按照这两篇博客安装好环境,即可,代码可参考下方实例。
注:
安装这里需要注意的点,canal安装好后记得打开mysql 的binary log日志,以及查看文件名、偏移量
可能你查看自己数据库的binary log日志文件不止一个,我当时测试的时候填的是文件名最大的那个,
至于后续新增后他如何找到binary log文件的,猜测应该是记录在了logs/example/meta.log中了 example代表监控的实例
记录一下主要的几个点
- 修改 canal instance.properties配置文件,主要为了配置监听哪里的数据库以及用户、密码
- spring boot监听服务,部分书写监听工具类以及数据处理工具类,以及kafka的生产者
- 各个子模块只需要书写kafka的消费端即可
- 宕机自动切换这个后面单独拿出来说
canal服务
新建一个spring boot项目,模拟监控数据的服务以及生产消息。
整体结构如下
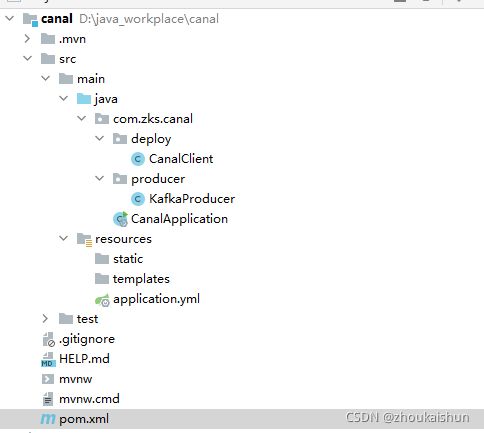
引入主要的两个依赖
<dependency>
<groupId>com.alibaba.ottergroupId>
<artifactId>canal.clientartifactId>
<version>1.1.4version>
dependency>
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
yml (这个如果kafka环境在本地可以直接复制,主要都是kafka的配置,canal的在类里面)
server:
port: 7111
spring:
kafka:
# kafka本地默认地址,低版本的端口可能是2181,新版本改为了9092
bootstrap-servers: 127.0.0.1:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
CanalClient.java 包含canal的连接,数据库的监听,日志数据的处理,sql的发送
package com.zks.canal.deploy;
import com.alibaba.fastjson.JSON;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
import com.zks.canal.producer.KafkaProducer;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
/**
* @Package: com.zks.canal.deploy
* @ClassName: CanalClient
* @Author: ZhouKaiShun
* @CreateTime: 2021/9/13 11:54
* @Description: canal客户端
*/
@Component
@Slf4j
public class CanalClient implements ApplicationRunner {
@Resource
private KafkaProducer kafkaProducer;
private final static int BATCH_SIZE = 1000;
/**
* sql队列
*/
private Queue<String> SQL_QUEUE = new ConcurrentLinkedQueue<>();
/**
* 订阅的数据库表
*/
public static String SUBSCRIBE_DB_TABLE = "kaishun.tb_user";
@Override
public void run(ApplicationArguments args) throws Exception {
log.info("启动canal服务,端口号:7111");
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
try {
//打开连接
connector.connect();
//订阅数据库表(全库全表:.*\\..* 指定库全表:库名\..* 单表:库名.表名 多规则组合使用:库名1\..*,库名2.表名1,库名3.表名2 (逗号分隔))
connector.subscribe(SUBSCRIBE_DB_TABLE);
//回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿
connector.rollback();
while (true) {
//尝试从master那边拉去数据batchSize条记录,有多少取多少
Message message = connector.getWithoutAck(BATCH_SIZE);
//获取批量ID
long batchId = message.getId();
//获取批量的数量
int size = message.getEntries().size();
//如果没有数据
if (batchId == -1 || size == 0) {
try {
//线程休眠2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
//处理数据为sql
dataHandle(message.getEntries());
}
/*设置队列sql语句执行最大值*/
if (SQL_QUEUE.size() >= 1) {
executeQueueSql();
}
//进行 batch id 的确认。确认之后,小于等于此 batchId 的 Message 都会被确认。
connector.ack(batchId);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
connector.disconnect();
}
System.out.println("连接canal end");
}
/**
* @description: 处理队列里sql
* @return:
* @author: ZhouKaiShun
* @time: 2021/9/15 10:35
*/
public void executeQueueSql() {
int size = SQL_QUEUE.size();
for (int i = 0; i < size; i++) {
String sql = SQL_QUEUE.poll();
this.execute(sql);
}
}
/**
* @description: 日志数据处理
* @return:
* @author: ZhouKaiShun
* @time: 2021/9/15 10:35
*/
private void dataHandle(List<Entry> entrys) throws
InvalidProtocolBufferException {
for (Entry entry : entrys) {
if (CanalEntry.EntryType.ROWDATA == entry.getEntryType()) {
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
CanalEntry.EventType eventType = rowChange.getEventType();
if (eventType == CanalEntry.EventType.DELETE) {
saveDeleteSql(entry);
} else if (eventType == CanalEntry.EventType.UPDATE) {
saveUpdateSql(entry);
} else if (eventType == CanalEntry.EventType.INSERT) {
saveInsertSql(entry);
}
}
}
}
/**
* @description: 处理update语句
* @return:
* @author: ZhouKaiShun
* @time: 2021/9/15 10:35
*/
private void saveUpdateSql(Entry entry) {
try {
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
for (CanalEntry.RowData rowData : rowDatasList) {
List<CanalEntry.Column> newColumnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("update " +
entry.getHeader().getTableName() + " set ");
for (int i = 0; i < newColumnList.size(); i++) {
sql.append(" " + newColumnList.get(i).getName()
+ " = '" + newColumnList.get(i).getValue() + "'");
if (i != newColumnList.size() - 1) {
sql.append(",");
}
}
sql.append(" where ");
List<CanalEntry.Column> oldColumnList = rowData.getBeforeColumnsList();
for (CanalEntry.Column column : oldColumnList) {
//暂时只支持单一主键
if (column.getIsKey()) {
sql.append(column.getName() + "= '" + column.getValue() + "'");
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* @description: 处理delete语句
* @return:
* @author: ZhouKaiShun
* @time: 2021/9/15 10:35
*/
private void saveDeleteSql(Entry entry) {
try {
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
for (CanalEntry.RowData rowData : rowDatasList) {
List<CanalEntry.Column> columnList = rowData.getBeforeColumnsList();
StringBuffer sql = new StringBuffer("delete from " +
entry.getHeader().getTableName() + " where ");
for (CanalEntry.Column column : columnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "= '" + column.getValue() + "'");
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* @description: 处理insert语句
* @return:
* @author: ZhouKaiShun
* @time: 2021/9/15 10:35
*/
private void saveInsertSql(Entry entry) {
try {
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
for (CanalEntry.RowData rowData : rowDatasList) {
List<CanalEntry.Column> columnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("insert into " +
entry.getHeader().getTableName() + " (");
for (int i = 0; i < columnList.size(); i++) {
sql.append(columnList.get(i).getName());
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(") VALUES (");
for (int i = 0; i < columnList.size(); i++) {
sql.append("'" + columnList.get(i).getValue() + "'");
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(")");
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* @description: 发送sql至kafka供订阅者消费
* @return:
* @author: ZhouKaiShun
* @time: 2021/9/15 10:35
*/
public void execute(String sql) {
kafkaProducer.send(sql);
System.out.println("SQL="+sql);
}
}
KafkaProducer.java Kafka消息发送
package com.zks.canal.producer;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
/**
* @Package: com.zks.kafka.producer
* @ClassName: KafkaProducer
* @Author: ZhouKaiShun
* @CreateTime: 2021/9/13 17:01
* @Description:
*/
@Component
@Slf4j
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
//自定义topic
public static final String TOPIC_TEST = "topic.test";
public void send(Object obj) {
String obj2String = JSONObject.toJSONString(obj);
log.info("准备发送消息为:{},监控到变动时间:{}", obj2String,System.currentTimeMillis());
//发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_TEST, obj);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable throwable) {
//发送失败的处理
log.info(TOPIC_TEST + " - 生产者 发送消息失败:" + throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> stringObjectSendResult) {
//成功的处理
log.info(TOPIC_TEST + " - 生产者 发送消息成功:" + stringObjectSendResult.toString());
log.info(TOPIC_TEST + " - 成功反馈时间:{}", System.currentTimeMillis());
}
});
}
}
到这里 canal监听以及kafka发送消息就完成了。后面新建两个项目去监听就可以了
新建一个项目 kafka,结构如下
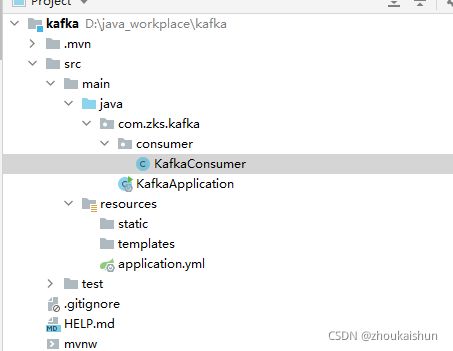
xml只需要引入kafka即可,yml同理
KafkaConsumer.java
package com.zks.kafka.consumer;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.Optional;
/**
* @Package: com.zks.kafka.consumer
* @ClassName: KafkaConsumer
* @Author: ZhouKaiShun
* @CreateTime: 2021/9/13 17:01
* @Description:
*/
@Component
@Slf4j
public class KafkaConsumer {
@Autowired
private JdbcTemplate jdbcTemplate;
//自定义topic
public static final String TOPIC_TEST = "topic.test";
public static final String TOPIC_GROUP1 = "topic.group1";
@KafkaListener(topics = TOPIC_TEST, groupId = TOPIC_GROUP1)
public void topic_test(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
log.info("项目kafka监听触发时间:{}",System.currentTimeMillis());
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
String sql = (String)message.get();
jdbcTemplate.update(sql);
log.info("项目kafka入库成功时间:{}",System.currentTimeMillis());
ack.acknowledge();
}
}
}
然后再建立一个项目模拟子模块,如kafka2,结构与这个一样
测试结构展示
启动zookeeper、Kafka、conal
启动canal项目,以及其他子模块
下图是我的一个测试demo,canal绑定的也就是这台数据库
canal监听处理并发送

kafka消费并入库

查看数据库,三台数据库表中都插入了数据,修改、删除同理
测试结果、结论
![]()
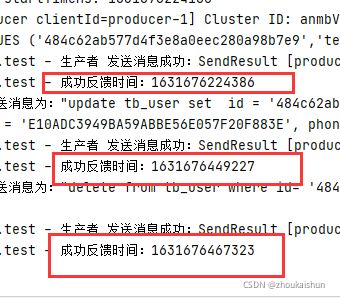
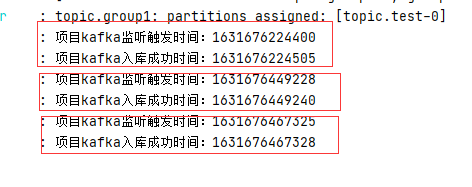
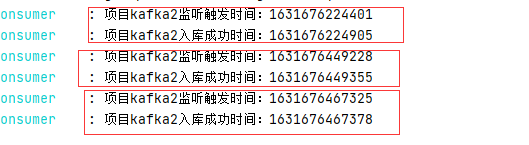
Canal结合kafka可以满足需求,新增、修改、删除的操作主库同步到各个子库的时间间隔本地测试基本在一秒内。其中修改、删除基本在100毫秒内或者更快。
注:
本次测试主库为阿里云服务器远程mysql;
子库一为我电脑window本地mysql;
子库二与主库在同一个mysql服务,不过是不同数据库而已。
Zk、kafka、canal均为本地环境。
开发量:除base服务中需要书写canal工具类以及日志转sql的工具类,子服务基本没有什么开发量。直接使用spring boot的JdbcTemple 服务直接执行sql即可。
关于canal监控的mysql宕机自动切换
参考资料:https://github.com/alibaba/canal/wiki/AdminGuide
主要步骤:
开启心跳检测以及失败后重连
修改canal安装目录下conf下的 canal.properties
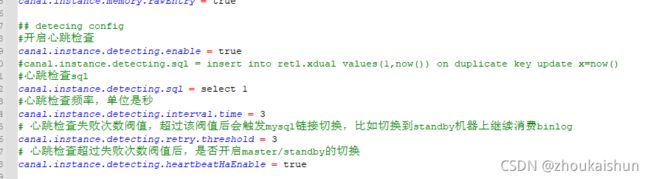
再修改实例的配置 instance.properties

注释解释的已经差不多了,下面就可以测试,我这里是首先绑定的一个远程mysql,当远程mysql宕机后,会经过心跳检测,以及断开重连,重新连接到我本地的数据库继续监听。
测试步骤:主库新增测试–>主库断开–>自动连接从库–>监听任务继续。
远程库新增数据:
canal监听处理、发送
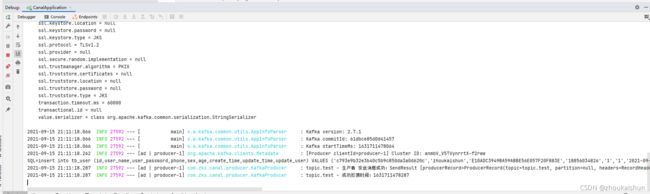
子模块1消费
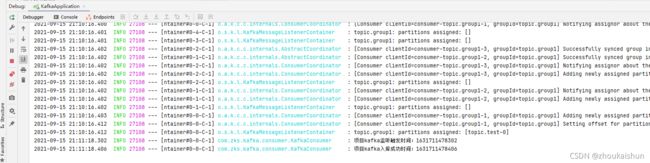
子模块2消费
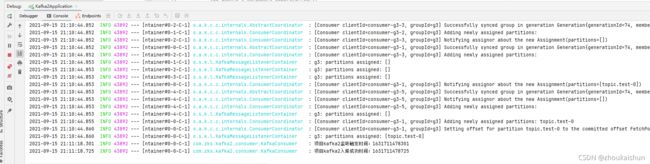
关闭远程mysql服务

查看canal实例日志自动重连、切换
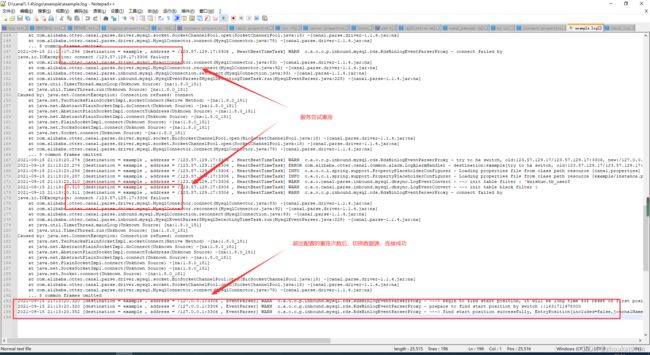
本地新增(相当于从库新增)
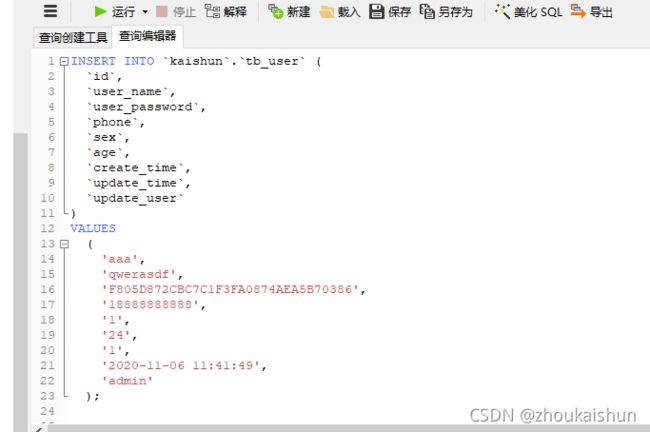
监听成功
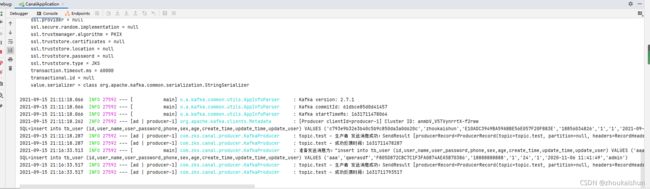
子模块消费成功
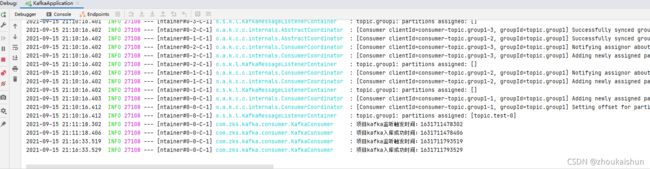
查看子模块数据库,两条都同步过来了
![]()