实战▍利用卷积神经网络(VGG19)实现火灾分类(附tensorflow代码及训练集)

作者| 帅虫哥 编辑|布袋熊
利用卷积神经网络(VGG19)实现火灾分类先看两组数据:
《新民周刊》:2018年6月到11月,美国加利福尼亚州的山火断断续续地烧了小半年,到入冬方才算彻底平息。这次山火造成35亿美元的经济损失,直接导致104人死亡,数万人被迫逃离家园,无论从规模还是损害上说,都是美国历史上最惨重的一次灾难了。
中新网济南3月24日电 (记者 梁犇)记者24日从山东省政府召开的全省消防工作会议上获悉,2018年该省发生火灾1.79万起,死亡29人,同比分别下降16.7%、25.6%,未发生较大以上亡人火灾;消防安全治理成效进一步提升,整改消除108.5万余处火灾隐患、176处重大隐患。
火灾无情人有情,除了建立有效的消防预警机制,强化公民消防意识,启动区域灭火与应急救援中心建设、加强消防设施建设等有效举措之外,技术又能为火灾做点什么呢?也许这篇干货慢慢的技术文章能给我们带来新的启示。
36大数据推荐 下面是正文
1. VGG介绍
1.1. VGG模型结构
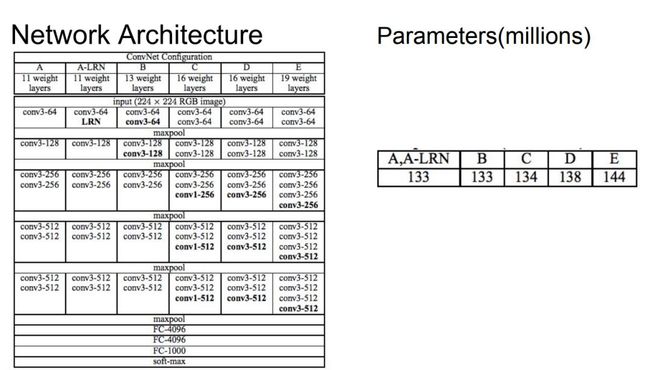
VGG网络是牛津大学Visual Geometry Group团队研发搭建,该项目的主要目的是证明增加网络深度能够在一定程度上提高网络的精度。VGG有5种模型,A-E,其中的E模型VGG19是参加ILSVRC 2014挑战赛使用的模型,并获得了ILSVRC定位第一名,和分类第二名的成绩。整个过程证明,通过把网络深度增加到16-19层确实能够提高网络性能。
VGG网络跟之前学习的LeNet网络和AlexNet网络有很多相似之处,以下搭建的VGG19模型也像上一次搭建的AlexNet一样,分成了5个大的卷积层,和3个大的全链层,不同的是,VGG的5个卷积层层数相应增加了;同时,为了减少网络训练参数的数量,整个卷积网络均使用3X3大小的卷积。
首先来看看原论文中VGG网络的5种模型结构。A-E模型均是由5个stage和3个全链层和一个softmax分类层组成,其中每个stege有一个max-pooling层和多个卷积层。每层的卷积核个数从首阶段的64个开始,每个阶段增长一倍,直到达到512个。
A:是最基本的模型,8个卷基层,3个全连接层,一共11层。
A-LRN:忽略
B:在A的基础上,在stage1和stage2基础上分别增加了1层3X3卷积层,一共13层。
C:在B的基础上,在stage3,stage4和stage5基础上分别增加了一层1X1的卷积层,一共16层。
D:在B的基础上,在stage3,stage4和stage5基础上分别增加了一层3X3的卷积层,一共16层。
E:在D的基础上,在stage3,stage4和stage5基础上分别增加了一层3X3的卷积层,一共19层。
模型D是就是经常说的VGG16网络,模型E则为VGG19网络。
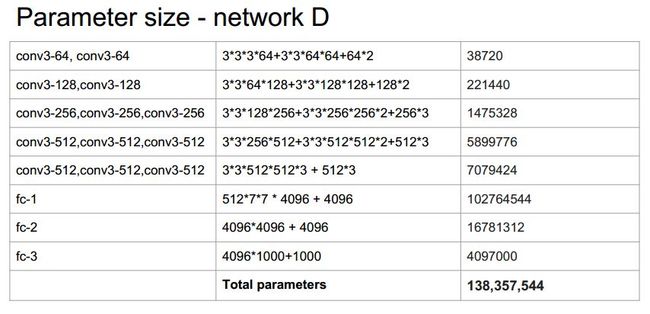
虽然VGG网络使用的均是3X3的卷积filter,极大的减小了参数个数,但和AlexNet比较起来,参数个数还是相当的多,以模型D为例,每一层的参数个数如下表所示,总参数个数为1.3亿左右,庞大的参数增加了训练的时间,下一章单搭建的VGG19模型仅在CPU上进行训练,单单一个epoch就要训练8小时以上!
尽管VGG19有那么多的参数,但是在训练过程中,作者发现VGG需要很少的迭代次数就开始收敛了,这是因为:
1、深度和小的filter尺寸起到了隐式的规则化作用
2、一些层的pre-initialisation
怎么做pre-initialisation呢?作者先训练最浅的网络A,然后把A的前4个卷积层和最后全链层的权值当作其他网络的初始值,未赋值的中间层通过随机初始化进行训练。这样避免了不好的权值初始值对于网络训练的影响,从而加快了收敛。
为什么在整个VGG网络中都用的是3X3大小的filter呢,VGG团队给出了下面的解释:
1、3 * 3是最小的能够捕获上下左右和中心概念的尺寸。
2、两个3 * 3的卷基层的有限感受野是5X5;三个3X3的感受野是7X7,可以替代大的filter尺寸。(感受野表示网络内部的不同位置的神经元对原图像的感受范围大小,神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着他可能蕴含更为全局、语义层次更高的特征;而值越小则表示其所包含的特征越趋向于局部和细节。)
3、多个3 * 3的卷基层比一个大尺寸filter卷基层有更多的非线性,使得判决函数更加具有判决性。
4、多个3 * 3的卷积层比一个大尺寸的filter有更少的参数,假设卷基层的输入和输出的特征图大小相同为C,那么三个3 * 3的卷积层参数个数为
![]()
整整比3 * 3的多了81%。
1.2. VGG19架构
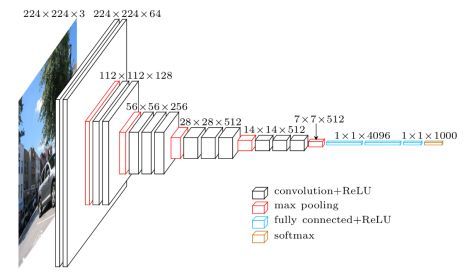
首先来看看论文中描述的VGG19的网络结构图,输入是一张224X224大小的RGB图片,在输入图片之前,仍然要对图片的每一个像素进行RGB数据的转换和提取。然后使用3X3大小的卷积核进行卷积,作者在论文中描述了使用3X3filter的意图:
“we use filters with a very small receptive field: 3 × 3 (which is the smallest size to capture the notion of left/right, up/down, center).”
即上面提到的“3X3是最小的能够捕获上下左右和中心概念的尺寸”。接着图片依次经过5个Stage和3层全连层的处理,一直到softmax输出分类。卷积核深度从64一直增长到512,更好的提取了图片的特征向量。
Stage1:
包含两个卷积层,一个池化层,每个卷积层和池化层的信息如下:

Stage2:
包含两个卷积层,一个池化层,每个卷积层和池化层的信息如下:
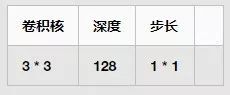
Stage3:
包含四个卷积层,一个池化层,每个卷积层和池化层的信息如下:

Stage4:
包含四个卷积层,一个池化层,每个卷积层和池化层的信息如下:
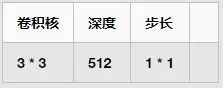
Stage5:
包含四个卷积层,一个池化层,每个卷积层和池化层的信息如下:
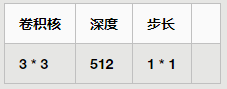
池化层
整个网络包含5个池化层,分别位于每一个Stage的后面,每个池化层的尺寸均一样,如下:

对于其他的隐藏层,作者在论文中做了如下阐述:
“All hidden layers are equipped with the rectification (ReLU (Krizhevsky et al., 2012)) non-linearity.We note that none of our networks (except for one) contain Local Response Normalisation(LRN) normalisation (Krizhevsky et al., 2012): as will be shown in Sect. 4, such normalisation does not improve the performance on the ILSVRC dataset, but leads to increased memory consumption and computation time. ”
整个网络不包含LRN,因为LRN会占用内存和增加计算时间。接着经过3个全链层的处理,由Softmax输出1000个类别的分类结果。
VGG团队早已用Tensorflow搭建好了VGG16和VGG19网络,在使用他们的网络前,你需要下载已经训练好的参数文件vgg19.npy,下载地址为:
https://mega.nz/#!xZ8glS6J!MAnE91ND_WyfZ_8mvkuSa2YcA7q-1ehfSm-Q1fxOvvs 。
原版的VGG16/19模型代码在
https://github.com/machrisaa/tensorflow-vgg (该模型中提到的weights文件已不可用),
我们根据该模型代码对VGG19网络做了一些微调以适应自己的训练需求,同时也像上一篇的AlexNet一样,增加了精调训练代码,后面会有介绍。
使用Tensorflow来搭建一个完整的VGG19网络,包含我修改过的整整用了160行代码,如下附上一部分代码,该网络也是VGG团队已经训练好了的,你可以拿来直接进行图片识别和分类,但是如果你有其他的图片识别需求,你需要用自己的训练集来训练一次以获得想要的结果,并存储好自己的权重文件。
我们在原版的基础上做了一些改动,增加了入参num_class,该参数代表分类个数,如果你有100个种类的图片需要训练,这个值必须设置成100,以此类推。
(此处略去代码)
使用Tenforflow来搭建网络确实代码量比较大,网上有使用Keras来搭建的,并且可以不用训练,直接用于图片识别,代码量少,使用简单方便,感兴趣的同学可以去
https://gist.github.com/baraldilorenzo/07d7802847aaad0a35d3#file-vgg-16_keras-py-L24
看看,由于Keras已经发布了新版本,这个github上的代码存在一些问题,需要做一些修改,附上我自己修改好的代码,仅有70多行就可以进行使用了。之前看了两天Keras的官方document,在使用fit方法训练的时候,入参就有epoch的设置,感觉不需要用到for循环,同时,不需要自定义Optimizer和acuuracy,只需指定名字就可以了,简直方便快捷,但是对于如何把每一个epoch得到的accuracy和loss用类似tensorboard视图的方式显示出来我就不太清楚了,如有知道的同学,请不吝赐教。
(此处略去代码)
3. 训练网络
虽然使用训练好的网络和网络权值可以直接进行分类识别应用,但是本着学习研究的精神,我们需要知道如何训练数据以及测试和验证网络模型。
目前,我们有项识别火灾的任务(该项目的数据集来自一位挪威教授,他的github地址为:
https://github.com/UIA-CAIR/Fire-Detection-Image-Dataset ,他使用的是改进过的VGG16网络),需要使用VGG19进行训练,而通常模型训练需要的正样本和负样本数量要相等,并且数据集越多越好,但在本次训练中,所有图片均是作者从网络抓取而来,且训练集中的fire的图片和non-fire图片是不相等的,分别为223张和445张(原图没有那么多,我们自己增加了一些火灾图片),测试集中的fire图片和non-fire的图片则相等,均为50张。
对于如何获取batch数据,在之前的AlexNet中使用的是数据迭代器,在本次训练中我们使用Tensorflow的队列来自动获取每个batch的数据,使用队列可以把图片及对应的标签准确的取出来,同时还自动打乱顺序,非常好使用。由于使用了
tf.train.slice_input_producer建立了文件队列,因此一定要记住,在训练图片的时候需要运行
tf.train.start_queue_runners(sess=sess)
这样数据才会真正的填充进队列,否则程序将会挂起。
程序代码如下:
import tensorflow as tfVGG_MEAN = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32)class ImageDataGenerator(object):def __init__(self, images, labels, batch_size, num_classes):self.filenames = imagesself.labels = labelsself.batch_size = batch_sizeself.num_class = num_classesself.image_batch, self.label_batch = self.image_decode()def image_decode(self):# 建立文件队列,把图片和对应的实际标签放入队列中#注:在没有运行tf.train.start_queue_runners(sess=sess)之前,数据实际上是没有放入队列中的file_queue = tf.train.slice_input_producer([self.filenames, self.labels])# 把图片数据转化为三维BGR矩阵image_content = tf.read_file(file_queue[0])image_data = tf.image.decode_jpeg(image_content, channels=3)image = tf.image.resize_images(image_data, [224, 224])img_centered = tf.subtract(image, VGG_MEAN)img_bgr = img_centered[:, :, ::-1]labels = tf.one_hot(file_queue[1],self.num_class, dtype=tf.uint8)# 分batch从文件队列中读取数据image_batch, label_batch = tf.train.shuffle_batch([img_bgr, labels],batch_size=self.batch_size,capacity=2000,min_after_dequeue=1000)
在精调中,代码和之前的AlexNet差不多,只是去掉了自定义的数据迭代器。整个VGG19网络一共训练100个epochs,每个epoch有100个迭代,同时使用交叉熵和梯度下降算法精调VGG19网络的最后三个全链层fc6,fc7,fc8。衡量网络性能的精确度(Precision)、召回率(Recall)及F1值我们没有使用,简单使用了准确率这一指标。值得注意的是,在训练获取数据之前,一定要运行
tf.train.start_queue_runners(sess=sess)这样才能保证数据真实的填充入文件队列。通过使用Tensorflow的队列存取数据,整个精调代码比AlexNet要精简一些,部分代码如下:
with tf.Session() as sess:sess.run(tf.global_variables_initializer())# 运行队列tf.train.start_queue_runners(sess=sess)# 把模型图加入TensorBoardwriter.add_graph(sess.graph)# 总共训练100代for epoch in range(num_epochs):print("{} Epoch number: {} start".format(datetime.now(), epoch + 1))# 开始训练每一代for step in range(num_iter):img_batch = sess.run(training.image_batch)label_batch = sess.run(training.label_batch)sess.run(train_op, feed_dict={x: img_batch, y: label_batch})
在测试网络性能的时候,以前采用的准确率(Accuracy)是不太准备的,首先看准确率计算公式(如下),这个指标有很大的缺陷,在正负样本不平衡的情况下,比如,负样本量很大,即使大部分正样本预测正确,所占的比例也是比较少的。所以,在统计学中常常使用精确率(Precision)、召回率(Recall)和两者的调和平均F1值来衡量一个网络的性能。
准确率(Accuracy)的计算公式为:
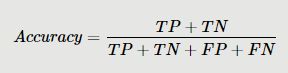
其中:
True Positive(真正, TP):将正类预测为正类数.
True Negative(真负 , TN):将负类预测为负类数.
False Positive(假正, FP):将负类预测为正类数 →→ 误报 (Type I error).
False Negative(假负 , FN):将正类预测为负类数 →→ 漏报 (Type II error).
精确率(Precision)的计算公式为:
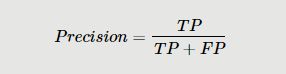
召回率(Recall)的计算公式为:两者的调和平均F1:
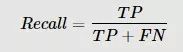
两者的调和平均F1:
![]()
精确率(Precision)是针对预测结果而言的,它表示的是预测为正的样本中有多少是对的。有两种值,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP)。精确率又叫查准率。
召回率(Recall)是针对原来的样本而言,它表示的是样本中的正例有多少被预测正确了。也有两种值,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。召回率又称查全率。
F1为精确率和召回率的调和平均,当两者值较高时,F1值也较高。
测试网络精确度代码如下:
Start testing".format(datetime.now()))tp = tn = fn = fp = 0for _ in range(num_iter):img_batch = sess.run(testing.image_batch)label_batch = sess.run(testing.label_batch)softmax_prediction = sess.run(score, feed_dict={x: img_batch, y: label_batch})prediction_label = sess.run(tf.argmax(softmax_prediction, 1))actual_label = sess.run(tf.argmax(label_batch, 1))for i in range(len(prediction_label)):if prediction_label[i] == actual_label[i] == 1:tp += 1elif prediction_label[i] == actual_label[i] == 0:tn += 1elif prediction_label[i] == 1 and actual_label[i] == 0:fp += 1elif prediction_label[i] == 0 and actual_label[i] == 1:fn += 1precision = tp / (tp + fp)recall = tp / (tp + fn)f1 = (2 * tp) / (2 * tp + fp + fn) # f1为精确率precision和召回率recall的调和平均Testing Precision = {:.4f}".format(datetime.now(), precision))Testing Recall = {:.4f}".format(datetime.now(), recall))Testing F1 = {:.4f}".format(datetime.now(), f1))
经过一天的训练和测试,网络精确度(Precision)为60%左右,召回率(Recall)为95%,F1值为72.6%。由于图片较少,因此性能指标不是很理想,后续我们接着改进。
下面开始验证网络。首先在网络上任选几张图片,然后编写代码如下,
class_name = ['not fire', 'fire']def test_image(path_image, num_class):img_string = tf.read_file(path_image)img_decoded = tf.image.decode_png(img_string, channels=3)img_resized = tf.image.resize_images(img_decoded, [224, 224])img_resized = tf.reshape(img_resized, shape=[1, 224, 224, 3])model = Vgg19(bgr_image=img_resized, num_class=num_class, vgg19_npy_path='./vgg19.npy')score = model.fc8prediction = tf.argmax(score, 1)saver = tf.train.Saver()with tf.Session() as sess:sess.run(tf.global_variables_initializer())"./tmp/checkpoints/model_epoch50.ckpt")plt.imshow(img_decoded.eval()):" + class_name[sess.run(prediction)[0]])plt.show()2)
对于大多数真正的火灾图片,该网络还是能够识别出来,但是一些夕阳图片或者暖色的灯光就不容易识别。以下是一些识别图片结果:








参考文献
《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》Karen Simonyan& Andrew Zisserman
《Deep Convolutional Neural Networks for Fire Detection in Images》Jivitesh Sharma(B), Ole-Christoffer Granmo, Morten Goodwin, and Jahn Thomas Fidje
https://github.com/UIA-CAIR/Fire-Detection-Image-Dataset
https://github.com/machrisaa/tensorflow-vgg
https://gist.github.com/baraldilorenzo/07d7802847aaad0a35d3#file-vgg-16_keras-py-L24
以上内容有任何错误或不准确的地方请大家指正,不喜勿喷!
源码地址 https://github.com/stephen-v/tensorflow_vgg_classify
实战案例
▍Python机器学习实践:随机森林算法训练及调参 (附代码)
▍自己动手构建一个人脸识别模型----看她是否认识您
▍Python实战 爬取万条票房数据分析2019春节档电影状况
▍教你用Python撩妹:微信推送天气早报/睡前故事/精美图片
▍用Python的Sklearn库预测电信客户流失分析
▍Python爬虫基础:验证码的爬取和识别详解
▍Python爬取3w条游戏评分数据,看看哪款最热门?
▍用大数据扒一扒蔡徐坤的真假流量粉 |
▍用Python爬取数据来分析 2019年金三银四 Python就业行情
▍一个完整的电信客服分析平台大数据项目:架构、实现、数据
▍如何使用 Deepfakes 给主播换脸?教程来了

END
“爱数据,爱技术,爱AI,36大数据社群(大数据交流、AI技术学习群、机器人研究、AI+行业、企业合作群)火热招募中,对大数据和AI感兴趣的小伙伴们。增加AI小秘书微信号:a769996688,说明身份即可加入。

欢迎投稿,投稿/合作:[email protected]
如果您觉得文章不错,那就分享到朋友圈~