文章目录
-
第2章 端到端的机器学习项目
1 使用真实数据( 加州房价预测 )
1.1 流行的各个领域的开放数据集存储库
2 观察大局
2.1 框架问题
2.2 选择性能指标
2.3 检查假设
3 获取数据
3.1 创建工作区
3.2 下载数据
3.3 快速查看数据结构
3.4 创建测试集 ( 经常被忽视但至关重要 )
4 从数据探索和可视化中获得洞见 EDA(pandas、matplotlib、seaborn)
4.1 将地理数据可视化
4.2 寻找相关性
4.3 试验不同属性的组合
5 机器学习算法的数据准备 ( 数据清洗、特征工程)
5.1 数据清理
5.1.1 【插曲1】 数据的拼接和合并
5.1.2 【插曲2】 sk的几个常用函数
5.2 处理文本和分类属性
5.3 自定义转换器
5.4 特征缩放
5.5 转换流水线
6 选择和训练模型(模型选择、训练和交叉验证)
6.1培训和评估训练集
6.1 使用交叉验证来更好地进行评估
7 模型微调(调参)
8 网格搜索
8.1 随机搜索
8.2 集成方法
8.3 分析最佳模型及其错误
8.4 通过测试集评估系统
9 启动、监控和维护系统
10 试试看和练习
11 那些年,我们踩过的坑。。。。。
12 练习题
1. 使用真实数据 ( 加州房价预测 )
1.1 流行的各个领域的开放数据集存储库:
① UC Irvine ML Repository
② Kaggle datasets
③ Amazon AWS datasets
1.2 元门户站点
①http://dataportals.org/
② http://opendatamonitor.eu/
③ http://quandl.com/
1.3 其他一些列出许多流行的开放数据存储库的页面
① Wiki list of ML datasets
② Quora.com question
③ Datasets subreddit
2. 观察大局

Pipeline: 一个序列的数据处理组件称为一个数据流水线。
2.1 框架问题
① 首先要问老板,我们的业务目标是什么? 因为建立模型本身可能不是最终问题。【审题很重要】
② 如果有现成的解决方案,可以参照。【站在巨人的肩膀上】
③ 如果数据量巨大,还会用到MapReduce技术。
2.2 选择性能指标
我们是预测房屋价格,典型的回归问题。回归常用的性能指标:RMSE(均方根误差)、MAE(平均绝对误差)。
RMSE和MAE如何选择?当异常值非常少时,RMSE更加优异。因为RMSE对异常值非常敏感,为什么?很好理解,平方比绝对值使误差变更大。
2.3 检查假设
搞清楚上下游系统到底是需要什么数据,比如,下游系统需要输出价格,那就是回归任务,需要输出类别,就是分类任务。所以要沟通清楚后再着手开发,不要盲目。
3. 获取数据
3.1 创建工作区
关于python的系统环境,我用的是anaconda,而且之前写python爬虫的时候也介绍过隔离环境如何去安装。所以这里就不过多介绍了。
3.2 下载数据
import os
import tarfile
from six.moves import urllib
downLoad_root = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
housing_path = "datasets/housing"
housing_url = downLoad_root + housing_path + "/housing.tgz"
def fetch_housing_data(housing_url = housing_url,housing_path = housing_path):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
print("======= housing_url ================",housing_url)
tgz_path = os.path.join(housing_path,"housing.tgz")
print("======= tgz_path ================",tgz_path)
urllib.request.urlretrieve(housing_url,tgz_path)
housing_taz = tarfile.open(tgz_path)
housing_taz.extractall(path=housing_path)
housing_taz.close()
def load_data(housing_path = housing_path):
csv_path = os.path.join(housing_path,"housing.csv")
print("======= csv_path ================",csv_path)
return pd.read_csv(csv_path)
3.3 快速查看数据结构
data.shape
data.describe()
data.info()
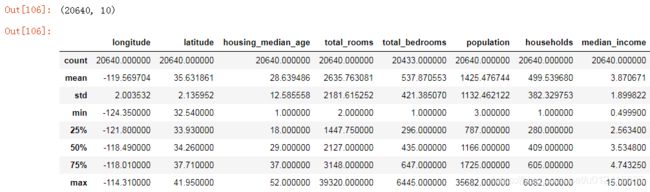
describe依次展示的是:总数、均值、标准差、最小值、25%分位数、50%分位数、75%分位数、最大值。
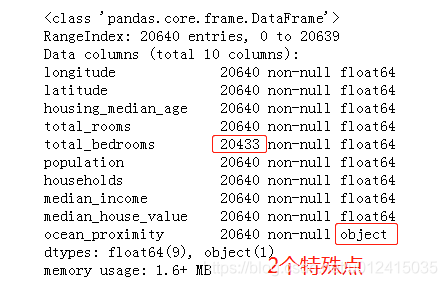
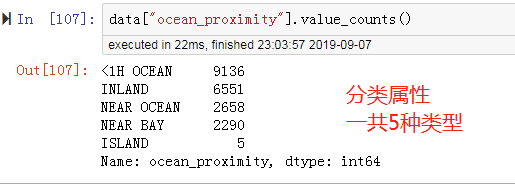
从数据看出,total_bedrooms有缺失值,ocean_proximity是对象类型,可能是分类属性。
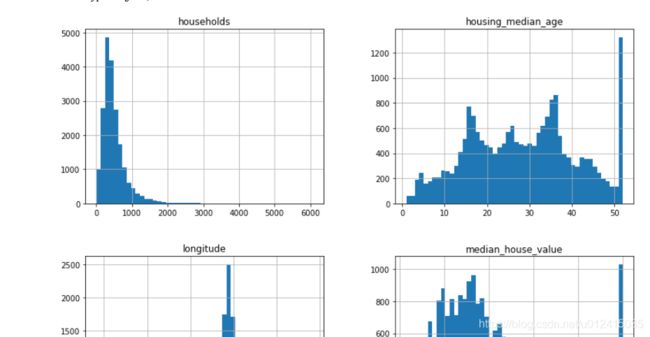
另一种比较直观的了解数据的方式:直方图。反应的是落在某一范围内(横轴)的实例数量(纵轴)。
data.hist(bins=50,figsize=(20,15))
3.4 创建测试集(经常被忽视但至关重要)
① 可以直接用sklearn提供的切分方法,但是在这之前要考虑数据量,数据量大的话用随机抽样的方法,数据量小的话最好用分层抽样,否则会造成明显的抽样偏差。
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1,test_size=0.2,random_state=42)
for train_index,test_index in split.split(data,data["income_cat"]):
strat_train_set = data.loc[train_index]
strat_test_set = data.loc[test_index]
咦,data[“income_cat”]哪里来的?这是因为我们想让测试集代表整个数据集中各种不同类型的收入而加的新特征—收入类别。处理如下:
data["income_cat"] = np.ceil(data["median_income"] / 1.5)
data["income_cat"].where(data["income_cat"] < 5,5.0,inplace = True)
data["income_cat"].value_counts()
data["income_cat"].hist()
注意:data[“income_cat”]就是为了切分后的数据分布更接近整个数据集的数据分布,所以,切分完后还要删掉。
for d in (strat_train_set,strat_test_set):
d.drop(["income_cat"],axis = 1,inplace=True)
至此,我们就完成了数据集的切分,得到了分层抽样后的测试集。分层抽样的测试集中的比例分布更接近于完整数据集中的分布。
4. 从数据探索和可视化中获得洞见 EDA(pandas、matplotlib、seaborn)
4.1 将地理数据可视化
h.plot(kind="scatter",x="longitude",y="latitude",alpha=0.4,
s=h["population"]/100,label="population",
c="median_house_value",cmap=plt.get_cmap("jet"),colorbar=True,
figsize=(15,10),fontsize=20)
plt.legend()

4.2 寻找相关性
数据集不大的话,可以直接用corr()方法计算出每对属性之间的相关系数,即皮尔逊相关系数。
corr_matrix = h.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)

从上面可以分析出,收入越高,房价越高。越往北走,房价越低。(常识:北纬为正,东经为正,南纬和西经为负)
各种数据集的标准相关系数:
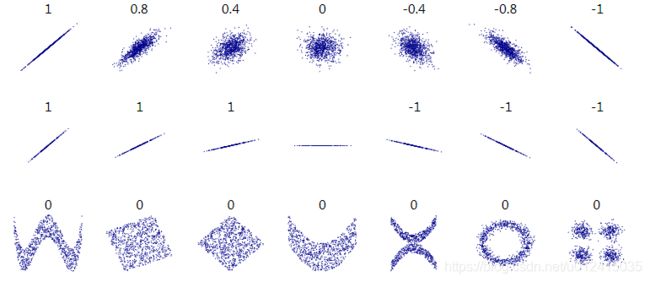
还有一种方法可以检测属性之间的相关性,就是使用pandas的scatter_matrix。
from pandas.tools.plotting import scatter_matrix
attr = ["median_house_value","median_income","total_rooms","housing_median_age"]
scatter_matrix(h[attr],figsize=(12,8))
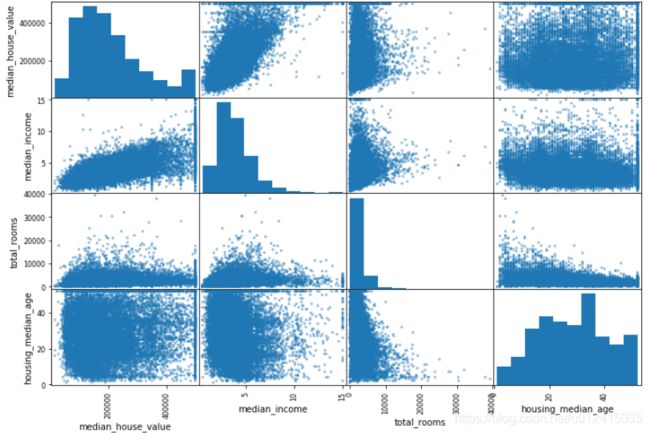
最有潜力预测房价中位数的特征是收入中位数,所以我们放大其散点图:
h.plot(kind="scatter",x="median_income",y="median_house_value",alpha=0.1)

分析上图:
① 相关性很强。
② 50万和35附近有一条水平线,可能数据已经经过了处理。
4.3 试验不同属性的组合
其实这属于是特征工程的部分。尝试不同的组合特征,可以简单的使用四则运算来实验。
思考:其实我认为这块东西要跟实际业务紧密相连,比如房价,在我们生活中很普遍,从购房者的角度来看,希望买到什么样的房子? 我会考虑是否学区,房屋质量(浇筑或板楼),建筑年代,是否可贷款,周边配套等等方面,那么这些特征较好的房价肯定贵啊,所以多从实际业务思考,当然除了我们能想到的,也有很多想不到的特征,就要多去试验一下(四则运算、决策树等方式),毕竟每个人的想法和心理是不一样的。
h["rooms_per_household"] = h["total_rooms"] / h["households"]
h["bedrooms_per_room"] = h["total_bedrooms"] / h["total_rooms"]
h["population_per_household"] = h["population"] / h["households"]
corr_matrix = h.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)

分析:卧室房间比例越低,房价越高;每个家庭的房价数量越多,房价越贵。
5. 机器学习算法的数据准备 ( 数据清洗、特征工程)
这里我们应该开始编写函数和积累函数,自己逐步建立一个转换函数的函数库,而不是每次都手动操作。最大原因:重用。
5.1 数据清理
对于缺失值,一般有3种方式:
① 删除对应的样本;
② 删除对应的特征;
③ 填充缺失值,填充值:中位数、众数、均值等。
对于第3种方式,sk提供了imputer来处理缺失值。
from sklearn.preprocessing import Imputer
imputer = Imputer(strategy = "median")
housing_nums = housing.drop("ocean_proximity",axis=1)
imputer.fit(housing_nums )
注意:此时imputer的估算只是针对【当前实例】,系统如果重启,则失效。 所以,为了稳妥,要对所有数值属性进行变换transform
X = imputer.transform(housing_nums)
housing_transform = pd.DataFrame(X,columns=housing_nums.columns)
5.1.1 【插曲1】 数据的拼接和合并:
① concat,基于axis拼接,类似union,适合纵向;
② merge,基于某列做关联,表的合并,类似sql的表连接,适合横向;
③ join,基于index合并。
5.1.2 【插曲2】 sk的几个常用函数:
sklearn做了一致性的设计,所以大部分数据集的操作通过以下函数就可以实现:
① fit 拟合;
② transform 变换;
③ fit_transform 拟合+变换;
④ predict 预测;
⑤ predict_prob 预测概率;
fit 和 transform 的区别和联系:举个通俗点的例子,从字面上来看,transform更像数据的实际转换方法,比如标准化StandardScaler(),当数据集执行了transform才算标准化完成,而fit更像是在这之前做一些基础数据的计算,为后面的transform作准备,所以一般我们在训练集做fit_transform,然后在测试集直接用transform,因为前面一步已经做了fit生成了一些基础数据比如均值,标准差等。
5.2 处理文本和分类属性
之前我们排除了分类属性ocean_proximity,因为它是一个文本属性,我们无法计算中位数。大部分的机器学习更易于跟数字打交道,所以我们可以将这种数据转换为数字。sk中提供了这种转换器,比如LabelEncoder。
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
housing_cat = housing["ocean_proximity"]
housing_cat_encoded = encoder.fit_transform(housing_cat)
housing_cat_encoded
encoder.classes_

注意:这里有个比较实际的问题,映射器将类别型特征转换为了0,1,2,3,4,但是这样的编码是有大小关系的,而实际ocean_proximity这个特征不具有大小关系的含义,所以通常解决方式:转化为二进制属性。
如果特征的值为高等、中等、低等,这种具有大小关系的含义,就可以映射为3,2,1这样的编码。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
housing_cat_1hot = encoder.fit_transform(housing_cat_encoded.reshape(-1,1))
housing_cat_1hot

这里输出是一个Scipy稀疏矩阵,但是只存非0元素的位置,因为大量0占用内存,所以做了优化。如果想转换成密集的二维数组:
housing_cat_1hot.toarray()

这样是不是就更像one-hot了?但是,LabelBinarizer默认返回的是一个密集的Numpy数组

但是,是不是很麻烦,难道每次我要先LabelEncoder再OneHotEncoder? sk提供了一个LabelBinarizer可以一次性完成2个转换(从文本类别转化为整数类别,再从整数类别转化为独热向量)
from sklearn.preprocessing import LabelBinarizer
encoder = LabelBinarizer()
housing_cat_1hot = encoder.fit_transform(housing_cat)
housing_cat_1hot
5.3 自定义转化器
① 为什么?因为一些清理操作或组合特定特征等任务需要自定义;再就是转换器能和sk的pipeline无缝衔接。
② 具体实现:新建类,添加两个基类BaseEstimator和TransformerMixin分别得到get_params()、set_params() 和 fit_transform() (这里的基类类似于继承),类中再实现fit和transform即可。
from sklearn.base import BaseEstimator,TransformerMixin
rooms_ix,bedrooms_ix,population_ix,household_ix = 3,4,5,6
class CombinedAttributesAdder(BaseEstimator,TransformerMixin):
def __init__(self,add_bedrooms_per_room = True):
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self,X,y=None):
return self
def transform(self,X,y=None):
rooms_per_household = X[:,rooms_ix] / X[:,household_ix]
population_per_household = X[:,population_ix] / X[:,household_ix]
if self.add_bedrooms_per_room :
bedrooms_per_room = X[:,bedrooms_ix] / X[:,rooms_ix]
return np.c_[X,rooms_per_household,population_per_household,bedrooms_per_room]
else:
return np.c_[X,rooms_per_household,population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room = False)
housing_extra_attr = attr_adder.transform(housing.values)
type(housing_extra_attr)
5.4 特征缩放
为什么?比如有的特征是0 ~ 9999,有的特征是2 ~ 9,会导致算法对取值较大的特征有所偏好,性能不佳,所以如果将两个特征都缩放到 0 ~ 1范围内,就能提高模型算法的泛化能力。
常用方法:最小最大值缩放 MinMaxScaler(默认范围0~1,可调)和 标准化StandadScaler。
区别:标准化不会将值缩放到特定范围,但是标准化能减小异常值的影响。
5.5 转换流水线
为什么? 许多数据转换的步骤需要以正确的顺序执行。
LabelBinarizer版本更新问题
from sklearn.base import BaseEstimator,TransformerMixin
rooms_ix,bedrooms_ix,population_ix,household_ix = 3,4,5,6
class CombinedAttributesAdder(BaseEstimator,TransformerMixin):
def __init__(self,add_bedrooms_per_room = True):
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self,X,y=None):
return self
def transform(self,X,y=None):
rooms_per_household = X[:,rooms_ix] / X[:,household_ix]
population_per_household = X[:,population_ix] / X[:,household_ix]
if self.add_bedrooms_per_room :
bedrooms_per_room = X[:,bedrooms_ix] / X[:,rooms_ix]
return np.c_[X,rooms_per_household,population_per_household,bedrooms_per_room]
else:
return np.c_[X,rooms_per_household,population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room = False)
housing_extra_attr = attr_adder.transform(housing.values)
type(housing_extra_attr)
class DataFrameSelector(BaseEstimator,TransformerMixin):
def __init__(self,attribute_names):
self.attribute_names = attribute_names
def fit(self,X,y=None):
return self
def transform(self,X):
return X[self.attribute_names].values
class MyLabelBinarizer(TransformerMixin):
def __init__(self, *args, **kwargs):
self.encoder = LabelBinarizer(*args, **kwargs)
def fit(self, x, y=0):
self.encoder.fit(x)
return self
def transform(self, x, y=0):
return self.encoder.transform(x)
from sklearn.pipeline import Pipeline,FeatureUnion
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import Imputer
housing_num = housing.drop("ocean_proximity",axis=1)
num_attr = list(housing_num)
cat_attr = ["ocean_proximity"]
num_pipeline = Pipeline([
('selector',DataFrameSelector(num_attr)),
('imputer',Imputer(strategy="median")),
('attribs_adder',CombinedAttributesAdder()),
('std_scaler',StandardScaler()),
])
cat_pipeline = Pipeline([
('selector',DataFrameSelector(cat_attr)),
('label_binarizer',MyLabelBinarizer()),
])
full_pipeline = FeatureUnion(transformer_list=[
("num_pipeline",num_pipeline),
("cat_pipeline",cat_pipeline),
])
housing_prepared = full_pipeline.fit_transform(housing)
housing_prepared
这一节主要完成了:自动清理 和 准备ML算法的数据的转换流水线
至此,看看我们完成了哪些内容:明确目标问题、获取数据、EDA、对训练集和测试集进行分层抽样、编写了自动清理和准备数据的转换器。
6. 选择和训练模型
6.1 训练和评估
首先,测试一下我们前面的组件。
from sklearn.linear_model import LinearRegression
m1 = LinearRegression()
m1.fit(housing_prepared,housing_label)
some_data = housing.iloc[:5]
some_labels = housing_label.iloc[:5]
housing_prepared = full_pipeline.fit_transform(housing)
some_data_prepared = full_pipeline.transform(some_data)
print("Predictions:",m1.predict(some_data_prepared))
print("Labels:",list(some_labels))

测试成功,说明我们前面的组件都可以正常工作。但是准确度堪忧~ 所以,先评估一下吧。
from sklearn.metrics import mean_squared_error
housing_predictions = m1.predict(housing_prepared)
m1_mse = mean_squared_error(housin_label,housing_predictions)
m1_rmse = np.sqrt(m1_mse)
m1_rmse

貌似损失有点大,说明欠拟合。如何解决?选择一个更复杂的模型试试,比如DecisionTreeRegressor
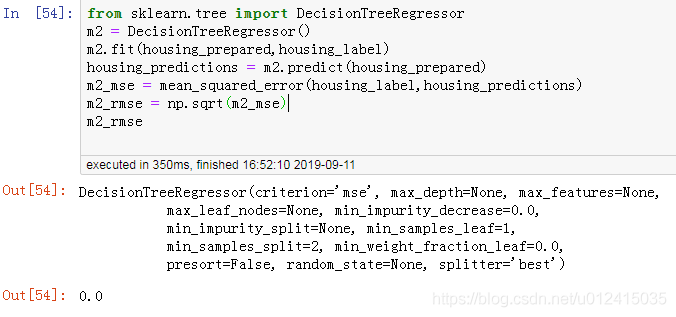
竟然0损失,好吧,模型过拟合了。所以我们还需要模型进行评估,正常来说要对训练集切分成训练集和验证集,然后用交叉验证评估,最后得到验证的模型再去预测测试集。
6.2 使用交叉验证来更好地进行评估
k-fold交叉验证
from sklearn.model_selection import cross_val_score
scores = cross_val_score(m2,housing_prepared,housing_label,scoring="neg_mean_squared_error",cv =10)
rmse_scores = np.sqrt(-scores)
def display_scores(scores):
print("Scores:",scores)
print("Mean:",scores.mean())
print("Std:",scores.std())
display_scores(rmse_scores)

l_scores = cross_val_score(m1,housing_prepared,housing_label,scoring="neg_mean_squared_error",cv =10)
l_rmse_scores = np.sqrt(-l_scores)
display_scores(l_rmse_scores)

from sklearn.ensemble import RandomForestRegressor
m3 = RandomForestRegressor()
m3.fit(housing_prepared,housing_label)
rf_scores = cross_val_score(m3,housing_prepared,housing_label,scoring="neg_mean_squared_error",cv =10)
rf_rmse_scores = np.sqrt(-rf_scores)
display_scores(rf_rmse_scores)

上面试验了3种不同模型的交叉验证效果,随机森林效果最好,但是还是过拟合。注意:此时不要急于去调超参数,而是要多试验几种其他模型(不同内核的SVM,神经网络模型等),我们这个阶段的目的是筛选有效模型(一般选出2~5个)。
模型保存:尝试过的模型要保存下来,包括超参数和训练过的参数,以及交叉验证的评分和实际预测的结果。比赛和实际工作都要这么做。我们通过python的pickel模块或sklearn.externals.joblib,这样可以有效将大型Numpy数组序列化。
from sklearn.externals import joblib
joblib.dump(m1,"linearReg_model.pkl")
my_model = joblib.load("linearReg_model.pkl")
my_model.predict(some_data_prepared)

7. 微调模型
经过上面过程,我们已经有了一个有效的模型列表,下一步需要对它们进行微调。
8. 网格搜索
可以直接使用sk的GridSearchCV来替代手动调整超参数。
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators': (3, 10, 30), 'max_features': (2, 3, 4, 6, 8),
}
rf_reg = RandomForestRegressor()
grid_search = GridSearchCV(rf_reg,params,cv=5,scoring="neg_mean_squared_error")
grid_search.fit(housing_prepared,housing_label)

查看最佳参数和最优估算器
grid_search.best_params_
grid_search.best_estimator_

查看评估分数
cvres = grid_search.cv_results_
for mean_score,param in zip(cvres["mean_test_score"],cvres["params"]):
print(np.sqrt(-mean_score),param)
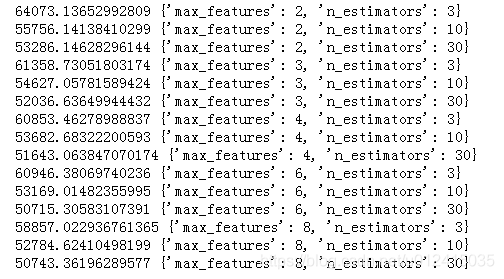
8.1 随机搜索
当数据量很大时,用网格搜索太慢,此时使用随机搜索RandomizedSearchCV:在每次迭代中,为每个超参数选择一个随机值,然后对一定数量的随机组合进行评估。
8.2 集成方法
将表现最优的几个模型组合起来。集成方法详细介绍
8.3 分析最佳模型及其错误
RF可以指出每个属性的相对重要程度 ( 怎么算的?根据某种增益和分裂次数等,曾经被面试官问到过。)
extra_attrs = ["rooms_per_hhold","pop_per_hhold","bedrooms_per_room"]
cat_one_hot_attrs = list(encoder.classes_)
attrs = num_attr + extra_attrs + cat_one_hot_attrs
sorted(zip(feature_importances,attrs),reverse=True)

从图中看出,收入中位数median_income是最重要的特征。
8.4 通过测试集评估系统
记住:在这之前我们没有动过测试集,也不应该动。
final_m = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value",axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_m.predict(X_test_prepared)
final_mse = mean_squared_error(y_test,final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse
特别注意: 测试集效果可能略差于交叉验证的结果,但是此时不要再调整超参数了,因为再调可能会导致新数据集上的泛化能力变差。
9. 启动、监控和维护系统
① 将生产数据源接入系统。
② 编写监控代码,实时监控系统的性能,在性能下降时触发警报。因为模型会慢慢腐坏,除非定期使用新数据训练模型。
③ 评估系统性能,需要对系统的预测结果进行抽样评估(人工分析)。这块需要将人工评估的流水线接入学习系统。
④ 需要定期用新数据训练模型,并且能保存系统当前状态,以便发生错误能及时回滚。
10. 试试看和练习
经过这一系列的过程,其实机器学习的大部分工作是:数据准备、构建监控工具、建立人工评估的流水线、自动定期训练模型。
尝试A ~ Z的过程:kaggle竞赛网站
11. 那些年我们踩过的坑。。。
① 已经训练好的模型predict数据,报特征维度不一致。报错信息如下:
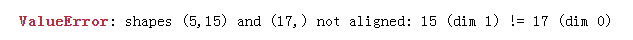
错误代码:
from sklearn.linear_model import LinearRegression
m1 = LinearRegression()
m1.fit(housing_prepared,housing_label)
some_data = housing.iloc[:5]
some_labels = housing_label.iloc[:5]
housing_prepared = full_pipeline.fit_transform(housing)
some_data_prepared = full_pipeline.fit_transform(some_data) 【错误处】
print("Predictions:",m1.predict(some_data_prepared))
仔细看上述代码,训练数据和测试数据都进行了fit_transform操作,相当于产生了2个不同pipeline实例,编码出来特征维度肯定不一致。我还傻傻的画了个图,造成这种情况的原因是创建了2个pipeline实例去编码:

错误修改
some_data_prepared = full_pipeline.transform(some_data) 【修改后】