MATLAB说话人识别系统GUI界面
MATLAB说话人识别系统GUI界面
一、 选题背景、目的及意义
随着社会的快速发展,人民的生活水平逐渐提高,人们已经进入了互联网信息时代,对生活智能的追求再提高。在智能生活中,语音识别技术是一种人机交流的重要手段,语音识别在市场的应用和分布中十分普遍,同时在一些实际的应用中,语音识别技术是作为一个十分具有竞争力的关键点。比如在声音控制的领域中,计算机能够准确地识别出输入的语音内容是一个关键点,另外,还要根据识别结果来完成对应的动作。
计算机的发展日益迅猛,对这些设备的尺寸要求也越来越严格,并且有时候需要有特殊需求,比如在行走或驾驶时需要进行信息的输入,传统的键盘输入方式已不能满足用户要求,而需要更方便、自然地在行进中有效地输入信息。采用语音识别技术可以解放用户的手眼,有效地改变人机交互手段,如目前在一些手持计算机手机等嵌入式电子产品上已经使用语音识别技术来进行控制[1]。
为此,本课题就基于MATLAB的人声音特征的识别与控制展开研究。需要实现利用语音进行控制,用户需要说出指令,经过MATLAB处理的指令信号传入单片机,由单片机执行指令,人机交互十分方便,在目前的物联网时代有着广泛的运用前景,本课题也可以认为是人工智能时代的应用研究。语音的特点跟很多因素有关系,比如音调、音色、语速、说话人的情绪等。所以最为重要的是,建立合理的语音数学模型以及提取出语音信号参数的特征。本次毕业设计中对语音信号处理方面进行具有一定使用价值的研究。
二、 语音识别与控制系统方案设计
2.1 语音识别方式选择
目前语音识别的研究方向有3个:基于声道模型和语音知识的方法、利用人工神经网络的方法以及模版匹配的方法[7]。其中,方法1需要建立人类发音的数学模型,让计算机能够听懂人类的话。方法2是模仿人的大脑的神经活动,学习一门新的语音,从字到词语,从词语到句子,需要大量的数据库。方法3是模版匹配的方法,这种方法是目前使用得最多的方法,而且其算法相对简单,所以本次设计选择的是模板匹配方法。在模板匹配中也有多种匹配方式:
① 矢量量化方法(VQ)
矢量量化是将人的语音样品训练变为码本,辨别中把样品语音遵循训练得到的码本展开编码,其确定标准为量化形成的失真度。使用矢量量化进行语音识别,具有速度非常快的优势,并且辨别准度也很高。
② 隐马尔可夫模型方法(HMM)
隐马尔可夫模型技术有着非常广泛的使用。它将语音转换成为一些符号,并且把这些符号的序列合成看作随机的过程,此种符号在导出时表示为系统发声状态。简单地说HMM模型就是关于概率矩阵的一个数学模型,从已知推断未知。
③ 动态时间规整方法(DTW)
说话人信息不但存在稳定性原因(发声的器官构成与惯性),并且还存在变化性原因(语音速度及其声调,发声轻重与规律)。把辨别模板和参考模板在时间一致下进行对比,然后按照一定的距离检测出这两块模板之间的相同程度[5]。
以上三种方法,各有优点缺点,其中矢量量化方法主要是用于说话人识别的场合,而这次的设计不针对特定的人,而是识别语音的内容,所以不合适使用。隐马尔可夫模型建立起数学模型比较复杂,对出初学者而言难度有点大。所以综合以上,最终选择用动态时间规整(DTW)算法来实现本次设计。选择动态时间规整(DTW)算法的主要原因是,算法相对容易理解,在人语音识别领域应用比较广泛,比其他几种方法更容易编程实现。最终的识别率来看也是比较理想的,在软件设计一章将会对此做详细介绍。
2.2 语音识别/控制系统总体设计
语音识别就是指通过一定的数据信号处理,让机器理解说话人的意思。识别语音内容是从许多个词汇中分辨出该词汇的内容,是一种一对多的关系,这种技术利用的方式一般为模式匹配。语音控制就是将识别出的命令通过特定的一种通讯方式发送到下位机,实现对下位机单片机的控制,从而达到语音识别的目的。
要实现语音识别控制,就必须先对样本进行训练,训练后才可以达到识别的目的。样品训练一般表示为对数据的挖掘,通过对大量的样品训练,再从中抽取其实质参数。模式匹配即根据一种特殊的算法,让待识别的样本与训练后的样本的特征参数进行相似度的计算分析,最后得到一个最佳匹配。
语音识别/控制系统,显然包括了识别和控制两个部分,系统的主要组成部分包括上位机和下位机两个部分:
上位机模块:上位机主要是笔记本,笔记本声卡采集语音信息,利用MATLAB的数据处理功能首先对声音信号进行预处理、特征参数提取,语音规整,然后利用模板匹配算法进行语音识别,最后转化为指令发送到下位机,上位机和下位机之间的通讯方式为红外通讯。
下位机模块:下位机主要是基于单片机,接收到上位机信号后,单片机开始运行,控制被控对象完成相应的动作,本次控制对象对直流电机,通过语音信号控制电机的正反转,加速、减速、停止动作。
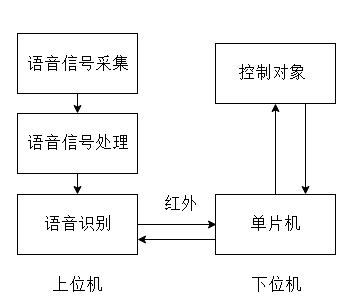
图2.1 语音识别/控制系统框图
三、 GUI设计
本次软件设计,一共分为两个部分,语音识别系统设计和控制系统设计。
其中语音识别系统的设计主要包括,模板训练、语音采集、端点检测、加窗分帧、特征参数提取、模板匹配、通讯程序以及人机交互界面设计几个部分。上位机的软件设计也是本次毕业设计的重点内容,语音识别的效果直接影响到了整个系统的运行。
控制系统软件设计是基于单片机的设计,主要分为串口通讯程序和电机控制程序两个部分。
3.1 语音识别系统设计
本次语音识别系统软件设计主要是基于MATLAB。MATLAB具有强大的数据处理功能,也被叫做矩阵实验室,在编程方面,MATLAB可以用C语言编写,同时MATLAB又提供许多可以调用的函数,另外利用MATLAB的GUI功能可以方便地绘制人机交互界面。本次语音识别系统软件设计分为,信号采集、信号预处理、特征参数提取、加窗分帧、端点检测等几个部分。软件流程图见下页:
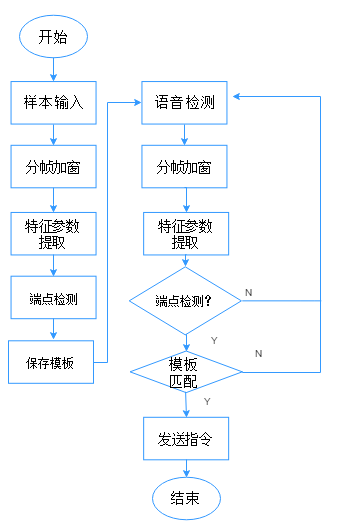
图4.1 语音识别软件流程图
3.1.1 语音信号采集
一般来说,采集语音可以通过三个步骤来实现。第一是使用传感器进行语音信号的接收然后进行信号放大和信号调理。第二是使用A/D转换电路把语音模拟信号转化为数字信号。第三部分就是使用电路接口把数字信号传送到PC机。在本次设计过程中使用的笔记本自带的声卡,调用了MATLAB声卡的使用函数,所以能够直接使用电脑内存声卡功能采取语音。
MATLAB中声卡调用函数为:
fs =44000;
R = audiorecorder(fs,16,2);
其中fs为采样频率,频率越高保真度越好,但是也不能过于高,一般来说根据人声的特点采样频率再8000Hz以上都可以,采样频率越高对硬件的要求也越高。16表示采样的数据以16bit保存,2表示采集两个声道的语音信号。
3.1.2 语音信号预处理
语音采样之后要对信号进行预处理,首先要对信号的幅值进行归一化[9]。方便后续处理,避免不必要的干扰;然后是通过高通滤波器,滤除一些低频噪声。最后是利用语音信号分帧,分帧是利用语音的短时间平稳特性[10]。将很长的语音信号进行分段,一般为是10ms以内, 也就是在时间域上将波动很大的语音信号分为成具有短而平稳特性的语音信号来处理。具体来说,是通过对语音信号加入窗函数来实现的, 即rw (n)= r(n)* w(n),其中r(n)为原始的语音信号, rw(n)加入窗函数后的语音信号, w(n) 为窗函数。窗函数,就像一个移动窗户,只有在窗函数一个区间是非零值,其他区间都是0,所以当信号卷积窗函数时,就相当于只取了那个区间的值。在语音信号的处理中, 一般选用汉明窗来进行语音的分帧。分帧示例图如下:
第k帧
第k+1帧
帧移 帧长
图4.2 帧长帧移示例图
通过预处理,语音信号变得比较容易分析,提取参数也比较容易。预处理MATLAB实现代码如下:
k=double(k);
k=k/max(abs(k)); %归一化
k=filter([1 -0.9375],1,k); %高通滤波
k=enframe(k,256,80); %调用窗函数
其中k为语音信号,在高通滤波器中参数为滤波器系数可以表示为方程 :
kj 为滤波后新得到的序列,ki为滤波前的序列,通过此差分滤波方程后语音信号会变得更平滑,有效地滤除一些低频的噪声。
预处理后的语音信号如下:

图4.3 预处理后语音信号
3.1.3 MFCC语音特征参数提取
MFCC是Mel频率倒谱系数的缩写。具体来说是对语音信号进行分帧处理后再对每一帧进行一种频谱特征参数的提取。如果是训练模板的语音样本就保存为一个模板参数文件,有待测语音信号进来时就调用模板参数文件进行模板匹配。MFCC语音特性参数提取在语音识别和说话人识别方面运用及其广泛,其处理的流程如下图:

图4.4 特征参数提取流程
3.1.4 端点检测
① 端点检测作用
端点检测就是去除一段语音信号中的无效部分,确定出有效语音信号的起点和终点。端点检测可以减少计算量,而且端点检测质量直接关系到模板匹配的准确度[12]。所以这一部分是十分关键的地方,要经过多次参数调试才能达到一种比较好的效果。
② 端点检测方法
本次设计使用的端点检测方法是双门限检测法及短时能量和短时平均过零率。
1)短时能量
短时能量就是计算一帧语音信号的能量幅值,其中S(n)为加窗后的语音信号。短时能量一般用在信噪比比较高的情况下,没有语音信号的时候,噪声能量很小, 而有语音信号的时候,能量明显增高, 所以比较好区分。其公式如下:
(4.3)
2)短时过零率
短时过零率是以一帧语音信号波形穿过横轴的次数作为检测的基础,也就是语音信号改变正负符号的次数[13]。
③ 软件实现
要实现端点检测主要是要将过零率高低门限和能量的高低门限参数设置正确,再做端点计算,参数的选择直接影响了端点检测的准确性,所以需要经过多次调试。当能量高于平均能量的1/8.2就可以当成是语音已经进入了过渡段,当语音信号能量高出平均能量的1/4.2可以当成是语音已经进入了语音段。过零率也起着一个辅助判断的作用。
MATLAB门限设置语句:
ZcrLow=max([round(mean(zcr)*0.1),3]); %过零率低门限
ZcrHigh=max([round(max(zcr)*0.1),5]); %过零率高门限
AmpLow=mean(amp)/8.2; % 能量低门限
AmpHigh=mean(amp)/4.2; % 能量高门限
④ 检测结果
检测结果如下,从下面图看出,同时运用这两种方法进行端点检测效果很明显,准确地找出了有效语音段的起点和终点,也就是有红色的竖线标记的地方。

图4.5 端点检测结果
3.1.5 DTW识别算法
① 算法原理
由于人说同一个词语的时间长短不一样,所以传统的距离检测方法不能很好的计算模板语音和测试语音的相似度。DTW算法是为了解决欧式距离等方法不能解决的序列长度不等的问题,计算两个时间长度不同的序列的相似程度。具体是通过找到这两个波形对齐的点,再计算它们的距离,而不是直接计算。把模板语音的各个帧号n=1~N在一个二维直角坐标系中的横轴上标出,把参考模板的各帧m=1~M在纵轴上标出[5]。用 i表示测试语音的帧数,j表示模板语音的帧数[14]。用网格线将这些语音帧都连接起来,目的是为了按照一定的约束条件一步一步计算,是用直线距离表示出模板语音与待测语音特征参数的之间的差别,找出距离最小的模板语音作为最佳匹配对象。一般来说,约束条件会约束每一步的步长和方向,每一步只能移动三个方向的其中一个方向,按照如下图所示的规则步移:
(i,j+1) (i+1,j+1)
(i,j) (i+1,j)
图4.6 DTW步移示意图
原理如下:
(4.5)

图4.7 DTW算法原理
② 算法特点
第一,由于要将待测语音与所有的模板匹配一次,然后再找出的那一个最佳匹配点,所以运算量是很大,所以识别的时间很长。第二,DTW识别算法识别的准确程度跟端点的检测结果有很大的关系[15]。但是可能因为噪声或者细小电流的影响端点检测而出现错误,例如无法识别到端点或者是将噪声当成有效语音等。但是本次设计端点检测的效果不错,所以这个问题影响不大,只是识别时间的问题。如果模板过少,识别速度较快但是相应的精度会下降,相反的想要提高识别率,只有加大模板的数量,随之识别时间又会增加,所以必须找出一个合适中间数,让识别时间和识别精度都达到一个比较理想的状态。
3.1.6 人机交互界面设计
人机交互界面是使用MATLAB的GUI来进行设计。在这个界面中,设置了两个按钮,一个模板导入,主要作用是为了形成模板数据的文件,在模板匹配的时候方便调用,再一次使用中这个按钮只需要用一次。另一个是声音采集按钮,主要作用是采集语音信号,说话人单击此按钮后有一个提示,需要按照提示进行语音。
总结人机交互界面的主要作用有以下几点:
① 提示说话者发送语音命令
② 显示语音识别结果
③ 显示电机当前工作状态
④ 直观地显示语音信号波形和端点检测结果
图4.9 GUI界面
四、 运行效果
打开GUI,首先点击模板导入按钮将模板参数储存为文档,然后在点击声音采集按钮,在文本框的提示下开始说话。三个波形图分别显示是:预处理后的语音以及端点检测,短时过零率以及短时能量。下面是当测试人员用普通话对着麦克风说‘反转’时,系统的反应:
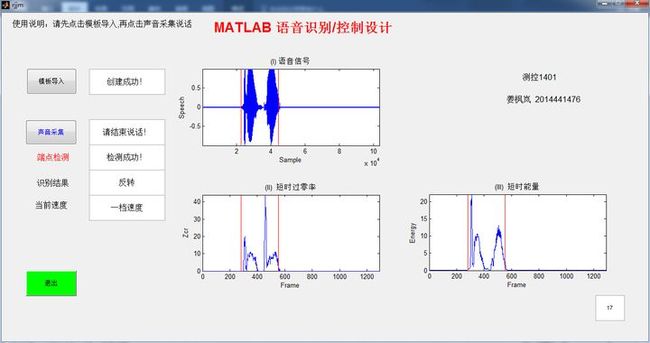
图4.1 GUI运行结果
源码参考
function pushbutton1_Callback(hObject, eventdata, handles)
% hObject handle to pushbutton1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
global R k
global StartPoint EndPoint FrameInc zcr amp
global zcrInd ampInd ref
fs =44000;
R = audiorecorder(fs,16,2);
str=['请开始说话....'];
set(handles.edit5, 'string',str);
record(R);
pause(2.4);
pause(R);
str=['请结束说话!'];
set(handles.edit5, 'string',str);
stop(R);
k=getaudiodata(R);
k=double(k);
k=k/max(abs(k));
t=0:1/fs:(length(k)-1)/fs;
axes(handles.axes1)
plot(t,k);
axis([0,(length(k)-1)/fs,min(k),max(k)]);
FrameLen=240;%帧长
FrameInc=80;%帧移
FrameTemp1=enframe(k(1:end-1),FrameLen,FrameInc); %分帧函数
FrameTemp2=enframe(k(2:end),FrameLen,FrameInc);
signs=(FrameTemp1.*FrameTemp2)<0;%矩阵小于等于零时赋值为1,大于零的赋值为0
diffs=abs(FrameTemp1-FrameTemp2)>0.01;%矩阵绝对值小于0.01为0,否者为1
zcr=sum(signs.*diffs,2);
zcrInd=1:length(zcr);
axes(handles.axes2)
plot(zcrInd,zcr);
axis([0,length(zcr),0,max(zcr)]);
amp=sum(abs(enframe(filter([1 -0.9375], 1, k), FrameLen, FrameInc)), 2);
ampInd=1:length(amp);
axes(handles.axes3)
plot(ampInd,amp);
axis([0,length(amp),0,max(amp)]);
ZcrLow=max([round(mean(zcr)*0.1),3]); %3to5 %过零率低门限
ZcrHigh=max([round(max(zcr)*0.1),5]); %5to7 %过零率高门限
AmpLow=mean(amp)/8.2; % 能量高门限
AmpHigh=mean(amp)/4.2;
MaxSilence=32; %最长语音间隙时间
MinAudio=16; %最短语音时间
Status=0; %状态:0静音段,1过渡段,2语音段,3结束段
HoldTime=0; %语音持续时间
SilenceTime=0; %语音间隙时间
for n=1:length(zcr)
switch Status
case{
0,1
}
if amp(n)>AmpHigh | zcr(n)>ZcrHigh
StartPoint=n-HoldTime;
Status=2;
HoldTime=HoldTime+1;
SilenceTime=0;
elseif amp(n)>AmpLow | zcr(n)>ZcrLow
Status=1;
HoldTime=HoldTime+1;
else
Status=0;
HoldTime=0;
end
case 2,
if amp(n)>AmpLow | zcr(n)>ZcrLow
HoldTime=HoldTime+1;
else
SilenceTime=SilenceTime+1;
if SilenceTime HoldTime=HoldTime+1; elseif (HoldTime-SilenceTime) Status=0; HoldTime=0; SilenceTime=0; else Status=3; end end case 3, break; end if Status==3 break; end end HoldTime=HoldTime-SilenceTime; EndPoint=StartPoint+HoldTime; if ((EndPoint-StartPoint)>=length(amp)*0.7) str=['检测失败','请重说']; set(handles.edit7, 'string',str); end if ((EndPoint-StartPoint) str=['检测成功','!']; set(handles.edit7, 'string',str); axes(handles.axes1) plot(k); axis([1,length(k),min(k),max(k)]); line([StartPoint*FrameInc,StartPoint*FrameInc],[min(k),max(k)],'color','red'); line([EndPoint*FrameInc,EndPoint*FrameInc],[min(k),max(k)],'color','red'); axes(handles.axes2) plot(zcrInd,zcr); axis([0,length(zcr),0,max(zcr)]); %line([StartPoint,StartPoint],[0,max(zcr)],'Color','red'); %line([EndPoint,EndPoint],[0,max(zcr)],'Color','red'); axes(handles.axes3) plot(ampInd,amp); axis([0,length(amp),0,max(amp)]); %line([StartPoint,StartPoint],[0,max(amp)],'Color','red'); %line([EndPoint,EndPoint],[0,max(amp)],'Color','red'); str=['正在识别','.....']; set(handles.edit4,'string',str); pause(0.1); cc=mfcc(k); cc=cc(StartPoint-2:EndPoint-2,:); test(1).StartPoint=StartPoint; test(1).EndPoint=EndPoint; test(1).mfcc=cc; dist = zeros(1,30) for j=1:30 dist(1,j) = dtw11(test(1).mfcc, ref(j).mfcc); end [d,j] = min(dist(1,:)); set(handles.edit9,'string',j); if d>700000 str=['无法识别!','']; set(handles.edit4,'string',str); end if j==1; str=['正转']; aa=[hex2dec('A1'),hex2dec('F1'),hex2dec('01'),hex2dec('01'),hex2dec('01')]; end if j==2; str=['反转']; aa=[hex2dec('A1'),hex2dec('F1'),hex2dec('02'),hex2dec('02'),hex2dec('02')]; end if j==3; str=['加速']; aa=[hex2dec('A1'),hex2dec('F1'),hex2dec('03'),hex2dec('03'),hex2dec('03')]; end if j==4; str=['减速']; aa=[hex2dec('A1'),hex2dec('F1'),hex2dec('04'),hex2dec('04'),hex2dec('04')]; end if j==5; str=['停止']; end set(handles.edit4,'string',str); s=serial('com7'); set(s,'BaudRate',9600,'StopBits',1,'Parity','none','DataBits',8,'InputBufferSize',255,'BytesAvailableFcnMode','byte'); fopen(s); fwrite(s,aa); pause(0.2); fwrite(s,aa); fwrite(s,aa); fclose(s); delete(s); clear s; end