PB级企业电商离线数仓项目实战【上】
第一部分 数据仓库理论
第1节 数据仓库
1.1 什么是数据仓库
1988年,为解决全企业集成问题,IBM公司第一次提出了信息仓库(InformationWarehouse)的概念。数据仓库的基本原理、技术架构以及分析系统的主要原则都
已确定,数据仓库初具雏形。1991年Bill Inmon(比尔·恩门)出版了他的第一本关于数据仓库的书《Building theData Warehouse》,标志着数据仓库概念的确立。书中指出,数据仓库(DataWarehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化的(Time Variant)数据集合,用于支持管理决策(Decision-Making Support)。该书还提供了建立数据仓库的指导意见和基本原则。凭借着这本书,Bill Inmon被称为数据仓库之父。
1.2 数据仓库四大特征
- 面向主题的
- 集成的
- 稳定的
- 反映历史变化的
面向主题的
与传统数据库面向应用进行数据组织的特点相对应,数据仓库中的数据是面向主题进行组织的。
什么是主题呢?
- 主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象
- 在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象
面向主题的数据组织方式,就是在较高层次上对分析对象的数据的一个完整、一致的描述,能完整、统一地刻划各个分析对象所涉及的企业的各项数据,以及数据之间的
联系。所谓较高层次是相对面向应用的数据组织方式而言的,是指按照主题进行数据组织的方式具有更高的数据抽象级别。
例如销售情况分析就是一个分析领域,那么数据仓库的分析主题可以是“销售分析”。
集成的
数据仓库的数据是从原有的分散的多个数据库、数据文件、用户日志中抽取来的,数据来源可能既有内部数据又有外部数据。操作型数据与分析型数据之间差别很大:
- 数据仓库的每一个主题所对应的源数据,在原有的各分散数据库中有重复和不一致的地方,且来源于不同的联机系统的数据与不同的应用逻辑捆绑在一起
- 数据仓库中的数据很难从原有数据库系统直接得到。数据在进入数据仓库之前,需要经过统一与综合
数据仓库中的数据是为分析服务的,而分析需要多种广泛的不同数据源以便进行比较、鉴别,数据仓库中的数据会从多个数据源中获取,这些数据源包括多种类型数据
库、文件系统以及Internet网上数据等,它们通过数据集成而形成数据仓库中的数据。
稳定的
数据仓库数据反映的是一段相当长的时间内历史数据的内容,是不同时点的数据库快照的集合,以及基于这些快照进行统计、综合和重组的导出数据。数据稳定主要是针对应用而言。数据仓库的用户对数据的操作大多是数据查询或比较复杂的挖掘,一旦数据进入数据仓库以后,一般情况下被较长时间保留。数据经加工和集成进入数据仓库后是极少更新的,通常只需要定期的加载和更新。
反映历史变化的
数据仓库包含各种粒度的历史数据。数据仓库中的数据可能与某个特定日期、星期、月份、季度或者年份有关。虽然数据仓库不会修改数据,但并不是说数据仓库的数据
是永远不变的。数据仓库的数据也需要更新,以适应决策的需要。数据仓库的数据随时间的变化表现在以下几个方面:
- 数据仓库的数据时限一般要远远长于操作型数据的数据时限
- 业务系统存储的是当前数据,而数据仓库中的数据是历史数据
- 数据仓库中的数据是按照时间顺序追加的,都带有时间属性
1.3 数据仓库作用
- 整合企业业务数据,建立统一的数据中心;
- 产生业务报表,了解企业的经营状况;
- 为企业运营、决策提供数据支持;
- 可以作为各个业务的数据源,形成业务数据互相反馈的良性循环;
- 分析用户行为数据,通过数据挖掘来降低投入成本,提高投入效果;
- 开发数据产品,直接或间接地为企业盈利;
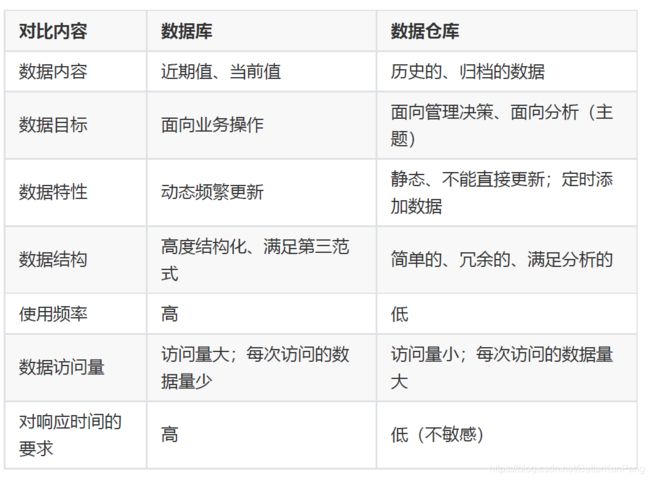
1.4 数据仓库与数据库的区别
数据库与数据仓库的区别实际讲的是 OLTP 与 OLAP 的区别。
OLTP(On-Line Transaction Processing 联机事务处理),也称面向交易的处理系统。主要针对具体业务在数据库系统的日常操作,通常对少数记录进行查询、修改。
用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
OLAP(On-Line Analytical Processing 联机分析处理),一般针对某些主题的历数据进行分析,支持管理决策。
数据仓库的出现,并不是要取代数据库:
- 数据仓库主要用于解决企业级的数据分析问题或者说管理和决策
- 数据仓库是为分析数据而设计,数据库是为捕获和存储数据而设计
- 数据仓库是面向分析,面向主题设计的,即信息是按主题进行组织的,属于分析型;数据库是面向事务设计的,属于操作型
- 数据仓库在设计是有意引入数据冗余(目的是为了提高查询的效率),采用反范式的方式来设计;数据库设计是尽量避免冗余(第三范式),一般采用符合范式的规则来设计
- 数据仓库较大,数据仓库中的数据来源于多个异构的数据源,而且保留了企业的历史数据;数据库存储有限期限、单一领域的业务数据
数据仓库的出现,并不是要取代数据库:
- 数据库是面向事务的设计,数据仓库是面向主题设计的
- 数据库存储有限期限的业务数据,数据仓库存储的是企业历史数据
- 数据库设计尽量避免冗余,数据存储设计满足第三范式,但是便于进行数据分析。数据仓库在设计时有意引入冗余,依照分析需求,分析维度、分析指标进行设计
- 数据库是为捕获数据而设计,数据仓库是为分析数据而设计
以银行业务为例。数据库是事务系统的数据平台,客户在银行做的每笔交易都会写入数据库,被记录下来,这里,可以简单地理解为用数据库记账。数据仓库是分析系统
的数据平台,它从事务系统获取数据,并做汇总、加工,为决策者提供决策的依据。比如,某银行某分行一个月发生多少交易,该分行当前存款余额是多少。如果存取款
多,消费交易多,那么该地区就有必要设立ATM了。银行的交易量是巨大的,通常以百万甚至千万次来计算。事务系统是实时的,这就要求时效性,客户存一笔钱需要几十秒是无法忍受的,这就要求数据库只能存储很短一段时间的数据。而分析系统是事后的,它要提供关注时间段内所有的有效数据。这些数据是海量的,汇总计算起来也要慢一些,但是,只要能够提供有效的分析数据就达到目的了。
数据仓库是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它决不是所谓的大型数据库。
1.5 数据集市
数据仓库(DW)是一种反映主题的全局性数据组织。但全局性数据仓库往往太大,在实际应用中将它们按部门或业务分别建立反映各个子主题的局部性数据组织,即数
据集市(Data Mart),有时也称它为部门数据仓库。
数据集市:是按照主题域组织的数据集合,用于支持部门级的数据分析与决策。如在商品销售的数据仓库中可以建立多个不同主题的数据集市:
- 商品采购数据集市
- 商品库存数据集市
- 商品销售数据集市
数据集市仅仅是数据仓库的某一部分,实施难度大大降低,并且能够满足企业内部部分业务部门的迫切需求,在初期获得了较大成功。但随着数据集市的不断增多,这种
架构的缺陷也逐步显现。企业内部独立建设的数据集市由于遵循不同的标准和建设原则,以致多个数据集市的数据混乱和不一致,形成众多的数据孤岛。
企业发展到一定阶段,出现多个事业部,每个事业部都有各自数据,事业部之间的数据往往都各自存储,各自定义。每个事业部的数据就像一个个孤岛一样无法(或者极
其困难)和企业内部的其他数据进行连接互动。这样的情况称为数据孤岛,简单说就是数据间缺乏关联性,彼此无法兼容。
第2节 数据仓库建模方法
数据模型就是数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据。有了适合业务和基础数据存储环境的模型,能获得以下好处:
- 性能:良好的数据模型能帮助我们快速查询所需要的数据,减少数据的I/O吞吐
- 成本:良好的数据模型能极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低大数据系统中的存储和计算成本
- 效率:良好的数据模型能极大地改善用户使用数据的体验,提高使用数据的效率
- 质量:良好的数据模型能改善数据统计口径的不一致性,减少数据计算错误的可能性
大数据系统需要数据模型方法来帮助更好地组织和存储数据,以便在性能、成本、效率和质量之间取得最佳平衡。
2.1 ER模型
数据仓库之父Bill Inmon提出的建模方法是从全企业的高度设计一个3NF模型,用实体关系(Entity Relationship, ER)模型描述企业业务,在范式理论上符合3NF。数据仓
库中的3NF与OLTP系统中的3NF 的区别在于,它是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系的抽象。其具有以下几个特点:
- 需要全面了解整个企业业务和数据
- 实施周期非常长
- 对建模人员的能力要求非常高
釆用ER模型建设数据仓库模型的出发点是整合数据,将各个系统中的数据以整个企业角度按主题进行相似性组合和合并,并进行一致性处理,为数据分析决策服务,但
是并不能直接用于分析决策。其建模步骤分为三个阶段:
高层模型:一个高度抽象的模型,描述主要的主题以及主题间的关系,用于描述企业的业务总体概况
中层模型:在高层模型的基础上,细化主题的数据项
物理模型(也叫底层模型):在中层模型的基础上,考虑物理存储,同时基于性能和平台特点进行物理属性的设计,也可能做一 些表的合并、分区的设计等
2.2 维度模型
维度模型是数据仓库领域的Ralph Kimball大师所倡导的,他的《数据仓库工具箱》是数据仓库工程领域最流行的数据仓库建模经典。维度建模从分析决策的需求出发构建模型,为分析需求服务,重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复杂查询的响应性能。其典型的代表是星型模型,以及在一些特殊场景下使用的雪花模型。其设计分为以下几个步骤:选择需要进行分析决策的业务过程。业务过程可以是:
单个业务事件,比如交易的支付、退款等
某个事件的状态,比如当前的账户余额等
一系列相关业务事件组成的业务流程
- 选择数据的粒度。在事件分析中,我们要预判所有分析需要细分的程度,从而决定选择的粒度
- 识别维表。选择好粒度之后,就需要基于此粒度设计维表,包括维度属性,用于分析时进行分组和筛选
- 选择事实。确定分析需要衡量的指标
现代企业业务变化快、人员流动频繁、业务知识功底的不够全面,导致ER模型设计产出周期长。大多数企业实施数据仓库的经验说明:在不太成熟、快速变化的业务面前,构建ER模型的风险非常大,不太适合去构建ER模型。而维度建模对技术要求不高,快速上手,敏捷迭代,快速交付;更快速完成分析需求,较好的大规模复杂查询的响应性能。
第3节 数据仓库分层
数据仓库更多代表的是一种对数据的管理和使用的方式,它是一整套包括了数据建模、ETL(数据抽取、转换、加载)、作用调度等在内的完整的理论体系流程。数据仓库在构建过程中通常都需要进行分层处理。业务不同,分层的技术处理手段也不同。分层的主要原因是在管理数据的时候,能对数据有一个更加清晰的掌控。详细来讲,
主要有下面几个原因:
清晰的数据结构
每一个数据分层都有它的作用域,在使用表的时候能更方便地定位和理解。
将复杂的问题简单化
将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的问题,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复
所有的数据,只需要从有问题的地方开始修复。减少重复开发
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
屏蔽原始数据的异常
屏蔽业务的影响,不必改一次业务就需要重新接入数据。
数据血缘的追踪
最终给业务呈现的是一个能直接使用业务表,但是它的来源很多,如果有一张来源表出问题了,借助血缘最终能够快速准确地定位到问题,并清楚它的危害范围。
数仓的常见分层一般为3层,分别为:数据操作层、数据仓库层和应用数据层(数据集市层)。当然根据研发人员经验或者业务,可以分为更多不同的层,只要能达到流程清晰、方便查数即可。
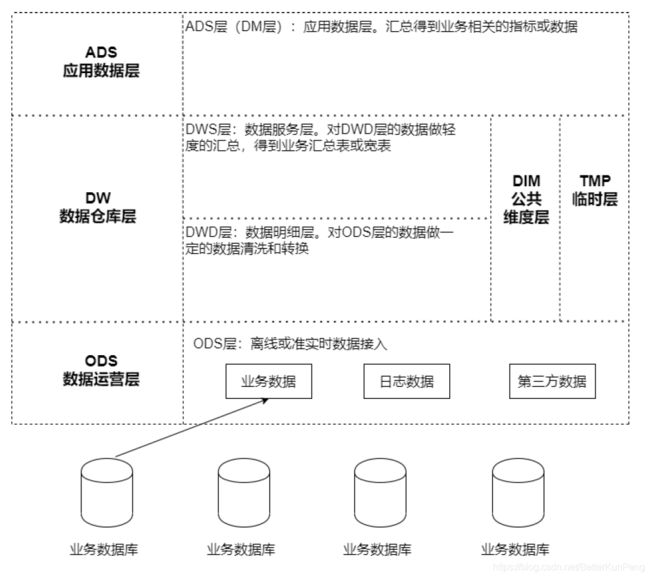
ODS(Operation Data Store 数据准备区)。数据仓库源头系统的数据表通常会原封不动的存储一份,这称为ODS层,也称为准备区。它们是后续数据仓库层加工数据
的来源。ODS层数据的主要来源包括:
- 业务数据库。可使用DataX、Sqoop等工具来抽取,每天定时抽取一次;在实时应用中,可用Canal监听MySQL的 Binlog,实时接入变更的数据;
- 埋点日志。线上系统会打入各种日志,这些日志一般以文件的形式保存,可以Flume 定时抽取;
- 其他数据源。从第三方购买的数据、或是网络爬虫抓取的数据;
DW(Data Warehouse 数据仓库层)。包含DWD、DWS、DIM层,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
- DWD(Data Warehouse Detail 细节数据层),是业务层与数据仓库的隔离层。以业务过程作为建模驱动,基于每个具体的业务过程特点,构建细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,也即宽表化处理;
- DWS(Data Warehouse Service 服务数据层),基于DWD的基础数据,整合汇总成分析某一个主题域的服务数据。以分析的主题为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表;
- 公共维度层(DIM):基于维度建模理念思想,建立一致性维度;
- TMP层 :临时层,存放计算过程中临时产生的数据;
ADS(Application Data Store 应用数据层)。基于DW数据,整合汇总成主题域的服务数据,用于提供后续的业务查询等。数据仓库层次的划分不是固定不变的,可以根据实际需求进行适当裁剪或者是添加。如果业务相对简单和独立,可以将DWD、DWS进行合并。
第4节 数据仓库模型
4.1 事实表与维度表
在数据仓库中,保存度量值的详细值或事实的表称为事实表。
事实数据表通常包含大量的行。事实数据表的主要特点是包含数字数据(事实),并且这些数字信息可以汇总,以提供有关单位作为历史的数据。事实表的粒度决定了数
据仓库中数据的详细程度。
常见事实表:订单事实表
事实表的特点:表多(各种各样的事实表);数据量大
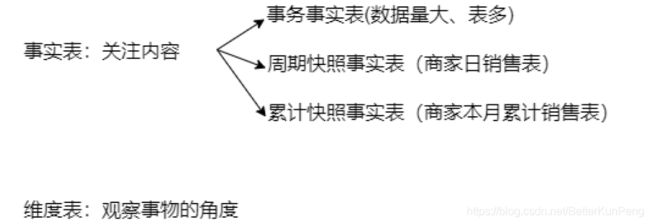
事实表根据数据的粒度可以分为:事务事实表、周期快照事实表、累计快照事实表
维度表(维表)可以看作是用来分析数据的角度,纬度表中包含事实数据表中事实记录的特性。有些特性提供描述性信息,有些特性指定如何汇总事实数据表数据,以便为分析者提供有用的信息。
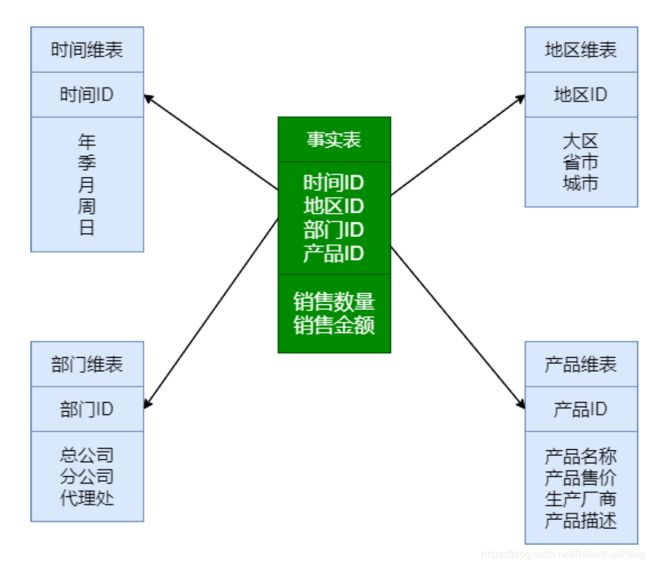
常见维度表:时间维度、地域维度、商品维度
小结:
- 事实表是关注的内容(如:销售额、销售量)
- 维表是观察事务的角度
4.2 事实表分类
1、事务事实表
事务事实表记录的事务层面的事实,保存的是最原子的数据,也称“原子事实表”。事务事实表中的数据在事务事件发生后产生,数据的粒度通常是每个事务一条记录。一旦事务被提交,事实表数据被插入,数据就不再进行更改,其更新方式为增量更新。事务事实表的日期维度记录的是事务发生的日期,它记录的事实是事务活动的内容。用户可以通过事务事实表对事务行为进行特别详细的分析。
如:订单表通过事务事实表,还可以建立聚集事实表,为用户提供高性能的分析。
2、周期快照事实表
周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,时间间隔如每天、每月、每年等等。典型的例子如销售日快照表、库存日快照表等。它统计的是间隔周期内的度量统计,如历史至今、自然年至今、季度至今等等。周期快照事实表的粒度是每个时间段一条记录,通常比事务事实表的粒度要粗,是在事务事实表之上建立的聚集表。周期快照事实表的维度个数比事务事实表要少,但是记录的事实要比事务事实表多。
如:商家日销售表(无论当天是否有销售发生,都记录一行)日期、商家名称、销售量、销售额
3、累积快照事实表
累积快照事实表和周期快照事实表有些相似之处,它们存储的都是事务数据的快照信息。但是它们之间也有着不同,周期快照事实表记录的确定的周期的数据,而累积快
照事实表记录的不确定的周期的数据。累积快照事实表代表的是完全覆盖一个事务或产品的生命周期的时间跨度,它通常具有多个日期字段,用来记录整个生命周期中的关键时间点。另外,它还会有一个用于指示最后更新日期的附加日期字段。由于事实表中许多日期在首次加载时是不知道的,所以必须使用代理关键字来处理未定义的日期,而且这类事实表在数据加载完后,是可以对它进行更新的,来补充随后知道的日期信息。
如:订货日期、预定交货日期、实际发货日期、实际交货日期、数量、金额、运费
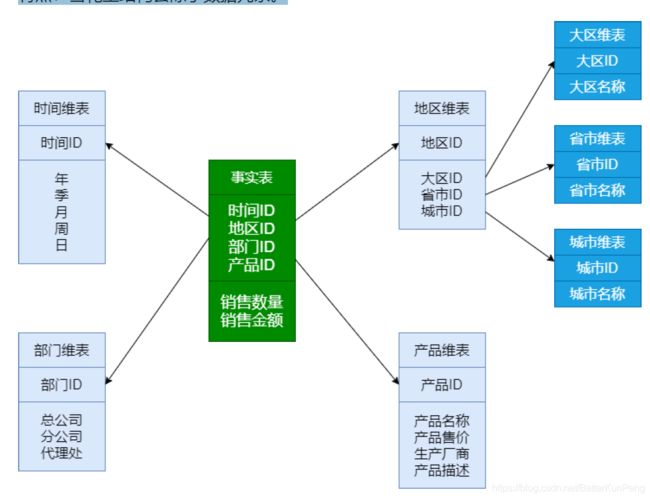
4.3 星型模型
星型模是一种多维的数据关系,它由一个事实表和一组维表组成;
事实表在中心,周围围绕地连接着维表;
事实表中包含了大量数据,没有数据冗余;
维表是逆规范化的,包含一定的数据冗余;
4.4 雪花模型
雪花模式是星型模型的变种,维表是规范化的,模型类似雪花的形状;
特点:雪花型结构去除了数据冗余。
星型模型存在数据冗余,所以在查询统计时只需要做少量的表连接,查询效率高;
星型模型不考虑维表正规化的因素,设计、实现容易;
在数据冗余可接受的情况下,实际上使用星型模型比较多;
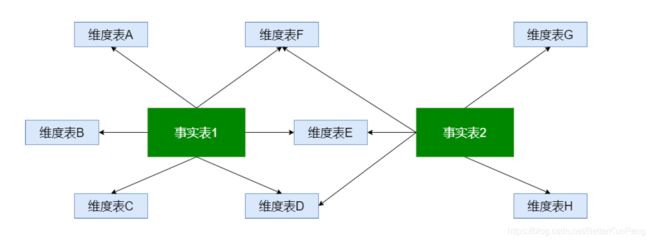
4.5 事实星座
数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享,这种模式
可以看做星型模式的汇集,因而称作星系模式或者事实星座模式。
特点:公用维表
第5节 元数据
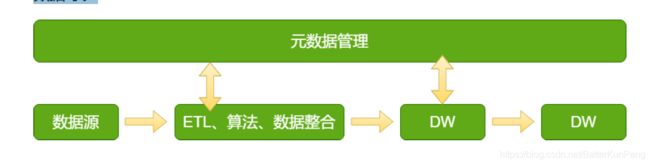
元数据(Metadata)是关于数据的数据。元数据打通了源数据、数据仓库、数据应用,记录了数据从产生到消费的全过程。元数据就相当于所有数据的地图,有了这张
地图就能知道数据仓库中:
- 有哪些数据
- 数据的分布情况
- 数据类型
- 数据之间有什么关系
- 哪些数据经常被使用,哪些数据很少有人光顾
在大数据平台中,元数据贯穿大数据平台数据流动的全过程,主要包括数据源元数据、数据加工处理过程元数据、数据主题库专题库元数据、服务层元数据、应用层元数据等。
业内通常把元数据分为以下类型:
- 技术元数据:库表结构、数据模型、ETL程序、SQL程序等
- 业务元数据:业务指标、业务代码、业务术语等
- 管理元数据:数据所有者、数据质量、数据安全等
第二部分 电商离线数仓设计
第1节 需求分析
电商行业技术特点
- 技术新
- 技术范围广
- 分布式
- 高并发、集群、负载均衡
- 海量数据
- 业务复杂
- 系统安全
电商业务简介
类似X东商城、X猫商城。电商网站采用商家入驻的模式,商家入驻平台提交申请,有平台进行资质审核,审核通过后,商家拥有独立的管理后台录入商品信息。商品经
过平台审核后即可发布。网上商城主要分为:
- 网站前台。网站首页、商家首页、商品详细页、搜索页、会员中心、订单与支付相关页面、秒杀频道等;
- 运营商后台。运营人员的管理平台, 主要功能包括:商家审核、品牌管理、规格管理、模板管理、商品分类管理、商品审核、广告类型管理、广告管理、订单查询、商家结算等;
- 商家管理后台。入驻的商家进行管理的平台,主要功能包括:商品管理、订单查询统计、资金结算等功能;
数据仓库项目主要分析以下数据:
- 日志数据:启动日志、点击日志(广告点击日志)
- 业务数据库的交易数据:用户下单、提交订单、支付、退款等核心交易数据的分析
数据仓库项目分析任务:
会员活跃度分析主题
- 每日新增会员数;每日、周、月活跃会员数;留存会员数、留存会员率
广告业务分析主题
- 广告点击次数、广告点击购买率、广告曝光次数
核心交易分析主题
- 订单数、成交商品数、支付金额
第2节 数据埋点
数据埋点,将用户的浏览、点击事件采集上报的一套数据采集的方法。
通过这套方法,能够记录到用户在App、网页的一些行为,用来跟踪应用使用的状况,后续用来进一步优化产品或是提供运营的数据支撑,包括访问数、访客数、停留时长、浏览数、跳出率。这样的信息收集可以大致分为两种:页面统计、统计操作行为。
埋点为数据分析提供基础数据,埋点工作流程可分为:
- 根据埋点需求完成开发(前端开发工程师 js)
- App或网页采用用户数据
- 数据上报服务器
- 数据的清洗、加工、存储(大数据工程师)
- 进行数据分析等到相应的指标(大数据工程师)
在以上过程中,涉及的相关人员可分以下几类:
- 埋点需求:数据产品经理,负责撰写需求文档,规定哪些区域、用户操作需要埋点
- 埋点采集:前端工程师,负责通过一套前端 js 代码对用户的请求事件上送至服务器
- 数据清洗、加工及存储:对埋点中数据缺失、误报等情况需要进行清洗,并通过
- 一定的计算加工,输出业务分析所需要的结构化数据,最后将数据存储在数据仓库中
- 数据分析:在数据仓库中对数据进行整理,成业务关注的指标
- 前端展示:Java 开发
主流的埋点实现方法如下,主要区别是前端开发的工作量:
- 手动埋点:开发需要手动写代码实现埋点,比如页面ID、区域ID、按钮ID、按钮位置、事件类型(曝光、浏览、点击)等,一般需要公司自主研发的一套埋点框架
- 优点:埋点数据更加精准
- 缺点:工作量大,容易出错
- 无痕埋点:不用开发写代码实现的,自动将设备号、浏览器型号、设备类型等数据采集。主要使用第三方统计工具,如友盟、百度移动、魔方等
- 优点:简单便捷
- 缺点:埋点数据统一,不够个性化和精准
第3节 数据指标体系
指标:对数据的统计值。如:会员数、活跃会员数、会员留存数;广告点击量;订单金额、订单数都是指标;
指标体系:将各种指标系统的组织起来,按照业务模型、标准对指标进行分类和分层;
没有数据指标体系的团队内数据需求经常表现为需求膨胀以及非常多的需求变更。每个人都有看数据的视角和诉求,然后以非专业的方式创造维度/指标的数据口径。数据分析人员被海量的数据需求缠住,很难抽离出业务规则设计好的解决方案,最终滚雪球似的搭建难以维护的数据仓库。
建立指标体系实际上是与需求方达成一致。能有效遏制不靠谱的需求,让需求变得有条例和体系化;
指标体系是知道数据仓库建设的基石。稳定而且体系化的需求,有利于数据仓库方案的优化,和效率提升;
由产品经理牵头、与业务、IT方协助,制定的一套能从维度反应业务状况的一套待实施框架。在建立指标体系时,要注重三个选取原则:准确、可解释、结构性。
准确:核心数据一定要理解到位和准确,不能选错;
可解释:所有指标都要配上明确、详细的业务解释。如日活的定义是什么,是使用了App、还是在App中停留了一段时间、或是收藏或购买购买了商品;
第4节 总体架构设计
4.1、技术方案选型
框架选型
Apache / 第三方发行版(CDH / HDP / Fusion Insight)
Apache社区版本优点:
- 完全开源免费
- 社区活跃
- 文档、资料详实
缺点:
- 复杂的版本管理
- 复杂的集群安装
- 复杂的集群运维
- 复杂的生态环境
第三方发行版本(CDH / HDP / Fusion Insight)
Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop。正因如此,市面上有很多厂家在Apache Hadoop的基础上开发自己的产品。如Cloudera的
CDH,Hortonworks的HDP,华为的Fusion Insight等。这些产品的优点是:
- 主要功能与社区版一致
- 版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4等,后面加上补丁版本,如CDH4.1.0 patch level 923.142
- 比 Apache Hadoop 在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运用到各种生产环境
- 版本更新快。如CDH每个季度会有一个update,每一年会有一个release
- 基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch
- 提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群
- 运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效
CDH:最成型的发行版本,拥有最多的部署案例。提供强大的部署、管理和监控工具。国内使用最多的版本;拥有强大的社区支持,当遇到问题时,能够通过社区、论坛等网络资源快速获取解决方法;
HDP:100%开源,可以进行二次开发,但没有CDH稳定。国内使用相对较少;
Fusion Insight:华为基于hadoop2.7.2版开发的,坚持分层,解耦,开放的原则,得益于高可靠性,在全国各地政府、运营商、金融系统有较多案例。
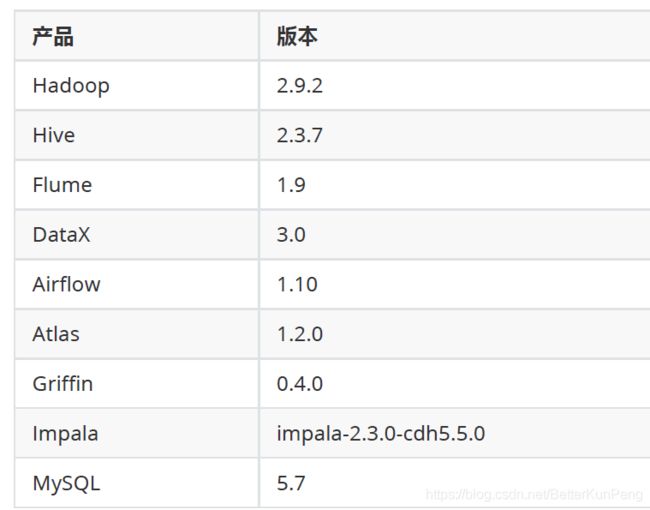
软件选型
数据采集:DataX、Flume、Sqoop、Logstash、Kafka
数据存储:HDFS、HBase
数据计算:Hive、MapReduce、Tez、Spark、Flink
调度系统:Airflow、azkaban、Oozie
元数据管理:Atlas
数据质量管理:Griffin
即席查询:Impala、Kylin、ClickHouse、Presto、Druid
其他:MySQL
框架、软件尽量不要选择最新的版本,选择半年前左右稳定的版本。
服务器选型
选择物理机还是云主机
机器成本考虑:物理机的价格 > 云主机的价格
运维成本考虑:物理机需要有专业的运维人员;云主机的运维工作由供应商完成,运维相对容易,成本相对较低;
集群规模规划
如何确认集群规模(假设:每台服务器20T硬盘,128G内存)
可以从计算能力(CPU、 内存)、存储量等方面着手考虑集群规模。
假设:
1、每天的日活用户500万,平均每人每天有100条日志信息
2、每条日志大小1K左右
3、不考虑历史数据,半年集群不扩容
4、数据3个副本
5、离线数据仓库应用
需要多大集群规模?
要分析的数据有两部分:日志数据+业务数据
每天日志数据量:500W * 100 * 1K / 1024 / 1024 = 500G
半年需要的存储量:500G * 3 * 180 / 1024 = 260T
通常要给磁盘预留20-30%的空间(这里取25%): 260 * 1.25 = 325T
数据仓库应用有1-2倍的数据膨胀(这里取1.5):500T
需要大约25个节点
其他未考虑因素:数据压缩、业务数据
以上估算的生产环境。实际上除了生产环境以外,还需要开发测试环境,这也需要一定数据的机器。
4.2、系统逻辑架构
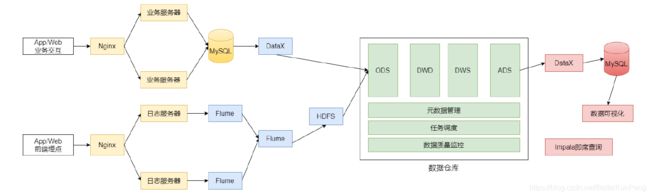
4.3、开发物理环境
5台物理机;1 500G数据盘;32G内存;8个core
4.4、数据仓库命名规范

创建数据库:
create database if not exists ods;
create database if not exists dwd;
create database if not exists dws;
create database if not exists ads;
create database if not exists dim;
create database if not exists tmp;第三部分 电商分析之--会员活跃度
第1节 需求分析
会员数据是后期营销的很重要的数据。网店会专门针对会员进行一系列营销活动。
电商会员一般门槛较低,注册网站即可加入。有些电商平台的高级会员具有时效性,
需要购买VIP会员卡或一年内消费额达到多少才能成为高级会员。
计算指标:
新增会员:每日新增会员数
活跃会员:每日,每周,每月的活跃会员数
会员留存:1日,2日,3日会员留存数、1日,2日,3日会员留存率
指标口径业务逻辑:
会员:以设备为判断标准,每个独立设备认为是一个会员。Android系统通常根据IMEI号,IOS系统通常根据OpenUDID 来标识一个独立会员,每部移动设备是一个会员;
活跃会员:打开应用的会员即为活跃会员,暂不考虑用户的实际使用情况。一台设备每天多次打开计算为一个活跃会员。在自然周内启动过应用的会员为周活跃会员,同
理还有月活跃会员;
会员活跃率:一天内活跃会员数与总会员数的比率是日活跃率;还有周活跃率(自然周)、月活跃率(自然月);
新增会员:第一次使用应用的用户,定义为新增会员;卸载再次安装的设备,不会被算作一次新增。新增用户包括日新增会员、周(自然周)新增会员、月(自然月)新增会员;
留存会员与留存率:某段时间的新增会员,经过一段时间后,仍继续使用应用认为是
留存会员;这部分会员占当时新增会员的比例为留存率。
已知条件:
- 1、明确了需求
- 2、输入:启动日志(OK)、事件日志
- 3、输出:新增会员、活跃会员、留存会员
- 4、日志文件、ODS、DWD、DWS、ADS(输出)
下一步作什么?
数据采集:日志文件 => Flume => HDFS => ODS
第2节 日志数据采集
原始日志数据(一条启动日志)
数据采集的流程:
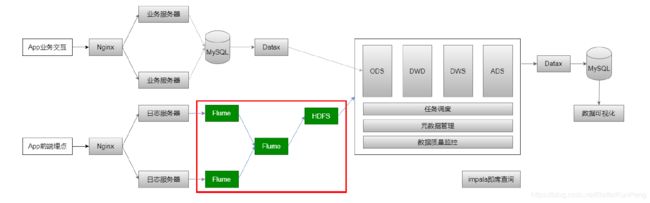
选择Flume作为采集日志数据的工具:
Flume 1.6
无论是Spooling Directory Source、Exec Source均不能很好的满足动态实
时收集的需求
Flume 1.8+
2.1、taildir source配置
taildir Source的特点:
- 使用正则表达式匹配目录中的文件名
- 监控的文件中,一旦有数据写入,Flume就会将信息写入到指定的Sink
- 高可靠,不会丢失数据
- 不会对跟踪文件有任何处理,不会重命名也不会删除
- 不支持Windows,不能读二进制文件。支持按行读取文本文件
taildir source配置
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile =
/data/lagoudw/conf/startlog_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/lagoudw/logs/start/.*logpositionFile
- 配置检查点文件的路径,检查点文件会以 json 格式保存已经读取文件的位置,解决断点续传的问题
filegroups
- 指定filegroups,可以有多个,以空格分隔(taildir source可同时监控多个目录中的文件)
filegroups.
- 配置每个filegroup的文件绝对路径,文件名可以用正则表达式匹配
2.2、hdfs sink配置
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/start/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# 配置文件滚动方式(文件大小32M)
a1.sinks.k1.hdfs.rollSize = 33554432
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 100
# 使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp = trueHDFS Sink 都会采用滚动生成文件的方式,滚动生成文件的策略有:
- 基于时间。hdfs.rollInterval 30秒
- 基于文件大小。hdfs.rollSize 1024字节
- 基于event数量。hdfs.rollCount 10个event
- 基于文件空闲时间。hdfs.idleTimeout 0 ,0,禁用
- minBlockReplicas。默认值与 hdfs 副本数一致。设为1是为了让 Flume 感知不到hdfs的块复制,此时其他的滚动方式配置(时间间隔、文件大小、events数量)才不会受影响
2.3、Agent的配置
/data/lagoudw/conf/flume-log2hdfs1.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# taildir source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile =
/data/lagoudw/conf/startlog_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/lagoudw/logs/start/.*log
# memorychannel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 2000
# hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/start/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# 配置文件滚动方式(文件大小32M)
a1.sinks.k1.hdfs.rollSize = 33554432
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 1000
# 使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c12.4、Flume的优化配置
1、启动agent
flume-ng agent --conf-file /data/lagoudw/conf/flumelog2hdfs1.conf -name a1 -Dflume.roog.logger=INFO,console2、向 /data/lagoudw/logs/ 目录中放入日志文件,报错:
java.lang.OutOfMemoryError: GC overhead limit exceeded缺省情况下 Flume jvm堆最大分配20m,这个值太小,需要调整。
缺省情况下 Flume jvm堆最大分配20m,这个值太小,需要调整。
3、解决方案:在 $FLUME_HOME/conf/flume-env.sh 中增加以下内容
export JAVA_OPTS="-Xms4000m -Xmx4000m -
Dcom.sun.management.jmxremote"
# 要想使配置文件生效,还要在命令行中指定配置文件目录
flume-ng agent --conf /opt/apps/flume-1.9/conf --conf-file
/data/lagoudw/conf/flume-log2hdfs1.conf -name a1 -
Dflume.roog.logger=INFO,console
flume-ng agent --conf-file /data/lagoudw/conf/flumelog2hdfs1.
conf -name a1 -Dflume.roog.logger=INFO,consoleFlume内存参数设置及优化:
根据日志数据量的大小,Jvm堆一般要设置为4G或更高
-Xms -Xmx 最好设置一致,减少内存抖动带来的性能影响
存在的问题:Flume放数据时,使用本地时间;不理会日志的时间戳
2.5、自定义拦截器
前面 Flume Agent 的配置使用了本地时间,可能导致数据存放的路径不正确。
要解决以上问题需要使用自定义拦截器。
agent用于测试自定义拦截器。netcat source =>logger sink
/data/lagoudw/conf/flumetest1.conf
# a1是agent的名称。source、channel、sink的名称分别为:r1 c1 k1
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop2
a1.sources.r1.port = 9999
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type =
cn.lagou.dw.flume.interceptor.CustomerInterceptor$Builder
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100
# sink
a1.sinks.k1.type = logger
# source、channel、sink之间的关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1自定义拦截器的原理:
1、自定义拦截器要集成Flume 的 Interceptor
2、Event 分为header 和 body(接收的字符串)
3、获取header和body
4、从body中获取"time":1596382570539,并将时间戳转换为字符串 "yyyy-MMdd"
5、将转换后的字符串放置header中
自定义拦截器的实现:
1、获取 event 的 header
2、获取 event 的 body
3、解析body获取json串
4、解析json串获取时间戳
5、将时间戳转换为字符串 "yyyy-MM-dd"
6、将转换后的字符串放置header中
7、返回event
package lagou.dw.flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.compress.utils.Charsets;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.interceptor.Interceptor;
import org.junit.Test;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class CustomerInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
//处理event事件
public Event intercept(Event event) {
//获取event的body
String eventBody = new String(event.getBody(), Charsets.UTF_8);
//获取event的header
Map headerMap = event.getHeaders();
//解析body获得json串
String[] bodyArr = eventBody.split("\\s+");
try{
String jsonStr = bodyArr[6];
//解析json串获得时间戳
JSONObject jsonObject = JSON.parseObject(jsonStr);
String timeStampStr ="";
//取启动日志的时间戳
if(headerMap.getOrDefault("logtype","").equals("start")){
timeStampStr = jsonObject.getJSONObject("app_active").getString("time");
}
//取事件日志第一条记录的时间戳
else if (headerMap.getOrDefault("logtype","").equals("event")){
JSONArray jsonArray = jsonObject.getJSONArray("lagou_event");
if (jsonArray.size()>0){
timeStampStr = jsonArray.getJSONObject(0).getString("time");
}
}
//将时间戳转换为字符串
//将字符串转换为Long
long timestamp = Long.parseLong(timeStampStr);
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
Instant instant = Instant.ofEpochMilli(timestamp);
LocalDateTime localDateTime = LocalDateTime.ofInstant(instant, ZoneId.systemDefault());
String date = dateTimeFormatter.format(localDateTime);
//将转换后的字符串放到header中
headerMap.put("logtime",date);
event.setHeaders(headerMap);
} catch (Exception e) {
headerMap.put("logtime","unknown");
event.setHeaders(headerMap);
}
return event;
}
@Override
public List intercept(List list) {
List listEvent = new ArrayList<>();
for (Event event:list) {
Event outEvent = intercept(event);
if(outEvent != null){
listEvent.add(outEvent);
}
}
return listEvent;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new CustomerInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Test
public void testJunit(){
String str = "2020-08-20 11:56:00.470 [main] INFO com.lagou.ecommerce.AppStart - {\"app_active\":{\"name\":\"app_active\",\"json\":{\"entry\":\"1\",\"action\":\"0\",\"error_code\":\"0\"},\"time\":1595317514407},\"attr\":{\"area\":\"苏州\",\"uid\":\"2F10092A350\",\"app_v\":\"1.1.19\",\"event_type\":\"common\",\"device_id\":\"1FB872-9A100350\",\"os_type\":\"9.5.0\",\"channel\":\"OH\",\"language\":\"chinese\",\"brand\":\"xiaomi-3\"}}";
Map map = new HashMap<>();
// new Event
Event event = new SimpleEvent();
map.put("logtype", "start");
event.setHeaders(map);
event.setBody(str.getBytes(Charsets.UTF_8));
// 调用interceptor处理event
CustomerInterceptor customerInterceptor = new CustomerInterceptor();
Event outEvent = customerInterceptor.intercept(event);
// 处理结果
Map headersMap = outEvent.getHeaders();
System.out.println(JSON.toJSONString(headersMap));
}
}