人脸特征点检测入门
基础
人脸特征点可以用来做脸型、眼睛形状、鼻子形状等分析,从而对人脸的特定位置进行修饰加工,实现人脸的特效美颜。人脸识别等算法可以通过对人脸的姿态进行对齐从而提高模型的精度。
68点标注是现今最通用的一种标注方案,早期在1999年的Xm2vtsdb数据集中就被提出,300W数据集和XM2VTS等数据集也都采用了68个关键点的方案,Dlib算法中所采用。

Dlib所采用的68个人脸关键点标注可以看上图,单边眉毛有5个关键点,从左边界到右边界均匀采样,共5×2=10个。 眼睛分为6个关键点,分别是左右边界,上下眼睑均匀采样,共6×2=12个。 嘴唇分为20个关键点,除了嘴角的2个,分为上下嘴唇。上下嘴唇的外边界,各自均匀采样5个点,上下嘴唇的内边界,各自均匀采样3个点,共20个。 鼻子的标注增加了鼻梁部分4个关键点,而鼻尖部分则均匀采集5个,共9个关键点。 脸部轮廓均匀采样了17个关键点。
特征点采集和标注
建立人脸特征点的索引,标记脸部两侧对称的特征点。这样做的好处是对训练图像做镜像时,可以扩大训练集一倍的大小。另外,手工标注特征点的对称关系时只能标注沿着Y轴对称的点。下面两幅图像互为镜像。
 标注的特征点可以用文本来保存。
标注的特征点可以用文本来保存。
几何约束构建
通过对采集数据点进行统计形态分析法(Statistical Shape Analysis, SSA),利用样本点建立对形状的描述,然后对描述的形状建立点分布模型,并从中学习统计参数,完成对形状的建模。该模块在后续跟踪阶段将被用来约束和剔除不合理的特征点。

根据上次对N幅图像手工采集得到的样本点,首先将point2f向量转换成坐标矩阵,然后利用普氏分析、标准正交基、SVD等技术提取非刚性变化(脸部表情),构建描述人脸模型的联合表达(刚性-非刚性)矩阵V,并计算N幅图像的样本点在该联合空间投影后得到坐标的标准差矩阵e,最后将上次标注的连接关系从Vec2i向量转换成坐标索引矩阵形式。
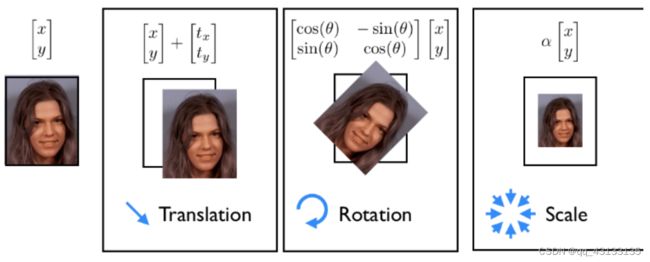
全局变形(刚性) 是指人脸在图像中的分布,允许人脸出现在图像中任意位置,比如整体进行平移,旋转,缩放,和人脸的坐标(x,y)、角度、大小相关;全局变形可以由二维空间的函数表达,并且可以应用于任何类型的对象,无需进行特定单独的学习。
局部形变(非刚性) 是指不同人和不同表情之间脸部形状的不同,与全局形变不同,人脸的高度结构化特征对局部形变产生了极大的约束。局部形变只针对特定目标,需要从训练集中学习。
为了构建脸型的形变模型,我们首先要从标注的样本点中剔除全局刚性部分,即保留物体在去除位移、旋转和缩放因素后所遗留的几何信息。
 关于普式分析可以看这篇最通俗易懂的Procrustes分析教程
关于普式分析可以看这篇最通俗易懂的Procrustes分析教程
1、选取N幅同类目标物体的二维图像,标注上轮廓特征点,这样就得到训练样本集: Ω = { X 1 , X 2 , . . . , X N } \Omega=\{X_1,X_2,...,X_N\} Ω={X1,X2,...,XN}
2、对其进行归一化处理。这里采用Procrustes分析方法对样本集中的所有形状集合进行归一化到[-1,1]范围。求每个样本i(i=1,2…,N)在其图像中的均值:
( X ˉ i , Y ˉ i ) = ( 1 n k ∑ j = 1 n k X i j , 1 n k ∑ j = 1 n k Y i j ) (\bar X_i,\bar Y_i)=(\frac{1}{n_{k}}\sum_{j=1}^{n_k}X_{ij},\frac{1}{n_{k}}\sum_{j=1}^{n_k}Y_{ij}) (Xˉi,Yˉi)=(nk1∑j=1nkXij,nk1∑j=1nkYij)
其中 n k n_k nk是样本中特征点的个数然后将所有样本减去其均值(平移分量移除):
( X i − , Y i − ) = ( X i − X ˉ i , Y i − Y ˉ i ) ( X_i^-,Y_i^-) = ( X_i - \bar X_i,Y_i - \bar Y_i) (Xi−,Yi−)=(Xi−Xˉi,Yi−Yˉi)
缩放分量移除一种方法是除以其均方根,使每个样本均方根距离s为1
s = 1 n k ∑ j = 1 n k ( X i j − ) 2 + ( Y i j − ) 2 s = \sqrt{ \frac{1}{n_{k}}\sum_{j=1}^{n_k}(X_{ij}^-)^2+(Y_{ij}^-)^2} s=nk1∑j=1nk(Xij−)2+(Yij−)2
( X i ′ , Y i ′ ) = 1 s ( X i − , Y i − ) ( X_i',Y_i') = \frac{1}{s}( X_i^-,Y_i^- ) (Xi′,Yi′)=s1(Xi−,Yi−)
但这里不直接移除,在旋转分量移除过程中同时移除缩放分量即可
通过迭代法,移除旋转分量和缩放分量,首先要估计出标准形状:
通过计算每幅图像中所有归一化样本点的平均值得到每个图像的标准形状canonical shape
( X ˉ , Y ˉ ) = ( 1 N ∑ i = 1 N X i − , 1 N ∑ i = 1 N Y i ) (\bar X,\bar Y)=(\frac{1}{N}\sum_{i=1}^{N}X_i^-,\frac{1}{N}\sum_{i=1}^{N}Y_i) (Xˉ,Yˉ)=(N1∑i=1NXi−,N1∑i=1NYi)然后根据普氏距离的定义,利用最小二乘法求每个图像中样本形状到标准形状的旋转角度:
对上式求导可得:
然后根据所求得的a,b参数,对样本形状做旋转缩放变化,得到和标准形状对齐的新的形状:
重复以上步骤,直到达到指定循环次数或者前后两次迭代之间canonical shape的绝对范数满足一定阈值,也就是基本不怎么变化了。

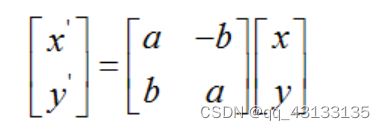
Procrustes Analysis的作用可以看作是一种对原始数据的预处理,目的是为了获取更好的局部变化模型作为后续模型学习的基础。如下图所示,每一个人脸特征点可以用一种单独的颜色表示;经过归一化变化,人脸的结构越来越明显,即脸部特征簇的位置越来越接近他们的平均位置;经过一系列迭代,尺度和旋转的归一化操作,这些特征簇变得更加紧凑,它们的分布越来越能表达人脸表情的变化。【剔除刚性部分、保留柔性部分】

Mat shape_model::procrustes(const Mat& X, const int itol, const float ftol)
{
/* X.cols:图像个数,X.rows: 特征点个数 * 2 */
int N = X.cols, n = X.rows / 2;
//remove centre of mass
Mat P = X.clone();
for (int i = 0; i < N; i++)
{
/*取X第i个列向量,即第i幅图的特征点集*/
Mat p = P.col(i);
float mx = 0, my = 0;
for (int j = 0; j < n; j++)
{
mx += p.fl(2 * j);
my += p.fl(2 * j + 1);
}
/*分别求点集,2维空间坐标x和y的平均值*/
mx /= n;
my /= n;
/*对x,y坐标去中心化*/
for (int j = 0; j < n; j++)
{
p.fl(2 * j) -= mx;
p.fl(2 * j + 1) -= my;
}
}
//optimise scale and rotation
Mat C_old;
for (int iter = 0; iter < itol; iter++)
{
/*计算 1/NΣPx,即每个特征点的重心,得到标准模型*/
Mat C = P * Mat::ones(N, 1, CV_32F) / N;
/*对标准模型进行归一化*/
normalize(C, C);
if (iter > 0)
{
if (norm(C, C_old) < ftol)//计算和C_old的距离,更新较小则退出
break;
}
C_old = C.clone();// 保存为 C_old,以便下次用
//遍历N幅图像的点集
for (int i = 0; i < N; i++)
{
//求当前形状与归一化标准模型之间的旋转角度,即上式a和b
Mat R = this->rot_scale_align(P.col(i), C);
//对当前形状进行坐标变换
for (int j = 0; j < n; j++)
{
float x = P.fl(2 * j, i), y = P.fl(2 * j + 1, i);
/*仿射变化*/
P.fl(2 * j, i) = R.fl(0, 0) * x + R.fl(0, 1) * y;
P.fl(2 * j + 1, i) = R.fl(1, 0) * x + R.fl(1, 1) * y;
}
}
}
return P;
}
经过上述归一化过程后,我们得到N个经过对齐的形状。
为了建立相应的表情空间,我们首先要剔除刚性成分,然后才能利用该空间里的数据,对人脸表情变化建模,即找到一种参数化表达方式,它能够描述不同人和不同表情的脸部变化。
最简单描述脸部变化的做法,是对脸部几何空间采用 线性表达方式 ,其主要思想如下:
假设一个人脸形状,在2n维空间中有n个脸部特征点,线性建模的目的是寻找一个低维超平面,该超平面将包含所有脸型的特征点(见下图中绿色的点)。这个超平面子空间的维数越低,脸型的表达就更具有兼容性。
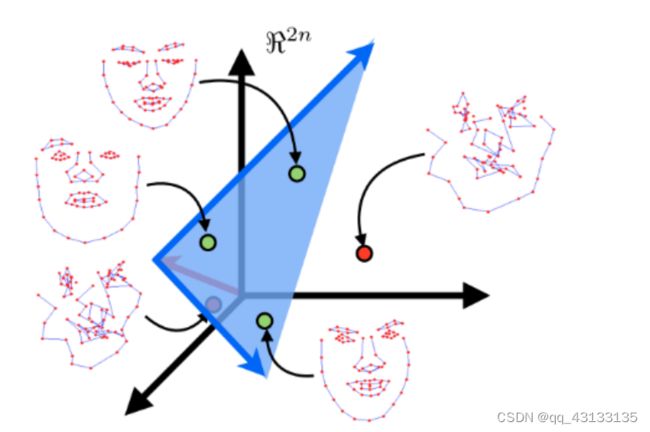
也就是说,经过上述样本点预处理(统计形状分析)后,必然会有大量的数据冗余,在人脸跟踪时会造成不必要的计算开销。因此,这里采用PCA降维技术,在尽可能保留具有显著变化特征数据的基础上,减少样本维数,剔除那些特征变化较小的维度。
由于PCA降维时需要提前指定保留子空间的维数,现实中是很难做到的。通常替代做法是根据所选子空间的特征变化占总体空间特征变化的比例来决定,这里我们可以采用SVD降维。。另外,针对单个个体人脸脸建模,其子空间捕捉的表情变化比大众化人脸建模更具有兼容性,因此针对个体的人脸跟踪比大众化跟踪更精确。
对非刚性空间里的特征点利用SVD降维后,得到了非刚性变化的投影矩阵,并没有得到真正的线性模型(Linear model)。
我们知道每帧图像中人脸的形状由局部变化和全局变化组成(非刚性和刚性)。从数学角度来讲,二者组合的参数是很难获取的,替代的解决方案:将二者合并到一个线性空间中,得到Linear Shape Model。
对于一个特定的形状,其相似变换可以按照如下线性子空间 [ a , b , t x , t y ] T [a,b, t_x, t_y]^T [a,b,tx,ty]T建模:
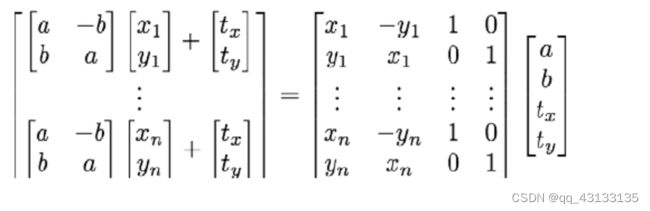 上述公式中,a和b是刚性变化的参数,tx和ty是非刚性变化参数,x和y是样本特征点坐标。
上述公式中,a和b是刚性变化的参数,tx和ty是非刚性变化参数,x和y是样本特征点坐标。
由于在得到非刚性参数之前,样本特征点就已经去中心化了,因此非刚性子空间正交于刚性子空间。那么将两个子空间串联起来,得到上述脸型的联合线性表达 [ a , b , t x , t y ] T [a,b, t_x, t_y]^T [a,b,tx,ty]T也是正交的。这样,我们就可以非常容易得使用这个正交空间来描述脸型。
P是人脸形状在联合子空间中的坐标,V是联合变化矩阵,X是2n维空间样本坐标。这样就可以获得联合分布空间的坐标了。
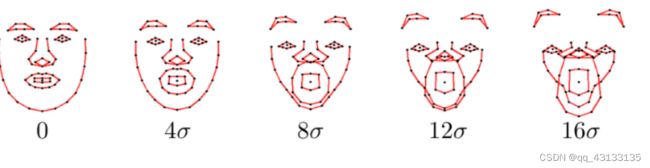
不过,2N维空间投射到联合分布空间的人脸可能会失真。我们注意到对于较小的方差倍数,图形的结果仍然保持人脸的形状,而方差倍数变大时,人脸形状就失真了。要注意的一点是,人脸失真只能是由非刚性变化导致的。
我们对联合分布空间坐标求标准方差,下面几幅图显示的是联合分布子空间中人脸的形状,并且人脸坐标沿着一个方向以4倍标准方差不断增加。
我们选用c(c=3)倍方差为阈值,对于映射后的坐标大于该阈值的,使用clamp函数进行尺寸修正。
void shape_model::clamp(const float c) //c*standard deviations box
{
/*p = V.t()*s; simple projection
* p: (k+4)*1维,存放采样点投影到联合分布空间的坐标集合
*/
double scale = p.fl(0);
for(int i = 0; i < e.rows; i++){
if(e.fl(i) < 0)
continue;
float v = c*sqrt(e.fl(i));
if(fabs(p.fl(i)/scale) > v)
{
if(p.fl(i) > 0)
p.fl(i) = v*scale;
else
p.fl(i) = -v*scale;
}
}
}
当完成表情模型的训练后,将shape_model类序列化,以文件形式保存,供后续步骤使用。
特征提取
上面我们获得了人脸的各种表情模式,也就是一堆标注点的形变参数。我们需要根据它们训练相应的人脸特征(团块模型),它能够对人脸的不同部位(即“标注点”)分别进行描述,作为后面人脸跟踪、表情识别的区分依据。
这次我们将用线性的图像团块来表达人脸特征,虽然它的构造非常简单,通过精心设计它的学习过程,我们了解到这种表达方式在人脸跟踪时能合理的估计人脸特征的位置。此外,由于设计简单,它的计算速度非常快,使得实时人脸跟踪成为了可能。
特征检测器训练算法主要有两类:侧重于描述对象外观结构的算法(generative)和侧重于从多个物体中区分出目标对象的算法(discriminative)。
我认为一个尽可能复原整个对象特征,一个仅仅是根据某几个特征来挑选目标。Generative算法的优点是结果模型通过对特定对象的属性进行编码使得其图像的细节在视觉上可以被观察到,比如特征脸Eigenfaces。discriminative算法的优点是模型集合的全集包含所有对象实例,直接面向求解的问题,比较代表性的算法SVM。
注意:特征脸和支持向量机算法设计的初衷是分类,而不是检测与图像配准。但是这两个算法所运用的数学技巧证明它们可以被运用于人脸跟踪领域
虽然很多场合上述两种算法都能取得不错的效果,但是本次以图像块对人脸特征进行建模,利用discriminative类型的算法得到的效果更好。接下来就详细介绍这种团块模型(Patch Model)的训练过程。
patch models是一种特征模版,当用它覆盖在原始图像上进行搜索时,含有人脸特征的区域在该模版上会有强烈的反馈,而不含人脸特征的区域反馈则较弱,可以用如下数学公式表达:
上式中矩阵 I i I_i Ii表示第 i i i幅样本图像, I i I_i Ii(.)表示手工标注的包含人脸特征的样本区域(TrainingPatch)的范围;矩阵P就是团块模型(Patch Model),其长和宽分别为w和h;矩阵R表示理想的反馈结果。
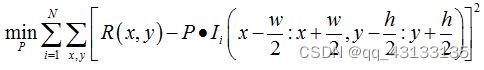
我们的目标是训练 某一个特定的团块特征 模版。这里也就是利用最小二乘法从上式中求解矩阵 P P P(矩阵 R R R和 I I I是不变量, P P P是自变量)。上述公式表达了在所有经特征模版P扫描过的区域而产生的响应图像,平均来说最接近理想响应图像(二者的差最小)。
(为了完整描述人脸所有细节特征,通常需要多个这样的团块特征模版,因此称为correlation-basedpatch models)
理想反馈图像R的选取,最直接的方式,是构造一个周围全0而中间非零的矩阵。如下图右侧的理想响应图像所示:
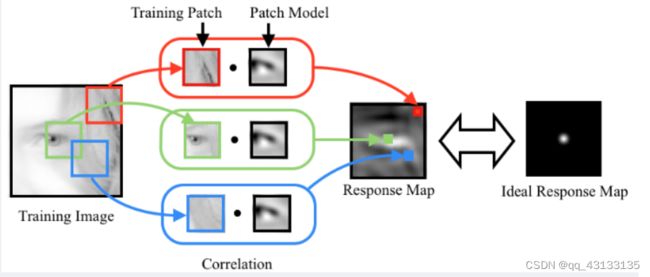 这种做法的前提是假设手工标注的训练样本所包含的人脸特征位于其窗口中央。
这种做法的前提是假设手工标注的训练样本所包含的人脸特征位于其窗口中央。
但是人脸特征在图像中的位置都是手工标注的,因此总是有错误的标注(或者说是偏差)。为了克服这个问题,可以将R设计成一个由中间向外逐渐衰减的函数。这里选取二维高斯分布来表达R,即等价于认为手工标注的错误服从高斯分布。上面图为检测人脸左眼眼角的特征模版在手工标注的不同训练样本上产生的不同响应图像,右侧为理想响应图像。
如果用最小二乘法 求解矩阵P ,那它的计算量实在太大。因为问题解的数量和团块模型中像素数量的个数一样多,比如若团块模型的大小为40*40,则方程的解(自变量)的数量将有1600个(维),这么大的计算量对于一个实时跟踪系统是不能忍受的。 比较有效的替代方案是 采用随机梯度下降法 ,该算法将团块模型的解集看成一幅地势图,通过不断迭代获得地势图梯度方向的近似估计,并每次向梯度的反方向前进,直到走到目标函数的极小值(达到阈值或迭代次数上限)。另外,随机梯度法每次随机选取样本,只需要很少的样本就能达到最优解,非常适合实时性要求较高的系统。
梯度下降法(最速下降法)是求解无约束最优化问题的一种最常用方法,它也是一种迭代方法,每一步需要求解目标函数的梯度向量。假设f(x)在Rn上是具有一阶连续偏导数的函数,要求解的无约束最优化问题是:
x ∗ x* x∗表示目标函数f(x)的极小点。梯度下降法是一种迭代算法,选取适当的初值 x ( 0 ) x(0) x(0),不断迭代,更新x的值,进行目标函数的极小化,直到收敛。由于负梯度方向是使函数值下降最快的方向,在迭代的每一步,以负方向更新x的值,从而达到减少函数值的目的。pk是搜索方向,取负方向
,λk是步长,由一维搜索确定,即λk使得
根据patch model的定义,我们对下面的函数求偏导数:
这样P的更新过程与上面例子类似,p=p-a*D,然后就是不断更新P和求D的迭代,直到D满足一定条件退出。
P:得到训练后的团块模型(针对某一个特征的团块模型,并不能描述完整的人脸)。计算目标函数的偏导数D: 公式同上不罗列了,只是对I有归一化处理。
更新团块模型P:
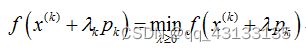
我们上面所使用的样本图像,都是基于假设所有的人脸都位于样本图像的中央,并且全局的大小及旋转的角度都已经归一化(人脸中正,没有偏离,人脸尺寸也是固定的)。但是,实际人脸跟踪时,人脸可以以任意角度、尺度出现在任何位置。
解决训练与测试条件差异导致团块提取失败的方法有两个:一种是在训练阶段手工修改样本图像的缩放尺度、旋转角度到我们所期望的程度,但是由于联合分布团块模型的组成形式比较简单,对于手工设置的样本数据无法产生有效的响应图像response map;另一种方法,由于联合分布团块模型对图像尺度和旋转角度的小范围扰动具有不变性,即前后两帧图像之间人脸的表情变化相对较小,所以我们可以利用上一帧中预估的全局几何变化来约束当前帧人脸的大小尺度和角度,具体做法从产生联合团块模型的图像帧中挑选一个参照帧作为第一个全局几何变化。第一种方法就是在训练阶段提前设置人脸器官尺和角度变化的范围,然后再去训练团块模型,这样做的结果肯定不会很好(因为实际跟踪时情况很复杂,无法假设);第二种的做法,每次训练团块模型前,利用上一帧的全局几何约束对当前帧做处理,然后再训练联合团块模型,这么做的前提是必须知道第一帧的全局几何约束如何获取。
为了增强训练后团块特征的鲁棒性,生成人脸模型的参考点集后,可以通过合理的几何变换让样本图像训练出最好的团块模型。为此,我们首先要求出这么个变换矩阵,然后再作仿射变换。我们可以Procrustes analysis算法计算每幅样本图像中特征点集的几何结构到参考人脸模型的变换矩阵,再利用这个矩阵对样本图像进行仿射变换(缩放、旋转、平移)。经过上述变化,我们就有了每个标注点对应的经过仿射变换的图像区域,我们在该图像区域搜索、训练团块模型。
在对应原始图像上的训练区域(由于设定了大小、又进行了平移旋转缩放等操作,所以效果类似于裁剪出一个团块模型的训练区域),标注点对应的团块模型训练过程,需要经过1000次(多次)迭代(随机梯度下降法),我们看到经过不到100次迭代其实就已经收敛了。得到的团块模型“贴”在手动标注点后的结果,可以直观地看到这些团块模型与标注点的关系

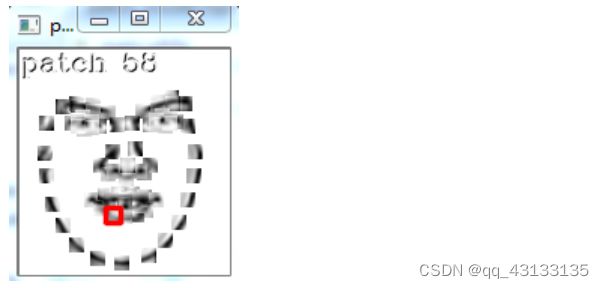
和人脸检测器联合
对于第一帧人脸检测,我们采用比较直观的方式,使用opencv内置的级联检测器来寻找人脸的大致区域,用外接矩形来描述。但这个矩形框和特征点质心其实会有一个偏移,这个也是我们需要学习的变量(这里让人使用我们之前标注的样本进行学习)。
通过学习训练使我们的系统能够学习人脸外界矩形与人脸跟踪特征之间的几何关系
detector_offset向量,然后利用该向量对人脸参考形状矩阵reference进行仿射变换,获得外界矩形区域内的人脸特征点。

训练过程:
- 载入样本标注点ft_data及形状模型数据shape_model
- 设置参数向量p,构造人脸子空间坐标点集合作为人脸特征的参考点集
- 调用trian函数,学习外界矩形与人脸特征点之间的几何关系
detector_offset,
这里train函数的目标是获取detector_offset向量,该向量的作用是将之前训练得到的形状模型以合理的方式镶嵌到人脸上。detector_offset向量通过外接矩形的width和该区域内手工标注点集合pt的重心计算得到。具体过程如下:
判断人脸的外接矩形内是否包含足够多的标注点(防止错误学习),如果包含足够的标注点,则按照如下公式计算
对X、Y、Z集合分别按升序排序,去各自的中值作为最终的detector_offset(Xm,Ym,Zm)
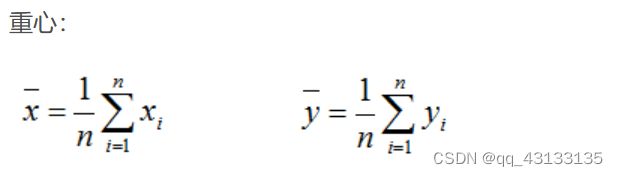
经过上述训练后,我们将序列化存储:级联分类器名称、偏移向量、形状参考点集。接下来,在展示训练结果之前,先介绍下detect函数,如何将我们训练的矩形与特征点的偏移关系套用到测试图像上(这里的前提是已经获得了正确的特征点形状模型,也就是坐标变换是从特征点位置->人脸检测器窗口->原始图像)。
detect函数,输入一副人脸测试图片,根据训练结果,在该人脸图像上标准人脸特征点。具体操作过程:
(1) 彩色图像转化成灰度图像,并进行直方图均衡化
(2) 利用Opencv的级联分类器检测人脸位置
(3) 根据人脸外界矩形,结合detector_offset和参考形状模型,重新计算标注点的坐标
该过程就是训练一个外界矩形与标注点的几何关系,然后让之后的测试图像人脸特征点得到合理标注
人脸跟踪测试
人脸跟踪问题,就是寻找一种高效、健壮的方法,将多个独立的人脸特征通过之前训练的几何依赖关系联合起来,实现精确跟踪每幅图像中人脸特征的几何位置。如果仅按照检测到人脸特征的位置进行跟踪会导致过度噪声。
 上面两幅图像,分别是带与不带几何依赖的人脸跟踪效果图。对比的结果清晰地展示了人脸特征之间空间内部依赖关系的优势,有了空间内部依赖关系,每个点的跟踪效果会更好。
上面两幅图像,分别是带与不带几何依赖的人脸跟踪效果图。对比的结果清晰地展示了人脸特征之间空间内部依赖关系的优势,有了空间内部依赖关系,每个点的跟踪效果会更好。
因为每个人脸特征跟踪时,采用模版匹配法,即便在正确的位置,该区域图像在人脸模版上的反馈,也有可能不是最佳的。无论是图像噪声、光照变化、还是表情变化,解决人脸特征”模版匹配式跟踪”局限性的唯一方法,就是借助每个人脸特征之间的几何关系。
几何依赖关系在人脸跟踪时的做法就是:我们将人脸特征提取的结果投影到形状模型的线性子空间 (shape model),也就是最小化原始点集到其在人脸子空间最接近合理形状分布的投影点集的距离。
把通过模版匹配检测到的原始点集A投影到人脸子空间产生新的点集B,再按照某种约束规则,通过对A迭代变化,使得A’到B的距离最小。融合了几何关系的人脸特征模版匹配法进行跟踪人脸时,即便空间噪声满足高斯近乎于高斯分布,其检测效果也“最像“人脸的形状。
int face_tracker::track(const Mat &im,const face_tracker_params &p)
{
//convert image to greyscale
Mat gray;
if(im.channels()==1)
gray = im;
else
cvtColor(im,gray,CV_RGB2GRAY);
//initialise,为第一帧或下一帧初始化人脸特征
if(!tracking)
points = detector.detect(gray,p.scaleFactor,p.minNeighbours,p.minSize);
if((int)points.size() != smodel.npts())
return 0;
//fit,通过迭代缩小的搜索范围,估计当前帧中的人脸特征点
for(int level = 0; level < int(p.ssize.size()); level++)
points = this->fit(gray,points,p.ssize[level],p.robust,p.itol,p.ftol);
//set tracking flag and increment timer
tracking = true;
timer.increment();
return 1;
}
fit函数就是给定一帧图像及上一帧人脸特征点集,在当前图像上搜索该点集附近的人脸特征,并产生新的人脸特征点集。这个过程分为两步:
1、为了得到合理的人脸子空间投影,我们需要求参数向量p,该函数通过人脸子空间投影坐标集合pts与人脸特征空间标准基V,计算得到参数向量。算参数向量p时可分为两种投影:simpleprojection和scale projection
如果权值为空,则采用简单投影,由于V是标准正交基:
否则对每个被投影点设置尺度权值,采用尺度投影,利用opencv提供的奇异值分解法求解非齐次线性系统(求p):
pts是在给定的搜索区域大小后,当前帧中人脸特征位置点集。至于权值,老外在后面robust model fitting流程有用到。由于H和g是对每种表情模式作累加的,所以我猜想权值w的作用是控制每个人脸特征点对每种表情模式的影响,即只要哪些点就能显著表达对应表情。无论哪种投影,都经过clamp函数处理,根据c_factor个标准差e约束调整参数向量p,防止人脸投影失真。
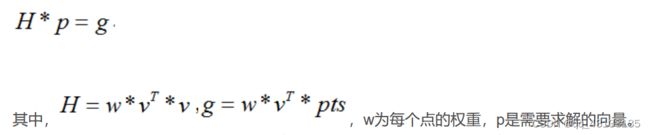
2、这一步是根据人脸子空间点集在当前图像内搜索人脸特征,并产生新的人脸特征位置估计。通过上一步的函数我们得到设置投影范围的参数向量p,然后再调用calc_shape函数(calc_param与calc_shape,如果排除权值,那么是一对互逆的操作)就可以得到人脸子空间中的特征点pts。 我们要在每个人脸子空间特征点附近搜索包含人脸特征的区域,最终为下一帧生成新的特征估计。这也是为什么,我们只需在第一帧或者跟踪失败时,才需要调用Opencv级联分类器重新定位人脸的原因。
//========================================================================
vector<Point2f>
patch_models::
calc_peaks(const Mat &im,
const vector<Point2f> &points,
const Size ssize)
{
int n = points.size(); assert(n == int(patches.size()));
Mat pt = Mat(points).reshape(1,2*n);
Mat S = this->calc_simil(pt);// 计算当前点集到人脸参考模型的变化矩阵
Mat Si = this->inv_simil(S); //对矩阵S求逆
vector<Point2f> pts = this->apply_simil(Si,points);
for(int i = 0; i < n; i++){
Size wsize = ssize + patches[i].patch_size(); Mat A(2,3,CV_32F);
A.fl(0,0) = S.fl(0,0); A.fl(0,1) = S.fl(0,1);
A.fl(1,0) = S.fl(1,0); A.fl(1,1) = S.fl(1,1);
A.fl(0,2) = pt.fl(2*i ) -
(A.fl(0,0) * (wsize.width-1)/2 + A.fl(0,1)*(wsize.height-1)/2);
A.fl(1,2) = pt.fl(2*i+1) -
(A.fl(1,0) * (wsize.width-1)/2 + A.fl(1,1)*(wsize.height-1)/2);
Mat I; warpAffine(im,I,A,wsize,INTER_LINEAR+WARP_INVERSE_MAP);
Mat R = patches[i].calc_response(I,false);
Point maxLoc; minMaxLoc(R,0,0,0,&maxLoc);
pts[i] = Point2f(pts[i].x + maxLoc.x - 0.5*ssize.width,
pts[i].y + maxLoc.y - 0.5*ssize.height);
}return this->apply_simil(S,pts);
}
面代码片段中,介绍以下函数:
(1) apply_simil函数,对点集points按照Si进行仿射变化(将人脸特征子空间中的坐标经过仿射变换转成图像空间中的坐标,或者反过来)
(2) calc_response函数,在灰度图像上搜索人脸特征(团块图像)的匹配位置,核心技术是Opencv API:matchTemplate模版匹配函数(图像I,模版T,匹配结果,算法标记),这里采用的算法是CV_TM_CCOEFF_NORMED,标准相关匹配宏。具体做法就是在原始图像上滑动模版窗口,在一次移动一个像素,最后在每个像素点上的匹配度量值R(x):
上式也就是窗口中心化以后进行NCC匹配,w,h为模版T的宽和高
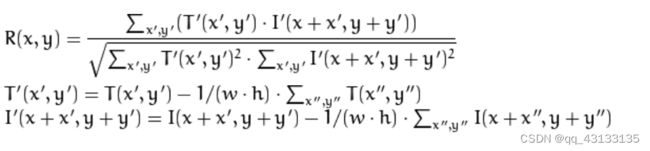
(3) minMaxLoc函数(数组 ,最小值,最大值,最小值坐标,最大值坐标):寻找矩阵中的最大最小值的位置,这里在矩阵R中寻找最大值,即最佳匹配位置。不需要关注的,API内直接填0即可。
calc_peak总体说来,利用上一帧坐标构造人脸特征的搜索区域,借助之前训练得到的团块模型,在搜索区域内进行模版匹配,找到最优匹配点,作为新一帧人脸特征点的坐标。完整操作过程如下:
(1) 计算前一帧人脸特征坐标到人脸参考模型坐标的仿射变换 S2 * 3
(2) 计算上述仿射变化的逆矩阵 Si 2 * 3
(3) 通过逆矩阵Si将人脸特征子空间中的坐标还原成图像帧中的坐标
(4) 遍历所有点,在原始图像中搜索每个人脸特征模版图像匹配的坐标点
(5) 利用(4)中的坐标,修正人脸特征估计点位置
(6) 利用仿射变化矩阵,再次将图像中的坐标投影到人脸特征子空间中,作为下一帧的人脸特征坐标估计
在对每帧图像进行人脸跟踪时,track函数都会通过fit函数迭代产生多个人脸子空间坐标集合,并且每次迭代的时候,搜索区域都在减小。在迭代过程中,可能会产生很多孤立的特征点(孤立点,我认为是模版匹配时得到人脸特征错误估计点,因为本文没有一种机制保证R(X)的反馈一定包含人脸特征)。为了得到更精确的人脸跟踪效果,如果存在孤立点时,仍采用简单投影simple projection,会严重影响跟踪效果。因此,老外在计算投影参数calc_param时引入了权重,搞了一套robust model fitting流程,特意去除孤立点。
 最终结果如下:
最终结果如下:

参考
虽然大部分都摘抄自下面链接,由于经过了整理,且摘抄的不限于一篇文章,不方便弄成转载,故打为原创。
人脸关键点数据集整理
非刚性人脸跟踪 I
非刚性人脸跟踪 II
最通俗易懂的Procrustes分析教程
非刚性人脸跟踪 III
非刚性人脸跟踪 IV (终)
ASM主动轮廓模型