NLP 之 word2vec 以及负采样原理详解
文章目录
-
-
- 一:前言
- 二:语言学模型
- 三:skip-gram
- 四:CBOW
- 五:负采样
-
一:前言
博主的导师让博主研究一下人机对话,上周花了一周的时间研究了一下word2vec。下面以这篇博客来总结一下博主对word2vec的理解。如果有错误的地方,欢迎大家在评论区进行批评指正。
word2vec是谷歌于2013年发布的用于计算词向量的工具,其可以很好的度量词之间的相似性,引起了工业界和学术界的广泛关注,目前也是计算词向量的重要方法。我们需要注意一点的是word2vec不是一个模型,而是计算词向量的方法,具体计算的时候可以使用不同的模型,在本篇博客中,我们主要介绍两种具体的模型,skip-gram和cbow。
本篇博客首先回顾一下统计语言学模型,接着介绍skip-gram模型和cbow模型,最后对模型训练过程中使用的负采样进行详细的解释。
二:语言学模型
在深入word2vec具体模型之前,我们先来简单回顾一下自然语言处理中的一个基本问题,如何去计算一个文本序列在某个语料中出现的概率?这个问题在很多的nlp问题中基本问题,如果在机器翻译的问题中,我们已经知道了目标语句中翻译结果的前面部分,如果选择后面的几个词?在文本的生成过程中,如何根据已经有的文本生成下一句话?等等。为了弄清楚这里面的规律,统计语言模型给出了这类问题的一个基本框架,给定一段文本序列:
(2.1) S = w 1 , w 2 , . . . , w T S=w_1,w2,...,w_T \tag{2.1} S=w1,w2,...,wT(2.1)
其概率可以表示为T个词的联合概率或者条件概率的乘积:
(2.2) P ( S ) = P ( w 1 , w 2 , . . . , w T ) = ∏ p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 1 , w 2 ) ⋯ p ( w T ∣ w 1 , w 2 , . . . w T − 1 ) = ∏ k = 1 T p ( w k ∣ w 1 , w 2 , . . . , w k − 1 ) P(S) = P(w_1,w_2,...,w_T)=\prod{p(w_1)p(w_2|w_1)p(w_3|w_1,w_2)\cdots p(w_T|w_1,w_2,...w_{T-1})} = \prod_{k=1}^T{p(w_k|w_1,w_2,...,w_{k-1})} \tag{2.2} P(S)=P(w1,w2,...,wT)=∏p(w1)p(w2∣w1)p(w3∣w1,w2)⋯p(wT∣w1,w2,...wT−1)=k=1∏Tp(wk∣w1,w2,...,wk−1)(2.2)
那么现在问题就变成了,给定 w 1 , w 2 , . . . , w k − 1 w_1,w_2,...,w_{k-1} w1,w2,...,wk−1,计算 w k w_k wk的出现的概率。即: p ( w k ∣ w 1 , w 2 , . . . w k − 1 ) p(w_k|w_1,w_2,...w_{k-1}) p(wk∣w1,w2,...wk−1),由于这个模型的参数空间是非常大的,难以求解,并且在比较长的一句话中,距离预测词的距离越远的词对预测的贡献越小,我们更多的是采用其简化的版本,即N-gram模型。即有:
(2.3) p ( w k ∣ w 1 , w 2 , . . . w k − 1 ) ≈ p ( w k ∣ w k − n + 1 ) , … , w k − 1 ) p(w_k|w_1,w_2,...w_{k-1}) \approx p(w_k|w_{k-n+1)},\dots ,w_{k-1}) \tag{2.3} p(wk∣w1,w2,...wk−1)≈p(wk∣wk−n+1),…,wk−1)(2.3)
常见的模型有 b i g r a m ( N = 2 ) bigram(N=2) bigram(N=2)和 t r i g r a m ( N = 3 ) trigram(N=3) trigram(N=3)等模型,这些模型可以使用 M L E MLE MLE (maximum likelihood estimation)进行求解。
以上简单回顾了统计语言模型的基本表示方法,下面我们来看看word2vec两种具体的实现模型。
三:skip-gram
skip-gram 翻译成中文的叫跳字模型,模型的目标是通过一个词来预测该词附近的词(上下文),比如一个句子“The quick brown fox jumps over lazy dog”,如果我们选定中心词‘fox’,来预测该词附近的两个词,模型的任务就是在输入“fox”的时候,输出“quick”,“brown”,“jumps”和“over”,模型如下图所示,我们可以看出这是一个非常简单的浅层神经网络。

skip-gram 模型的训练目标是寻找有效词的表示来预测一句话或者一个文本中一个词的附近的词。由第二节的语言学模型我们可以将其使用数学符号来表示。给定一个序列 S = w 1 , w 2 , . . . , w T S=w_1,w2,...,w_T S=w1,w2,...,wT,最大化联合概率分布,这里假设 p ( w t + j ∣ w t ) p(w_{t+j}|w_t) p(wt+j∣wt)之间是相互独立的:
(3.1) ∏ t = 1 T ∏ − c ⩽ j ⩽ , j = ̸ 0 p ( w t + j ∣ w t ) \prod_{t=1}^T{ \prod_{-c\leqslant j\leqslant ,j =\not 0}{p(w_{t+j}|w_t)}} \tag{3.1} t=1∏T−c⩽j⩽,j≠0∏p(wt+j∣wt)(3.1)
对上式取对数并且进行平均取复数可以得到我们需要优化的目标函数:
(3.2) arg min − 1 T ∑ t = 1 T ∑ − c ⩽ j ⩽ , j = ̸ 0 log p ( w t + j ∣ w t ) \arg\min - \frac{1}{T} \sum_{t=1}^T{\sum_{-c\leqslant j\leqslant ,j =\not 0}{\log p(w_{t+j}|w_t)}}\tag{3.2} argmin−T1t=1∑T−c⩽j⩽,j≠0∑logp(wt+j∣wt)(3.2)
p ( w t + j ∣ w t ) p(w_{t+j}|w_t) p(wt+j∣wt) 是概率的表示方法,那么我们知道在神经网络模型中,sigmoid和softmax函数可以输出概率的形式,在此模型中,输出为多个分类,因此,需要使用softmax函数,即有:
(3.3) P ( w o ∣ w i ) = exp ( u o ⊺ v i ) ∑ w = 1 W exp ( u o ⊺ v i ) P(w_o|w_i) = \frac{\exp(u_{o}^{\intercal}v_{i})}{\sum_{w=1}^W{\exp(u_{o}^{\intercal}v_{i})}}\tag{3.3} P(wo∣wi)=∑w=1Wexp(uo⊺vi)exp(uo⊺vi)(3.3)
其中 u o , v i u_{o},v_{i} uo,vi 分别表示输出词向量表示和输入的词向量表示,在模型中,一个词在作为输入词和输出词时有不同的向量表示。 W W W表示语料库词典的大小,通常这个数是非常大的。我们需要使用梯度下降法来更新输入词向量的向量表示,那么有:
(3.4) ∂ log ( P ( w o ∣ w i ) ∂ w i = u o − ∑ j = 1 W exp ( u j ⊺ v i ) u j ∑ s = 1 W exp ( u s ⊺ v i ) = u o − ∑ j = 1 W log ( P ( w o ∣ w j ) ) u j \frac{\partial \log(P(w_o|w_i )}{\partial w_i} = u_o -\sum_{j=1}^W{\frac{\exp{(u_{j}^{\intercal}v_i})u_j}{\sum_{s=1}^W{}\exp(u_{s}^{\intercal}v_i)}}=u_o -\sum_{j=1}^W{\log(P(w_o|w_j) )u_j}\tag{3.4} ∂wi∂log(P(wo∣wi)=uo−j=1∑W∑s=1Wexp(us⊺vi)exp(uj⊺vi)uj=uo−j=1∑Wlog(P(wo∣wj))uj(3.4)
由(3.2)和(3.4)梯度计算公式就可以得到 ∂ L ∂ v c \frac{\partial L }{\partial v_c} ∂vc∂L,那么输入词的向量就可以按照下式进行迭代训练,得到最终的结果。
(3.5) v i = v i − ∂ L ∂ v c v_i = v_i - \frac{\partial L }{\partial v_c} \tag{3.5} vi=vi−∂vc∂L(3.5)
由(3.4)我们可以知道,神经网络的最后一层softmax分类数是整个词典的大小,通常在训练词向量的时候用的语料库都是很大的,一般可能会有几百万词,由此导致此步骤计算开销非常大,我们在第五节详细说一下如何使用负采样的方法进行优化。
四:CBOW
CBOW,Continuous Bag-Of-Words,即连续词袋模型,该模型模型和skip-gram模型相反,给定上下文的词,来预测中心词,用skip-gram中的例子,比如一个句子“The quick brown fox jumps over lazy dog”,设窗口大小为2,如果我们输入“quick”,“brown”,“jumps”和“over”,我们希望模型输出“fox”的概率最大,模型如下图所示:
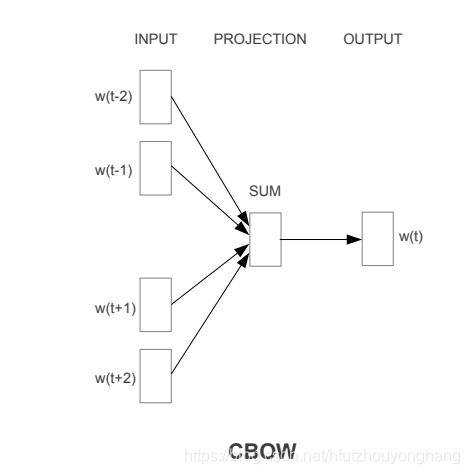
CBOW模型的训练目标为最大化下式的联合条件概率,其中m窗口大小:
(4.1) ∏ k = 1 T P ( w k ∣ w k − m , … , w k − 1 , w k + 1 , … , w k + m ) \prod_{k=1}^T{P(w_k|w_{k-m},\dots,w_{k-1},w_{k+1}, \dots ,w_{k+m})} \tag{4.1} k=1∏TP(wk∣wk−m,…,wk−1,wk+1,…,wk+m)(4.1)
上式取对数,平均,取负数之后即可到的模型的损失函数:
(4.2) − 1 T ∑ k = 1 T log P ( w k ∣ w k − m , … , w k − 1 , w k + 1 , … , w k + m ) -\frac{1}{T}\sum_{k=1}^T{\log{P(w_k|w_{k-m},\dots,w_{k-1},w_{k+1}, \dots ,w_{k+m})}} \tag{4.2} −T1k=1∑TlogP(wk∣wk−m,…,wk−1,wk+1,…,wk+m)(4.2)
其中由softmax函数可得:
(4.3) P ( w k ∣ w k − m , … , w k − 1 , w k + 1 , … , w k + m ) = exp ( u k ⊺ ( v k − m , … , v k + m ) / 2 m ) ∑ i = 1 T exp ( u k ⊺ ( v i − m , … , v i + m ) / 2 m ) P(w_k|w_{k-m},\dots,w_{k-1},w_{k+1}, \dots ,w_{k+m})= \frac{\exp{(u_{k}^{\intercal}(v_{k-m},\dots ,v_{k+m})/2m)}}{\sum_{i=1}^{T}{\exp{(u_{k}^{\intercal}(v_{i-m},\dots ,v_{i+m})/2m)}}} \tag{4.3} P(wk∣wk−m,…,wk−1,wk+1,…,wk+m)=∑i=1Texp(uk⊺(vi−m,…,vi+m)/2m)exp(uk⊺(vk−m,…,vk+m)/2m)(4.3)
其中 u k u_k uk为被预测中心词的向量表示,在例子中为“fox”, v k − m , … , v k + m v_{k-m},\dots ,v_{k+m} vk−m,…,vk+m为输入词的向量表示,在模型中,一个词在作为输入词和输出词时有不同的向量表示。训练模型时,其梯度计算公式为:
(4.4) ∂ P ( w k ∣ w k − m , … , w k − 1 , w k + 1 , … , w k + m ) ∂ w i = 1 2 m ∑ j = 1 T ( u k − P ( w j ∣ w j − m , … , w j − 1 , w j + 1 , … , w j + m ) u j ) ( i ∈ { k − m , … , k + m } ) \frac{\partial P(w_k|w_{k-m},\dots,w_{k-1},w_{k+1}, \dots ,w_{k+m})}{\partial w_i} = \frac{1}{2m}\sum_{j=1}^T({u_k}-P(w_j|w_{j-m},\dots,w_{j-1},w_{j+1}, \dots ,w_{j+m})u_j)(i \in \{k-m,\dots,k+m \}) \tag{4.4} ∂wi∂P(wk∣wk−m,…,wk−1,wk+1,…,wk+m)=2m1j=1∑T(uk−P(wj∣wj−m,…,wj−1,wj+1,…,wj+m)uj)(i∈{k−m,…,k+m})(4.4)
类似于公式(3.5),利用随机梯度下降法更新输入词的向量表示,得到最终的结果。
五:负采样
我们注意到其(3.3),(3,4),(4.3),(4.4)式的时候,分母的计算复杂度为 O ( W ) O(W) O(W), W W W为字典的规模。我们在训练模型时一般使用的字典大小都是非常大的,这导致计算开销是无法接受的。原文的作者提出了hierarchical softmax和negative sampling两种优化方法,TensorFlow框架中的实现方法为negative sampling。下面我们就详细解释一下negative sampling的原理。
negative sampling的是NCE(Noise-Constrastive Estimation)噪声对比估计的一种简化版本,感兴趣的读者可以去谷歌阅读一下原文。我们知道在softmax中,输出是 W W W维的向量C,每个分量 c i c_i ci表示预测为第 i i i个词的概率,我们选择概率最大的词作为当前的输出值,negative sampling 的思想是只需要按照一定的概率分布 P ( w ~ ) P( \tilde{w}) P(w~) 抽取K个负样本,比如在skip-gram的例子中,输入“fox”,抽出的负样本可能是“two”,“mother”等等,与正样本放在一起,将多分类问题转换成K+1个二分类问题,从而减少计算量,加快训练速度。为了解释这种思想,我们首先定义一些概念。
给定一个文本序列 w 1 , w 2 , … , w c − m , … , w c , … , w c + m , . . . , w T w_1,w2,\dots,w_{c-m},\dots,w_c,\dots,w_{c+m},...,w_T w1,w2,…,wc−m,…,wc,…,wc+m,...,wT,某个中心词 w c w_c wc,窗口大小m. { w c , w c − m } , … , { w c , w c + m } \{w_c,w_{c-m}\} ,\dots, \{w_c,w_{c+m}\} {wc,wc−m},…,{wc,wc+m}称为正样本,我们按照一定的概率分布 P ( w ~ ) P(\tilde w) P(w~)从词典中抽取 K K K个负样本 w ~ 1 , w ~ 2 , … w ~ K \tilde w_1,\tilde w_2,\dots \tilde w_K w~1,w~2,…w~K,那么 { w c , w ~ k } ( k = 1 , … , K ) \{ w_c,\tilde w_k\} (k =1,\dots,K) {wc,w~k}(k=1,…,K)称为负样本。那么给定中心词 w c w_c wc,预测 w j ( j ∈ { c − m , c + m } ) w_j(j\in \{c-m,c+m\}) wj(j∈{c−m,c+m})就是由以下事件组成的:
- w c w_c wc与 w j w_{j} wj共同出现
- w c w_c wc没有 w ~ 1 \tilde w_1 w~1共同出现
- w c w_c wc没有 w ~ 2 \tilde w_2 w~2共同出现
- … \dots …
- w c w_c wc没有 w ~ K \tilde w_K w~K共同出现
我们以skip-gram为例,在一个文本序列中,设 P ( D = 1 ∣ w j , w c ) P(D=1|w_j,w_c) P(D=1∣wj,wc)为中心词 w c w_c wc与词 w j w_j wj在当前窗口中同时出现的概率, w j w_j wj是需要预测的词,可能是当前窗口中中心词的上下文词,也有可能不是当前窗口中的上下文词。 P ( D = 0 ∣ w j , w c ) P(D=0|w_j,w_c) P(D=0∣wj,wc)为中心词 w c w_c wc与词 w j w_j wj在没有当前窗口中同时出现的概率。则这些事件的联合分布概率为:
(5.1) P ( D = 1 ∣ w j , w c ) ∏ k = 1 K P ( D = 0 ∣ w ~ k , w c ) P(D=1|w_j,w_c)\prod_{k=1}^K{P(D=0|\tilde w_k,w_c)} \tag{5.1} P(D=1∣wj,wc)k=1∏KP(D=0∣w~k,wc)(5.1)
(5.2) P ( D = 1 ∣ w j , w c ) = 1 − P ( D = 0 ∣ w j , w c ) P(D=1|w_j,w_c) = 1-P(D=0|w_j,w_c) \tag{5.2} P(D=1∣wj,wc)=1−P(D=0∣wj,wc)(5.2)
联合(5.1)(5.2)之后取对数可得:
(5.3) log P ( D = 1 ∣ w j , w c ) + ∑ k = 1 K log ( 1 − P ( D = 1 ∣ w ~ k , w c ) ) \log P(D=1|w_j,w_c) + \sum_{k=1}^K \log(1-P(D=1|\tilde w_k,w_c)) \tag{5.3} logP(D=1∣wj,wc)+k=1∑Klog(1−P(D=1∣w~k,wc))(5.3)
预测两个词有没有在同一窗口出现,结果只有两种,同时出现,没有同时出现。我们可以使用sigmoid函数来预测两个词同时出现的概率 u j u_j uj表示输出词的词向量表示, v c v_c vc表示输入词(中心词)的词向量表示,如之前所述,一个词作为输入词和输出词时有不同的向量表示。
(5.4) P ( w j ∣ w c ) = P ( D = 1 ∣ w j , w c ) = σ ( u j ⊺ v c ) = 1 1 + exp ( − u j ⊺ v c ) P(w_j|w_c)=P(D=1|w_j,w_c) = \sigma(u_{j}^{\intercal}v_c) = \frac{1}{1+\exp(-u_{j}^{\intercal}v_c)} \tag{5.4} P(wj∣wc)=P(D=1∣wj,wc)=σ(uj⊺vc)=1+exp(−uj⊺vc)1(5.4)
由(5.3)和(5.4)可得:
(5.5) log 1 1 + exp ( − u j ⊺ v c ) + ∑ k = 1 K log 1 1 + exp ( u k ⊺ v c ) \log \frac{1}{1+\exp(-u_{j}^{\intercal}v_c)} + \sum_{k=1}^K \log\frac{1}{1+\exp(u_{k}^{\intercal}v_c)} \tag{5.5} log1+exp(−uj⊺vc)1+k=1∑Klog1+exp(uk⊺vc)1(5.5)
从(5.5)我们可以看出来,上式其实是二分类的交叉熵损失函数,不熟悉的同学可以去复习一下二分类的交叉熵函数。
至此,我们将softmax函数中 O ( W ) O(W) O(W)复杂度的计算降低成 O ( K ) O(K) O(K)的复杂度,大大地简化了计算。
skip-gram模型的具体实现可以参考我的另一篇博客。传送门
补充一个公式,负采样的概率分布在tensorflow中实现的是:
(5.6) P ( w i ) = log ( s ( w i ) + 2 ) − log ( s ( w i ) + 1 ) log ( W + 1 ) P(w_i) = \frac{\log (s(w_i)+2) - \log(s(w_i)+1)}{\log(W+1)} \tag{5.6} P(wi)=log(W+1)log(s(wi)+2)−log(s(wi)+1)(5.6)
其中 s ( w i ) s(w_i) s(wi)是词 w i w_i wi在字典中根据词频逆排序的序号.