【C++11】可变参数和lambda表达式
目录
1.可变参数模板
1.1可变参数的模板
1.2参数包的展开方式
1.21递归函数展开参数包
1.3逗号表达式展开参数包
2.STL库中的emplace相关接口
3.lambda表达式
3.1lambda的引入
3.2lambda的介绍
列表使用 lambda 表达式捕获
lambda实现swap函数
lambda表达式之间不能相互赋值
1.可变参数模板
可变参数模板可以说是C++的一大新收获,也是C++11新增的最强大的特性之一,它对参数高度泛化,能够让我们创建可以接受可变参数的函数模板和类模板。但是可变参数模板上手需要一定的技巧性,以及对C++进行初步的认识,所以我们来具体讲解一下。
1.1可变参数的模板
template返回类型 函数名(Args... args) { //函数主体 } //Args+省略号叫做模板参数包,args是函数形参参数包 //Args... args代表参数从0到多个 例如:
templatevoid ShowList(Args... args) { //函数主体 }
- 这里的template<>不禁让人想到了类模板和函数模板,这个其实和他很像,只不过那个指定参数了而这个Args...代表这从0到N的模板参数。
- 最为关键的是Args并不是关键字,只不过大家都用它来形容可变参数模板,你也可以叫他Brgs还可以叫做Crgs我是没有啥意见。
接下来我们用ShowList写一个传入不同参数的代码。
//可变参数 templatevoid ShowList(Args...args) { cout << sizeof...(args) << endl; //获取函数包中参数的个数 } 接下来传参------》
int main() { string str("hello"); ShowList(); //0 ShowList(1); //1 ShowList(11,str); //2 ShowList(1,'A',string("hello,world"), 12); //4 }
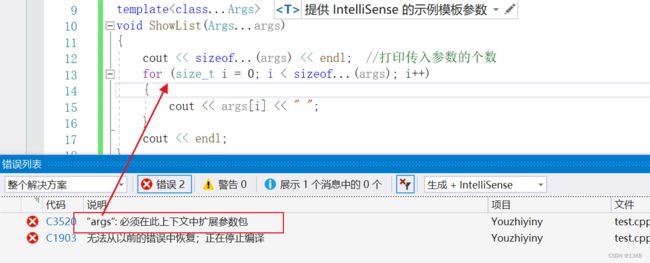
特别提醒:但是我们无法直接获取参数包中的每个参数,只能通过展开参数包的方式来获取,这是使用可变参数模板的一个主要特点 。语法并不支持使用args[i]的方式来获取参数包中的参数同样也不支持范围for那个。
templatevoid ShowList(Args...args) { cout << sizeof...(args) << endl; //打印传入参数的个数 for (size_t i = 0; i < sizeof...(args); i++) { cout << args[i] << " "; } cout << endl; }
1.2参数包的展开方式
1.21递归函数展开参数包
这里用到两部分递归函数,但是这两部分递归函数的函数名相同:
- 递归函数
- 递归终止函数
递归展开参数包的方式如下:
- 给函数模板增加一个模板参数,这样就可以从接收到的参数包中分离出一个参数出来。
- 在函数模板中递归调用该函数模板,调用时传入剩下的参数包。
- 如此递归下去,每次分离出参数包中的一个参数,直到参数包中的所有参数都被取出来。
每次我们都要先写递归函数,而递归终结函数可以理解为当参数包中所有参数都被取出后,就会调用这个杀死循环的终止函数了。
templatevoid ShowList(const T& val, Args... args) { cout << val << " "; ShowList(args...); } 这个可变参数的整体就写好了,最棘手的就是那个递归终结函数了。
此时这个终结函数又会分为两类有参和无参两种情况,这两种情况还不太一样。
我们先看一下无参的情况:
void ShowList() { cout << endl; } templatevoid ShowList(const T& val, Args... args) { cout << val << " "; ShowList(args...); } 此时当参数包的个数为0个的时候,就会走此函数,完成递归终止。
- 如果外部调用ShowList函数时就没有传入参数,那么就会直接匹配到无参的递归终止函数。
- 而我们本意是想让外部调用ShowList函数时匹配的都是函数模板,并不是让外部调用时直接匹配到这个递归终止函数。也就是说这个通道是我的老员工用的并且我也不想借给外界人员用,所以我们不得不再给外部人员提供一个新道路。
//递归终止函数 void ShowListArg() { cout << endl; } //展开函数 templatevoid ShowListArg(T value, Args... args) { cout << value << " "; //打印传入的若干参数中的第一个参数 ShowListArg(args...); //将剩下参数继续向下传 } //外部人员专业通道 template void ShowList(Args... args) { ShowListArg(args...); } 带参的情况:
//递归终止函数-------》带参情况 templatevoid ShowListArg(const T& val) //终止函数带参 { cout << endl; } //展开函数 template void ShowListArg(T value, Args... args) { cout << value << " "; //打印传入的若干参数中的第一个参数 ShowListArg(args...); //将剩下参数继续向下传 } //外部人员专业通道 template void ShowList(Args... args) { ShowListArg(args...); } int main() { ShowListArg(1,'A',string("hello,world"), 12); //4 }
- 当传入参数包中参数的个数为1时,就会传入这个终止函数中。
- 但该方法有一个弊端就是,我们在调用ShowList函数时必须至少传入一个参数,否则就会报错。因为此时无论是调用递归终止函数还是展开函数,都需要至少传入一个参数。
1.3逗号表达式展开参数包
C++只允许数组里面是同一种类型,但是模板的可变参数就意味着我参数包的类型并不统一,会出现一会是int,一会是char……。为了解决此问题,我们可以单独封装一层函数(PrintArg),此函数专门用于获得参数包的每个数据并输出,我们可以使用逗号表达式将返回值重新放到数组中。
- 逗号表达式会从左到右依次计算各个表达式,并且将最后一个表达式的值作为返回值进行返回。
- 将逗号表达式的最后一个表达式设置为一个整型值,确保逗号表达式返回的是一个整型值。
- 将处理参数包中参数的动作封装成一个函数,将该函数的调用作为逗号表达式的第一个表达式。
//逗号表达式展开参数包 templatevoid PrintArg(const T& t) { cout << t << " "; } //展开函数 template void ShowList(Args... args) { int arr[] = { (PrintArg(args), 0)... }; //列表初始化+逗号表达式 cout << endl; } int main() { ShowList(1,'A',string("hello,world"), 12); //4 }
- 可变参数的省略号需要加在逗号表达式外面,表示需要将逗号表达式展开,如果将省略号加在args的后面,那么参数包将会被展开后全部传入PrintArg函数,代码中的{(PrintArg(args), 0)...}将会展开成{(PrintArg(arg1), 0), (PrintArg(arg2), 0)(PrintArg(arg3), 0), etc...}。

2.STL库中的emplace相关接口
vector - C++ Reference (cplusplus.com) 我们可以进入cplusplus官网搜索vector,就可以看到C++11新增的emplace
templatevoid emplace_back (Args&&... args); &&不是特指右值引用而是代表左右值引用都可以。


我们以vector的emplace_back和push_back为例进行说明 :
- 调用push_back函数插入元素时,可以传入左值对象或者右值对象,也可以使用列表进行初始化。
- 调用emplace_back函数插入元素时,也可以传入左值对象或者右值对象,但不可以使用列表进行初始化。
- 除此之外,emplace系列接口最大的特点就是,插入元素时可以传入用于构造元素的参数包。
//emplace 相关应用
int main()
{
vector > vec;
pair kv(22, "emplace");
vec.push_back(kv); //传左值
vec.push_back(pair(1222, "2022")); //传右值
vec.push_back({ 30, "abc" }); //列表初始化
vec.emplace_back(kv); //传左值
vec.emplace_back(pair(1222, "2022")); //传右值
vec.emplace_back(50, "555"); //传参数包
for (auto e : vec)
{
cout << e.first << ": " << e.second << endl;
}
} 由于emplace系列接口的可变模板参数的类型都是万能引用,因此既可以接收左值对象,也可以接收右值对象,还可以接收参数包。
- 如果调用emplace系列接口时传入的是左值对象,那么首先需要先在此之前调用构造函数实例化出一个左值对象,最终在使用定位new表达式调用构造函数对空间进行初始化时,会匹配到拷贝构造函数。
- 如果调用emplace系列接口时传入的是右值对象,那么就需要在此之前调用构造函数实例化出一个右值对象,最终在使用定位new表达式调用构造函数对空间进行初始化时,就会匹配到移动构造函数。
- 如果调用emplace系列接口时传入的是参数包,那就可以直接调用函数进行插入,并且最终在使用定位new表达式调用构造函数对空间进行初始化时,匹配到的是构造函数。
使用emplace的原因:
- 之所以说emplace系列接口更高效是因为emplace系列接口最大的特点就是支持传入参数包,用这些参数包直接构造出对象,这样就能减少一次拷贝,
- 但emplace系列接口并不是在所有场景下都比原有的插入接口高效,如果传入的是左值对象或右值对象,那么emplace系列接口的效率其实和原有的插入接口的效率是一样的。
3.lambda表达式
3.1lambda的引入
lambda表达式有如下优点:
- 声明式编程风格:就地匿名定义目标函数或函数对象,不需要额外写一个命名函数或者函数对象。以更直接的方式去写程序,好的可读性和可维护性。
- 简洁:不需要额外再写一个函数或者函数对象,避免了代码膨胀和功能分散,让开发者更加集中精力在手边的问题,同时也获取了更高的生产率。
- 在需要的时间和地点实现功能闭包,使程序更灵活。
但是lambda具体的应用在什么地方?--------->
在学校这个完整的教育系统中老师会根据学生的考试成绩进行排名,而学校会根据班级成绩从而对教师进行考核,现在学校的后勤部要根据这些指标进行升序,降序排列。这里就会用到lambda表达式,这里一般会选择仿函数来指定排序的主要方式。
//lambda表达式 struct Teacher { string _name; // 名字 double _point; // 班级成绩 int _evaluate; // 总评分 Teacher(const char* str, double price, double evaluate) :_name(str) , _point(price) , _evaluate(evaluate) {} }; struct ComparePointLess { bool operator()(const Teacher& gl, const Teacher& gr) { return gl._point < gr._point; } }; struct ComparePointGreater { bool operator()(const Teacher& gl, const Teacher& gr) { return gl._point > gr._point; } }; int main() { vectorv = { { "李老师", 88, 8.9 }, { "张老师", 91, 8.7 }, { "徐老师", 86,9 }, { "王老师", 87, 8.7 } }; sort(v.begin(), v.end(), ComparePointLess());//按成绩升序排 sort(v.begin(), v.end(), ComparePointGreater());//按成绩降序排 } 这里我们就可以用lambda表达式解决这个问题了。
int main() { vectorv = { { "李老师", 88, 8.9 }, { "张老师", 91, 8.7 }, { "徐老师", 86,9 }, { "王老师", 87, 8.7 } }; sort(v.begin(), v.end(), [](const Teacher& g1, const Teacher& g2) { return g1._point < g2._point; }); sort(v.begin(), v.end(), [](const Teacher& g1, const Teacher& g2) { return g1._point > g2._point; }); sort(v.begin(), v.end(), [](const Teacher& g1, const Teacher& g2) { return g1._evaluate < g2._evaluate; }); sort(v.begin(), v.end(), [](const Teacher& g1, const Teacher& g2) { return g1._evaluate > g2._evaluate; }); }
3.2lambda的介绍
lambda 表达式定义了一个匿名函数,并且可以捕获一定范围内的变量。lambda 表达式的语法形式可简单归纳如下:
[ capture -list] ( params ) mutable -> return { body; };
- 其中 capture 是捕获列表,params 是参数表,
- mutable 默认情况下,lambda函数总是一个const函数,
mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。- return 是返回值类型,body是函数。
lambda函数的参数列表和返回值类型都是可选部分,但捕捉列表和函数体是不可省略的,因此最简单的lambda函数如下:
int main() { []{}; //最简单的lambda表达式 return 0; }一个完整的 lambda 表达式看起来像这样:
auto f = [](int a) -> int { return a + 1; }; std::cout << f(1) << std::endl; // 输出: 2需要注意的是,初始化列表不能用于返回值的自动推导:
auto x1 = [](int i){ return i; }; // OK: return type is int auto x2 = [](){ return { 1, 2 }; }; // error: 无法推导出返回值类型这时我们需要显式给出具体的返回值类型。
另外,lambda 表达式在没有参数列表时,参数列表是可以省略的。因此像下面的写法都是正确的:auto f1 = [](){ return 1; }; auto f2 = []{ return 1; }; // 省略空参数表
列表使用 lambda 表达式捕获
lambda 表达式还可以通过捕获列表捕获一定范围内的变量:
- [] 不捕获任何变量。
- [&] 捕获外部作用域中所有变量,并作为引用在函数体中使用(按引用捕获)。
- [bar] 按值捕获 bar 变量,同时不捕获其他变量。
- [&bar] 按值捕获外部作用域中所有变量,并按引用传递捕获bar变量。
- [=] 表示值传递方式捕获所有父作用域中的变量包括this。(按值捕获)。
- [this] 捕获当前类中的 this 指针,让 lambda 表达式拥有和当前类成员函数同样的访问权限。如果已经使用了 & 或者 =,就默认添加此选项。捕获 this 的目的是可以在 lamda 中使用当前类的成员函数和成员变量。
说明:
- 父作用域指的是包含lambda函数的语句块。
- 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。比如[=, &a, &b]。
- 捕捉列表不允许变量重复传递,否则会导致编译错误。比如[=, a]重复传递了变量a。
- 在块作用域以外的lambda函数捕捉列表必须为空,即全局lambda函数的捕捉列表必须为空。
- 在块作用域中的lambda函数仅能捕捉父作用域中的局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
- lambda表达式之间不能相互赋值,即使看起来类型相同。
lambda实现swap函数
//lambda实现swap
int main()
{
int a=5, b=7;
cout <<"a: " << a <<" " << "b: " << b << endl;
auto swap = [](int& a, int& b)->void
{
int tmp = a;
a = b;
b = tmp;
};
swap(a, b); //别忘了分号
cout << "a: " << a << " " << "b: " << b << endl;
return 0;
}
- lambda表达式是一个匿名函数,该函数无法直接调用,如果想要直接调用,可借助auto将其赋值给一个变量,此时这个变量就可以像普通函数一样使用。
- lambda表达式的函数体在格式上并不是必须写成一行,如果函数体太长可以进行换行,但换行后不要忘了函数体最后还有一个分号。
其实这个代码还可以进行优化,我们还可以利用捕捉列表进行捕捉 :
int main()
{
int a=5, b=7;
cout <<"a: " << a <<" " << "b: " << b << endl;
//auto swap = [](int& a, int& b)->void
//{
// int tmp = a;
// a = b;
// b = tmp;
//}; //不要忘了后面的分号
//swap(a, b);
auto swap = [&a, &b]
{
int tmp = a;
a = b;
b = tmp;
};
swap(); //()里面不需要传参
cout << "a: " << a << " " << "b: " << b << endl;
return 0;
}还有的交换函数会这样写:
auto swap = [a, b]()mutable
{
int tmp = a;
a = b;
b = tmp;
};
swap(); //()里面不需要传参
cout << "a: " << a << " " << "b: " << b << endl;注意:mutable的作用是取消lambda表达式的常量性,因为lambda总是一个const函数,光取消const属性还是不足以进行交换,这里还需要用到引用传递来捕获变量进行数据交换。
lambda表达式之间不能相互赋值
注意任何的lambda表达式之间的不能进行相互赋值,即使是两者的类型相同。
int main() { int a = 5, b = 7; cout << "a: " << a << " " << "b: " << b << endl; auto swap1 = [](int& a, int& b)->void { int tmp = a; a = b; b = tmp; }; //不要忘了后面的分号 auto swap2 = [](int& a, int& b)->void { int tmp = a; a = b; b = tmp; }; //不要忘了后面的分号 cout << typeid(swap1).name() << endl; // classcout << typeid(swap2).name() << endl; //class return 0; }
- lambda表达式之间不能相互赋值,就算是两个一模一样的lambda表达式。
- 因为lambda表达式底层的处理方式和仿函数是一样的,在VS下,lambda表达式在底层会被处理为函数对象,该函数对象对应的类名叫做
。 - 类名中的uuid叫做通用唯一识别码(Universally Unique Identifier),简单来说,uuid就是通过算法生成一串字符串,保证在当前程序当中每次生成的uuid都不会重复。
- lambda表达式底层的类名包含uuid,这样就能保证每个lambda表达式底层类名都是唯一的。
- 因此每个lambda表达式的类型都是不同的,这也就是lambda表达式之间不能相互赋值的原因,我们可以通过typeid(变量名).name()的方式来获取lambda表达式的类型。