DataX从入门实战到精通一文搞定
1、概述
1.1、什么是 DataX
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
1.2、DataX 的设计
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到 DataX,便能跟已有的数据源做到无缝数据同步。
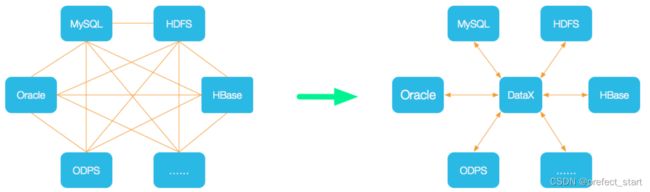
1.3、支持的数据源
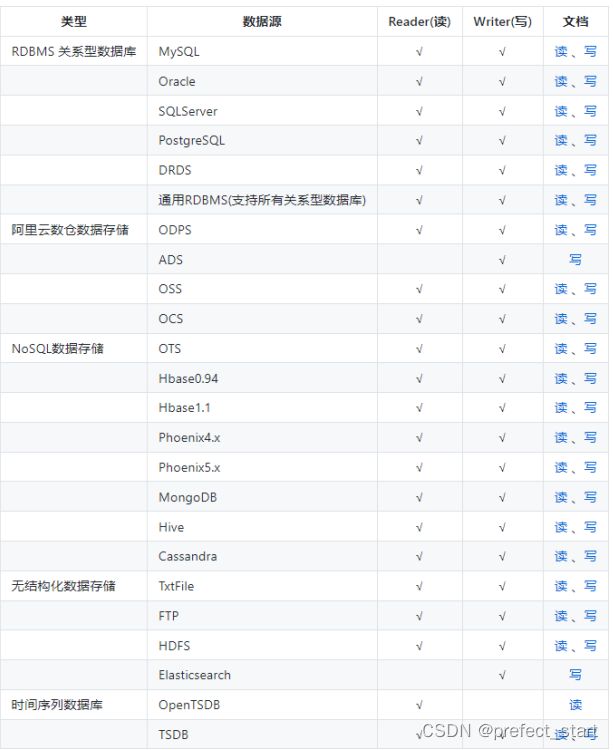
DataX 目前已经有了比较全面的插件体系,主流的 RDBMS 数据库、NOSQL、大数据计算系统都已经接入。
1.4、框架设计

- Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
1.5、运行原理
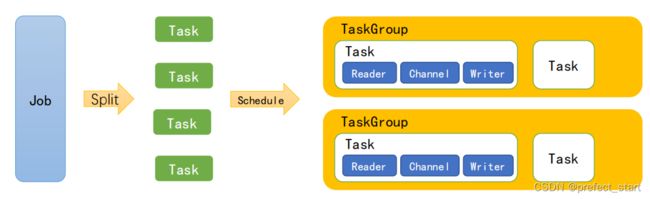
- Job:单个作业的管理节点,负责数据清理、子任务划分、TaskGroup监控管理。
- Task:由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- Schedule:将Task组成TaskGroup,单个TaskGroup的并发数量为5。
- TaskGroup:负责启动Task。
举例来说,用户提交了一个 DataX 作业,并且配置了 20 个并发,目的是将一个 100 张分表的 mysql 数据同步到 odps 里面。 DataX 的调度决策思路是:
- DataXJob 根据分库分表切分成了 100 个 Task。
- 根据 20 个并发,DataX 计算共需要分配 4 个 TaskGroup。
- 个 TaskGroup 平分切分好的 100 个 Task,每一个 TaskGroup 负责以 5 个并发共计运行 25 个 Task。
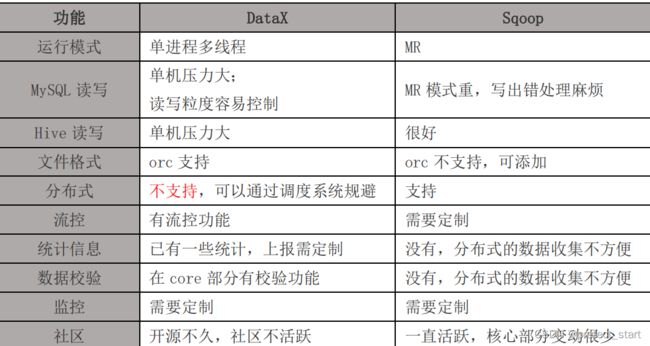
1.6、与 Sqoop 的对比
2、快速入门
2.1、官方地址
下载地址:
添源码地址:
2.2、前置要求
- Linux
- JDK(1.8 以上,推荐 1.8)
- Python(推荐 Python2.6.X)
2.3、安装
- 将下载好的 datax.tar.gz 上传到 hadoop102 的/opt/software
- 解压 datax.tar.gz 到/opt/model
[song@hadoop102 software]$ tar -zxvf datax.tar.gz -C /opt/model/
- 运行自检脚本
[song@hadoop102 bin]$ cd /opt/model/datax/bin/
[song@hadoop102 bin]$ python datax.py /opt/model/datax/job/job.json

3、Mysql使用案例
3.1、从 stream 流读取数据并打印到控制台
- 查看配置模板
The di[song@hadoop102 bin]$ python datax.py -r streamreader -w streamwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
- 根据模板编写配置文件
[song@hadoop102 job]$ vim stream2stream.json
- 填写以下内容:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
- 运行
[song@hadoop102 job]$ /opt/module/datax/bin/datax.py /opt/module/datax/job/stream2stream.json
3.2、读取 MySQL 中的数据存放到 HDFS
3.2.1、查看官方模板
[song@hadoop102 ~]$ python /opt/module/datax/bin/datax.py -r mysqlreader -w hdfswriter
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
- mysqlreader 参数解析:

- hdfswriter 参数解析:

3.2.2、准备数据
- 创建 student 表
mysql> create database datax;
mysql> use datax;
mysql> create table student(id int,name varchar(20));
- 插入数据
mysql> insert into student values(1001,'zhangsan'),(1002,'lisi'),(1003,'wangwu');
3.2.3、编写配置文件
[song@hadoop102 datax]$ vim /opt/module/datax/job/mysql2hdfs.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/datax"
],
"table": [
"student"
]
}
],
"username": "root",
"password": "xxxxxx"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "student.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
3.2.4、执行任务
[song@hadoop102 datax]$ bin/datax.py job/mysql2hdfs.json
2019-05-17 16:02:16.581 [job-0] INFO JobContainer -
任务启动时刻 : 2019-05-17 16:02:04
任务结束时刻 : 2019-05-17 16:02:16
任务总计耗时 : 12s
任务平均流量 : 3B/s
记录写入速度 : 0rec/s
读出记录总数 : 3
读写失败总数 : 0
3.2.5、查看 hdfs
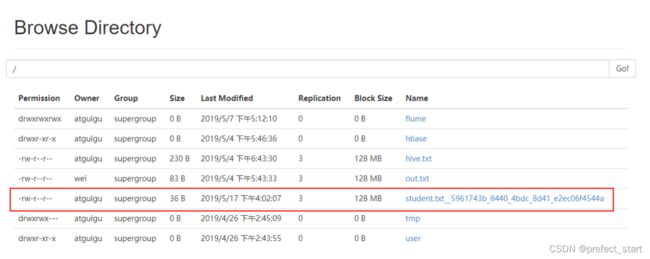
注意:HdfsWriter 实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名。
3.2.6、关于 HA 的支持
"hadoopConfig":{
"dfs.nameservices": "ns",
"dfs.ha.namenodes.ns": "nn1,nn2",
"dfs.namenode.rpc-address.ns.nn1": "主机名:端口",
"dfs.namenode.rpc-address.ns.nn2": "主机名:端口",
"dfs.client.failover.proxy.provider.ns": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
3.3、读取 HDFS 数据写入 MySQL
- 将上个案例上传的文件改名
[song@hadoop102 datax]$ hadoop fs -mv /student.txt* /student.txt
- 查看官方模板
[song@hadoop102 datax]$ python bin/datax.py -r hdfsreader -w mysqlwriter
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [],
"defaultFS": "",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileType": "orc",
"path": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
- 创建配置文件
[song@hadoop102 datax]$ vim job/hdfs2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [
"*"
],
"defaultFS": "hdfs://hadoop102:9000",
"encoding": "UTF-8",
"fieldDelimiter": "\t",
"fileType": "text",
"path": "/student.txt"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": [
"student2"
]
}
],
"password": "xxxxxx",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
- 在 MySQL 的 datax 数据库中创建 student2
mysql> use datax;
mysql> create table student2(id int,name varchar(20));
- 执行任务
[song@hadoop102 datax]$ bin/datax.py job/hdfs2mysql.json
任务启动时刻 : 2019-05-17 16:21:41
任务结束时刻 : 2019-05-17 16:21:53
任务总计耗时 : 11s
任务平均流量 : 3B/s
记录写入速度 : 0rec/s
读出记录总数 : 3
读写失败总数 : 0
- 查看 student2 表
mysql> select * from student2;
+------+----------+
| id | name |
+------+----------+
| 1001 | zhangsan |
| 1002 | lisi |
| 1003 | wangwu |
+------+----------+
3 rows in set (0.00 sec)
4、Oracle 数据库
4.1、oracle 数据库简介
Oracle Database,又名 Oracle RDBMS,或简称 Oracle。是甲骨文公司的一款关系数据库管理系统。它是在数据库领域一直处于领先地位的产品。可以说 Oracle 数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。它是一种高效率、可靠性好的、适应高吞吐量的数据库解决方案。
4.2、安装前的准备
4.2.1、安装依赖
yum install -y bc binutils compat-libcap1 compat-libstdc++33 elfutils-libelf elfutils-libelf-devel fontconfig-devel
glibc glibc-devel ksh libaio libaio-devel libX11 libXau libXi libXtst libXrender libXrender-devel libgcc libstdc++ libstdc++-
devel libxcb make smartmontools sysstat kmod* gcc-c++ compat-libstdc++-33
4.2.2、配置用户组
Oracle 安装文件不允许通过 root 用户启动,需要为 oracle 配置一个专门的用户。
- 创建 sql 用户组
[root@hadoop102 software]#groupadd sql
- 创建 oracle 用户并放入 sql 组中
[root@hadoop102 software]#useradd oracle -g sql
- 修改 oracle 用户登录密码,输入密码后即可使用 oracle 用户登录系统
[root@hadoop102 software]#passwd oracle
4.2.3、上传安装包并解压
注意:19c 需要把软件包直接解压到 ORACLE_HOME 的目录下
[root@hadoop102 software]# mkdir -p /home/oracle/app/oracle/product/19.3.0/dbhome_1
[root@hadoop102 software]# unzip LINUX.X64_193000_db_home.zip -d /home/oracle/app/oracle/product/19.3.0/dbhome_1
修改所属用户和组
[root@hadoop102 dbhome_1]# chown -R oracle:sql /home/oracle/app/
4.2.4、修改配置文件 sysctl.conf
[root@hadoop102 module]# vim /etc/sysctl.conf
删除里面的内容,添加如下内容:
net.ipv4.ip_local_port_range = 9000 65500
fs.file-max = 6815744
kernel.shmall = 10523004
kernel.shmmax = 6465333657
kernel.shmmni = 4096
kernel.sem = 250 32000 100 128
net.core.rmem_default=262144
net.core.wmem_default=262144
net.core.rmem_max=4194304
net.core.wmem_max=1048576
fs.aio-max-nr = 1048576
参数解析:
- net.ipv4.ip_local_port_range :可使用的 IPv4 端口范围
- fs.file-max :该参数表示文件句柄的最大数量。文件句柄设置表示在 linux 系统中可以打开的文件数量。
- kernel.shmall :该参数表示系统一次可以使用的共享内存总量(以页为单位)
- kernel.shmmax :该参数定义了共享内存段的最大尺寸(以字节为单位)
- kernel.shmmni :这个内核参数用于设置系统范围内共享内存段的最大数量
- kernel.sem : 该参数表示设置的信号量。
- net.core.rmem_default:默认的 TCP 数据接收窗口大小(字节)。
- net.core.wmem_default:默认的 TCP 数据发送窗口大小(字节)。
- net.core.rmem_max:最大的 TCP 数据接收窗口(字节)。
- net.core.wmem_max:最大的 TCP 数据发送窗口(字节)。
- fs.aio-max-nr :同时可以拥有的的异步 IO 请求数目。
4.2.5、修改配置文件 limits.conf
[root@hadoop102 module]# vim /etc/security/limits.conf
在文件末尾添加:
oracle soft nproc 2047
oracle hard nproc 16384
oracle soft nofile 1024
oracle hard nofile 65536
重启机器生效。
4.3、安装 Oracle 数据库
4.3.1、设置环境变量
[oracle@hadoop102 dbhome_1]# vim /home/oracle/.bash_profile
添加:
#ORACLE_HOME
export ORACLE_BASE=/home/oracle/app/oracle
export ORACLE_HOME=/home/oracle/app/oracle/product/19.3.0/dbhome_1
export PATH=$PATH:$ORACLE_HOME/bin
export ORACLE_SID=orcl
export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
[oracle@hadoop102 ~]$ source /home/oracle/.bash_profile
4.3.2、进入虚拟机图像化页面操作
[oracle@hadoop102 ~]# cd /opt/module/oracle
[oracle@hadoop102 database]# ./runInstaller
4.3.3、安装数据库
- 选择仅安装数据库软件

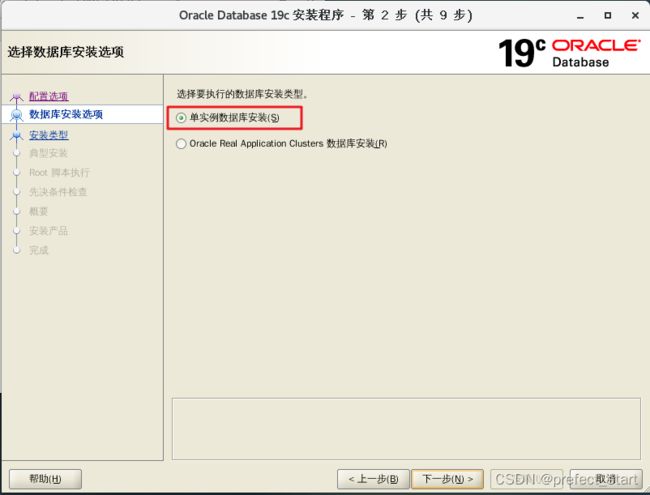
-
选择单实例数据库安装
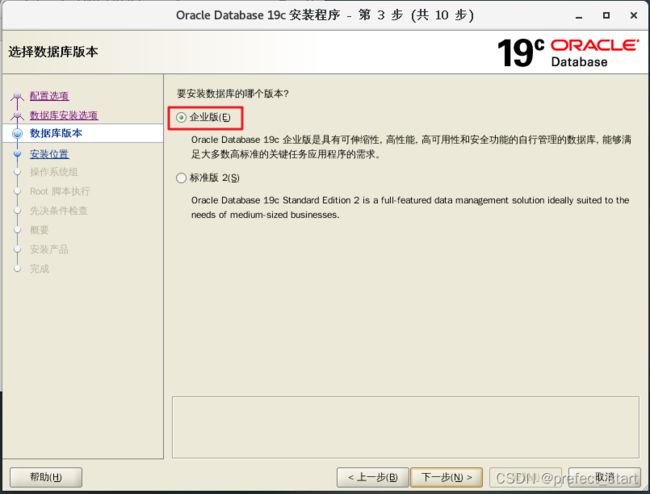
-
选择企业版,默认
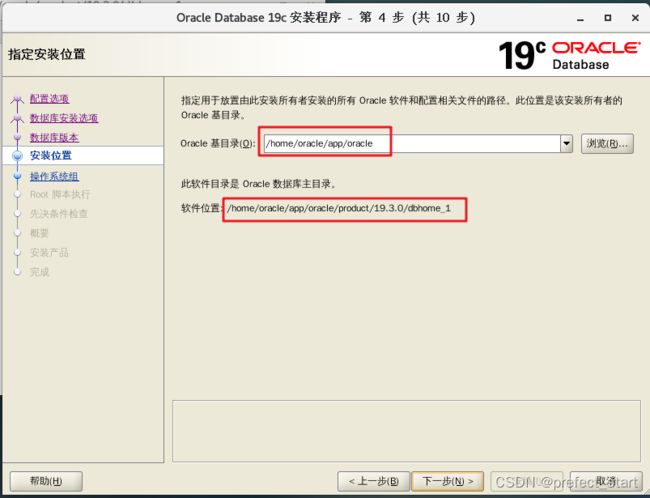
-
设置安装位置
-
操作系统组设置
-
配置 root 脚本自动执行
-
条件检查通过后,选择开始安装
-
运行 root 脚本

-
安装完成
4.4、设置 Oracle 监听
4.4.1、命令行输入以下命令
4.4.2、选择添加
4.4.3、设置监听名,默认即可
4.4.4、选择协议,默认即可
4.4.5、设置端口号,默认即可
4.4.6、配置更多监听,默认

4.4.7、完成

4.5、创建数据库
4.5.1、进入创建页面
[oracle@hadoop2 ~]$ dbca
4.5.2、选择创建数据库

4.5.3、选择高级配置

4.5.4、选择数据仓库
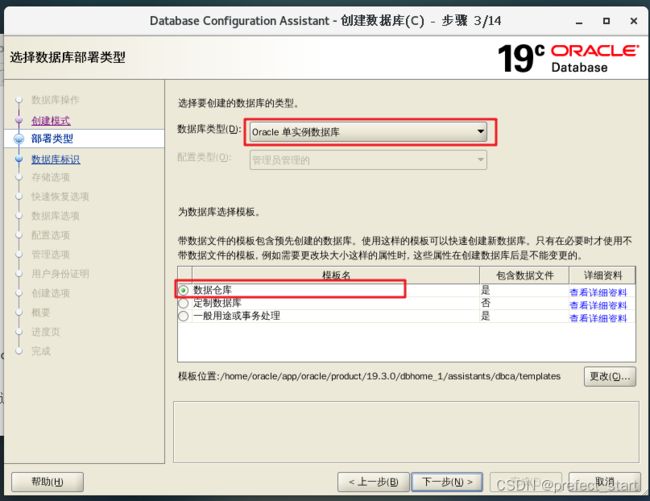
4.5.5、将图中所示对勾去掉
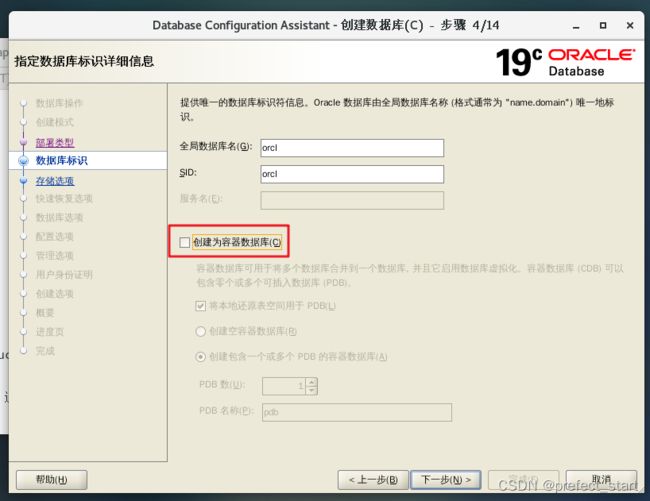
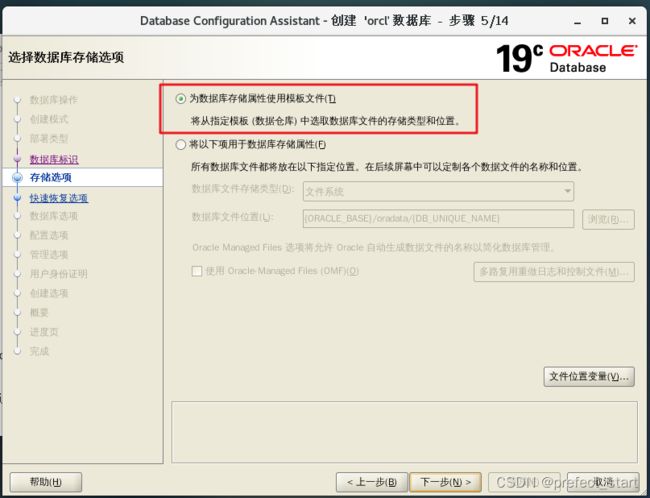
4.5.6、存储选项
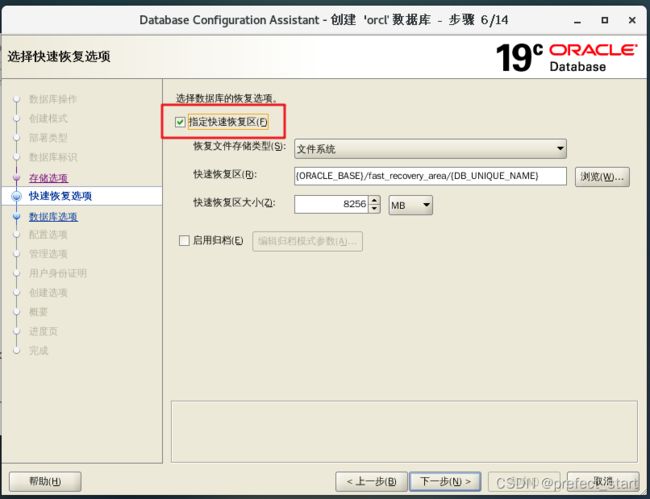
4.5.7、快速恢复选项
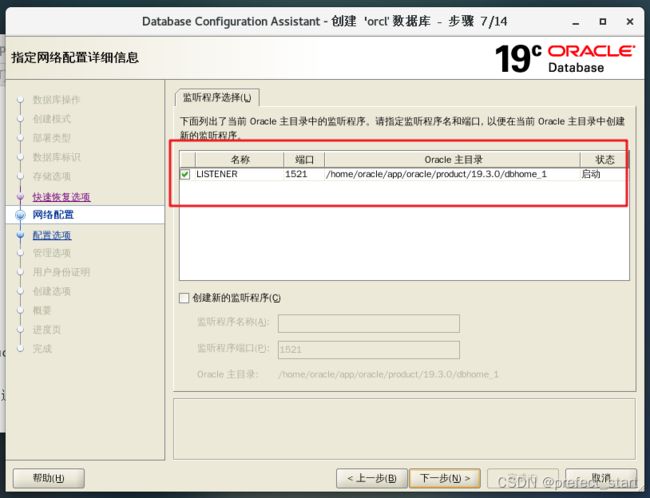
4.5.8、选择监听程序
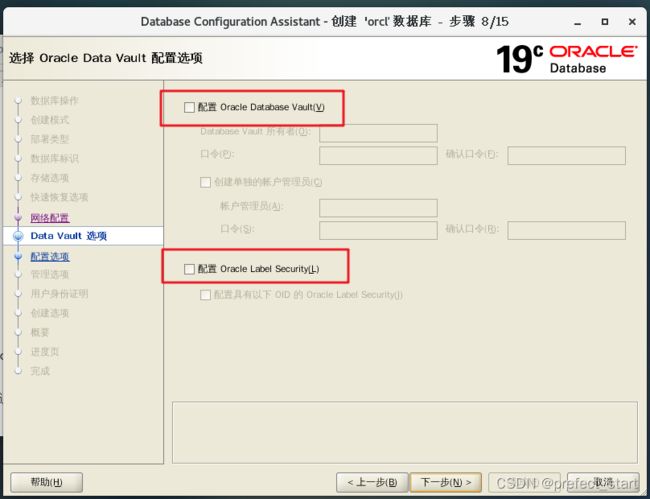
4.5.9、如图设置
4.5.10、使用自动内存管理
4.5.11、管理选项,默认

4.5.12、设置统一密码
4.5.13、创建选项,选择创建数据库
4.5.14、概要,点击完成
4.5.15、等待安装
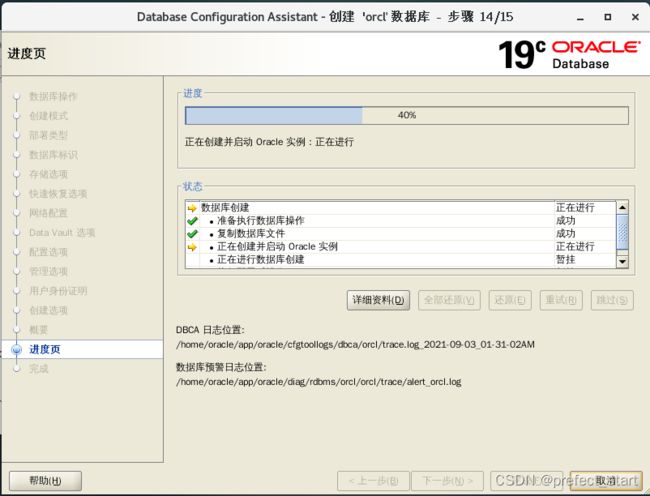

4.6、简单使用
4.6.1、开启,关闭监听服务
开启服务:
[oracle@hadoop102 ~]$ lsnrctl start
关闭服务:
[oracle@hadoop102 ~]$ lsnrctl stop
4.6.2、进入命令行
[oracle@hadoop102 ~]$ sqlplus
SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 3 01:44:30 2021
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Enter user-name: system
Enter password: (这里输入之前配置的统一密码)
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL>
4.6.3、创建用户并授权
SQL> create user song identified by 000000;
User created.
SQL> grant create session,create table,create view,create sequence,unlimited tablespace to song;
Grant succeeded.
4.6.4、进入 song 账号,创建表
SQL>create TABLE student(id INTEGER,name VARCHAR2(20));
SQL>insert into student values (1,'zhangsan');
SQL> select * from student;
ID NAME
---------- ----------------------------------------
1 zhangsan
注意:安装完成后重启机器可能出现 ORACLE not available 错误,解决方法如下:
[oracle@hadoop102 ~]$ sqlplus / as sysdba
SQL>startup
SQL>conn song
Enter password:
4.7、Oracle 与 MySQL 的 SQL 区别
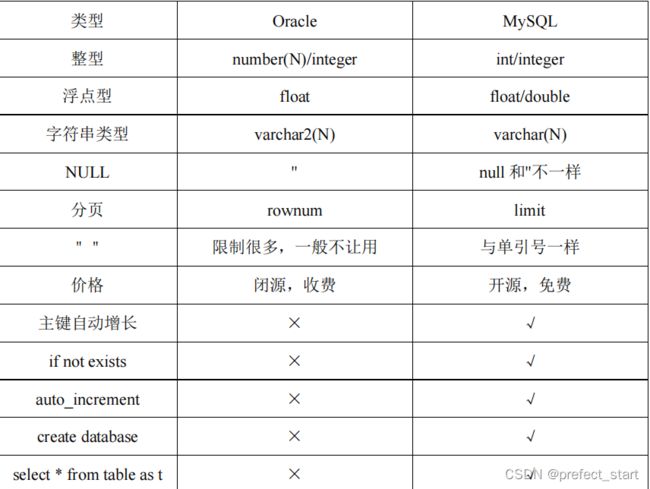
4.8、DataX 案例
4.8.1、从 Oracle 中读取数据存到 MySQL
- MySQL 中创建表
[oracle@hadoop102 ~]$ mysql -uroot -p000000
mysql> create database oracle;
mysql> use oracle;
mysql> create table student(id int,name varchar(20));
- 编写 datax 配置文件
[oracle@hadoop102 ~]$ vim /opt/module/datax/job/oracle2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": [
"*"
],
"connection": [
{
"jdbcUrl": [
"jdbc:oracle:thin:@hadoop102:1521:orcl"
],
"table": [
"student"
]
}
],
"password": "xxxxxx",
"username": "song"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"*"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/oracle",
"table": [
"student"
]
}
],
"password": "xxxxxx",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
- 执行命令
[oracle@hadoop102 ~]$ /opt/module/datax/bin/datax.py /opt/module/datax/job/oracle2mysql.json
查看结果:
mysql> select * from student;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
+------+----------+
4.8.2、读取 Oracle 的数据存入 HDFS 中
- 编写配置文件
[oracle@hadoop102 datax]$ vim job/oracle2hdfs.json
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": [
"*"
],
"connection": [
{
"jdbcUrl": [
"jdbc:oracle:thin:@hadoop102:1521:orcl"
],
"table": [
"student"
]
}
],
"password": "xxxxxx",
"username": "song"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "oracle.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
- 执行
[oracle@hadoop102 datax]$ bin/datax.py job/oracle2hdfs.json
- 查看 HDFS 结果
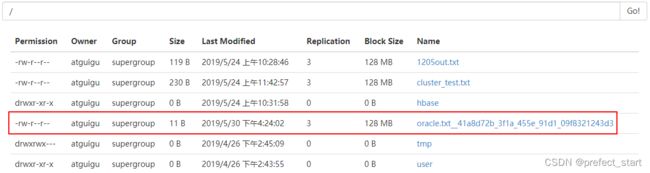
5、MongoDB
5.1、什么是 MongoDB
MongoDB 是由 C++语言编写的,是一个基于分布式文件存储的开源数据库系统。MongoDB 旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。

5.2、MongoDB 优缺点
优点:
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易;
- 内置GridFS,支持大容量的存储;
- 可以在MongoDB记录中设置任何属性的索引;
- MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言;
- 安装简单;
- 复制(复制集)和支持自动故障恢复;
- MapReduce 支持复杂聚合。
缺点:
- 不支持事务;
- 占用空间过大;
- 不能进行表关联;
- 复杂聚合操作通过MapReduce创建,速度慢;
- MongoDB 在你删除记录后不会在文件系统回收空间。除非你删掉数据库。
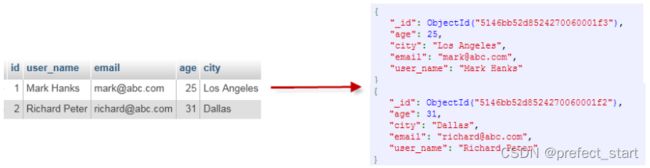
5.3、基础概念解析
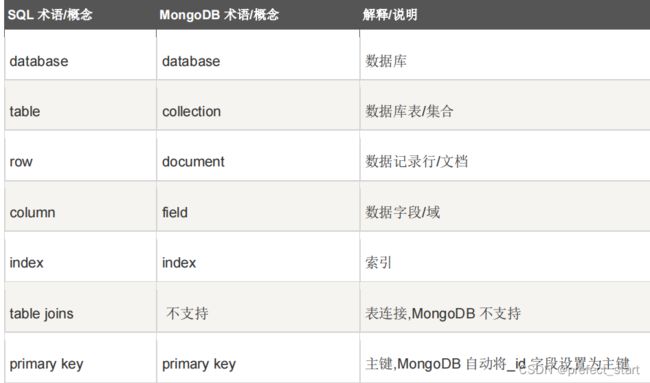
5.4、 安装
5.4.1、下载地址
5.4.2、安装
- 上传压缩包到虚拟机中,解压
[song@hadoop102 software]$ tar -zxvf mongodb-linux-x86_64-rhel70-5.0.2.tgz -C /opt/module/
- 重命名
[song@hadoop102 module]$ mv mongodb-linux-x86_64- rhel70-5.0.2/ mongodb
- 创建数据库目录
MongoDB 的数据存储在 data 目录的 db 目录下,但是这个目录在安装过程不会自动创建,所以需要手动创建 data 目录,并在 data 目录中创建 db 目录。
[song@hadoop102 module]$ sudo mkdir -p /data/db
[song@hadoop102 mongodb]$ sudo chmod 777 -R /data/db/
- 启动 MongoDB 服务
[song@hadoop102 mongodb]$ bin/mongod
- 进入 shell 页面
[song@hadoop102 mongodb]$ bin/mongo
5.5、基础概念详解
5.5.1、数据库
一个 mongodb 中可以建立多个数据库。MongoDB 的默认数据库为"db",该数据库存储在 data 目录中。MongoDB 的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
- 显示所有数据库
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
- admin:从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local:这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config:当 Mongo 用于分片设置时,config 数据库在内部使用,用于保存分片的相关信息。
- 显示当前使用的数据库
> db
test
- 切换数据库
> use local
switched to db local
> db
local
5.5.2、集合
集合就是 MongoDB 文档组,类似于 MySQL 中的 table。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
MongoDB 中使用 createCollection() 方法来创建集合。下面我们来看看如何创建集合:
语法格式:db.createCollection(name, options)
参数说明:
- name: 要创建的集合名称
- options: 可选参数, 指定有关内存大小及索引的选项,有以下参数:

- 案例1:在 test 库中创建一个 song的集合
> use test
switched to db test
> db.createCollection("song")
{ "ok" : 1 }
> show collections
song
//插入数据
> db.song.insert({"name":"song","url":"www.song.com"})
WriteResult({ "nInserted" : 1 })
//查看数据
> db.song.find()
{ "_id" : ObjectId("5d0314ceecb77ee2fb2d7566"), "name" : "song", "url" :
"www.song.com" }
说明:
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,由 24 个 16 进制数字组成的字符串(每个字节可以存储两个 16 进制数字),含义是:
- 前 4 个字节表示创建 unix 时间戳
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数
- 案例 2:创建一个固定集合 mycol
> db.createCollection("mycol",{ capped : true,autoIndexId : true,size : 6142800, max :
1000})
> show tables;
song
mycol
- 案例 3:自动创建集合在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
> db.mycol2.insert({"name":"song"})
WriteResult({ "nInserted" : 1 })
> show collections
song
mycol
mycol2
- 案例 4:删除集合
> db.mycol2.drop()
True
> show tables;
song
mycol
5.5.3、文档(Document)
文档是一组键值(key-value)对组成。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。一个简单的例子:{"name":"song"}
注意:
- 文档中的键/值对是有序的。
- MongoDB 区分类型和大小写。
- MongoDB 的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意 UTF-8 字符。
5.6、DataX 导入导出案例
5.6.1、读取 MongoDB 的数据导入到 HDFS
- 编写配置文件
[song@hadoop102 datax]$ vim job/mongdb2hdfs.json
{
"job": {
"content": [
{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": ["127.0.0.1:27017"],
"collectionName": "song",
"column": [
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"dbName": "test",
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "mongo.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
- mongodbreader 参数解析
- address: MongoDB 的数据地址信息,因为 MonogDB 可能是个集群,则 ip 端口信息需要以 Json 数组的形式给出。【必填】
- userName:MongoDB 的用户名。【选填】
- userPassword: MongoDB 的密码。【选填】
- collectionName: MonogoDB 的集合名。【必填】
- column:MongoDB 的文档列名。【必填】
- name:Column 的名字。【必填】
- type:Column 的类型。【选填】.
- splitter:因为 MongoDB 支持数组类型,但是 Datax 框架本身不支持数组类型,所以mongoDB 读出来的数组类型要通过这个分隔符合并成字符串。【选填】
- 执行
[song@hadoop102 datax]$ bin/datax.py job/mongdb2hdfs.json
- 查看结果
5.6.2、读取 MongoDB 的数据导入 MySQL
- 在 MySQL 中创建表
mysql> create table song(name varchar(20),url varchar(20));
- 编写 DataX 配置文件
[song@hadoop102 datax]$ vim job/mongodb2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": ["127.0.0.1:27017"],
"collectionName": "song",
"column": [
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"dbName": "test",
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/test",
"table": ["song"]
}
],
"password": "xxxxx",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
- 执行
[song@hadoop102 datax]$ bin/datax.py job/mongodb2mysql.json
- 查看结果
mysql> select * from song;
+---------+-----------------+
| name | url |
+---------+-----------------+
| song| www.song.com |
+---------+-----------------+
6、执行流程源码分析
6.1、 总体流程
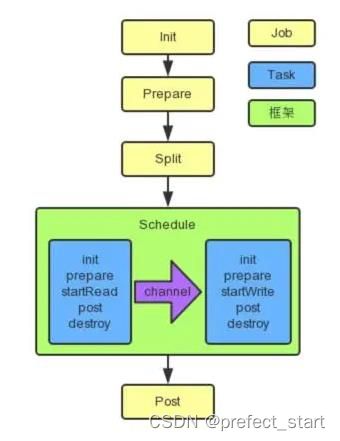
- 黄色: Job 部分的执行阶段,
- 蓝色: Task 部分的执行阶段,
- 绿色:框架执行阶段。
6.2、 程序入口
datax.py
……
ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params}
com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (
DEFAULT_PROPERTY_CONF, CLASS_PATH)
……
Engine.java
public void start(Configuration allConf) {
……
//JobContainer 会在 schedule 后再行进行设置和调整值
int channelNumber =0;
AbstractContainer container;
long instanceId;
int taskGroupId = -1;
if (isJob) {
allConf.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, RUNTIME_MODE);
container = new JobContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, 0);
} else {
container = new TaskGroupContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID);
taskGroupId = allConf.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_ID);
channelNumber = allConf.getInt(CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL);
}
……
container.start();
}
JobContainer.java
/**
* jobContainer 主要负责的工作全部在 start()里面,包括 init、prepare、split、 scheduler、
* post 以及 destroy 和 statistics
*/
@Override
public void start() {
LOG.info("DataX jobContainer starts job.");
boolean hasException = false;
boolean isDryRun = false;
try {
this.startTimeStamp = System.currentTimeMillis();
isDryRun = configuration.getBool(CoreConstant.DATAX_JOB_SETTING_DRYRUN, false);
if(isDryRun) {
LOG.info("jobContainer starts to do preCheck ...");
this.preCheck();
} else {
userConf = configuration.clone();
LOG.debug("jobContainer starts to do preHandle ...");
//Job 前置操作
this.preHandle();
LOG.debug("jobContainer starts to do init ...");
//初始化 reader 和 writer
this.init();
LOG.info("jobContainer starts to do prepare ...");
//全局准备工作,比如 odpswriter 清空目标表
this.prepare();
LOG.info("jobContainer starts to do split ...");
//拆分 Task
this.totalStage = this.split();
LOG.info("jobContainer starts to do schedule ...");
this.schedule();
LOG.debug("jobContainer starts to do post ...");
this.post();
LOG.debug("jobContainer starts to do postHandle ...");
this.postHandle();
LOG.info("DataX jobId [{}] completed successfully.", this.jobId);
this.invokeHooks();
}
} ……
}
6.3、Task 切分逻辑
JobContainer.java
private int split() {
this.adjustChannelNumber();
if (this.needChannelNumber <= 0) {
this.needChannelNumber = 1;
}
List<Configuration> readerTaskConfigs = this .doReaderSplit(this.needChannelNumber);
int taskNumber = readerTaskConfigs.size();
List<Configuration> writerTaskConfigs = this.doWriterSplit(taskNumber);
List<Configuration> transformerList = this.configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT_TRANSF
ORMER);
LOG.debug("transformer configuration: "+ JSON.toJSONString(transformerList));
/**
* 输入是 reader 和 writer 的 parameter list,输出是 content 下面元素的 list
*/
List<Configuration> contentConfig = mergeReaderAndWriterTaskConfigs(
readerTaskConfigs, writerTaskConfigs, transformerList);
LOG.debug("contentConfig configuration: "+
JSON.toJSONString(contentConfig));
this.configuration.set(CoreConstant.DATAX_JOB_CONTENT, contentConfig);
return contentConfig.size();
}
6.3.1、并发数的确定
private void adjustChannelNumber() {
int needChannelNumberByByte = Integer.MAX_VALUE;
int needChannelNumberByRecord = Integer.MAX_VALUE;
boolean isByteLimit = (this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 0) > 0);
if (isByteLimit) {
long globalLimitedByteSpeed = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 10 * 1024 * 1024);
// 在 byte 流控情况下,单个 Channel 流量最大值必须设置,否则报错!
Long channelLimitedByteSpeed = this.configuration.getLong(CoreConstant.DATAX_CORE_TRANSPORT_CHANNE
L_SPEED_BYTE);
if (channelLimitedByteSpeed == null || channelLimitedByteSpeed <= 0) {
throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR, "在有总 bps 限速条件下,单个 channel 的 bps 值不能为空,也不能为非正数");
}
needChannelNumberByByte = (int) (globalLimitedByteSpeed / channelLimitedByteSpeed);
needChannelNumberByByte = needChannelNumberByByte > 0 ? needChannelNumberByByte : 1;
LOG.info("Job set Max-Byte-Speed to " + globalLimitedByteSpeed + " bytes.");
}
boolean isRecordLimit = (this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 0)) > 0;
if (isRecordLimit) {
long globalLimitedRecordSpeed = this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 100000);
Long channelLimitedRecordSpeed = this.configuration.getLong(CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_RECORD);
if (channelLimitedRecordSpeed == null || channelLimitedRecordSpeed <= 0) {
throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,"在有总 tps 限速条件下,单个 channel 的 tps 值不能为空,
也不能为非正数");
}
needChannelNumberByRecord = (int) (globalLimitedRecordSpeed / channelLimitedRecordSpeed);
needChannelNumberByRecord = needChannelNumberByRecord > 0 ? needChannelNumberByRecord : 1;
LOG.info("Job set Max-Record-Speed to " + globalLimitedRecordSpeed + " records.");
}
// 取较小值
this.needChannelNumber = needChannelNumberByByte < needChannelNumberByRecord ?
needChannelNumberByByte : needChannelNumberByRecord;
// 如果从 byte 或 record 上设置了 needChannelNumber 则退出
if (this.needChannelNumber < Integer.MAX_VALUE) {
return;
}
boolean isChannelLimit = (this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL, 0) > 0);
if (isChannelLimit) {
this.needChannelNumber = this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL);
LOG.info("Job set Channel-Number to " + this.needChannelNumber + " channels.");
return;
}
throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,"Job 运行速度必须设置");
}
6.4、调度
JobContainer.java
private void schedule() {
/**
* 这里的全局 speed 和每个 channel 的速度设置为 B/s
*/
int channelsPerTaskGroup = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL, 5);
int taskNumber = this.configuration.getList(CoreConstant.DATAX_JOB_CONTENT).size();
//确定的 channel 数和切分的 task 数取最小值,避免浪费
this.needChannelNumber = Math.min(this.needChannelNumber, taskNumber);
PerfTrace.getInstance().setChannelNumber(needChannelNumber);
/**
* 通过获取配置信息得到每个 taskGroup 需要运行哪些 tasks 任务
*/
List<Configuration> taskGroupConfigs = JobAssignUtil.assignFairly(this.configuration,
this.needChannelNumber, channelsPerTaskGroup);
LOG.info("Scheduler starts [{}] taskGroups.", taskGroupConfigs.size());
ExecuteMode executeMode = null;
AbstractScheduler scheduler;
try {
//可以看到 3.0 进行了阉割,只有 STANDALONE 模式
executeMode = ExecuteMode.STANDALONE;
scheduler = initStandaloneScheduler(this.configuration);
//设置 executeMode
for (Configuration taskGroupConfig : taskGroupConfigs) {
taskGroupConfig.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, executeMode.getValue());
}
if (executeMode == ExecuteMode.LOCAL || executeMode == ExecuteMode.DISTRIBUTE) {
if (this.jobId <= 0) {
throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR, "在[ local | distribute ]模式下必须设置 jobId,并且其
值 > 0 .");
}
}
LOG.info("Running by {} Mode.", executeMode);
this.startTransferTimeStamp = System.currentTimeMillis();
scheduler.schedule(taskGroupConfigs);
this.endTransferTimeStamp = System.currentTimeMillis();
} catch (Exception e) {
LOG.error("运行 scheduler 模式[{}]出错.", executeMode);
this.endTransferTimeStamp = System.currentTimeMillis();
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
}
/**
* 检查任务执行情况
*/
this.checkLimit();
}
6.4.1、确定组数和分组
assignFairly 方法:
- 确定 taskGroupNumber,
- 做分组分配,
- 做分组优化
public static List<Configuration> assignFairly(Configuration configuration, int channelNumber, int channelsPerTaskGroup) {
Validate.isTrue(configuration != null, "框架获得的 Job 不能为 null.");
List<Configuration> contentConfig = configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT);
Validate.isTrue(contentConfig.size() > 0, "框架获得的切分后的 Job 无内容.");
Validate.isTrue(channelNumber > 0 && channelsPerTaskGroup > 0, "每个 channel 的平均 task 数[averTaskPerChannel],channel 数目
[channelNumber],每个 taskGroup 的平均 channel 数[channelsPerTaskGroup]都应该为正数");
//TODO 确定 taskgroup 的数量
int taskGroupNumber = (int) Math.ceil(1.0 * channelNumber / channelsPerTaskGroup);
Configuration aTaskConfig = contentConfig.get(0);
String readerResourceMark = aTaskConfig.getString(CoreConstant.JOB_READER_PARAMETER + "." +
CommonConstant.LOAD_BALANCE_RESOURCE_MARK);
String writerResourceMark = aTaskConfig.getString(CoreConstant.JOB_WRITER_PARAMETER + "." +
CommonConstant.LOAD_BALANCE_RESOURCE_MARK);
boolean hasLoadBalanceResourceMark = StringUtils.isNotBlank(readerResourceMark) || StringUtils.isNotBlank(writerResourceMark);
if (!hasLoadBalanceResourceMark) {
// fake 一个固定的 key 作为资源标识(在 reader 或者 writer 上均可,此处选择在 reader 上进行 fake)
for (Configuration conf : contentConfig) {
conf.set(CoreConstant.JOB_READER_PARAMETER + "." + CommonConstant.LOAD_BALANCE_RESOURCE_MARK, "aFakeResourceMarkForLoadBalance");
}
// 是为了避免某些插件没有设置 资源标识 而进行了一次随机打乱操作
Collections.shuffle(contentConfig, new Random(System.currentTimeMillis()));
}
LinkedHashMap<String, List<Integer>> resourceMarkAndTaskIdMap = parseAndGetResourceMarkAndTaskIdMap(contentConfig);
List<Configuration> taskGroupConfig = doAssign(resourceMarkAndTaskIdMap, configuration, taskGroupNumber);
// 调整 每个 taskGroup 对应的 Channel 个数(属于优化范畴)
adjustChannelNumPerTaskGroup(taskGroupConfig, channelNumber);
return taskGroupConfig;
}
6.4.2、调度实现
AbstractScheduler.java
public void schedule(List<Configuration> configurations) {
Validate.notNull(configurations, "scheduler 配置不能为空");
int jobReportIntervalInMillSec = configurations.get(0).getInt(CoreConstant.DATAX_CORE_CONTAINER_JOB_REPORTINTERVAL, 30000);
int jobSleepIntervalInMillSec = configurations.get(0).getInt( CoreConstant.DATAX_CORE_CONTAINER_JOB_SLEEPINTERVAL, 10000); this.jobId = configurations.get(0).getLong( CoreConstant.DATAX_CORE_CONTAINER_JOB_ID);
errorLimit = new ErrorRecordChecker(configurations.get(0));
/**
* 给 taskGroupContainer 的 Communication 注册
*/
this.containerCommunicator.registerCommunication(configurations);
int totalTasks = calculateTaskCount(configurations);
startAllTaskGroup(configurations);
Communication lastJobContainerCommunication = new Communication();
long lastReportTimeStamp = System.currentTimeMillis();
try {
while (true) {
/**
* step 1: collect job stat
* step 2: getReport info, then report it
* step 3: errorLimit do check
* step 4: dealSucceedStat();
* step 5: dealKillingStat();
* step 6: dealFailedStat();
* step 7: refresh last job stat, and then sleep for next while
*
* above steps, some ones should report info to DS
*
*/
……
}
}
……
}
ProcessInnerScheduler.java
public void startAllTaskGroup(List<Configuration> configurations) {
this.taskGroupContainerExecutorService = Executors.newFixedThreadPool(configurations.size());
for (Configuration taskGroupConfiguration : configurations) {
TaskGroupContainerRunner taskGroupContainerRunner = newTaskGroupContainerRunner(taskGroupConfiguration);
this.taskGroupContainerExecutorService.execute(taskGroupContainerRunner);
}
this.taskGroupContainerExecutorService.shutdown();
}
6.5、数据传输
接 6.3.2 丢到线程池执行
TaskGroupContainer.start()-> taskExecutor.doStart()
可以看到调用插件的 start 方法
public void doStart() {
this.writerThread.start();
// reader 没有起来,writer 不可能结束
if (!this.writerThread.isAlive() || this.taskCommunication.getState() == State.FAILED) {
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
this.taskCommunication.getThrowable());
}
this.readerThread.start();
……
}
可以看看 generateRunner()
ReaderRunner.java
public void run() {
……
try {
channelWaitWrite.start();
……
initPerfRecord.start();
taskReader.init();
initPerfRecord.end();
……
preparePerfRecord.start();
taskReader.prepare();
preparePerfRecord.end();
……
dataPerfRecord.start();
taskReader.startRead(recordSender);
recordSender.terminate();
……
postPerfRecord.start();
taskReader.post();
postPerfRecord.end();
// automatic flush
// super.markSuccess(); 这里不能标记为成功,成功的标志由
writerRunner 来标志(否则可能导致 reader 先结束,而 writer 还没有结束的严重bug)
} catch (Throwable e) {
LOG.error("Reader runner Received Exceptions:", e);
super.markFail(e);
} finally {
LOG.debug("task reader starts to do destroy ...");
PerfRecord desPerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.READ_TASK_DESTROY);
desPerfRecord.start();
super.destroy();
desPerfRecord.end();
channelWaitWrite.end(super.getRunnerCommunication().getLongCounter(CommunicationTool.WAIT_WRITER_TIME));
long transformerUsedTime = super.getRunnerCommunication().getLongCounter(CommunicationTool.TRANSFORMER_USED_TIME);
if (transformerUsedTime > 0) {
PerfRecord transformerRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.TRANSFORMER_TIME);
transformerRecord.start();
transformerRecord.end(transformerUsedTime);
}
}
}
6.5.1、限速的实现
比如看 MysqlReader 的 startReader 方法
-》CommonRdbmsReaderTask.startRead() -》transportOneRecord() -》sendToWriter() -》BufferedRecordExchanger. flush()
-》Channel.pushAll() -》Channel. statPush()
private void statPush(long recordSize, long byteSize) {
currentCommunication.increaseCounter(CommunicationTool.READ_SUCCEED_RECORDS, recordSize);
currentCommunication.increaseCounter(CommunicationTool.READ_SUCCEED_BYTES, byteSize);
//在读的时候进行统计 waitCounter 即可,因为写(pull)的时候可能正在阻塞,但读的时候已经能读到这个阻塞的 counter 数
currentCommunication.setLongCounter(CommunicationTool.WAIT_READER_TIME, waitReaderTime);
currentCommunication.setLongCounter(CommunicationTool.WAIT_WRITER_TIME, waitWriterTime);
boolean isChannelByteSpeedLimit = (this.byteSpeed > 0);
boolean isChannelRecordSpeedLimit = (this.recordSpeed > 0);
if (!isChannelByteSpeedLimit && !isChannelRecordSpeedLimit) {
return;
}
long lastTimestamp = lastCommunication.getTimestamp();
long nowTimestamp = System.currentTimeMillis();
long interval = nowTimestamp - lastTimestamp;
if (interval - this.flowControlInterval >= 0) {
long byteLimitSleepTime = 0;
long recordLimitSleepTime = 0;
if (isChannelByteSpeedLimit) {
long currentByteSpeed = (CommunicationTool.getTotalReadBytes(currentCommunication) -
CommunicationTool.getTotalReadBytes(lastCommunication)) * 1000 / interval;
if (currentByteSpeed > this.byteSpeed) {
// 计算根据 byteLimit 得到的休眠时间
byteLimitSleepTime = currentByteSpeed * interval / this.byteSpeed - interval;
}
}
if (isChannelRecordSpeedLimit) {
long currentRecordSpeed = (CommunicationTool.getTotalReadRecords(currentCommunication) -
CommunicationTool.getTotalReadRecords(lastCommunication)) * 1000 / interval;
if (currentRecordSpeed > this.recordSpeed) {
// 计算根据 recordLimit 得到的休眠时间
recordLimitSleepTime = currentRecordSpeed * interval / this.recordSpeed - interval;
}
}
// 休眠时间取较大值
long sleepTime = byteLimitSleepTime < recordLimitSleepTime ?
recordLimitSleepTime : byteLimitSleepTime;
if (sleepTime > 0) {
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
……
}
}
7、 DataX 使用优化
7.1、关键参数
- job.setting.speed.channel : channel 并发数
- job.setting.speed.record : 2 全局配置 channel 的 record 限速
- job.setting.speed.byte:全局配置 channel 的 byte 限速
- core.transport.channel.speed.record:单个 channel 的 record 限速
- core.transport.channel.speed.byte:单个 channel 的 byte 限速
7.2、优化 1:提升每个 channel 的速度
在 DataX 内部对每个 Channel 会有严格的速度控制,分两种,一种是控制每秒同步的记录数,另外一种是每秒同步的字节数,默认的速度限制是 1MB/s,可以根据具体硬件情况设置这个 byte 速度或者 record 速度,一般设置 byte 速度,比如:我们可以把单个 Channel 的速度上限配置为 5MB
7.3、优化 2:提升 DataX Job 内 Channel 并发数
并发数 = taskGroup 的数量 * 每个 TaskGroup 并发执行的 Task 数 (默认为 5)。
提升 job 内 Channel 并发有三种配置方式:
7.3.1、配置全局 Byte 限速以及单 Channel Byte 限速
Channel 个数 = 全局 Byte 限速 / 单 Channel Byte 限速
{
"core": {
"transport": {
"channel": {
"speed": {
"byte": 1048576
}
}
}
},
"job": {
"setting": {
"speed": {
"byte" : 5242880
}
},
...
} }
core.transport.channel.speed.byte=1048576,job.setting.speed.byte=5242880,
所以 Channel个数 = 全局 Byte 限速 / 单 Channel Byte 限速=5242880/1048576=5 个
7.3.2、配置全局 Record 限速以及单 Channel Record 限速
Channel 个数 = 全局 Record 限速 / 单 Channel Record 限速
{
"core": {
"transport": {
"channel": {
"speed": {
"record": 100
}
}
}
},
"job": {
"setting": {
"speed": {
"record" : 500
}
},
...
} }
core.transport.channel.speed.record=100 , job.setting.speed.record=500, 所 以 配 置 全 局Record 限速以及单 Channel Record 限速,Channel 个数 = 全局 Record 限速 / 单 Channel Record 限速=500/100=5
7.3.3、直接配置 Channel 个数
只有在上面两种未设置才生效,上面两个同时设置是取值小的作为最终的 channel 数。
{
"job": {
"setting": {
"speed": {
"channel" : 5
}
},
...
} }
直接配置 job.setting.speed.channel=5,所以 job 内 Channel 并发=5 个
7.3.4、优化 3:提高 JVM 堆内存
当提升 DataX Job 内 Channel 并发数时,内存的占用会显著增加,因为 DataX 作为数据交换通道,在内存中会缓存较多的数据。例如 Channel 中会有一个 Buffer,作为临时的数据交换的缓冲区,而在部分 Reader 和 Writer 的中,也会存在一些 Buffer,为了防止 OOM 等错
误,调大 JVM 的堆内存。建议将内存设置为 4G 或者 8G,这个也可以根据实际情况来调整。
调整 JVM xms xmx 参数的两种方式:
- 一种是直接更改 datax.py 脚本;
- 另一种是在启动的时候,加上对应的参数,如下:python datax/bin/datax.py --jvm=“-Xms8G -Xmx8G” XXX.json