python爬虫框架-PySpider
From: http://cuiqingcai.com/2652.html
From: http://python.jobbole.com/81109/
PySpider
PySpider github地址 PySpider 官方文档 PySpider 中文文档
PySpider是binux做的一个爬虫架构的开源化实现。主要的功能需求是:
- 1. 抓取、更新调度多站点的特定的页面
- 2. 需要对页面进行结构化信息提取
- 3. 灵活可扩展,稳定可监控
而这也是绝大多数python爬虫的需求 —— 定向抓取,结构化化解析。但是面对结构迥异的各种网站,单一的抓取模式并不一定能满足,灵活的抓取控制是必须的。为了达到这个目的,单纯的配置文件往往不够灵活,于是,通过脚本去控制抓取是最后的选择。
而去重调度,队列,抓取,异常处理,监控等功能作为框架,提供给抓取脚本,并保证灵活性。最后加上web的编辑调试环境,以及web任务监控,即成为了这套框架。
pyspider的设计基础是:以python脚本驱动的抓取环模型爬虫
- 1. 通过python脚本进行结构化信息的提取,follow链接调度抓取控制,实现最大的灵活性
- 2. 通过web化的脚本编写、调试环境。web展现调度状态
- 3. 抓取环模型成熟稳定,模块间相互独立,通过消息队列连接,从单进程到多机分布式灵活拓展
pyspider的架构主要分为 scheduler(调度器), fetcher(抓取器), processor(脚本执行):
- 1. 各个组件间使用消息队列连接,除了scheduler是单点的,fetcher 和 processor 都是可以多实例分布式部署的。 scheduler 负责整体的调度控制
- 2. 任务由 scheduler 发起调度,fetcher 抓取网页内容, processor 执行预先编写的python脚本,输出结果或产生新的提链任务(发往 scheduler),形成闭环。
- 3. 每个脚本可以灵活使用各种python库对页面进行解析,使用框架API控制下一步抓取动作,通过设置回调控制解析动作。
爬虫pyspider提供一个异常强大的网页界面(web ui),它允许你编辑和调试你的脚本,管理整个抓取过程,监控正在进行的任务,并最终输出结果。
项目和任务
在pyspider中,我们有项目和任务的概念。
一个任务指的是一个需要从网站检索并进行分析的单独页面。
一个项目指的是一个更大的实体,它包括爬虫涉及到的所有页面,分析网页所需要的python脚本,以及用于存储数据的数据库等等。
在pyspider中我们可以同时运行多个项目。代码结构分析
根目录:在根目录中可以找到的文件夹有:
•data,空文件夹,它是存放由爬虫所生成的数据的地方。
•docs,包含该项目文档,里边有一些markdown代码。
•pyspider,包含项目实际的代码。
•test,包含相当多的测试代码。这里重点介绍一些重要的文件:
•travis.yml,一个很棒的、连续性测试的整合。你如何确定你的项目确实有效?毕竟仅在你自己的带有固定版本的库的机器上进行测试是不够的。
•Dockerfile,同样很棒的工具!如果我想在我的机器上尝试一个项目,我只需要运行Docker,我不需要手动安装任何东西,这是一个使开发者参与到你的项目中的很好的方式。
•LICENSE,对于任何开源项目都是必需的,(如果你自己有开源项目的话)不要忘记自己项目中的该文件。
•requirements.txt,在Python世界中,该文件用于指明为了运行该软件,需要在你的系统中安装什么Python包,在任何的Python项目中该文件都是必须的。
•run.py,该软件的主入口点。
•setup.py,该文件是一个Python脚本,用于在你的系统中安装pyspider项目。分析完项目的根目录了,仅根目录就能说明该项目是以一种非常专业的方式进行开发的。如果你正在开发任何的开源程序,希望你能达到这样的水准。
文件夹pyspider
让我们更深入一点儿,一起来分析实际的代码。
在这个文件夹中还能找到其他的文件夹,整个软件背后的逻辑已经被分割,以便更容易的进行管理和扩展。
这些文件夹是:database、fetcher、libs、processor、result、scheduler、webui。
在这个文件夹中我们也能找到整个项目的主入口点,run.py。文件run.py
这个文件首先完成所有必需的杂事,以保证爬虫成功地运行。最终它产生所有必需的计算单元。向下滚动我们可以看到整个项目的入口点,cli()。函数cli()
这个函数好像很复杂,但与我相随,你会发现它并没有你想象中复杂。函数cli()的主要目的是创建数据库和消息系统的所有连接。它主要解析命令行参数,并利用所有我们需要的东西创建一个大字典。最后,我们通过调用函数all()开始真正的工作。函数all()
一个网络爬虫会进行大量的IO操作,因此一个好的想法是产生不同的线程或子进程来管理所有的这些工作。通过这种方式,你可以在等待网络获取你当前html页面的同时,提取前一个页面的有用信息。现在我们的爬虫就开始运行了,让我们进行更深入一点儿的探索。
调度程序
调度程序从两个不同的队列中获取任务(newtask_queue和status_queue),并把任务加入到另外一个队列(out_queue),这个队列稍后会被抓取程序读取。
调度程序做的第一件事情是从数据库中加载所需要完成的所有的任务。之后,它开始一个无限循环。在这个循环中会调用几个方法:
1._update_projects():尝试更新的各种设置,例如,我们想在爬虫工作的时候调整爬取速度。
2._check_task_done():分析已完成的任务并将其保存到数据库,它从status_queue中获取任务。
3._check_request():如果内容处理程序要求分析更多的页面,把这些页面放在队列newtask_queue中,该函数会从该队列中获得新的任务。
4._check_select():把新的网页加入到抓取程序的队列中。
5._check_delete():删除已被用户标记的任务和项目。
6._try_dump_cnt():记录一个文件中已完成任务的数量。对于防止程序异常所导致的数据丢失,这是有必要的。def run(self):
while not self._quit:
try:
time.sleep(self.LOOP_INTERVAL)
self._update_projects()
self._check_task_done()
self._check_request()
while self._check_cronjob():
pass
self._check_select()
self._check_delete()
self._try_dump_cnt()
self._exceptions = 0
except KeyboardInterrupt:
break
except Exception as e:
logger.exception(e)
self._exceptions += 1
if self._exceptions > self.EXCEPTION_LIMIT:
break
continuefinally:
# exit components run in subprocess
for each in threads:
if not each.is_alive():
continue
if hasattr(each, 'terminate'):
each.terminate()
each.join()抓取程序
抓取程序的目的是检索网络资源。
pyspider能够处理普通HTML文本页面和基于AJAX的页面。只有抓取程序能意识到这种差异,了解这一点非常重要。我们将仅专注于普通的html文本抓取,然而大部分的想法可以很容易地移植到Ajax抓取器。
这里的想法在某种形式上类似于调度程序,我们有分别用于输入和输出的两个队列,以及一个大的循环。对于输入队列中的所有元素,抓取程序生成一个请求,并将结果放入输出队列中。
它听起来简单但有一个大问题。网络通常是极其缓慢的,如果因为等待一个网页而阻止了所有的计算,那么整个过程将会运行的极其缓慢。解决方法非常的简单,即不要在等待网络的时候阻塞所有的计算。这个想法即在网络上发送大量消息,并且相当一部分消息是同时发送的,然后异步等待响应的返回。一旦我们收回一个响应,我们将会调用另外的回调函数,回调函数将会以最适合的方式管理这样的响应。
爬虫pyspider中的所有的复杂的异步调度都是由另一个优秀的开源项目tornado完成。
现在我们的脑海里已经有了极好的想法了,让我们更深入地探索这是如何实现的。
def run(self):
def queue_loop():
if not self.outqueue or not self.inqueue:
return
while not self._quit:
try:
if self.outqueue.full():
break
task = self.inqueue.get_nowait()
task = utils.decode_unicode_obj(task)
self.fetch(task)
except queue.Empty:
break
tornado.ioloop.PeriodicCallback(queue_loop, 100, io_loop=self.ioloop).start()
self._running = True
self.ioloop.start()
函数run()中定义了另外一个函数queue_loop(),该函数接收输入队列中的所有任务,并抓取它们。同时该函数也监听中断信号。函数queue_loop()作为参数传递给tornado的类PeriodicCallback,如你所猜,PeriodicCallback会每隔一段具体的时间调用一次queue_loop()函数。函数queue_loop()也会调用另一个能使我们更接近于实际检索Web资源操作的函数:fetch()。
函数fetch(self, task, callback=None)
网络上的资源必须使用函数phantomjs_fetch()或简单的http_fetch()函数检索,函数fetch()只决定检索该资源的正确方法是什么。接下来我们看一下函数http_fetch()。
函数http_fetch(self, url, task, callback)
def http_fetch(self, url, task, callback):
'''HTTP fetcher'''
fetch = copy.deepcopy(self.default_options)
fetch['url'] = url
fetch['headers']['User-Agent'] = self.user_agent
def handle_response(response):
...
return task, result
try:
request = tornado.httpclient.HTTPRequest(header_callback=header_callback, **fetch)
if self.async:
self.http_client.fetch(request, handle_response)
else:
return handle_response(self.http_client.fetch(request))在函数的开始部分,它设置了抓取请求的header,比如User-Agent、超时timeout等等。然后定义一个处理响应response的函数:handle_response(),后边我们会分析这个函数。最后我们得到一个tornado的请求对象request,并发送这个请求对象。请注意在异步和非异步的情况下,是如何使用相同的函数来处理响应response的。
让我们往回看一下,分析一下函数handle_response()做了什么。
函数handle_response(response)
def handle_response(response):
result = {}
result['orig_url'] = url
result['content'] = response.body or ''
callback('http', task, result)
return task, result这个函数以字典的形式保存一个response的所有相关信息,例如url,状态码和实际响应等,然后调用回调函数。这里的回调函数是一个小方法:send_result()。
函数send_result(self, type, task, result)
def send_result(self, type, task, result):
if self.outqueue:
self.outqueue.put((task, result))内容处理程序processor
内容处理程序的目的是分析已经抓取回来的页面。它的过程同样也是一个大循环,但输出中有三个队列(status_queue, newtask_queue 以及result_queue)而输入中只有一个队列(inqueue)。
让我们稍微深入地分析一下函数run()中的循环过程。
函数run(self)
def run(self):
try:
task, response = self.inqueue.get(timeout=1)
self.on_task(task, response)
self._exceptions = 0
except KeyboardInterrupt:
break
except Exception as e:
self._exceptions += 1
if self._exceptions > self.EXCEPTION_LIMIT:
break
continue这个函数的代码比较少,易于理解,它简单地从队列中得到需要被分析的下一个任务,并利用on_task(task, response)函数对其进行分析。这个循环监听中断信号,只要我们给Python发送这样的信号,这个循环就会终止。最后这个循环统计它引发的异常的数量,异常数量过多会终止这个循环。
函数on_task(self, task, response)
def on_task(self, task, response):
response = rebuild_response(response)
project = task['project']
project_data = self.project_manager.get(project, updatetime)
ret = project_data['instance'].run(
status_pack = {
'taskid': task['taskid'],
'project': task['project'],
'url': task.get('url'),
...
}
self.status_queue.put(utils.unicode_obj(status_pack))
if ret.follows:
self.newtask_queue.put(
[utils.unicode_obj(newtask) for newtask in ret.follows])
for project, msg, url in ret.messages:
self.inqueue.put(({...},{...}))
return True函数on_task()是真正干活的方法。
它尝试利用输入的任务找到任务所属的项目。然后它运行项目中的定制脚本。最后它分析定制脚本返回的响应response。如果一切顺利,将会创建一个包含所有我们从网页上得到的信息的字典。最后将字典放到队列status_queue中,稍后它会被调度程序重新使用。
如果在分析的页面中有一些新的链接需要处理,新链接会被放入到队列newtask_queue中,并在稍后被调度程序使用。
现在,如果有需要的话,pyspider会将结果发送给其他项目。
最后如果发生了一些错误,像页面返回错误,错误信息会被添加到日志中。
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
Scrapy 使用了 Twisted 异步网络库来处理网络通讯。整体架构大致如下

Scrapy主要包括了以下组件:
- 1. 引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 2. 调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 3. 下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 4. 爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 5. 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 6. 下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 7. 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 8. 调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 1. 首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 2. 引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
- 3. 然后,爬虫解析Response
- 4. 若是解析出实体(Item),则交给实体管道进行进一步的处理。
- 5. 若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
安装
1. pip。首先确保你已经安装了pip,若没有安装,请参照 pip安装
2. phantomjs。PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它全面支持web而不需浏览器支持,其快速、原生支持各种Web标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。 PhantomJS 可以用于页面自动化、网络监测、网页截屏以及无界面测试等。phantomjs安装
3. pyspider。直接利用 pip 安装即可:pip install pyspider。如果你是 Ubuntu 用户,请提前安装好以下支持类库
sudo apt-get install python python-dev python-distribute python-pip libcurl4-openssl-dev libxml2-dev libxslt1-dev python-lxml4. 测试。如果安装过程没有提示任何错误,那就证明一些OK。命令行输入:pyspider all (这句命令的意思是,运行 pyspider 并 启动它的所有组件。)。然后浏览器访问 http://localhost:5000 观察一下效果,如果可以正常出现 PySpider 的页面,那证明一切OK,在此附图一张,这是我写了几个爬虫之后的界面。
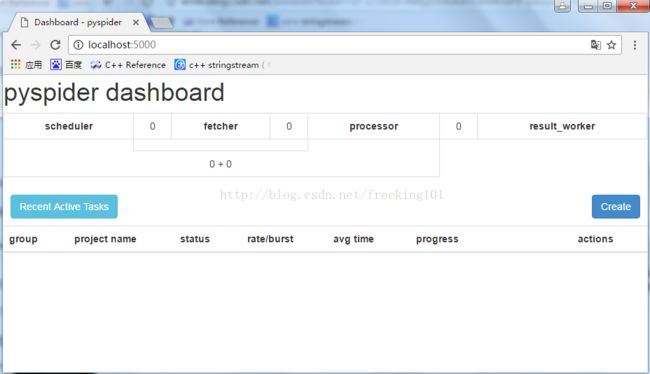
接下来我会进一步介绍这个框架的使用。
PySpider的用法
1. 抓取淘宝MM照片
PySpider 是一个非常方便并且功能强大的爬虫框架,支持多线程爬取、JS动态解析,提供了可操作界面、出错重试、定时爬取等等的功能,使用非常人性化。
爬取目标网站:https://mm.taobao.com/json/request_top_list.htm?page=1,大家打开之后可以看到许多淘宝MM的列表。
列表有多少?
https://mm.taobao.com/json/request_top_list.htm?page=10000,第10000页都有,看你想要多少。我什么也不知道。
随机点击一位 MM 的姓名,可以看到她的基本资料。
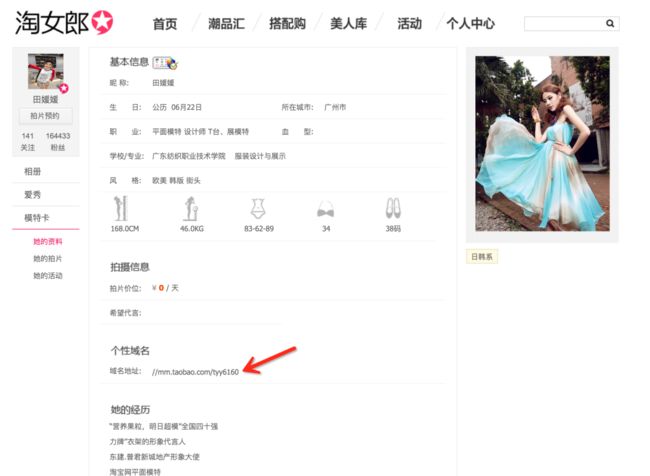
可以看到图中有一个个性域名,我们复制到浏览器打开。mm.taobao.com/tyy6160
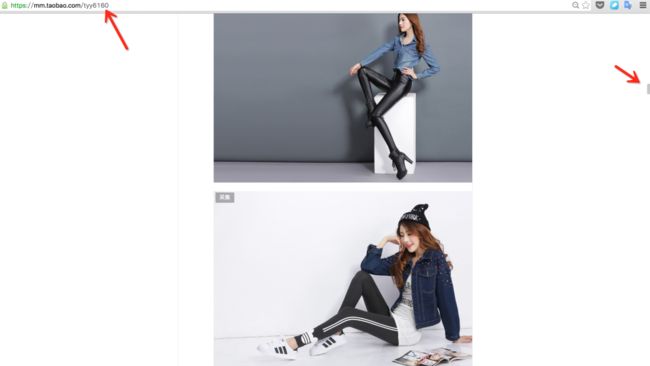
嗯,往下拖,海量的 MM 图片都在这里了,怎么办你懂得,我们要把她们的照片和个人信息都存下来。
P.S. 注意图中进度条!你猜有多少图片~
命令行下执行:pyspider all。这句命令的意思是,运行 pyspider 并 启动它的所有组件。

可以发现程序已经正常启动,并在 5000 这个端口运行。接下来在浏览器中输入 http://localhost:5000,可以看到 PySpider 的主界面,点击右下角的 Create,命名为 taobaomm,当然名称你可以随意取,继续点击 Create。
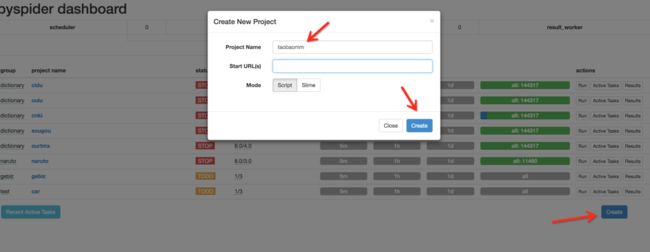
这样我们会进入到一个爬取操作的页面。
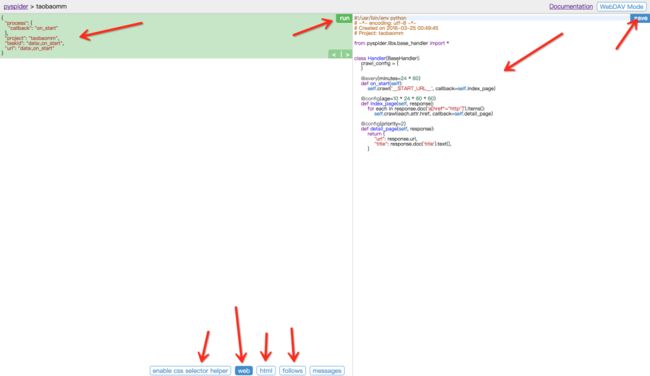
整个页面分为两栏,左边是爬取页面预览区域,右边是代码编写区域。下面对区块进行说明:
左侧绿色区域:这个请求对应的 JSON 变量,在 PySpider 中,其实每个请求都有与之对应的 JSON 变量,包括回调函数,方法名,请求链接,请求数据等等。
绿色区域右上角Run:点击右上角的 run 按钮,就会执行这个请求,可以在左边的白色区域出现请求的结果。
左侧 enable css selector helper: 抓取页面之后,点击此按钮,可以方便地获取页面中某个元素的 CSS 选择器。
左侧 web: 即抓取的页面的实时预览图。
左侧 html: 抓取页面的 HTML 代码。
左侧 follows: 如果当前抓取方法中又新建了爬取请求,那么接下来的请求就会出现在 follows 里。
左侧 messages: 爬取过程中输出的一些信息。
右侧代码区域: 你可以在右侧区域书写代码,并点击右上角的 Save 按钮保存。
右侧 WebDAV Mode: 打开调试模式,左侧最大化,便于观察调试。
依然是上面那个网址,https://mm.taobao.com/json/request_top_list.htm?page=1,其中 page 参数代表页码。所以我们暂时抓取前 30 页。页码到最后可以随意调整。首先我们定义基地址,然后定义爬取的页码和总页码。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
def __init__(self):
self.base_url = 'https://mm.taobao.com/json/request_top_list.htm?page='
self.page_num = 1
self.total_num = 30
@every(minutes=24 * 60)
def on_start(self):
while self.page_num <= self.total_num:
url = self.base_url + str(self.page_num)
print url
self.crawl(url, callback=self.index_page)
self.page_num += 1
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}点击 save 保存代码,然后点击左边的 run,运行代码。
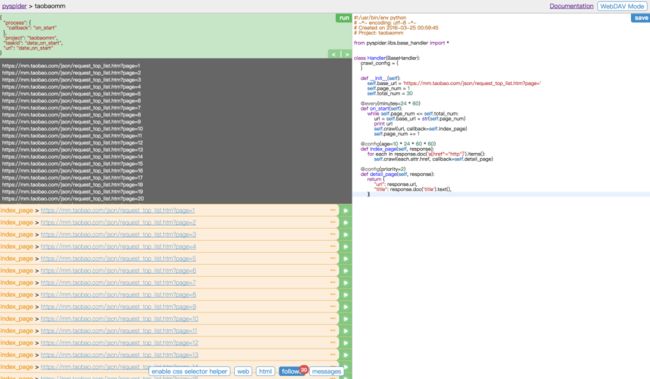
运行后我们会发现 follows 出现了 30 这个数字,说明我们接下来有 30 个新请求,点击可查看所有爬取列表。另外控制台也有输出,将所有要爬取的 URL 打印了出来。
然后我们点击左侧任意一个绿色箭头,可以继续爬取这个页面。例如点击第一个 URL,来爬取这个 URL
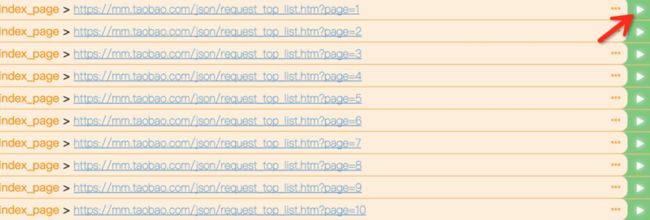
点击之后,再查看下方的 web 页面,可以预览实时页面,这个页面被我们爬取了下来,并且回调到 index_page 函数来处理,目前 index_page 函数我们还没有处理,所以是继续构件了所有的链接请求。
好,接下来我们怎么办?当然是进入到 MM 到个人页面去爬取了。
爬取到了 MM 的列表,接下来就要进入到 MM 详情页了,修改 index_page 方法。
def index_page(self, response):
for each in response.doc('.lady-name').items():
self.crawl(each.attr.href, callback=self.detail_page)其中 response 就是刚才爬取的列表页,response 其实就相当于列表页的 html 代码,利用 doc 函数,其实是调用了 PyQuery,用 CSS 选择器得到每一个MM的链接,然后重新发起新的请求。比如,我们这里拿到的 each.attr.href 可能是 mm.taobao.com/self/model_card.htm?user_id=687471686,在这里继续调用了 crawl 方法,代表继续抓取这个链接的详情。
self.crawl(each.attr.href, callback=self.detail_page)然后回调函数就是 detail_page,爬取的结果会作为 response 变量传过去。detail_page 接到这个变量继续下面的分析。
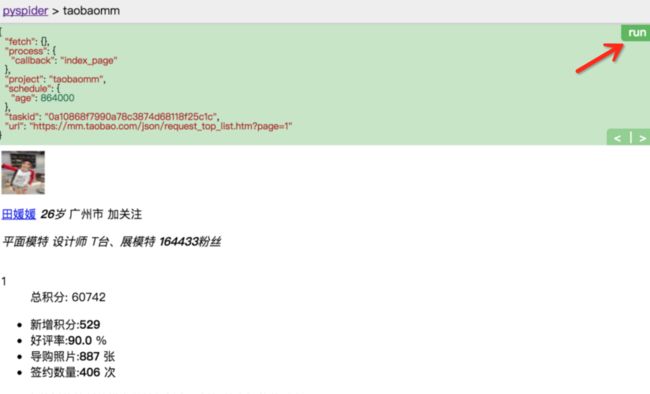
好,我们继续点击 run 按钮,开始下一个页面的爬取。得到的结果是这样的。
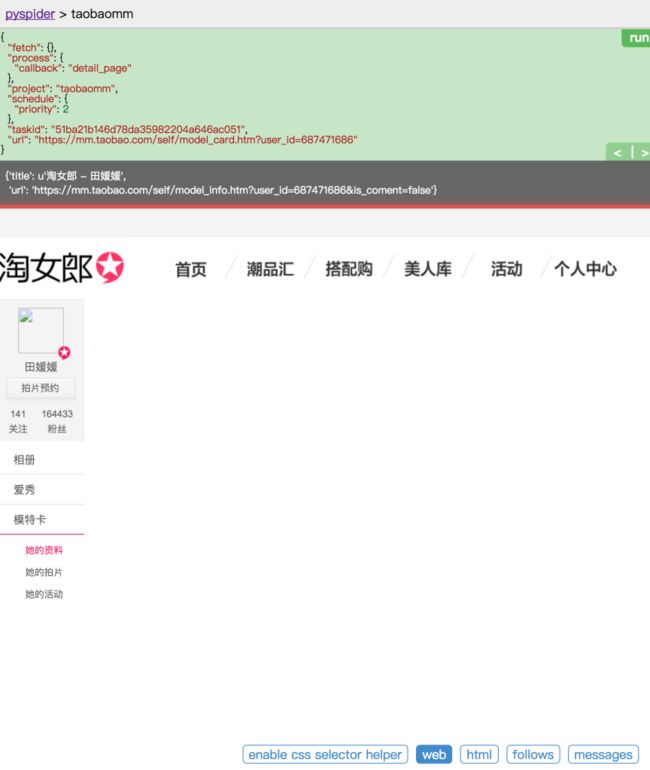
哦,有些页面没有加载出来,这是为什么?在之前的文章说过,这个页面比较特殊,右边的页面使用 JS 渲染生成的,而普通的抓取是不能得到 JS 渲染后的页面的,这可麻烦了。然而,幸运的是,PySpider 提供了动态解析 JS 的机制。
友情提示:可能有的小伙伴不知道 PhantomJS,可以参考:Python爬虫利器五之Selenium的用法
如果已经装好了 PhantomJS,这时候就轮到它来出场了。在最开始运行 PySpider 的时候,使用了pyspider all命令,这个命令是把 PySpider 所有的组件启动起来,其中也包括 PhantomJS。
所以我们代码怎么改呢?很简单。
def index_page(self, response):
for each in response.doc('.lady-name').items():
self.crawl(each.attr.href, callback=self.detail_page, fetch_type='js')只是简单地加了一个 fetch_type=’js’,点击绿色的返回箭头,重新运行一下。可以发现,页面已经被我们成功加载出来了,简直不能更帅!
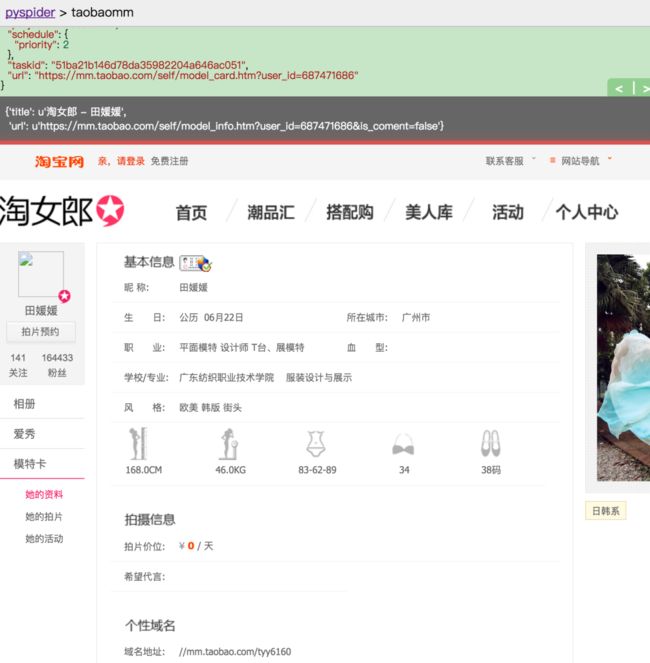
看下面的个性域名,所有我们需要的 MM 图片都在那里面了,所以我们需要继续抓取这个页面。
好,继续修改 detail_page 方法,然后增加一个 domain_page 方法,用来处理每个 MM 的个性域名。
def detail_page(self, response):
domain = 'https:' + response.doc('.mm-p-domain-info li > span').text()
print domain
self.crawl(domain, callback=self.domain_page)
def domain_page(self, response):
pass好,继续重新 run,预览一下页面,终于,我们看到了 MM 的所有图片。

照片都有了,那么我们就偷偷地下载下来吧~。完善 domain_page 代码,实现保存简介和遍历保存图片的方法。
在这里,PySpider 有一个特点,所有的 request 都会保存到一个队列中,并具有去重和自动重试机制。所以,我们最好的解决方法是,把每张图片的请求都写成一个 request,然后成功后用文件写入即可,这样会避免图片加载不全的问题。
曾经在之前文章写过图片下载和文件夹创建的过程,在这里就不多赘述原理了,直接上写好的工具类,后面会有完整代码。
import os
class Deal:
def __init__(self):
self.path = DIR_PATH
if not self.path.endswith('/'):
self.path = self.path + '/'
if not os.path.exists(self.path):
os.makedirs(self.path)
def mkDir(self, path):
path = path.strip()
dir_path = self.path + path
exists = os.path.exists(dir_path)
if not exists:
os.makedirs(dir_path)
return dir_path
else:
return dir_path
def saveImg(self, content, path):
f = open(path, 'wb')
f.write(content)
f.close()
def saveBrief(self, content, dir_path, name):
file_name = dir_path + "/" + name + ".txt"
f = open(file_name, "w+")
f.write(content.encode('utf-8'))
def getExtension(self, url):
extension = url.split('.')[-1]
return extension这里面包含了四个方法。
mkDir:创建文件夹,用来创建 MM 名字对应的文件夹。
saveBrief: 保存简介,保存 MM 的文字简介。
saveImg: 传入图片二进制流以及保存路径,存储图片。
getExtension: 获得链接的后缀名,通过图片 URL 获得。然后在 domain_page 中具体实现如下
def domain_page(self, response):
name = response.doc('.mm-p-model-info-left-top dd > a').text()
dir_path = self.deal.mkDir(name)
brief = response.doc('.mm-aixiu-content').text()
if dir_path:
imgs = response.doc('.mm-aixiu-content img').items()
count = 1
self.deal.saveBrief(brief, dir_path, name)
for img in imgs:
url = img.attr.src
if url:
extension = self.deal.getExtension(url)
file_name = name + str(count) + '.' + extension
count += 1
self.crawl(img.attr.src, callback=self.save_img,
save={'dir_path': dir_path, 'file_name': file_name})
def save_img(self, response):
content = response.content
dir_path = response.save['dir_path']
file_name = response.save['file_name']
file_path = dir_path + '/' + file_name
self.deal.saveImg(content, file_path)以上方法首先获取了页面的所有文字,然后调用了 saveBrief 方法存储简介。
然后遍历了 MM 所有的图片,并通过链接获取后缀名,和 MM 的姓名以及自增计数组合成一个新的文件名,调用 saveImg 方法保存图片。
基本的东西都写好了。接下来。继续完善一下代码。第一版本完成。
版本一功能:按照淘宝MM姓名分文件夹,存储MM的 txt 文本简介以及所有美图至本地。
可配置项:
PAGE_START: 列表开始页码
PAGE_END: 列表结束页码
DIR_PATH: 资源保存路径#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2016-03-25 00:59:45
# Project: taobaomm
from pyspider.libs.base_handler import *
PAGE_START = 1
PAGE_END = 30
DIR_PATH = '/var/py/mm'
class Handler(BaseHandler):
crawl_config = {
}
def __init__(self):
self.base_url = 'https://mm.taobao.com/json/request_top_list.htm?page='
self.page_num = PAGE_START
self.total_num = PAGE_END
self.deal = Deal()
def on_start(self):
while self.page_num <= self.total_num:
url = self.base_url + str(self.page_num)
self.crawl(url, callback=self.index_page)
self.page_num += 1
def index_page(self, response):
for each in response.doc('.lady-name').items():
self.crawl(each.attr.href, callback=self.detail_page, fetch_type='js')
def detail_page(self, response):
domain = response.doc('.mm-p-domain-info li > span').text()
if domain:
page_url = 'https:' + domain
self.crawl(page_url, callback=self.domain_page)
def domain_page(self, response):
name = response.doc('.mm-p-model-info-left-top dd > a').text()
dir_path = self.deal.mkDir(name)
brief = response.doc('.mm-aixiu-content').text()
if dir_path:
imgs = response.doc('.mm-aixiu-content img').items()
count = 1
self.deal.saveBrief(brief, dir_path, name)
for img in imgs:
url = img.attr.src
if url:
extension = self.deal.getExtension(url)
file_name = name + str(count) + '.' + extension
count += 1
self.crawl(img.attr.src, callback=self.save_img,
save={'dir_path': dir_path, 'file_name': file_name})
def save_img(self, response):
content = response.content
dir_path = response.save['dir_path']
file_name = response.save['file_name']
file_path = dir_path + '/' + file_name
self.deal.saveImg(content, file_path)
import os
class Deal:
def __init__(self):
self.path = DIR_PATH
if not self.path.endswith('/'):
self.path = self.path + '/'
if not os.path.exists(self.path):
os.makedirs(self.path)
def mkDir(self, path):
path = path.strip()
dir_path = self.path + path
exists = os.path.exists(dir_path)
if not exists:
os.makedirs(dir_path)
return dir_path
else:
return dir_path
def saveImg(self, content, path):
f = open(path, 'wb')
f.write(content)
f.close()
def saveBrief(self, content, dir_path, name):
file_name = dir_path + "/" + name + ".txt"
f = open(file_name, "w+")
f.write(content.encode('utf-8'))
def getExtension(self, url):
extension = url.split('.')[-1]
return extension粘贴到你的 PySpider 中运行吧~。其中有一些知识点,我会在后面作详细的用法总结。大家可以先体会一下代码。
保存之后,点击下方的 run,你会发现,海量的 MM 图片已经涌入你的电脑啦~

项目代码:
TaobaoMM – GitHub
pyspider 爬虫教程
From: https://segmentfault.com/a/1190000002477863
(一):HTML 和 CSS 选择器
在 教程一 中,我们将要爬取的网站是豆瓣电影:http://movie.douban.com/
你可以在: http://demo.pyspider.org/debug/tutorial_douban_movie 获得完整的代码,和进行测试。
开始之前由于教程是基于 pyspider 的,你可以安装一个 pyspider(Quickstart,也可以直接使用 pyspider 的 demo 环境: http://demo.pyspider.org/。
你还应该至少对万维网是什么有一个简单的认识:
- 万维网是一个由许多互相链接的超文本页面(以下简称网页)组成的系统。
- 网页使用网址(URL)定位,并链接彼此
- 网页使用 HTTP 协议传输
- 网页使用 HTML 描述外观和语义
所以,爬网页实际上就是:
- 找到包含我们需要的信息的网址(URL)列表
- 通过 HTTP 协议把页面下载回来
- 从页面的 HTML 中解析出需要的信息
- 找到更多这个的 URL,回到 2 继续
既然我们要爬所有的电影,首先我们需要抓一个电影列表,一个好的列表应该:
- 包含足够多的电影的 URL
- 通过翻页,可以遍历到所有的电影
- 一个按照更新时间排序的列表,可以更快抓到最新更新的电影
我们在 http://movie.douban.com/ 扫了一遍,发现并没有一个列表能包含所有电影,只能退而求其次,通过抓取分类下的所有的标签列表页,来遍历所有的电影: http://movie.douban.com/tag/
创建一个项目在 pyspider 的 dashboard 的右下角,点击 "Create" 按钮
替换 on_start 函数的 self.crawl 的 URL:
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://movie.douban.com/tag/', callback=self.index_page)-
self.crawl告诉 pyspider 抓取指定页面,然后使用callback函数对结果进行解析。 -
@every修饰器,表示on_start每天会执行一次,这样就能抓到最新的电影了。
点击绿色的 run 执行,你会看到 follows 上面有一个红色的 1,切换到 follows 面板,点击绿色的播放按钮:
Tag 列表页
在 tag 列表页 中,我们需要提取出所有的 电影列表页 的 URL。你可能已经发现了,sample handler 已经提取了非常多大的 URL,所有,一种可行的提取列表页 URL 的方法就是用正则从中过滤出来:
import re
...
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://movie.douban.com/tag/\w+", each.attr.href, re.U):
self.crawl(each.attr.href, callback=self.list_page)- 由于 电影列表页和 tag列表页长的并不一样,在这里新建了一个
callback为self.list_page -
@config(age=10 * 24 * 60 * 60)在这表示我们认为 10 天内页面有效,不会再次进行更新抓取
电影列表页
再次点击 run 让我们进入一个电影列表页(list_page)。在这个页面中我们需要提取:
- 电影的链接,例如,http://movie.douban.com/subject/1292052/
- 下一页的链接,用来翻页
CSS选择器,顾名思义,是 CSS 用来定位需要设置样式的元素 所使用的表达式。既然前端程序员都使用 CSS选择器 为页面上的不同元素设置样式,我们也可以通过它定位需要的元素。你可以在 CSS 选择器参考手册 这里学习更多的 CSS选择器 语法。
在 pyspider 中,内置了 response.doc 的 PyQuery 对象,让你可以使用类似 jQuery 的语法操作 DOM 元素。你可以在 PyQuery 的页面上找到完整的文档。
在 pyspider 中,还内置了一个 CSS Selector Helper,当你点击页面上的元素的时候,可以帮你生成它的 CSS选择器 表达式。你可以点击 Enable CSS selector helper 按钮,然后切换到 web 页面:
开启后,鼠标放在元素上,会被黄色高亮,点击后,所有拥有相同 CSS选择器 表达式的元素会被高亮。表达式会被插入到 python 代码当前光标位置。创建下面的代码,将光标停留在单引号中间:
def list_page(self, response):
for each in response.doc('').items():点击一个电影的链接,CSS选择器 表达式将会插入到你的代码中,如此重复,插入翻页的链接:
def list_page(self, response):
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV>TABLE TR.item>TD>DIV.pl2>A').items():
self.crawl(each.attr.href, callback=self.detail_page)
# 翻页
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.paginator>A').items():
self.crawl(each.attr.href, callback=self.list_page)- 翻页是一个到自己的
callback回调
再次点击 run,follow 到详情页。使用 css selector helper 分别添加电影标题,打分和导演:
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('HTML>BODY>DIV#wrapper>DIV#content>H1>SPAN').text(),
"rating": response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.indent.clearfix>DIV.subjectwrap.clearfix>DIV#interest_sectl>DIV.rating_wrap.clearbox>P.rating_self.clearfix>STRONG.ll.rating_num').text(),
"导演": [x.text() for x in response.doc('a[rel="v:directedBy"]').items()],
} 注意,你会发现 css selector helper 并不是总是能提取到合适的 CSS选择器 表达式。你可以在 Chrome Dev Tools 的帮助下,写一个合适的表达式:
右键点击需要提取的元素,点击审查元素。你并不需要像自动生成的表达式那样写出所有的祖先节点,只要写出那些能区分你不需要的元素的关键节点的属性就可以了。不过这需要抓取和网页前端的经验。所以,学习抓取的最好方法就是学会这个页面/网站是怎么写的。
你也可以在 Chrome Dev Tools 的 Javascript Console 中,使用 $$(a[rel="v:directedBy"]) 测试 CSS Selector。
- 使用
run单步调试你的代码,对于用一个callback最好使用多个页面类型进行测试。然后保存。 - 回到 Dashboard,找到你的项目
- 将
status修改为DEBUG或RUNNING - 按
run按钮
(二):AJAX 和 HTTP
From: https://segmentfault.com/a/1190000002477870
在上面教程中,用 self.crawl API 抓取豆瓣电影的 HTML 内容,并使用 CSS 选择器解析了一些内容。不过,现在的网站通过使用 AJAX 等技术,在你与服务器交互的同时,不用重新加载整个页面。但是,这些交互手段,让抓取变得稍微难了一些:你会发现,这些网页在抓回来后,和浏览器中的并不相同。你需要的信息并不在返回 HTML 代码中。
在这一篇教程中,我们会讨论这些技术 和 抓取他们的方法。(英文版:AJAX-and-more-HTTP)
AJAX
AJAX 是 Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)的缩写。AJAX 通过使用原有的 web 标准组件,实现了在不重新加载整个页面的情况下,与服务器进行数据交互。例如在新浪微博中,你可以展开一条微博的评论,而不需要重新加载,或者打开一个新的页面。但是这些内容并不是一开始就在页面中的(这样页面就太大了),而是在你点击的时候被加载进来的。这就导致了你抓取这个页面的时候,并不能获得这些评论信息(因为你没有『展开』)。
AJAX 的一种常见用法是使用 AJAX 加载 JSON 数据,然后在浏览器端渲染。如果能直接抓取到 JSON 数据,会比 HTML 更容易解析。
当一个网站使用了 AJAX 的时候,除了用 pyspider 抓取到的页面和浏览器看到的不同以外。你在浏览器中打开这样的页面,或者点击『展开』的时候,常常会看到『加载中』或者类似的图标/动画。例如,当你尝试抓取:http://movie.douban.com/explore
你会发现电影是『载入中...』
找到真实的请求
由于 AJAX 实际上也是通过 HTTP 传输数据的,所以我们可以通过 Chrome Developer Tools 找到真实的请求,直接发起真实请求的抓取就可以获得数据了。
- 打开一个新窗口
- 按
Ctrl+Shift+I(在 Mac 上请按Cmd+Opt+I) 打开开发者工具。 - 切换到网络( Netwotk 面板)
- 在窗口中打开 http://movie.douban.com/explore
在页面加载的过程中,你会在面板中看到所有的资源请求。
AJAX 一般是通过 XMLHttpRequest 对象接口发送请求的,XMLHttpRequest 一般被缩写为 XHR。点击网络面板上漏斗形的过滤按钮,过滤出 XHR 请求。挨个查看每个请求,通过访问路径和预览,找到包含信息的请求: http://movie.douban.com/j/searchX 61Xsubjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
在豆瓣这个例子中,XHR 请求并不多,可以挨个查看来确认。但在 XHR 请求较多的时候,可能需要结合触发动作的时间,请求的路径等信息帮助在大量的请求中找到包含信息的关键请求。这需要抓取或者前端的相关经验。所以,有一个我一直在提的观点,学习抓取的最好方法是:学会写网站。
现在可以在新窗口中打开 http://movie.douban.com/j/searchX67Xsubjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0,你会看到包含电影数据的 JSON 原始数据。推荐安装 JSONView(Firfox版)插件,这样可以看到更好看的 JSON 格式,展开折叠列等功能。然后,我们根据 JSON 数据,编写一个提取电影名和评分的脚本:
class Handler(BaseHandler):
def on_start(self):
self.crawl('http://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0',
callback=self.json_parser)
def json_parser(self, response):
return [{
"title": x['title'],
"rate": x['rate'],
"url": x['url']
} for x in response.json['subjects']]- 你可以使用
response.json将结果转为一个 python 的dict对象
HTTP
HTTP 是用来传输网页内容的协议。在前面已经通过 self.crawl 接口提交了 URL 进行了抓取。这些抓取就是通过 HTTP 协议传输的。
在抓取过程中,你可能会遇到类似 403 Forbidden,或者需要登录的情况,这时候你就需要正确的 HTTP 参数进行抓取了。
一个典型的 HTTP 请求包如下,这个请求是发往 http://example.com/ 的:
GET / HTTP/1.1
Host: example.com
Connection: keep-alive
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.45 Safari/537.36
Referer: http://en.wikipedia.org/wiki/Example.com
Accept-Encoding: gzip, deflate, sdch
Accept-Language: zh-CN,zh;q=0.8
If-None-Match: "359670651"
If-Modified-Since: Fri, 09 Aug 2013 23:54:35 GMT- 请求的第一行包含
method,path和 HTTP 协议的版本信息 - 余下的行被称为 header,是以
key: value的形式呈现的 - 如果是 POST 请求,在请求结尾可能还会有
body内容
在大多数时候,使用正确的 method, path, headers 和 body 总是能抓取到你需要的信息的。
HTTP Method
HTTP Method 告诉服务器对 URL 资源期望进行的操作。例如在打开一个 URL 的时候使用的是 GET 方式,而在提交数据的时候一般使用 POST。
TODO: need example here
HTTP HeadersHTTP Headers 是请求所带的一个参数列表,你可以在 这里 找到完整的常用 Headers 列表。一些常用的需要注意的有:
User-Agent
UA 是标识你使用的浏览器,或抓取程序的一段字符串。pyspider 使用的默认 UA 是 pyspider/VERSION (+http://pyspider.org/)。网站常用这个字符串来区分用户的操作系统和浏览器,以及判断对方是否是爬虫。所以在抓取的时候,常常会对 UA 进行伪装。
在 pyspider 中,你可以通过 self.crawl(URL, headers={'User-Agent': 'pyspider'}),或者是 crawl_config = {'headers': {'User-Agent': 'xxxx'}} 来指定脚本级别的 UA。详细请查看 API 文档。
Referer 用于告诉服务器,你访问的上一个网页是什么。常常被用于防盗链,在抓取图片的时候可能会用到。
X-Requested-With
当使用 XHR 发送 AJAX 请求时会带上的 Header,常被用于判断是不是 AJAX 请求。例如在 北邮人论坛 中,你需要:
def on_start(self):
self.crawl('http://bbs.byr.cn/board/Python', headers={'X-Requested-With': 'XMLHttpRequest'}, callback=self.index_page)带有 headers={'X-Requested-With': 'XMLHttpRequest'} 才能抓取到内容。
HTTP Cookie
虽然 Cookie 只是 HTTP Header 中的一个,但是因为非常重要,但是拿出来说一下。Cookie 被 HTTP 请求用来区分、追踪用户的身份,当你在一个网站登录的时候,就是通过写入 Cookie 字段来记录登录状态的。
当遇到需要登录的网站,你需要通过设置 Cookie 参数,来请求需要登录的内容。Cookie 可以通过开发者工具的请求面板,或者是资源面板中获得。在 pyspider 中,你也可以使用 response.cookies 获得返回的 cookie,并使用 self.crawl(URL, cookie={'key': 'value'}) 来设置请求的 Cookie 参数。
(三):使用 PhantomJS 渲染带 JS 的页面
在上两篇教程中,我们学习了怎么从 HTML 中提取信息,也学习了怎么处理一些请求复杂的页面。但是有一些页面,它实在太复杂了,无论是分析 API 请求的地址,还是渲染时进行了加密,让直接抓取请求非常麻烦。这时候就是 PhantomJS 大显身手的时候了。
在使用 PhantomJS 之前,你需要安装它(安装文档)。当你安装了之后,在运行 all 模式的 pyspider 时就会自动启用了。当然,你也可以在 demo.pyspider.org 上尝试。
使用 PhantomJS
当 pyspider 连上 PhantomJS 代理后,你就能通过在 self.crawl 中添加 fetch_type='js' 的参数,开启使用 PhantomJS 抓取。例如,在教程二中,我们尝试抓取的 http://movie.douban.com/explore 就可以通过 PhantomJS 直接抓取:
class Handler(BaseHandler):
def on_start(self):
self.crawl('http://movie.douban.com/explore',
fetch_type='js', callback=self.phantomjs_parser)
def phantomjs_parser(self, response):
return [{
"title": "".join(
s for s in x('p').contents() if isinstance(s, basestring)
).strip(),
"rate": x('p strong').text(),
"url": x.attr.href,
} for x in response.doc('a.item').items()]- 我在这里使用了一些 PyQuery 的 API,你可以在 PyQuery complete API 获得完整的 API 手册。
你会发现,在上面我们使用 PhantomJS 抓取的豆瓣热门电影只有 20 条。当你点击『加载更多』时,能获得更多的热门电影。为了获得更多的电影,我们可以使用 self.crawl 的 js_script 参数,在页面上执行一段脚本,点击加载更多:
def on_start(self):
self.crawl('http://movie.douban.com/explore#more',
fetch_type='js', js_script="""
function() {
setTimeout("$('.more').click()", 1000);
}""", callback=self.phantomjs_parser)- 这个脚本默认在页面加载结束后执行,你可以通过
js_run_at参数 修改这个行为 - 由于是 AJAX 异步加载的,在页面加载完成时,第一页的电影可能还没有加载完,所以我们用
setTimeout延迟 1 秒执行。 - 你可以间隔一定时间,多次点击,这样可以加载更多页。
- 由于相同 URL (实际是相同 taskid) 的任务会被去重,所以这里为 URL 加了一个
#more
漫谈Pyspider网络爬虫的实践
转载地址
为什么是Python
写网络爬虫的语言有很多,编程的语言更多。个人认为Python是一种工具型的语言,上手快,语法简单(相比于C/C++/JAVA族),各种功能库丰富而且小巧单一(每个独立的库只做一件事情),所以编程就像是在玩乐高积木,照着自己设计好的流程,拼接就行了。当然,这是笔者个人的经验和喜好。如果你有自己擅长并喜欢的,大可用自己的去实现一个网络爬虫系统,这个不在本文的讨论范围之类了。
有关几种编程语言编写网络爬虫的比较,可以参考知乎上的文章 PHP, Python, Node.js 哪个比较适合写爬虫?
为什么是Pyspider
Python有很多成熟的网络爬虫框架, 知乎上很多大牛总结了一些实践经验,具体可以参考如何入门 Python 爬虫?
很多推荐用requests做请求,query/soup做页面数据(Html/Xml)解析,看起来很灵活,然而,一个比较完善的网络爬虫系统,所需要提供的功能可能远远不止这些。也有推荐Scrapy的,虽然看起来功能非常强大,但是这个框架上手需要一些时间,有一定的学习成本,相对于新手来说,很难快速专注爬虫业务的开发。
Pyspider是Roy Binux开发的一款开源的网络爬虫系统,它不止是一个爬虫框架,而是一套完备的爬虫系统,使用这套系统你只需要关注两件事情
- 目标网站上的内容元素的解析,而且只需要关注解析什么,解析框架也有提供,并且提供了可视化工具辅助从目标页面抠取需要解析的元素CSS属性
- 解析出来的内容元素如何保存,你只需要关注数据库表字段的设计,然后把解析出来的页面元素内容保存到数据库表中
- 那么,剩下的几乎所有事情,就交给Pyspider吧
是不是听上去感觉很简单,那么,开始动手吧,跟着这篇官方文档,最快几分钟的功夫,你就可以学会从2048(草榴)找到真爱了。
简单的爬取看官方文档就可以了,不过,实践过程中总会遇到各种问题,那么,看看这些如何解决的吧。
如何模拟登陆有些网站内容的展示需要用户登录,那么如果需要爬取这样的页面内容,我们的爬虫就需要模拟用户登陆。网站一般在页面跳转或者刷新的时候,也需要获取登录信息以确定这个页面的访问用户是登陆过的。如果每次都需要用户重新登录,那么这种体验就太烂了,需要一种机制把之前用户登陆的信息保存起来,而且一定是保存在浏览器可以访问的本地存储上,这样,用户在页面跳转或者页面刷新的时候,登录信息被网站自动读取,就不需要用户频繁登录了。而这个保存的地方,叫做Cookie。
爬虫需要做的事情,一是模拟登陆,拿到Cookie数据,然后保存下来,二是每次去访问网页的时候,将Cookie信息传递给请求,这样就可以正常爬到需要用户登录的数据了。
我们先设计一个登录类,用来管理登录的请求和数据
import urllib
import urllib2
import lxml.html as HTML
class Login(object):
def __init__(self, username, password, login_url, post_url_prefix):
self.username = username
self.password = password
self.login_url = login_url
self.post_url_prefix = post_url_prefix
def login(self):
post_url, post_data = self.getPostData()
post_url = self.post_url_prefix + post_url
req = urllib2.Request(url = post_url, data = post_data)
resp = urllib2.urlopen(req)
return True
def getPostData(self):
url = self.login_url.strip()
if not re.match(r'^http://', url):
return None, None
req = urllib2.Request(url)
resp = urllib2.urlopen(req)
login_page = resp.read()
doc = HTML.fromstring (login_page)
post_url = doc.xpath("//form[@method='post' and @id='lsform']/@action")[0]
cookietime = doc.xpath("//input[@name='cookietime' and @id='ls_cookietime']/@value")[0]
username = self.username
password = self.password
post_data = urllib.urlencode({
'fastloginfield' : 'username',
'username' : username,
'password' : password,
'quickforward' : 'no',
'handlekey' : 'ls',
'cookietime' : cookietime,
})
return post_url, post_data代码解释
- 用户名username, 密码password, 目标网站的登录页面地址login_url, 目标网站的主域名post_url_prefix,这些参数从外部传入,目标网站的登录页面地址也有可能就是网站的主页地址。
- getPostData首先向目标网站的登录页面地址发起一个请求,然后解析这个页面的数据,解析出登录请求的目标地址和post请求的数据(登录请求一般为post请求),然后返回这两个参数
设计一个方法,这个方法用来获取爬取网页请求需要的Cookie数据。
import os
import hashlib
import cookielib
LOGIN_URL = 'http://登录页面地址'
USER_NAME = '用户名'
PASSWORD = '密码'
HOST = '目标网页主域名'
REFERER = 'http://目标网页主域名/'
POST_URL_PREFIX = 'http://目标网页主域名/'
# !!! Notice !!!
# Tasks that share the same account MUST share the same cookies file
COOKIES_FILE = '/tmp/pyspider.%s.%s.cookies' % (HOST, hashlib.md5(USER_NAME).hexdigest())
COOKIES_DOMAIN = HOST
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36'
HTTP_HEADERS = {
'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding' : 'gzip, deflate, sdch',
'Accept-Language' : 'zh-CN,zh;q=0.8,en;q=0.6',
'Connection' : 'keep-alive',
'DNT' : '1',
'Host' : HOST,
'Referer' : REFERER,
'User-Agent' : USER_AGENT,
}
def getCookies():
cookiesJar = cookielib.MozillaCookieJar(COOKIES_FILE)
if not os.path.isfile(COOKIES_FILE):
cookiesJar.save()
cookiesJar.load (COOKIES_FILE)
cookieProcessor = urllib2.HTTPCookieProcessor(cookiesJar)
cookieOpener = urllib2.build_opener(cookieProcessor, urllib2.HTTPHandler)
for item in HTTP_HEADERS:
cookieOpener.addheaders.append ((item ,HTTP_HEADERS[item]))
urllib2.install_opener(cookieOpener)
if len(cookiesJar) == 0:
login = Login(USER_NAME, PASSWORD, LOGIN_URL, POST_URL_PREFIX)
if login.login():
cookiesJar.save()
else:
return None
cookiesDict = {}
for cookie in cookiesJar:
if COOKIES_DOMAIN in cookie.domain:
cookiesDict[cookie.name] = cookie.value
return cookiesDict代码解释
- USER_NAME PASSWORD LOGIN_URL POST_URL_PREFIX 分别定义了用户名/密码/登录页面地址/目标网页前缀
- 如果从COOKIES_FILE读取出的Cookie信息为空,那么就调用Login做登录流程,并且把获取到的结果保存,如果Cookie不为空,就返回Cookie信息到字典cookiesDict中
Pyspider每次爬取请求都带上Cookie字典,这样,向目标地址发请求就可以获取到需要登录才能访问到的数据了。
cookies = getCookies()
self.crawl(url, cookies = cookies, callback=self.index_page)如何解析爬取下来的内容
爬取的内容通过回调的参数response返回,response有多种解析方式
- 如果返回的数据是json,则可以通过response.json访问
- response.doc返回的是PyQuery对象
- response.etree返回的是lxml对象
- response.text返回的是unicode文本
- response.content返回的是字节码
所以返回数据可以是5种形式,unicode和字节码不是结构化的数据,很难解析,这里就不赘述了,json需要特定的条件,而且解析相对简单,也不必说。
常用的就是PyQuery和lxml的方式,关于lxml,可以采用XPath的语法来解析,比如前面模拟登录中就采用了xpath的语法解析网页,具体可参考lxml和XPath的相关文档。
XPath选择器参考
| 选择器 | 示例 | 示例说明 |
|---|---|---|
| nodename | bookstore | 选择所有名称叫做”bookstore”的节点 |
| / | bookstore/book | 选择”bookstore”的节点的所有”book”子节点 |
| // | //book | 选择文档中所有名称叫做”book”的节点,不管它们的父节点叫做什么 |
| . | 选择当前的节点 | |
| .. | 选择当前节点的父节点 | |
| @ | //@lang | 选择所有名称叫做”lang”的属性 |
| bookstore//book | 选择节点”bookstore”所有叫做”book”的子孙节点,bookstore不一定是book的父节点 | |
| /bookstore/book[1] | 选择节点”bookstore”的第一个叫做”book”的子节点 | |
| /bookstore/book[last()] | 选择节点”bookstore”的最后一个叫做”book”的子节点 | |
| //title[@lang] | 选择所有有一个属性名叫做”lang”的title节点 | |
| //title[@lang=’en’] | 选择所有有一个属性”lang”的值为”en”的title节点 | |
| * | /bookstore/* | 选择”bookstore”节点的所有子节点 |
| //* | 选择文档中所有的节点 | |
| @* | //title[@*] | 选择所有的”title”节点至少含有一个属性,属性名称不限 |
PyQuery可以采用CSS选择器作为参数对网页进行解析。
类似这样
response.doc('.ml.mlt.mtw.cl > li').items()
或者这样
response.doc('.pti > .pdbt > .authi > em > span').attr('title')
关于PyQuery更多玩法,可以参考PyQuery complete API
CSS选择器
| 选择器 | 示例 | 示例说明 |
|---|---|---|
| .class | .intro | Selects all elements with class=”intro” |
| #id | #firstname | Selects the element with id=”firstname” |
| element | p | Selects all elements |
| element,element | div, p | Selects all elements and all elements |
| element element | div p | Selects all elements inside elements |
| element>element | div > p | Selects all elements where the parent is a element |
| [attribute] | [target] | Selects all elements with a target attribute |
| [attribute=value] | [target=_blank] | Selects all elements with target=”_blank” |
| [attribute^=value] | a[href^=”https”] | Selects every element whose href attribute value begins with “https” |
| [attribute$=value] | a[href$=”.pdf”] | Selects every element whose href attribute value ends with “.pdf” |
| [attribute*=value] | a[href*=”w3schools”] | Selects every element whose href attribute value contains the substring “w3schools” |
| :checked | input:checked | Selects every checked element |
更多详情请参考CSS Selector Reference
如何将数据保存到MySQL中将MySQL的数据库访问封装成一个类
import hashlib
import unicodedata
import mysql.connector
from mysql.connector import errorcode
class MySQLDB:
username = '数据库用户名'
password = '数据库密码'
database = '数据库名'
host = 'localhost' #数据库主机地址
connection = ''
isconnect = True
placeholder = '%s'
def __init__(self):
if self.isconnect:
MySQLDB.connect(self)
MySQLDB.initdb(self)
def escape(self,string):
return '`%s`' % string
def connect(self):
config = {
'user':self.username,
'password':self.password,
'host':self.host
}
if self.database != None:
config['database'] = self.database
try:
cnx = mysql.connector.connect(**config)
self.connection = cnx
return True
except mysql.connector.Error as err:
if (err.errno == errorcode.ER_ACCESS_DENIED_ERROR):
print "The credentials you provided are not correct."
elif (err.errno == errorcode.ER_BAD_DB_ERROR):
print "The database you provided does not exist."
else:
print "Something went wrong: " , err
return False
def initdb(self):
if self.connection == '':
print "Please connect first"
return False
cursor = self.connection.cursor()
# 创建表的定义
sql = 'CREATE TABLE IF NOT EXISTS \
table_name ( \
id VARCHAR(64) PRIMARY KEY, \
url TEXT, \
title TEXT, \
type TEXT, \
thumb TEXT, \
count INTEGER, \
images TEXT, \
tags TEXT, \
post_time DATETIME \
) ENGINE=INNODB DEFAULT CHARSET=UTF8'
try:
cursor.execute(sql)
self.connection.commit()
return True
except mysql.connector.Error as err:
print ("An error occured: {}".format(err))
return False
def cleardb (self):
if self.connection == '':
print "Please connect first"
return False
cursor = self.connection.cursor()
sql = 'DROP TABLE IF EXISTS table_name'
try:
cursor.execute(sql)
self.connection.commit()
return True
except mysql.connector.Error as err:
print ("An error occured: {}".format(err))
return False
def insert (self,**values):
if self.connection == '':
print "Please connect first"
return False
cursor = self.connection.cursor()
# 插入数据
sql = "insert into table_name (id, url, title, type, thumb, count, temperature, images, tags, post_time) values (%s,%s,%s,%s,%s,%s,%s,%s,%s) on duplicate key update id=VALUES(id), url=VALUES(url), title=VALUES(title), type=VALUES(type), thumb=VALUES(thumb), count=VALUES(count), images=VALUES(images), tags=VALUES(tags), post_time=VALUES(post_time)"
title = unicodedata.normalize('NFKD', values['title']).encode('ascii','ignore')
images = ", ".join('%s' % k for k in values['images'])
params = (hashlib.md5(title + images).hexdigest(), values['url'], values['title'], values['type'], values['thumb'], values['count'], images, '', values['date'])
try:
cursor.execute(sql,params)
self.connection.commit()
return True
except mysql.connector.Error as err:
print ("An error occured: {}".format(err))
return False
def replace(self,tablename=None,**values):
if self.connection == '':
print "Please connect first"
return False
tablename = self.escape(tablename)
if values:
_keys = ", ".join(self.escape(k) for k in values)
_values = ", ".join([self.placeholder, ] * len(values))
sql_query = "REPLACE INTO %s (%s) VALUES (%s)" % (tablename, _keys, _values)
else:
sql_query = "REPLACE INTO %s DEFAULT VALUES" % tablename
cur = self.connection.cursor()
try:
if values:
cur.execute(sql_query, list(itervalues(values)))
else:
cur.execute(sql_query)
self.connection.commit()
return True
except mysql.connector.Error as err:
print ("An error occured: {}".format(err))
return False在处理爬取结果的回调中保存到数据库
def on_result(self, result):
db = MySQLDB()
db.insert(**result)如何在爬虫脚本更新后重新运行之前执行过的任务
比如这种场景,爬取了一些数据,发现没有写保存到数据库的逻辑,然后加上了这段逻辑,却发现之前跑过的任务不会在执行了。那么如何做到在爬虫脚本改动后,之前的任务重新自动再跑一遍呢。
在crawl_config中使用itag来标示爬虫脚本的版本号,如果这个值发生改变,那么所有的任务都会重新再跑一遍。示例代码如下
class Handler(BaseHandler):
crawl_config = {
'headers': {
'User-Agent': USER_AGENT,
},
'itag': 'v1'
}itag也可以用来控制特定的任务是否需要重新执行,详见官方文档。
如何解析JavaScript代码
具体如何使用的可以看官方文档,这里列举出一些可供参考的JavaScript解析器
基于Webkit的PhantomJS 基于Gecko的SlimerJS
基于PhantomJS和SlimerJS的CasperJS
Nightmare
Selenium
spynner
ghost.py
更多工具/框架请参考Headless Browser and scraping - solutions
参考资料binux/pyspider
Pyspider官方文档
pyspider架构设计
pyspider中文脚本编写指南
Pyspider爬虫教程
把 pyspider的结果存入自定义的mysql数据库中
pyspider的mysql数据存储接口
PyQuery complete API
CSS Selector Reference
收集的一些其它网络爬虫的资料
Java
雪球股票信息超级爬虫
一个简单易用的爬虫框架,内置代理管理模块,灵活设置多线程爬取
A scalable web crawler framework for Java
强力 Java 爬虫,列表分页、详细页分页、ajax、微内核高扩展、配置灵活
Python
Scrapy
a smart stream-like crawler & etl python library
爬视频音频神器You-Get
另一款视频下载神器youtube-dl
youtube-dl图形界面版
自动抓取Tumblr指定用户视频分享
crawley
乌云公开漏洞、知识库爬虫和搜索
下载指定的 Tumblr 博客中的图片,视频
下载指定的 Tumblr 博客中的图片,视频,玄魂修改版
DHT网络爬虫
豆瓣电影、书籍、小组、相册、东西等爬虫集 writen in Python
如何不用客户端下载 YouKu 视频-YouKu 实现下载 Python3 实现
一个可配置的、分布式的爬虫框架
cloud-based web crawling platform
百度云爬虫-爬取百度云/百度网盘所有的分享文件
爱丝APP图片爬虫,以及免支付破解VIP看图
微信公众号爬虫
拉勾网爬虫
百度网盘爬虫(如何爬取百度网盘)
PHP
PHP Crawler
PHPCrawl
Phpfetcher
php spider framework
我用爬虫一天时间“偷了”知乎一百万用户,只为证明PHP是世界上最好的语言
爬虫组件
PHP Simple HTML DOM Parser
QueryList
Goutte, a simple PHP Web Scraper
Nodejs
Nodejs 编写的爬虫工具
批量抓取AV磁链或封面的苦劳力
Easily download all the photos from a Tumblr blog.
DHT Spider + BitTorrent Client = P2P Spider
P2P Spider修改版,添加了babel,eslint,gulp等工具来支持es6代码
一个Node.js福利图网站爬虫程序
一个简单的dht爬虫,用于搜集infohash
百度云分享爬虫项目
Ruby
A simple DHT crawler, written in Ruby
C sharp
visualized crawler & ETL IDE written with C#/WPF
Erlang
使用erlang实现P2P磁力搜索
C++
给不了你梦中情人,至少还有硬盘女神:hardseed
Golang
a distributed, high concurrency and powerful web crawler software
网络爬虫专题
open-open 网络爬虫专题
你想要的爬虫,都在这里