机械臂抓取学习笔记二
论文:
Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network
摘要:
本文提出了一个模块化的机器人系统,用于预测、规划和执行场景中物体的反足抓取。
提出了一种生成剩余卷积神经网络(GR ConvNet),该网络为n通道输入图像中的每个像素生成反模式抓取,该结构用于预测摄像机视场中物体的合适反足抓取配置。
- “Deep learning for detecting robotic grasps,”
- “Real-time grasp detection using convolutional neural networks,”
- “Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot
hours,” - “Robotic grasp detection using deep convolutional neural networks,”
四篇文章将抓取预测为通过从多个抓取概率中选择最佳抓取来计算的抓取矩形;
本文的网络则生成三幅图像,从中可以推断多个对象的抓取矩形。此外,可以从GR ConvNet的输出一次推断多个对象的多个抓取矩形,从而减少总体计算时间。
下图显示了所提议的系统架构的概述。它由两个主要模块组成:推理模块和控制模块。推理模块从RGB-D相机获取场景的RGB和对齐深度图像。图像经过预处理以匹配GR ConvNet的输入格式。该网络生成质量、角度和宽度图像,然后用于推断反足抓取姿势(Antipodal grasp poses)。控制模块由任务控制器组成,该任务控制器使用推理模块生成的抓取姿势准备并执行执行拾取和放置任务的计划。它使用轨迹规划器和控制器,通过ROS接口将所需动作传达给机器人。

引文:
机器人抓取领域,虽然问题似乎只是能够找到一个合适的抓取物体的方法,但实际任务涉及多方面的因素,例如:要抓取的物体、物体的形状、物体的物理特性以及需要抓取的抓取器等。该领域的早期研究涉及到手动设计特征可以从以下四篇文章看到:
- “Cloth grasp point detection based on multiple-view geometric cues with appli-
cation to robotic towel folding,” - “Robust visual servoing,”
- “One-shot learning and generation of dexterous grasps for novel objects,”
- “Data-driven grasp synthesis—a survey,”
下两文采用与物体接触的末端执行器的力学和接触运动学,并进行了抓取分析(经典控制)。
- “Robotic grasping and contact: A review,”
- “Robot grasp synthesis algorithms: A survey,”
在机器人抓取新物体方面,之前的工作涉及使用监督学习,监督学习是基于合成数据进行训练的,但仅限于办公室、厨房和洗碗机等环境。下文主要讨论了这种研究方向
- “Robotic grasping of novel objects using vision,”
下文则介绍了一种全卷积抓取质量卷积神经网络(FC-GQ-CNN),该网络通过使用数据收集策略和综合训练环境预测鲁棒抓取质量。此方法使每0.625s中的抓取次数增加了5000倍。然而,目前的研究更多地依赖于使用RGB-D数据来预测抓取姿势。这些方法完全依赖于深度学习技术。
- “On-policy dataset synthesis for learning robot grasping policies using fully convolutional deep networks,”
下文提出了一种通过形状完成来掌握规划的有趣方法,其使用3D CNN在从不同视角捕获的对象数据集上的3D原型上训练网络。
- “Shape completion enabled robotic grasping,”
下文使用触觉数据和视觉数据来训练混合的深层结构。
- “A hybrid deep architecture for robotic grasp detection,”
下文提出了一种抓取质量卷积神经网络(GQ-CNN),该网络通过在Dex Net 2上训练的合成点云数据预测抓取。
- “Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics,”
下文讨论了使用单目图像进行手-眼协调,以便使用深度学习框架进行机器人抓取。他们使用CNN预测抓取成功,并进一步使用连续伺服来连续伺服操纵器以纠正错误。
- “Learning hand-eye coordination for robotic grasping with deep learning and large-
scale data collection,”
下文讨论了一种称为概率逻辑框架的有趣方法,该方法据说可以提高机器人的抓取能力,他借助语义对象部分。该框架将高级推理与低级抓取相结合。高级推理包括对象启示、对象类别和基于任务的信息,而低级推理使用视觉形状特征。据观察,这在厨房相关场景中效果良好
- “Semantic and geometric reason- ing for robotic grasping: a probabilistic logic approach,”
下文生成式抓取CNN体系结构使用深度图像生成抓取姿势,网络基于像素计算抓取。文章表明它减少了离散采样和计算复杂性的现有缺点。
- “Learning robust, real-time, reac- tive robotic grasping,”
多模态数据抓取:
早先Jiange等人使用RGB-D图像,基于两步学习过程推断抓取。第一步用于缩小搜索空间,第二步用于从使用第一种方法获得的顶部抓取计算最佳抓取矩形。而Lenzet等人使用了类似的两步方法,但采用了深度学习体系结构,但该体系结构不能很好地适用于所有类型的物体,并且经常预测一个抓取位置,该位置不是该特定物体的最佳抓取位置。
下文使用点云预测网络生成抓取,首先通过获取颜色、深度和遮罩图像对数据进行预处理,然后获取物体的3D点云,并将其输入批评网络以预测抓取。
- “Data- efficient learning for sim-to-real robotic grasping using
deep point cloud prediction networks,”
下文提出了一种新的体系结构,可以同时预测多个对象的多个抓取,而不是单个对象的多个抓取。为此,他们使用了自己的多对象数据集。
- “Real-world multiobject, multigrasp detection,”
下文讨论了一种机器人抓取方法,该方法由用于对象识别的ConvNet和用于操纵对象的抓取方法组成,该抓取方法假设工业装配线中的对象参数是预先已知的
- “A robotic grasping method using convnets,”
Kumraet等人提出了一种深度CNN架构,该架构使用剩余层来预测鲁棒抓取。本文证明,随着剩余层的增加,更深的网络可以更好地学习特征,执行速度更快。Asifet al.引入了一个称为EnsembleNet的整合框架,其中GRAP生成网络生成四个GRAP表示,EnsembleNet合成这些生成的GRAP以生成GRAP分数,从中选择得分最高的GRAP。
下表将我们的工作与机器人抓取未知物体的最新相关工作进行了比较

问题表述:
- 本文将机器人抓取问题定义为从场景的n通道图像预测未知对象的反足抓取并在机器人上执行。与其他文章中使用的5维抓取表示不同,本文使用了一种改进的抓取表示形式,类似于Morrisonet等人在[20]中提出的抓取表示形式。
- 将机器人框架中的抓取姿势表示为:Gr= (P,Θr,Wr,Q) ,其中P=(x,y,z)是工具的中心位置;Θr是工具围绕z轴旋转的角度;Wr是工具所需的宽度;Q是抓取质量的分数。
- 从n通道图像中检测抓取I=R^(n×h×w),高度为h和宽度为W,可定义为:Gi= (x,y,Θi,Wi,Q)
- 式中,(x,y)对应于图像坐标中的抓取中心,Θi是相机参考系中的旋转角度,wi是图像坐标中所需的宽度,Q是抓取质量的分数。
- 抓取质量分数是图像中每个点的抓取质量,表示为0到1之间的分数值,接近1的值表示抓取成功的几率更大。Θi表示抓住感兴趣对象所需的每个点的角旋转量的反足测量,并表示为范围内的值[−π/2,π/2]. Wi是所需的宽度,表示为均匀深度的度量,表示为[0,Wmax]像素范围内的值。Wmaxis反足抓握器的最大宽度。
- 为了在机器人的图像空间中执行抓取,我们可以应用以下变换将图像坐标转换为机器人的参考框架:Gr=Trc(Tci(Gi))
- GI是一种转换,它使用摄像机的固有参数将图像空间转换为摄像机的3D空间,并使用摄像机姿势校准值将摄像机空间转换为机器人空间。
- 对于图像中的多个抓取,可以缩放此符号。所有抓取的集合组可表示为:
- G= (Θ,W,Q)∈R^(3×h×w)
- Θ、W和Q以抓取角度、抓取宽度和抓取质量分数的形式表示三幅图像,分别在图像的每个像素处使用公式 Gi= (x,y,Θi,Wi,Q) 计算.
方法:
我们提出了一个双模块系统来预测、规划和执行场景中对象的反足抓取。建议系统的概述如第一张图所示。推理模块用于预测摄像机视野中物体的合适抓取姿势。控制模块使用这些抓取姿势规划和执行机器人轨迹,以执行反足抓取。
- 推理模块:
- 推理模块由三部分组成。首先,对输入数据进行预处理,对其进行裁剪、调整大小和规范化。如果输入具有深度图像,则对其进行修复以获得深度表示。224×224的图像经过n通道处理后的输入图像被送入GR-ConvNet。它使用n通道输入,该输入不限于特定类型的输入模态,例如仅深度或仅RGB图像作为输入图像。因此,可将其推广到任何类型的输入模态。第二步使用GRConvNet从预处理图像中提取的特征生成抓取角度、抓取宽度和抓取质量分数三种图像作为输出。第三步从三个输出图像推断抓取姿势。
- 控制模块
- 控制模块主要包含一个任务控制器,执行拾取、放置和校准等任务。控制器从推理模块请求抓取姿势,推理模块返回具有最高质量分数的抓取姿势。然后,通过hand-
eye calibration (手眼标定)计算的变换将抓取姿势从摄像机坐标转换为机器人坐标。此外,机器人框架中的抓取姿势用于规划轨迹,以通过ROS接口使用反向运动学执行拾取和放置动作。然后机器人执行计划的轨迹。由于我们的模块化方法和ROS集成,该系统可适用于任何机械臂。 - 模型架构:
- 下图显示了建议的GR ConvNet模型,它是一种生成架构,接收n通道输入图像并以三幅图像的形式生成像素级抓取。n通道图像通过三个卷积层,然后是五个剩余层和卷积转置层,以生成四个图像。这些输出图像包括抓取质量分数、图末表格中所需的角度cos 2Θ和sin 2Θ以及所需的末端执行器宽度。由于反足抓取在±π2附近是均匀的,因此我们以两个元素cos 2Θ和sin 2Θ的形式提取角度,这两个元素输出不同的值,组合起来形成所需的角度

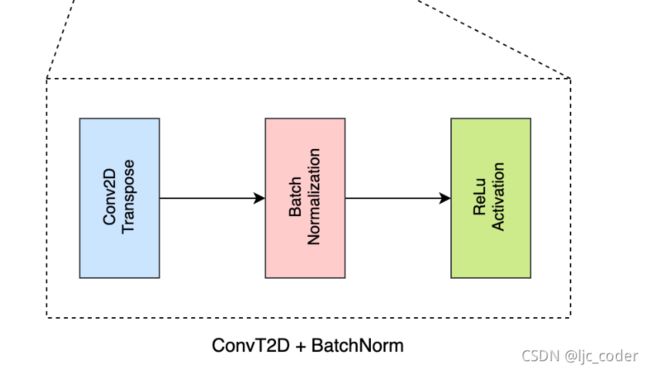


-
我们的网络总共有1900900个参数,这表明我们的网络相对其他网络更短。因此,与使用包含数百万个参数和复杂体系结构的类似抓取预测技术的其他体系结构相比,它的计算成本更低,速度更快。该型号的轻量级特性使其适合以高达50 Hz的频率进行闭环控制。
-
训练方法:
-
对于获取物品D={D1…Dn}的数据集,输入场景图像I={I^1. . .I^n}。在图片框架中的成功抓取表示为:此式
-
我们可以通过最小化输入图像场景上的条件的负对数似然,从端到端训练我们的模型,以学习映射函数γ(I,D)=gib,这是由此式给出
-
使用Adam优化器,标准反向传播和小批量SGD技术对模型进行训练。学习率设置为10^−3使用的最小批量为8。我们使用三个随机种子训练模型,并报告三个种子的平均值
-
损失函数:
-
我们分析了我们网络的各种损耗函数的性能,在运行了一些试验后发现,为了处理梯度爆炸,平滑L1损耗(也称为Huber损耗)效果最好。我们把损失定义为此式其中,Zi表示为:此式
-
Gi是由网络预测产生的抓取位姿,Gi帽是正确的抓取位姿
机器人抓取实验的物体有:
家用测试对象
对抗性测试对象
- 抓取检测尺度:
根据提出的矩形度量,当抓取满足以下两个条件时,它被认为是有效的
- 真实抓取矩形和预测抓取矩形之间的联合交集(IoU)分数大于25%。
- 预测抓取矩形的抓取方向与真实抓取矩形之间的偏移小于30◦
该度量要求抓取矩形表示,但我们的模型预测基于图像的抓取表示Gi帽由等式决定。因此,为了从基于图像的抓取表示转换为矩形表示,输出图像中每个像素对应的值被映射到其等效的矩形表示
- 实验:
家用测试对象:
总共选择了35个家庭对象来测试我们系统的性能。每个对象分别测试10个不同的位置和方向,导致350次抓握尝试。选择对象,使每个对象代表不同的形状、大小和几何体;而且彼此之间几乎没有相似之处。我们创建了可变形、难以抓取、反射和需要高精度的小对象的组合。
对抗性测试对象:
另一组由10个具有复杂几何结构的敌方目标组成,用于评估我们提出的系统的准确性。这些3D打印对象具有抽象几何体,具有难以感知和把握的不确定表面和边缘。这些物体中的每一个都被单独测试了10个不同的方向和位置,共有100次抓握尝试。
杂乱的物体:
工业应用(如仓库)需要在隔离和杂乱的环境中拾取对象。因此,为了对杂乱的物体进行实验,我们对60个看不见的物体进行了10次实验。从以前看不到的新对象中为每次运行选择一组不同的对象,以创建混乱的场景。
使用数据集:
- Cornell Dataset
- Jacquard Dataset