KNN与交叉检验
KNN与交叉检验
KNN基础知识
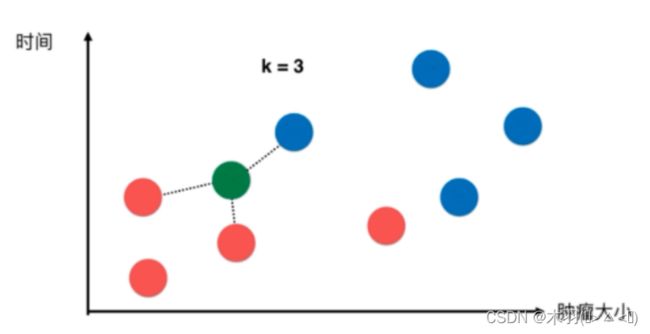
KNN(K-Nearest Neighbors)算法原理
“近朱者赤,近墨者黑”——从训练数据集中找出和待预测样本最接近的K个样本,然后投票决定待预测样本的分类;如果是回归问题,则求出K个样本的平均值作为待预测样本最终的预测值
样本距离公式

特征标准化问题
如果样本的多个特征值差别很大,或者样本特征的量纲不一致,导致样本间距离被某些特征所主导,就应该考虑样本特征标准化的问题
最常用的特征标准化方法是:z-score标准化

z-score标准化通过sklearn中的sklearn.preprocessing.StandardScaler实现
实战——使用KNN完成鸢尾花分类预测
在sklearn中使用sklearn.neighbors.KNeighborsClassifier实现KNN分类的功能
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data # 所有样本特征
y = iris.target # 所有样本标签
# 将数据集拆分成训练样本集和测试样本集
X_train,X_test,y_train,y_test =
train_test_split(X,y,test_size=0.2,random_state=666)
# 样本特征标准化
std = StandardScaler()
# 通过训练样本集特征进行标准化拟合并转换
X_train_standard = std.fit_transform(X_train)
# 对于测试集,直接转换即可!
X_test_standard = std.transform(X_test)
from sklearn.neighbors import
KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3) # 创
建KNN分类器对象,K=3
knn.fit(X_train_standard,y_train) # 拟合
# 根据样本特征,对测试样本进行预测
y_predict = knn.predict(X_test_standard)
print(y_predict)
# 直接调用score方法,得出分类准确率
print(knn.score(X_test_standard,y_test))
交叉验证
什么是交叉验证(Cross Validation)
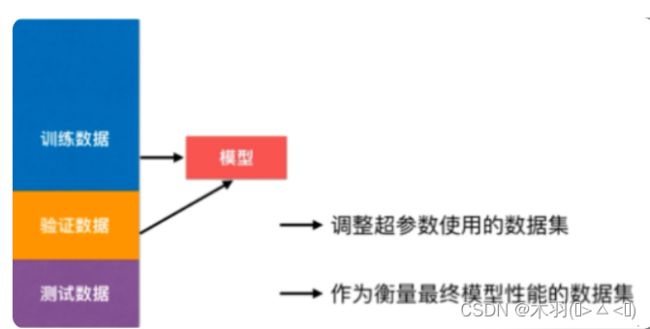
交叉验证是一种模型选择方法和调参方法,它随机地将数据集切分成三部分,分别为训练集(training set)、验证集(validation set)和测试集(test set)。训练集用来训练模型,验证集用于模型的选择,测试集用于最终对学习方法的评估。
K折交叉验证(k-fold cross validation)
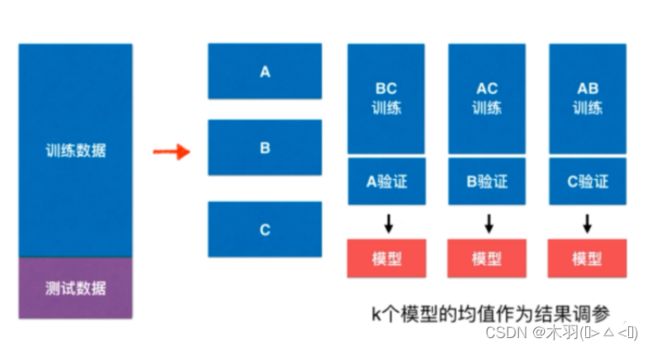
首先随机地将已给训练数据集切分为k个互不相交的大小相同的子集;然后利用K-1个子集的数据训练模型,利用余下的子集验证模型;将这一过程对可能的K种选择重复进行(这一过程使用的是同一组超参数);最后通过计算K次的预测误差,对其平均便会得到1个交叉验证误差(也就是这一组超参数的预测误差或成绩)。
留一交叉验证(leave-one-out cross validation)
留一交叉验证(留一法)是K折交叉验证的特殊情形,即:K=N,这里N是给定训练数据集的容量。留一法不受随机样本划分方式的影响,最接近模型真正的性能指标。因为N个样本只有唯一的方式划分为N个子集——每个子集包含一个样本。
缺点:计算量巨大
实战——手写数字图片数据集的调参、分类识别
交叉验证使用sklearn.model_selection.cross_val_score来完成
'''
参数解释:
estimator: 需要使用交叉验证的算法
X: 样本特征
y: 样本标签
cv: 交叉验证折数
'''
cross_val_score(estimator, X, y=None,cv=None)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 数据加载,展示图像
digits = datasets.load_digits()
images = digits.images # 所有图像数据
plt.gray() # 灰色图像
plt.matshow(images[0]) # 显示第一个图像
plt.show()
# 拆分数据集
X_train, X_test, y_train, y_test =
train_test_split(X, y, test_size=0.4,random_state=666)
# 交叉验证调参开始
from sklearn.model_selection import
cross_val_score,best_k,best_p,best_score = 0,0,0
for k in range(2,11): # 外层循环搜索k
for p in range(1,6): # 内层循环搜索p
knn =KNeighborsClassifier(weights="distance",
n_neighbors=k,p=p)
scores =cross_val_score(knn,X_train,y_train,cv=3) # 3折交叉验证
score = np.mean(scores) # 当前这一组超参数在验证集上的平均分
if score > best_score:
best_k,best_p,best_score =k,p,score
print("best_k=",best_k)
print("best_p=",best_p)
print("验证最好成绩:best_score=",best_score)
# 使用调好的超参数进行训练与测试
best_knn =KNeighborsClassifier(weights="distance",n_neighbors=2,p=2)
best_knn.fit(X_train,y_train)
best_knn.score(X_test,y_test) # 测试集上最终的分数
#使用调好的超参数进行训练与测试
best_knn = KNeighborsClassifier(weights="distance",n_neighbors=2,p=2)
best_knn.fit(X_train,y_train)
best_knn.score(X_test,y_test)
实战——使用网格搜索进行调参
网格搜索可以实现自动调参并返回最佳的参数组合
网格搜索,搜索的是参数,即在指定的参数范围内,依次调整参数,利用调整的参数训练学习器
网格搜索的sklearn实现
使用sklearn.model_selection.GridSearchCV实现网格搜索GridSearchCV的名字可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
digits = datasets.load_digits() # 加载数据集
X = digits.data # 样本特征
y = digits.target # 样本标签
# 拆分数据集
X_train, X_test, y_train, y_test =train_test_split(X, y, test_size=0.4,random_state=666)
#网格搜索
from sklearn.model_selection import GridSearchCV
#组装待搜索的超参数
param_grid = [
{
"weights":["uniform"],
"n_neighbors":[i for i in range(1,11)]
},
{
"weights":[distance],
"n_neighbors":[i for i in range(1,11)],
"p":[i for i in range(1,6)]
}
]
knn = KNeighborsClassifier()
gs = GridSearchCV(knn,param_grid,cv=3,n_jobs=-1)#n_jobs使用几核CPU,-1代表有多少用多少
gs.fit(X_train,y_train)#搜索最佳超参数组合
print(gs.best_params_) # 最佳超参数
print(gs.best_score_) # 最佳验证成绩
# 携带最佳超参数组合的KNeighborsClassifier对象
best_knn = gs.best_estimator_
# 使用最佳超参数组合的分类器进行拟合训练
best_knn.fit(X_train,y_train)
print("在测试集上的最终评估效果:",best_knn.score(X_test,y_test))