Counterfactual Zero-Shot and Open-Set Visual Recognition
Counterfactual Zero-Shot and Open-Set Visual Recognition

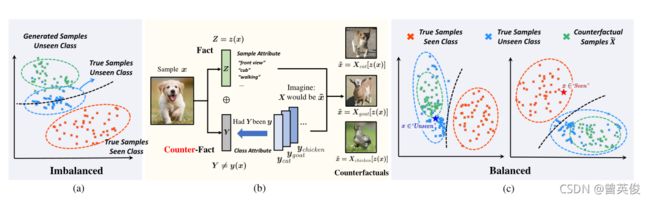
1 Introduction
文献提出一个反事实框架,是由对不可见类的泛化来支撑的。作者基于反事实的一致性规则(反事实确实是基本事实,反事实就等于事实)改变可见和不可见类的类属性来作为二元分类器。拟议的反事实框架是第一个为平衡和改进可见/不可见分类提供理论依据的框架。特别是,作者表明,分离Z和Y的质量是关键瓶颈,因此它是ZSL/OSR未来的一个潜在方向。

2 Methodology
2.1 Zero-Shot Learning (ZSL)
1)传统ZSL,其中模型仅在未可见类上评估;2)广义ZSL,其中模型在可见类上评估可见类和未可见类。一种常见的做法是使用一组额外的类属性 和 来分别描述可见类和不可见类。与独热标签嵌入相比,这些属性可视为密集标签嵌入。当上下文清楚时,将ZSL称为广义ZSL。
2.2 Open-Set Recognition (OSR)
它是用于评估可见类和不可见类,与ZSL不同的是,不可见类被标记为“未知”。OSR通过K维度的独热标签来标记每一个可见类,并不是通过密集标签。
2.3 Generative Causal Model
作者假设ZSL和OSR都遵循生成因果模型如图所示:
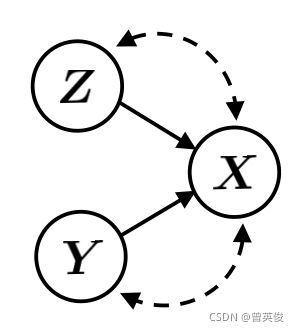
其中Z表示样本属性,Y表示类别属性。忽略混淆因素,给定Z和Y可以从条件分布生成X。同时给定X是可以通过后验和推断出Z和Y。
2.4 Counterfactual Generation and Inference
通过上图的GCM按照计算反事实的三个步骤生成反事实样本:
1)假设,在GCM可以表示为;
2)Y是不是y?这里是目标Y的干预对象,文献通过丢弃推断值和设置Y作为y进行干预,并不是;
3)在推断的Z和干预目标Y的条件下,可以通过生成反事实样本 。
。
文献给出了一些定义:
反事实忠诚,给定 ,使用GCM进行反事实生成的是忠实与。
,使用GCM进行反事实生成的是忠实与。
一致性规则,,其中是未被观测到的真实标签类。因此异类则表示为。
由于反事实的忠实性,差异性可以通过在x中定义的任何距离度量(例如,欧几里德距离)来测量。现有方法中的类不可知论无法弥补纠缠在一起的属性。这导致对看不见的类样本的非忠实生成,并且距离很难区分看到的类样本和看不见的类样本。
ZSL中的推断,在可见类和不可见类中分别用top-K分类概率的平均池表示为和,则二元分类可以表示为:
OSR中的推断,由于OSR是在一个开放的环境中,即可能有无限多个看不见的类,因此不可能生成看不见的类反事实。与ZSL采用相反的方法,通过对不相似性进行阈值化,可以正确地对两个样本进行分类。计算x与的最小欧式距离,通过与临界值的比较给定类别:
2.5 Counterfactual-Faithful Training
定理:反事实生成是可信的,当且仅当样本属性Z和类别属性Y是群分离的。
文献中专门设计的训练目标:。
从Y中解开Z,作者最小化的损失函数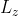 :
:
从Z中解开Y,因为Z中是包含了Y的,所以需要解开纠缠。给定x,已知真实标签y和样本属性z,需要x接近,并且远离,因此采用对数损失:
通过忠诚进一步解开谜团。因为VAE目标优化了可能性P(X)的下限,其中边界松散会破坏忠实性,作者采用Wasserstein GAN损耗进行解决, WGAN损失公式如下:
3 Experimental Studies
3.1 Datasets
ZSL在标准基准数据集上评估方法: Caltech-UCSD-Birds 200-2011 (CUB) 、Animals with Attributes 2 (AWA2) 和 attribute Pascal and Yahoo (aPY),并且根据Proposed Split (PS) V2.0对可见类和不可见类进行分割。
OSR在标准评估数据集:MNIST、SVHN、CIFAR10和CIFAR100。
3.2 Performance evaluation
ZSL评估:
1)ZSL 准确度,为三元组(U,S,H),其中U是不可见类,S是可见类,U/S是每个类别top-1精度,H是U和S的调和平均数:。
2)CVb,为了衡量看不见/看不见分类之间的平衡,作者建议使用看不见和看不见二元分类精度的变异系数,表示为CVb,即。
3)AUSUC,通过绘制一系列ZSL精度的反差来绘制可见-不可见精度曲线(SUC),其中该系列是通过调整校准因子ω来获得的,该校正因子ω从可见类的分类器分对数中减去。然后我们使用SUC(AUSUC)下的面积进行评估。
OSR评估:
1)F1分数,显示了一个方法在拒绝非类样本的同时识别可见类的能力。
2)Openness-F1图,研究不同Openness下的F1的反应:,其中N和M分别是可见类和不可见类的数量。与开放性固定的单个F1分数相比,该图显示了OSR分类器对未知数量的未看见类的开放环境的鲁棒性。
3.3 Experimental Results
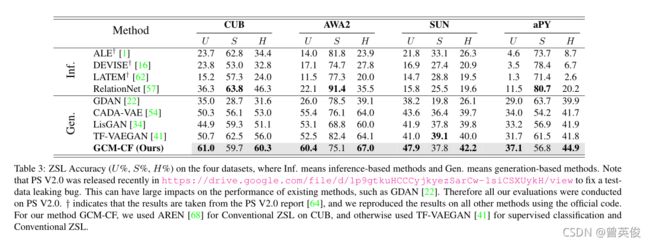
图中GCM-CF是文献提出的框架,其表现相对出色。
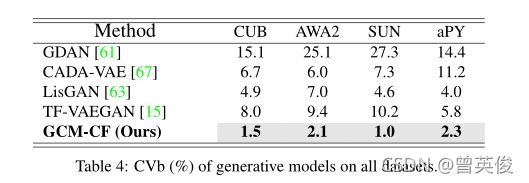
在所有数据集上生成模型的CVb值。
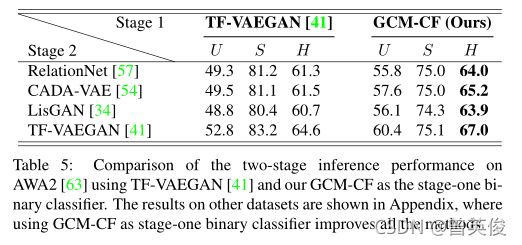
上图显示了二阶段推理性能。
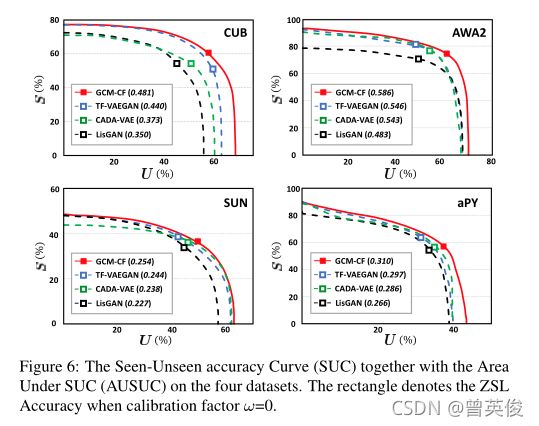
四个数据集上的可见-不可见精度曲线。

使用CGD对重建图像进行比较。
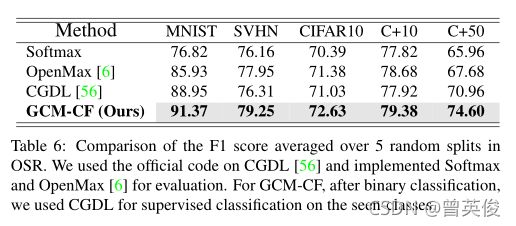
比较OSR中5次随机拆分的F1平均分数。

Openness-F1图,其中使用CIFAR10中的4个非动物类作为可见类。
4 Conclusion
文献提出了一种新的零次学习(ZSL)和开放集识别(OSR)的反事实框架,为平衡和改善可见/不可见分类不平衡提供了理论基础。具体来说,作者提出了一个生成因果模型来生成忠实的反事实,这使我们能够使用一致性规则来平衡二元可见/不可见分类。ZSL和OSR中的大量结果表明,我们的方法确实改善了平衡,从而达到了最先进的性能。作为未来的方向,我们将寻求关于解纠缠的新定义,并设计实际实现以实现改进的解纠缠。