NYUDv2数据集预处理——获得语义分割的图像和标签并着色
NYUDv2数据集
- NYUDv2数据集包含RGB、RGB-D图像,共有849类。
- 本文只使用NYUDv2数据集中的RGB图像,且只包含40类。
- 只需下载Labeled dataset (~2.8 GB)
本文内容
- 获得NYUDv2数据集中的RGB原始图像、灰度分割图像
- 对灰度分割图像进行着色
- 将原始图像和分割图像划分为训练集和验证集
完整代码和数据集已上传至百度网盘,链接如下:
链接:https://pan.baidu.com/s/1QTbKN9WKIKkf9BmTv_1tyA
提取码:a7ux
获得原始图像和分割图像
- 运行
preprocess.py,输出原始图像和分割图像,并且能够输出划分训练集和验证集的txt文件
## preprocess.py
import os
import h5py
import numpy as np
from PIL import Image
from tqdm import tqdm
from scipy.io import loadmat
def write_txt(f, list_ids):
f.write('\n'.join(list_ids))
f.close()
def extract_data(root):
"""
extract images and labels.
:param root:
:return:
"""
print('Extracting images and labels from nyu_depth_v2_labeled.mat...')
data = h5py.File(os.path.join(root, 'nyu_depth_v2_labeled.mat'))
images = np.array(data['images'])
print(f'images shape: {images.shape}')
num_img = images.shape[0]
print(f'image number: {num_img}')
images_dir = os.path.join(root, 'images')
if not os.path.isdir(images_dir):
os.makedirs(images_dir)
bar = tqdm(range(num_img))
for i in bar:
img = images[i]
r = Image.fromarray(img[0]).convert('L')
g = Image.fromarray(img[1]).convert('L')
b = Image.fromarray(img[2]).convert('L')
img = Image.merge('RGB', (r, g, b))
img = img.transpose(Image.ROTATE_270)
img.save(os.path.join(images_dir, str(i) + '.jpg'), optimize=True)
def split(root):
print('Generating training and validation split from split.mat...')
split_file = loadmat(os.path.join(root, 'splits.mat'))
train_images = tuple([int(x) for x in split_file["trainNdxs"]])
test_images = tuple([int(x) for x in split_file["testNdxs"]])
print("%d training images" % len(train_images))
print("%d test images" % len(test_images))
train_ids = [str(i - 1) for i in train_images]
test_ids = [str(i - 1) for i in test_images]
train_list_file = open(os.path.join(root, 'train.txt'), 'a')
write_txt(train_list_file, train_ids)
test_list_file = open(os.path.join(root, 'val.txt'), 'a')
write_txt(test_list_file, test_ids)
def labels_40(root):
print('Extracting labels with 40 classes from labels40.mat...')
data = loadmat(os.path.join(root, 'labels40.mat'))
labels = np.array(data['labels40'])
print(f'labels shape: {labels.shape}')
path_converted = os.path.join(root, 'labels40')
if not os.path.isdir(path_converted):
os.makedirs(path_converted)
bar = tqdm(range(labels.shape[2]))
for i in bar:
label = np.array(labels[:, :, i].transpose((1, 0)))
label_img = Image.fromarray(np.uint8(label))
label_img = label_img.transpose(Image.ROTATE_270)
label_img.save(os.path.join(path_converted, str(i) + '.png'), optimize=True)
def main():
root = os.path.dirname(__file__)
extract_data(root)
split(root)
labels_40(root)
if __name__ == '__main__':
main()
-
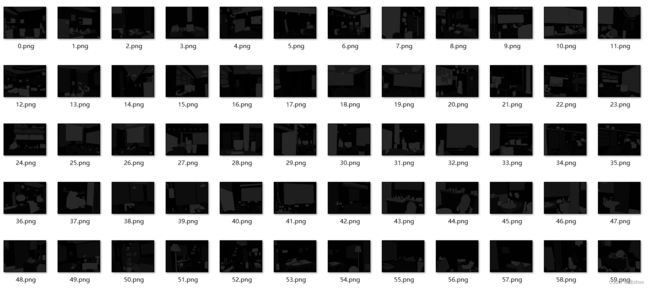
在生成的images文件夹中存放着原始图像,共1449张,如下图所示:
-
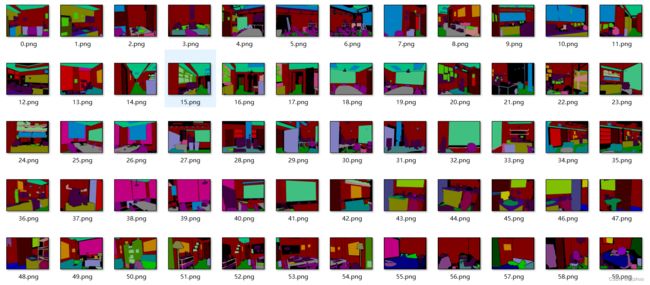
在生成的labels40文件夹中存放着40分类的分割图像,共1449张,如下图所示:
-
生成的train.txt和val.txt中存放训练集和验证集的划分,其中训练集795张,验证集654张
分割图像着色
- 在根目录下新建一个文件夹out_color40,然后运行
main.py,即可对分割图像着色,如下图所示:
## main.py
import os
import cv2
import numpy as np
import rgb2gray2rgb
import label2color
def label_color_label(img_path, color_map):
src_label = cv2.imread(img_path, cv2.IMREAD_UNCHANGED)
# resize
# src_label = cv2.resize(img, (256, 256))
'''
label2color
'''
color_img = rgb2gray2rgb.gray2color(src_label, color_map)
#save
dir, name = os.path.split(img_path)
save_path=os.path.join('./out_color40', name)
cv2.imwrite(save_path, color_img)
'''
color2label
'''
gray_img = rgb2gray2rgb.color2gray(color_img, color_map)
'''
原始lable图像的灰度值
lable2color2label图像的灰度值,
'''
pix_value = np.unique(src_label)
print('src_label_value', pix_value)
pix_value = np.unique(gray_img)
print("color2label_value", pix_value)
if __name__ == '__main__':
img_dir = './labels40/'
n_label = 41 # the number of label class
color_map1 = label2color.label_colormap(n_label=n_label, rgb1_bgr0=0)
'''
random gene color map
'''
random_state = np.random.RandomState(seed=1234)
color_custom_map = np.random.randint(low=0, high=255, size=(n_label, 3), dtype=np.uint8)
for img in sorted(os.listdir(img_dir)):
if not img.endswith((".png", ".jpg")):
continue
img_path = os.path.join(img_dir, img)
label_color_label(img_path, color_map1)
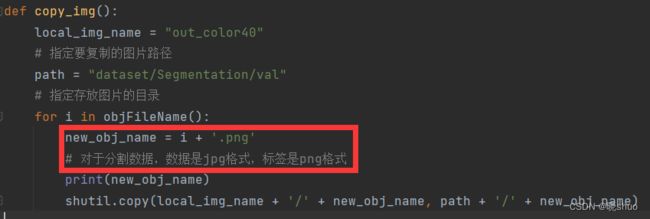
划分训练集和验证集
- 运行
splits_trainval.py,按照train.txt和val.txt的内容,将原始图像和分割图像划分为训练集和验证集
## splits_trainval.py
import shutil
import os
def objFileName():
local_file_name_list = "val.txt"
obj_name_list = []
for i in open(local_file_name_list, 'r'):
obj_name_list.append(i.replace('\n', ''))
return obj_name_list
def copy_img():
local_img_name = "out_color40"
# 指定要复制的图片路径
path = "dataset/Segmentation/val"
# 指定存放图片的目录
for i in objFileName():
new_obj_name = i + '.png'
# 对于分割数据,数据是jpg格式,标签是png格式
print(new_obj_name)
shutil.copy(local_img_name + '/' + new_obj_name, path + '/' + new_obj_name)
if __name__ == '__main__':
copy_img()
- 需要注意,原始图像的格式是.jpg,分割图像的格式是.png,在运行代码时需要根据图片格式进行修改