python数据分析基础技术篇_Python数据分析基础技术之scikit-learn(史上最全面)
一、scikit-learn 简介
scikit-learn (sklearn) 是基于 Python 语言的机器学习工具。python
是简单高效的数据挖掘和数据分析工具
可供你们在各类环境中重复使用
创建在 NumPy ,SciPy 和 matplotlib 上
开源,可商业使用 - BSD许可证
sklearn能够实现数据预处理、分类、回归、降维、模型选择等经常使用的机器学习算法。sklearn是基于NumPy, SciPy, matplotlib的。git
NumPy:NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。。
SciPy :scipy是一个用于数学、科学、工程领域的经常使用软件包,能够处理插值、积分、优化、图像处理、常微分方程数值解的求解、信号处理等问题
matplotlib :Matplotlib 是 Python 的绘图库,仅须要几行代码,即可以生成直方图、功率谱、条形图、错误图、散点图等。 它可与 NumPy 一块儿使用,提供了一种有效的 MatLab 开源替代方案。 它也能够和图形工具包一块儿使用,如 PyQt 和 wxPython。
二、安装 scikit-learn最新版本
Scikit-learn 要求:web
Python (>= 2.7 or >= 3.3),
NumPy (>= 1.8.2),
SciPy (>= 0.13.3).算法
若是你已经有一个安全的 numpy 和 scipy,安装 scikit-learn 最简单的方法是使用pip:数组
pip install -U scikit-learn安全
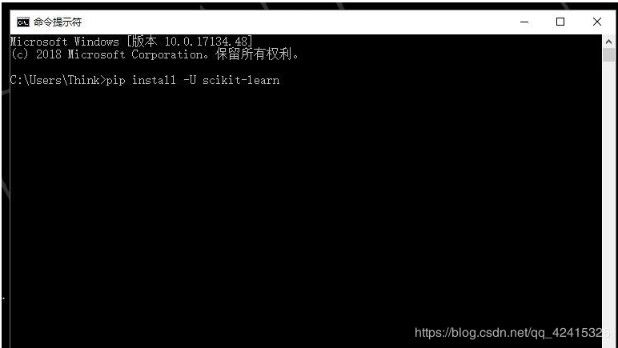
pip 是一个Python包管理工具,主要是用于安装 PyPI 上的软件包。若是你安装的Python 2 >=2.7.9 或者Python 3 >=3.4 python自带了pip,因此不用安装。能够用 pip list命令查看安装了哪些python包。
 机器学习
机器学习
或者你是在Anaconda环境下,可使用conda:svg
conda install scikit-learn函数
pip 升级和卸载操做仅适用于经过 pip install 安装的软件包;升级或卸载使用 Anaconda 安装的 scikit-learn要用conda命令:工具
升级 scikit-learn:conda update scikit-learn
卸载 scikit-learn:conda remove scikit-learn
使用 pip install -U scikit-learn 升级 or pip uninstall scikit-learn 卸载 可能没法正确删除 conda 命令安装的文件
三、使用 scikit-learn 介绍机器学习
机器学习是什么?
通常来讲,一个学习问题一般会考虑一系列 n 个 样本 数据,而后尝试预测未知数据的属性。 若是每一个样本是 多个属性的数据 (好比说是一个多维记录),就说它有许多“属性”,或称 features(特征) 。
咱们能够将学习问题分为如下几大类:
有监督学习:其中数据带有一个附加属性,即咱们想要预测的结果值
分类:样本属于两个或更多个类,咱们想从已经标记的数据中学习如何预测未标记数据的类别。 分类问题的一个例子是手写数字识别,其目的是将每一个输入向量分配给有限数目的离散类别之一。 咱们一般把分类视做监督学习的一个离散形式(区别于连续形式),从有限的类别中,给每一个样本贴上正确的标签。
回归:若是指望的输出由一个或多个连续变量组成,则该任务称为 回归 。 回归问题的一个例子是预测鲑鱼的长度是其年龄和体重的函数。
无监督学习:其中训练数据由没有任何相应目标值的一组输入向量x组成。这种问题的目标多是在数据中发现彼此相似的示例所聚成的组,这种问题称为 聚类 , 或者,肯定输入空间内的数据分布,称为 密度估计 ,又或从高维数据投影数据空间缩小到二维或三维以进行可视化
训练集和测试集
机器学习是从数据的属性中学习,并将它们应用到新数据的过程。 这就是为何机器学习中评估算法的广泛实践是把数据集分割成训练集 (咱们从中学习数据的属性)和 测试集 (咱们测试这些性质)。
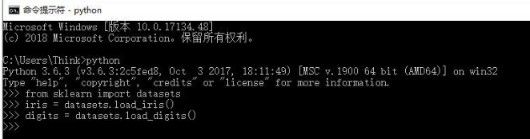
咱们来加载一个栗子数据集
scikit-learn自带几个标准数据集。例如,用于分类的iris和digits数据集,和用于回归的波士顿房价数据集。下面,咱们从cmd命令处理程序启动python解释器,练习加载iris和digits数据集。
python环境中的数据集是一个相似字典的对象,它保存有关数据的全部数据和一些元数据。 该数据存储在 .data 成员中,它是 n_samples(样本), n_features (特征)数组。 在监督问题的状况下,一个或多个响应变量存储在 .target 成员中。
例如,在数字数据集的状况下,digits.data 使咱们可以获得一些用于分类的样本特征:

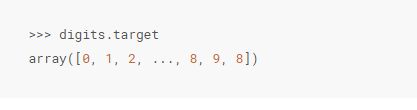
而且 digits.target 表示了数据集内每一个数字的真实类别,也就是咱们指望从每一个手写数字图像中学得的相应的数字标记:
数据数组的形状
数据老是二维数组,形状为 (n_samples, n_features) ,尽管原始数据可能具备不一样的形状。 在数字的状况下,每一个原始样本是形状 (8, 8) 的图像,可使用如下方式访问:

如何加载外部数据集?
scikit-learn将任何数值型数据存储为numpy数组或scipy稀疏矩阵。其它能够转换为numpy数组的类型也能够。下面介绍几种推荐的数据加载方式:
一、pandas.io提供了一组工具,利用它们读取包括CSV, Excel, JSON, SQL等常见格式的数据集。pandas很适合处理不一样类型的数据,而且可以把这些数据转为适合的数值数组。
二、scipy.io专门处理在科学计算中经常使用的二进制形式,例如,.mat, .arff
三、numpy/routines.io是列形数据进入numpy数组的标准加载形式。
四、scikit-learn的datasets.load_files函数做为文本文件的字典加载形式。在这种加载形式,每个字典名是每个类的名,而字典里的每个文件则对应来自该类的一个样本。
提示: 若是在管理本身的数值型数据时,咱们推荐使用一个优化过的文件格式,例如,HDF5, 这样能够减小数据加载时间。当你加载的外部数据很大时,这种方式尤为有用。 不一样的python库,例如,H5Py, PyTables, pandas都提供读写HDF5格式的数据的接口。