微软SQL Server2012增加对Hadoop的支持
今天去听了微软的SQL Server2012发布预览会,听说到Hadoop的支持。在海量数据时代的大趋势下,微软增加了SQL Server大规模数据处理和并行数据仓库平台对开源Hadoop框架的支持。
大数据的泡沫在毫无止境的膨胀,它给IT企业带来了颠覆性的改革。 Hortonworks的CEO Eric Baldeschwieler表示,目前企业中80%的数据是非结构化数据。更为雷人的是这些数据在以60%的速度呈现指数级增长,到2020年,全球数据使用量预计将暴增44倍,达到35.2ZB(1ZB=10亿TB)。大数据的急剧蔓延使得企业在存储架构方面逐渐面临着史无前例的考验,由此引发了数据仓库、数据挖掘、商业智能、云计算等应用的一连串连锁反应。
据最新消息,微软正在研发一种连接器,即Excel用户能访问Hadoop大数据处理结果。而Hortonworks希望把它变成NoSQL到SQL的的通用连接器,在开源社区推而广之。
大数据膨胀催生了微软等巨头纷纷拥抱Hadoop
各大企业巨头纷纷有所行动,雅虎、AOL、谷歌、Facebook等早期采用并使用Hadoop来存储和分析PB级别的非结构化数据。IBM也在在 SmartCloud 平台上新增基于 Apache Hadoop 的服务 InfoSphere BigInsights 分析软件。Oracle的Big Data机采用了NoSQL数据库和Hadoop框架。EMC也推出了世界上第一个定制的、高性能的Hadoop专用数据协同处理设备——Greenplum HD数据计算设备。Google 的网络搜索引擎在得益于算法发挥作用的同时,Hadoop的核心MapReduce 在后台发挥了极大的作用。亿贝的Hadoop系统能够很好地处理大规模非结构化数据,高效处理用户邮件数据。
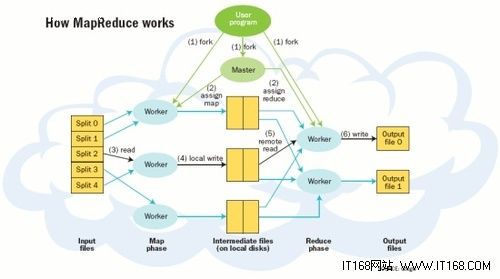
Hadoop核心框架MapReduce工作原理
与各大巨头相比,微软更是耐不住寂寞,它与Hortonworks达成合作,致力于将Hadoop打造成用于存储和处理数据的引人注目的平台。Windows和Hadoop的结合将是非常具有吸引力的,这将吸引大量的Windows用户。显然微软具有在此领域竞争的实力,优化和调整是确保其成功的重要因素。
微软捷足先登 不断强化开源Hadoop框架的支持
大数据的浪潮一浪高过一浪,企业厮杀角逐越发激烈,微软迈出的步伐似乎更快,发力更猛。Hadoop可谓是开源创新领域的杰出典范,微软对Hadoop的支持更应该被看作极具转折式的决策。
首先,早在2006年起微软就捷足先登,致力于研发某种非常类似于Hadoop的项目,被称为“Dryad”。
2011年年初,该计划通过与SQL Server和Windows Azure云的集成实现了Dryad的产品化。虽然现在微软还没有更新,但看上去Dryad似乎将成为在SQL Server平台上影响大数据爱好者的有力竞争者。
其次,微软早在2011年3月份就发布了数据库系统Trinity. Trinity是一款NoSQL数据库,同时也是一个基于内存的数据存储与运算系统。Trinity包括一个图结构数据库(提供实时查询与后台批量计算任务,类似于Map/Reduce,同时支持ACI的事物并提供C#的客户端API)和一个并行计算系统。目前在微软为Probase和AEther这两个产品服务。
此外,2011年8月微软就增加了SQL Server在大规模数据处理和并行数据仓库平台对开源Hadoop框架的支持。微软已经将Hadoop嵌入到了生态系统中,并且发布了SQL Server的Hadoop连接器,此外,还推出了基于Hadoop的Windows Azure预览版,该连接器的最终版本已提供下载。这两个连接器采用SQL to Hadoop (SQOOP)技术,在Hadoop File System (HDFS)和微软关系数据库之间有效地传输数据。通过这个连接器,用户可以在Hadoop中分析非结构化数据,然后迁移到SQL Server环境中进行数据分析。

SQL Server的Hadoop连接器
用户需要将SQL Server Hadoop连接器部署到Hadoop集群的主节点上。主节点还需要安装Sqoop和微软的Java数据库连接驱动。Sqoop是一个开源命令行工具,用来从关系型数据库导入数据,并使用Hadoop MapReduce框架进行数据转换,然后将数据重新导回数据库当中。
当SQL Server Hadoop连接器部署完毕之后,用户可以使用Sqoop来导入导出SQL Server数据。注意,Sqoop和连接器是在一个Hadoop的集中视图下进行操作的,这意味着用户使用Sqoop导入数据的时候是从SQL Server数据库检索数据并添加到Hadoop环境中,而相反地,导出数据是指从Hadoop中检索数据并发送到SQL Server数据库当中。
总而言之,微软表示,随着新连接工具的出现,客户将能够在Hadoop、SQL Server和并行数据仓换环境下相互交换数据。
微软再次发力在线数据库连接器:Apache Hadoop发扬光大
微软新研发的是一款ODBC连接器,用于访问Hadoop对应的Hive数据仓库系统。Excel用户拿到Hive数据后,就可以借助Excel PowerPivot等工具,开始数据分析了。
Hortonworks与微软积极开展合作,致力于将微软的Hadoop连接器推广到开源社区。另外的JavaScript也遵循同样的模式,即微软关注的是做产品,而Hortonworks则致力于开源。
Hortonworks借微软东风 强化合作
虽然目前来讲,这款Javascript框架和连接器还没有发布,不过预计将来会开源,前景很客观。
总之,“闭源”微软拥抱Hadoop是木已成舟,微软似乎对开源领域频繁抛出橄榄枝,但无论如何,微软都不可能与开源Linux划上等号,因为Linux永远是Windows系统在台式机及服务器领域的直接对手。而Hadoop则不同,它可以作为微软SQL Server及Azure系列产品的一大重要补充方案而存在。另一方面,Hortonworks 希望能够与微软积极合作,将这门技术应用到开源领域,被广大Apache Hadoop社区所采用。微软将重点研发这款工具,打造属于自己产品的核心平台,正所谓各取所需,Hortonworks 也将重点瞄准了产品,希望借此东风,进一步衍生出更广泛的应用。