DL基本知识(四)权重矩阵初始化
概述
权重矩阵初始化的好坏能够直接决定深度学习模型收敛后的效果,因而这里专门开一个专题来讲述这部分内容,后文会讲述几个比较有代表性的权重矩阵初始化的方法。
全0初始化
如果每一层的权重都是0,则只有最后一层的参数可以得到更新,其他层的参数一直为0,具体推导过程如下:
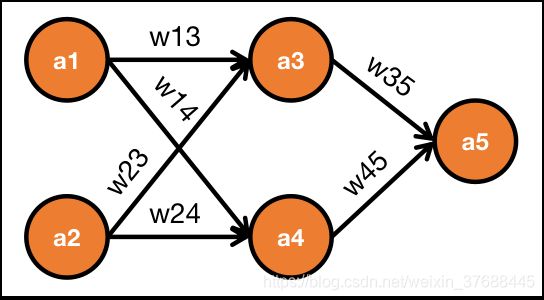
{ a 3 = f ( w 13 a 1 + w 23 a 2 ) a 4 = f ( w 14 a 1 + w 24 a 2 ) a 5 = w 35 a 3 + w 45 a 4 \left\{\begin{matrix} a_3 = f(w_{13}a_1+w_{23}a_2)\\ a_4 = f(w_{14}a_1+w_{24}a_2)\\ a_5 = w_{35}a_3+w_{45}a_4 \end{matrix}\right. ⎩⎨⎧a3=f(w13a1+w23a2)a4=f(w14a1+w24a2)a5=w35a3+w45a4
求导过程为:
{ ∂ L ∂ w 35 = ∂ L ∂ a 5 ∂ a 5 ∂ w 35 = ∂ L ∂ a 5 a 3 ≠ 0 ∂ L ∂ a 3 = ∂ L ∂ a 5 ∂ a 5 ∂ z 5 ∂ z 5 ∂ a 3 = ∂ L ∂ a 5 ∂ a 5 ∂ z 5 w 35 = 0 ∂ L ∂ w 13 = ∂ L ∂ a 3 ∂ a 3 ∂ z 3 ∂ z 3 ∂ w 13 = 0 . . . \left\{\begin{matrix} \frac{\partial L}{\partial w_{35}}=\frac{\partial L}{\partial a_{5}}\frac{\partial a_5}{\partial w_{35}}=\frac{\partial L}{\partial a_{5}} a_3\neq 0\\ \frac{\partial L}{\partial a_{3}}=\frac{\partial L}{\partial a_{5}}\frac{\partial a_5}{\partial z_{5}}\frac{\partial z_5}{\partial a_{3}}=\frac{\partial L}{\partial a_{5}} \frac{\partial a_5}{\partial z_{5}}w_{35} =0\\ \frac{\partial L}{\partial w_{13}}=\frac{\partial L}{\partial a_{3}}\frac{\partial a_3}{\partial z_{3}}\frac{\partial z_3}{\partial w_{13}}=0\\ ... \end{matrix}\right. ⎩⎪⎪⎨⎪⎪⎧∂w35∂L=∂a5∂L∂w35∂a5=∂a5∂La3=0∂a3∂L=∂a5∂L∂z5∂a5∂a3∂z5=∂a5∂L∂z5∂a5w35=0∂w13∂L=∂a3∂L∂z3∂a3∂w13∂z3=0...
可以看出除了最后一层的权重矩阵的梯度不为0之外,其他权重矩阵的梯度都为0,因而没有办法更新,因而权重矩阵全0初始化不行。
xaiver初始化
为了解决过饱和已经神经元死亡的问题,引入xavier初始化来解决问题,假设维度为 n n n, 而且输入x和权重矩阵W相对独立,如果把W初始化为如下所示,这里 W i , j W_{i, j} Wi,j的方差为 1 12 ( 2 n ) 2 = 1 3 n \frac{1}{12}(\frac{2}{\sqrt{n}})^2 = \frac{1}{3n} 121(n2)2=3n1。
W i , j ∼ [ − 1 n , 1 n ] W_{i,j} \sim [-\frac{1}{\sqrt{n}}, \frac{1}{\sqrt{n}}] Wi,j∼[−n1,n1]
因为W和x相对独立,因而
{ V a r [ W i , k ∗ x i ] = V a r [ W i , k ] ∗ V a r [ x i ] V a r [ ∑ i = 0 n W i , k ∗ x i ] = ∑ i = 0 n V a r [ W i , k ∗ x i ] \left\{\begin{matrix} Var[{W_{i,k}}* x_i ] = Var[{W_{i,k}}] * Var[x_i]\\ Var[\sum_{i=0}^n W_{i, k} * x_i]= \sum_{i=0}^n Var[W_{i, k} * x_i] \end{matrix}\right. {Var[Wi,k∗xi]=Var[Wi,k]∗Var[xi]Var[∑i=0nWi,k∗xi]=∑i=0nVar[Wi,k∗xi]
矩阵相乘输出数据 z k z_k zk以及其方差如下,
{ z k = ∑ i = 0 n W i , k ∗ x i V a r [ z k ] = ∑ i = 0 n V a r [ W i , k ∗ x i ] \left\{\begin{matrix} z_k = \sum_{i=0}^n W_{i, k} * x_i\\ Var[z_k] = \sum_{i=0}^n Var[W_{i, k} * x_i] \end{matrix}\right. {zk=∑i=0nWi,k∗xiVar[zk]=∑i=0nVar[Wi,k∗xi]
假设x的方差为1, 因而z的方差为
V a r [ z k ] = ∑ i = 0 n V a r [ W i , k ] ∗ V a r [ x i ] = ∑ i = 0 n 1 3 n = 1 3 Var[z_k] = \sum_{i=0}^n Var[W_{i, k}]* Var[ x_i] = \sum_{i=0}^n \frac{1}{3n} = \frac{1}{3} Var[zk]=i=0∑nVar[Wi,k]∗Var[xi]=i=0∑n3n1=31
可以看出,输入到激活函数之前的数据都是0均值恒等方差的,数据不会畸形,而且相对于sigmoid这样还能够使梯度不饱和。
截断正太分布初始化
从截断的正态分布中输出随机值,如果生成的值大于平均值2个标准偏差的值则丢弃重新选择。因为在 [ μ − 3 σ , μ + 3 σ ] [\mu-3\sigma, \mu+3\sigma] [μ−3σ,μ+3σ]之间取值的范围太广,因而限制范围到 [ μ − 2 σ , μ + 2 σ ] [\mu-2\sigma, \mu+2\sigma] [μ−2σ,μ+2σ]之间。
小随机数初始化
权值初始值接近0但又不等于0,这样就可以通过把权重赋值为0周围的一个随机数。