利用paddleseg训练自己的数据集
Github开源地址,内有数据集设置规则。
参考博客:docs/whole_process_cn.md · PaddlePaddle/PaddleSeg - Gitee.com
开源数据集:
https://paddleseg.bj.bcebos.com/dataset/optic_disc_seg.zip
目录
1.环境安装
2. 配置数据集
2.1 打开项目后,界面如图
2.2 对于数据集的修改脚本都在tools中
2.2.1 tools中工具说明
2.3 整理数据
2.4 切分数据
3.准备配置文件
4.模型训练
1.单卡训练
2.恢复训练
3.加载预训练模型
6.训练可视化
7.模型预测
8.模型导出(2步导出)
9.二次开发
1.环境安装
参考官方安装文档
2. 配置数据集
2.1 打开项目后,界面如图

2.2 对于数据集的修改脚本都在tools中

这里paddleseg既支持灰度图也支持伪彩色图
 通常我们数据集二值化后为像素值为0 255这里伪彩色标注图像素为 0 1归一化,如果有2类就是0 1 如果有3类就是0 1 2 以此类推(这一步很重要)
通常我们数据集二值化后为像素值为0 255这里伪彩色标注图像素为 0 1归一化,如果有2类就是0 1 如果有3类就是0 1 2 以此类推(这一步很重要)
如果使用0 255 进行训练就会出现如下情况

而且loss很快会变为0
2.2.1 tools中工具说明
1) 灰度标注图转换为伪彩色标注图 (非必须)
python tools/gray2pseudo_color.py 
脚本使用方法,以下类似
在此文件目录下cmd,将路径替换掉,绝对路径即可中间空格隔开

如果仅希望将指定数据集中的部分灰度标注图转换为伪彩色标注图,则执行以下命令。
python tools/gray2pseudo_color.py --dataset_dir --file_separator 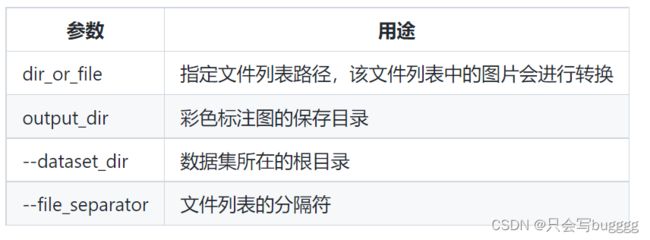
2.3 整理数据
数据格式如下,图片要求24深度jpg格式,标签要求8深度png格式,分类为几项则从0到几

2.4 切分数据
对于所有原始图像和标注图像,需要按照比例划分为训练集、验证集、测试集。
PaddleSeg提供了切分数据并生成文件列表的脚本
split_dataset_list.py此代码为默认比例7 :3 :1
python tools/split_dataset_list.py ${FLAGS} 参数说明:
- dataset_root: 数据集根目录
- images_dir_name: 原始图像目录名
- labels_dir_name: 标注图像目录名

使用示例:
python tools/split_dataset_list.py images annotations --split 0.6 0.2 0.2 --format jpg png 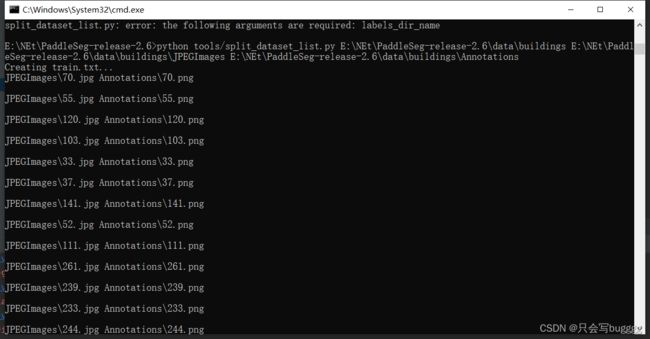
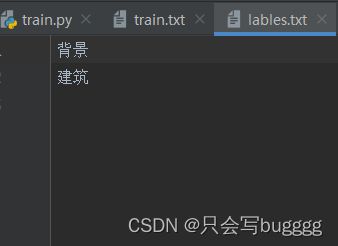
切分完成后将生成3个或者2个txt文件

这里的lables.txt为分类种类数如图 ,需要自行设置
这里也可以使用这个切分方法,无需使用脚本。
至此,数据集准备完毕
3.准备配置文件
配置文件均位于configs中,建议自己建一个文件夹,需要哪个模型复制哪个
建议将所有需要的配置复制到一个中,避免重复
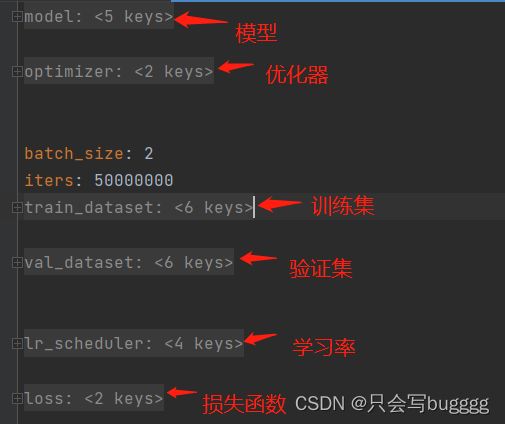
避免这种情况,还要去_base_中再去找

配置文件说明说的非常清楚
4.模型训练
1.单卡训练
准备好配置文件后,在PaddleSeg根目录下执行如下命令,使用train.py脚本进行单卡模型训练
export CUDA_VISIBLE_DEVICES=0 # 设置1张可用的卡
**windows下请执行以下命令**
**set CUDA_VISIBLE_DEVICES=0**
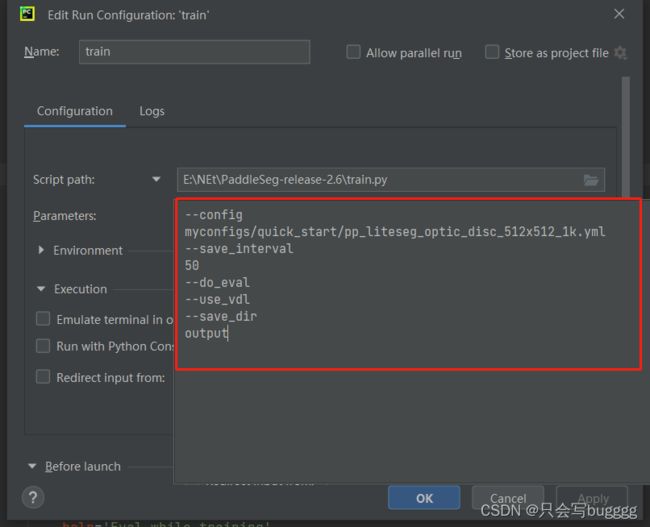
python train.py \
--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \
--save_interval 500 \
--do_eval \
--use_vdl \
--save_dir output在pycharm中train下右击
上述训练命令解释:
--config指定配置文件。--save_interval指定每训练特定轮数后,就进行一次模型保存或者评估(如果开启模型评估)。--do_eval开启模型评估。具体而言,在训练save_interval指定的轮数后,会进行模型评估。--use_vdl开启写入VisualDL日志信息,用于VisualDL可视化训练过程。--save_dir指定模型和visualdl日志文件的保存根路径。

train.py文件说明
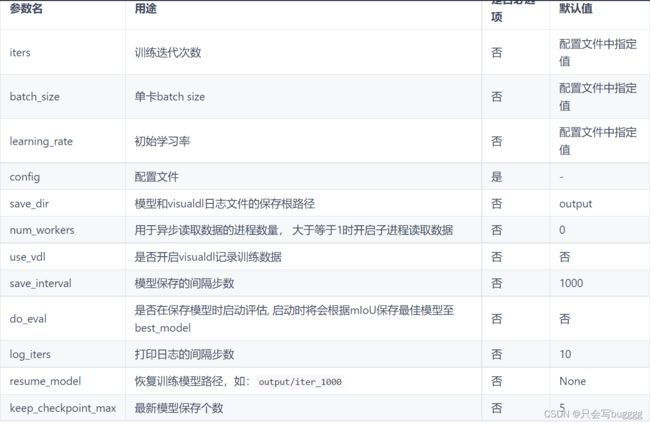
2.恢复训练
添加一行resume_model 选择保存的iter
python train.py \
--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \
--resume_model output/iter_500 \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output3.加载预训练模型
将config中model中的pretrained配置为自己训练的模型即可
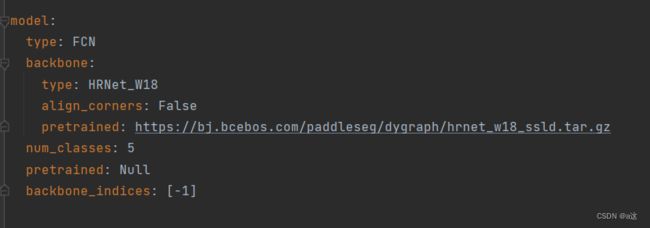
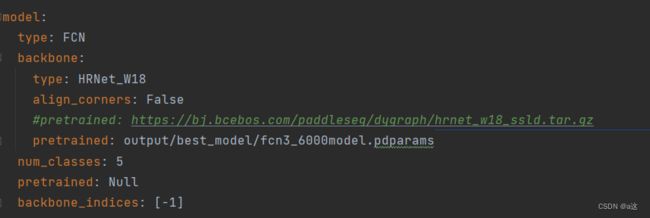
6.训练可视化
官方文档
1.首先安装visualdl
pip install --upgrade --pre visualdl
2.输入命令 ,需要存在log文件
visualdl --logdir ./log --port 8080
# 或者写在自己的文件夹
visualdl --logdir ./output/fcnclass3 --port 8080 
7.模型预测
在predict.py中将此代码放入
其中image_path可以是一个图片路径,也可以是一个目录。如果是一个目录,将对目录内的所有图片进行预测并保存可视化结果图。
同样的,可以通过--aug_pred开启多尺度翻转预测, --is_slide开启滑窗预测。
python predict.py \
--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \
--model_path output/best_model/model.pdparams \
--image_path data/optic_disc_seg/JPEGImages/H0002.jpg \
--save_dir output/result8.模型导出(2步导出)
(1)在export.py中输入如下命令,将模型转为静态
python export.py \
--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \
--model_path output/best_model/model.pdparams \
--save_dir output/infer_model
--input_shape 1 3 512 512

会生成4个文件如图
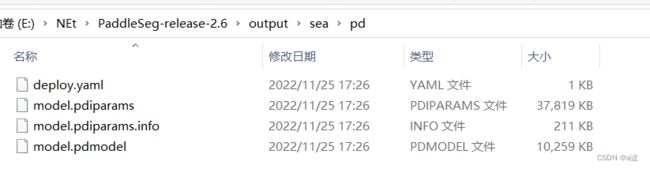
output/infer_model
├── deploy.yaml # 部署相关的配置文件
├── model.pdiparams # 静态图模型参数
├── model.pdiparams.info # 参数额外信息,一般无需关注
└── model.pdmodel # 静态图模型文件,可以使用netron软件进行可视化查看(2).利用onnxruntime转为.onnx格式
需要安装onnxruntime库
# 安装cpu版本
pip install onnxruntime
# 安装gpu版本
pip install onnxruntime-gpu利用pycharm或者cmd都可以在终端输入,需要在中间添加空格
![]()
# 使用paddle2onnx将paddle模型格式转化到ONNX模型格式。
! paddle2onnx --model_dir ./output/ \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file segonnx/model.onnx \
--opset_version 11
--save_file test.onnx最后转出的模型为
![]()
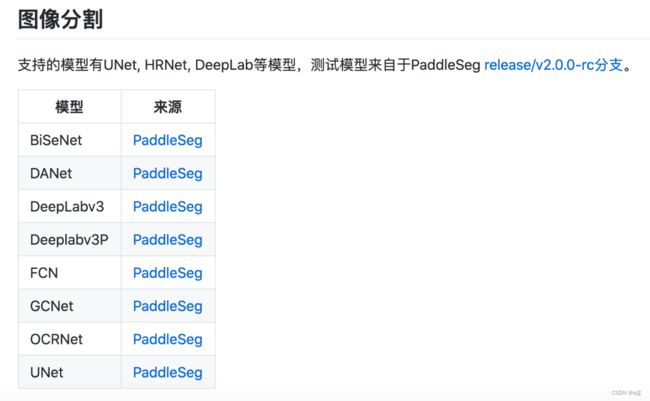
目前支持的模型
利用onnx格式进行整张图像的预测
# encoding: utf-8
import numpy as np
import cv2
from osgeo import gdal
import onnxruntime
import os
import math
import time
def gdal_read_info(path):
dataset = gdal.Open(path)
if dataset == None:
print(path + "文件无法打开")
return
_im_width = dataset.RasterXSize # 栅格矩阵的列数
_im_height = dataset.RasterYSize # 栅格矩阵的行数
im_bands = dataset.RasterCount # 波段数
im_geotrans = dataset.GetGeoTransform() # 获取仿射矩阵信息
im_proj = dataset.GetProjection() # 获取投影信息
return dataset, im_bands, _im_width, _im_height, im_geotrans, im_proj
def save_tif_whit_geo(out_path, dataset, save_name, array):
"""
存储相同坐标系tif
"""
# dataset = gdal.Open(input_path)
# if dataset == None:
# print(input_path + "文件无法打开")
# return
im_width = dataset.RasterXSize # 栅格矩阵的列数
im_height = dataset.RasterYSize # 栅格矩阵的行数
im_bands = 1 # 波段数
im_geotrans = dataset.GetGeoTransform() # 获取仿射矩阵信息
im_proj = dataset.GetProjection() # 获取投影信息
# 创建文件
driver = gdal.GetDriverByName("GTiff")
sav_path = os.path.join(out_path, save_name)
sav_dataset = driver.Create(sav_path, im_width, im_height, im_bands, gdal.GDT_Byte)
sav_dataset.SetGeoTransform(im_geotrans) # 写入仿射变换参数
sav_dataset.SetProjection(im_proj) # 写入投影
sav_dataset.GetRasterBand(1).WriteArray(array)
del dataset
def pre(img):
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = np.transpose(img, (2, 0, 1)) # 转为chw
input_blob = ((np.expand_dims(img, axis=0).astype(np.float32) / 255.0) - 0.5) / 0.5 # 转为nchw并归一化
# time0 = time.time()
out = sess.run([outputs0], input_feed={input_name: input_blob})
# time1 = time.time()
# print(time1 - time0)
# res_img = np.ones((512,512,3),dtype=np.uint8) #空白图像
tmp = out[0][0]
# print(tmp)
return tmp
def predict_result(bfpath, save_path, nBlockSize):
bf_dataset, bf_im_bands, bf_im_width, bf_im_height, bf_im_geotrans, bf_im_proj = gdal_read_info(bfpath)
cols = bf_im_width
rows = bf_im_height
pre_all = np.zeros((bf_im_height, bf_im_width), np.uint8)
i = 0
j = 0
try:
num = 0
total = math.ceil(rows / nBlockSize) * math.ceil(cols / nBlockSize)
while i < rows:
while j < cols:
# 保存分块大小
nXBK = nBlockSize
nYBK = nBlockSize
# 最后不够分块的区域,有多少读取多少
if i + nBlockSize > rows:
i = rows - nYBK
if j + nBlockSize > cols:
j = cols - nXBK
# 分块读取影像
bf_Image_part = bf_dataset.ReadAsArray(j, i, nXBK, nYBK)
imagebf = np.transpose(bf_Image_part, [1, 2, 0]) # 转为张量
# print(imagebf.mean())
if (imagebf.mean()==0.0 or imagebf.mean()==255):
j = j + nXBK
num += 1
continue
try:
imagebf = imagebf.astype('float32')
result = pre(imagebf)
# print(result)
# result = model.predict(imagebf)['label_map']
arr = result.astype(np.uint8) * 255
# print(arr)
num += 1
pre_all[i:i + nYBK, j:j + nXBK] = arr + pre_all[i:i + nYBK, j:j + nXBK]
j = j + nXBK
except Exception as e:
print(e)
print(num, "/", total)
j = 0
i = i + nYBK
save_tif_whit_geo("", bf_dataset, save_path, pre_all.astype(np.uint8))
except Exception as e:
print(e)
model_path = r'output/海面第一版.onnx'
sess = onnxruntime.InferenceSession(model_path, providers=['CUDAExecutionProvider']) # 使用GPU
input_name = sess.get_inputs()[0].name # 'data'
outputs0 = sess.get_outputs()[0].name
if __name__ == '__main__':
image_path = r'E:\2\0.2\21-5.tif'
save_path = r'E:\2\0.2\21-5.tif'
predict_result(image_path, save_path, 512)
9.二次开发
paddleseg的代码格式,这里是官方提供的格式说明文件
PaddleSeg
├── configs #配置文件文件夹
├── paddleseg #训练部署的核心代码
├── core # 启动模型训练,评估与预测的接口
├── cvlibs # Config类定义在该文件夹中。它保存了数据集、模型配置、主干网络、损失函数等所有的超参数。
├── callbacks.py
└── ...
├── datasets #PaddleSeg支持的数据格式,包括ade、citycapes等多种格式
├── ade.py
├── citycapes.py
└── ...
├── models #该文件夹下包含了PaddleSeg组网的各个部分
├── backbone # paddleseg的使用的主干网络
├── hrnet.py
├── resnet_vd.py
└── ...
├── layers # 一些组件,例如attention机制
├── activation.py
├── attention.py
└── ...
├── losses #该文件夹下包含了PaddleSeg所用到的损失函数
├── dice_loss.py
├── lovasz_loss.py
└── ...
├── ann.py #该文件表示的是PaddleSeg所支持的算法模型,这里表示ann算法。
├── deeplab.py #该文件表示的是PaddleSeg所支持的算法模型,这里表示Deeplab算法。
├── unet.py #该文件表示的是PaddleSeg所支持的算法模型,这里表示unet算法。
└── ...
├── transforms #进行数据预处理的操作,包括各种数据增强策略
├── functional.py
└── transforms.py
└── utils
├── config_check.py
├── visualize.py
└── ...
├── train.py # 训练入口文件,该文件里描述了参数的解析,训练的启动方法,以及为训练准备的资源等。
├── predict.py # 预测文件
└── ...