我的python笔记
文章目录
-
-
-
- 0 零碎但重要的基础知识
-
- 0.1 模块导入
-
- 0.1.1 import ... 和from ... import ...
- 0.1.2 ImportError: No module named 通用解决方法
- 0.2 Python方法的动态参数调用*args(元组),**args(字典)
- 1 字符串/列表方法
-
- 1.1 extend()和append()区别
- 1.1 endswith() 方法
- 1.2 strip(),lstrip(),rstrip()
- 1.3 列表元素转为整形
- 1.4 生成随机数的方法
-
- 1.4.1 random模块
- 1.4.2 numpy中的random函数
- 1.5 字符串格式化方法——format函数
- 1.6 eval函数(执行一个字符串表达式,并返回表达式的值)
- 1.7 zip方法(执行一个字符串表达式,并返回表达式的值)
- 1.8 product方法
- 1.9 encode()方法
- 1.9 index()方法
- 1.10 insert()方法
- 1.11 join()方法
- 2 变量
-
- 2.1 python的LEGB规则
- 2.2 global和方法globals()的区别
- 3 文件操作(主要是os模块)
-
- 3.1 创建文件夹
- 3.2 遍历文件夹下的文件
- 3.3 删除文件和文件夹
- 3.5 读写csv文件
- 3.6 shutil模块
-
- 3.6.1 shutil.rmtree()、os.rmdir()以及os.removedirs()的区别
- 3.7 glob模块
- 3.8 其他方法
- 4 正则表达式
-
- 正则表达式语法
- 正则表达式 re.findall()用法
- 5 numpy用法
-
- 5.0 一文彻底明白随机数生成器numpy.random.RandomState!
- 5.1 数组和列表的互相转化
- 5.1 数组增加维度:None和np.newaxis
- 5.2 数组的拼接:hstack()、vstack()、stack()、concatenate()方法
- 5.3 numpy的运算
-
- 5.3.1 点积和哈达玛积
- 5.3.2 np.linalg.norm(求范数)
- 5.3.3 获得数组的最大、小值索引
- 5.4 数组复制的坑——np.copy()
- 5.5 np.unique( )去除数组中的重复数字
- 5.6 reshape的坑——IndexError: invalid index to scalar variable.
- 5.7 np.where()——获取数组中指定元素的索引位置
- 6 集合的运算
- 7 绘图专区
-
- 7.1 分图的画法
- 8 其他方法
-
- 8.1 for循环中常用的——enumerate() 函数
- 8.2 函数修饰符@
- 8.3 assert(断言)
- 9 迭代器与生成器
-
- 9.1 迭代器
- 9.2 生成器
- 10 脚本相关的模块
-
- 10.1 Argparse模块
-
- 10.1.1 子命令subparsers()方法
- 10 深度学习相关
-
- 10.1 conda
-
- 10.1.1 conda 创建/删除 环境
- 10.1.2 conda换为国内源
- 11 python常见异常分类与处理方法
- 12 一些模块
-
- 12.1 hdf5模块
-
- 12.1.1 常用方法
- 12.1.2 创建不定长数据集
- 12.2 librosa模块
-
- 12.2.1 音频处理
- 12.2.2 特征提取
- 12.3 pickle模块
- 13 python的数学方法
-
-
0 零碎但重要的基础知识
0.1 模块导入
0.1.1 import … 和from … import …
通俗来说:
from import 可以理解为 从三年二班(某模块)里让周杰伦(某变量)到训导处(当前模块)报道。
import 可以理解为先让三年二班到训导处,然后再让这些同学其中的周杰伦报道。
0.1.2 ImportError: No module named 通用解决方法
大佬讲的很好ImportError: No module named 通用解决方法
问题原因:
- 该模块没有安装
- 该模块已经安装,但是没有安装到python的搜索路径下
解决方案:
(1)如果是上面的原因1导致的,安装就行了;
(2)如果是上面的原因2导致的。解决方法,就是将刚刚安装完的包,或者你自己开发的包,添加到Python添加默认模块搜索路径就行了。
方法①: 函数添加
1 import sys
2 查看sys.path
3 添加sys.path.append("/usr/lib/python2.6/site-packages")
这里假设:你需要的包默认安装到 /usr/lib/python2.6/site-packages/下面了。
方法②: 增加.pth文件
在site-packages添加一个路径文件(假设你现在的python默认是:/usr/local/lib/python2.7/),
在 /usr/local/lib/python2.7/site-packages 路径下 新建一个文件 “mypkpath.pth”,文件里面的内容是 你想要加入的模块文件所在的目录名称。
例如:
新建文件:/usr/local/lib/python2.7/site-packages/mypkpath.pth
该文件内容:/usr/lib/python2.6/site-packages/
0.2 Python方法的动态参数调用*args(元组),**args(字典)
参考python函数动态参数调用*args(元组),**kwargs(字典)
1 字符串/列表方法
1.1 extend()和append()区别
extend()接受一个列表参数,把参数列表的元素添加到列表的尾部,append()接受一个对象参数,把对象添加到列表的尾部。
举例说明:
[1,2].extend([1,2,3])
[1,2,1,2,3]
[1,2].append([1,2,3])
[1,2,[1,2,3]]
1.1 endswith() 方法
如果字符串以指定值结尾,则 endswith() 方法返回 True,否则返回 False。
语法:
string.endswith(value, start, end)
| 参数 | 描述 |
|---|---|
| value | 必需。检查字符串是否以之结尾的值。 |
| start | 可选。整数。规定从哪个位置开始检索。 |
| end | 可选。整数。规定从哪个位置结束检索。 |
1.2 strip(),lstrip(),rstrip()
用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
语法:
str.strip([chars])
参数:chars -- 移除字符串头尾指定的字符序列。
返回移除字符串头尾指定的字符生成的新字符串。
1.3 列表元素转为整形
numbers = ['1', '5', '10', '8']
方法一:
numbers = [ int(x) for x in numbers ]
方法二:
umbers = list(map(int, numbers))
1.4 生成随机数的方法
1.4.1 random模块
random.random()生成一个随机的浮点数,范围是在0.0~1.0之间。
random.uniform()正好弥补了上面函数的不足,它可设定浮点数的范围,一个是上限,一个是下限。
random.randint()随机生一个整数int类型,可以指定这个整数的范围,同样有上限和下限值。
random.choice()可以从任何序列,比如list列表中,选取一个随机的元素返回,可以用于字符串、列表、元组等。
random.shuffle()如果你想将一个序列中的元素,随机打乱的话可以用这个函数方法。
random.sample()可以从指定的序列中,随机的截取指定长度的片断,不作原地修改。
例如:
python3生成一个含有20个随机数的列表,要求所有元素不相同,并且每个元素的值介于1到100之间。
import random
alist = random.sample(range(1,101),20) #random.sample()生成不相同的随机数
print(alist)
1.4.2 numpy中的random函数
numpy中的random函数可以调用的方法主要有两种,一种是生成随机浮点数,二是生成随机整数。
① np.random.randn(a,b)
功能:生成a*b维的随机数,且该数服从标准正太分布
data = np.random.randn(5,4)
# 输出:
array([[-1.6101468 , -0.81103612, 0.44875047, 0.55987574],
[-0.33322916, 0.18676658, -0.18424432, -0.84435811],
[ 0.57654276, 0.28830858, -0.73403656, 1.59404864],
[ 0.39009202, 0.86239796, 0.66290243, -0.61292579],
[ 0.03081516, 0.99335315, -0.6875357 , 0.90552971]])
② random.randint(low,high,size)
功能:生成一个<以low为下限,high为上限,size大小>的随机整数矩阵,其中数值范围包含low,不包含high
用法:
data = np.random.randint(low=2,high=5,size=(5,7))
# 输出:
array([[4, 2, 4, 4, 4, 4, 2],
[4, 2, 2, 4, 3, 3, 3],
[3, 4, 3, 4, 3, 3, 4],
[3, 4, 2, 3, 3, 2, 2],
[3, 3, 3, 3, 2, 3, 2]])
总结:如果是为了得到随机的单个数,用random模块;如果是为了得到随机小数或者整数的矩阵,就用numpy中的random函数。
参考自:Python中随机数的生成
1.5 字符串格式化方法——format函数
format用法(可以接受不限个参数,位置可以不按顺序)
注意:外是引号,内是大括号,.format
例3:设置指定位置,按默认顺序
>>> "{} {}".format("hello","world")
'hello world'
例4:设置指定位置
"{0} {1}".format("hello","world")
'hello world'
例5:设置指定位置
>>> “{1} {0} {1}” .format("hello","world")
>'world hello world'
更详细的用法请参照python基础语法–format()函数
1.6 eval函数(执行一个字符串表达式,并返回表达式的值)
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
详细说明见:eval函数
1.7 zip方法(执行一个字符串表达式,并返回表达式的值)
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。如需展示列表,需手动 list() 转换。
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
1.8 product方法
- product(A,B)
返回A和B中的元素组成的笛卡尔积的元组,具体见如下代码:
import itertools
for item in itertools.product([1,2,3,4],[100,200]):
print(item)
'''
(1, 100)
(1, 200)
(2, 100)
(2, 200)
(3, 100)
(3, 200)
(4, 100)
(4, 200)
'''
product(list1,list2)依次取出list1中每1个元素,与list2中的每1个元素,组成元组,将所有元组组合成一个列表返回。
摘自Python product函数介绍
1.9 encode()方法
-
用法:以指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案。
-
语法:str.encode(encoding=‘UTF-8’,errors=‘strict’)
1.9 index()方法
- 用法:检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。
语法:str1.index(str2, beg=0, end=len(string))
参数
str1 – 被检索的字符串
str2 – 被检索的关键词
beg – 开始索引,默认为0。
end – 结束索引,默认为字符串的长度。
1.10 insert()方法
- 将指定对象插入列表的指定位置。
- nsert()方法语法:
list.insert(index, obj)
参数:
index – 对象 obj 需要插入的索引位置。
obj – 要插入列表中的对象。
1.11 join()方法
- 将序列中的元素以指定字符连接生成一个新的字符串。
- nsert()方法语法:
str.join(a)
参数:a:要连接的元素序列。
例子:

2 变量
2.1 python的LEGB规则
详见Python中的命名空间及LEGB原则
注意:在python中,global 的生效范围是有限的!!!
2.2 global和方法globals()的区别
global变量:为全局作用域;
globals() :以字典类型返回当前位置的全部全局变量。
举例说明:
globals():globals()用于在方法中访问全局变量
gyd = 'gyd'
def show():
gyd = 'sss'
print(gyd)
print(globals()['gyd'])
show()
print(gyd)
输出:
sss
gyd
gyd
global:用于把方法中的变量全局化
gyd = 'gyd'
def show():
gyd = 'sss'
print(gyd)
global gyd
print(gyd)
show()
print(gyd)
输出:
sss
sss
sss
3 文件操作(主要是os模块)
3.1 创建文件夹
os.path.exists(path) 判断一个目录是否存在
os.makedirs(path) 多层创建目录
os.mkdir(path) 创建目录
mkdir和makedirs之间最大的区别是当父目录不存在的时候os.mkdir(path)不会创建,os.makedirs(path)则会创建父目录。
比如:例子中我要创建的目录web位于D盘的qttc目录下,然而我D盘下没有qttc父目录,如果使用os.mkdir(path)函数就会提示我目标路径不存在,但使用os.makedirs(path)会自动帮我创建父目录qttc,请在qttc目录下创建子目录web。
3.2 遍历文件夹下的文件
os.walk(path)
返回一个三元组(root,dirs,files)。
root 所指的是当前正在遍历的这个文件夹的本身的地址
dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
import os
for root, dirs, files in os.walk("."):
for name in files:
print(os.path.join(root, name))
3.3 删除文件和文件夹
#删除文件
import os
os.remove(path) # path是文件的路径,如果这个路径是一个文件夹,则会抛出OSError的错误
#删除文件夹
import shutil
shutil.rmtree(r"C:\Users\k\Desktop\aaa")
#删除空文件夹
os.rmdir(path)
#递归地删除文件夹中的空文件夹
os.removedirs(path) #递归地删除空目录,每一次递归都调用一次rmdir
removedirs的工作方式像rmdir()一样,其删除多个文件夹的方式是通过在目录上由深及浅逐层调用rmdir()函数实现的,在确定最深的目录为空目录时(因为rmdir只能移除空目录),调用rmdir()函数,移除该目录,工作对象上移一层目录,如果上次的移除动作完毕后当前目录也变成了空目录,那么移除当前目录。重复此动作,直到遇到一个非空目录为止。
详细请参考详解os.removedirs(path)的正确用法
3.5 读写csv文件
读取csv文件
写csv文件
3.6 shutil模块
python-shutil模块拥有许多文件(夹)操作的功能,包括复制、移动、重命名、删除等等
3.6.1 shutil.rmtree()、os.rmdir()以及os.removedirs()的区别
(1)os.rmdir()
>>> os.rmdir("C:\\demo")
把 C 盘的 demo 文件夹删除掉,如果 demo 文件夹不是空的,则报错。
(2)os.removedirs()
>>> os.removedirs("C:\\demo\\test\\demo2")
先删除 demo2 文件夹,再删除 test 文件夹,最后删除 demo 文件夹。如果碰到任何一个文件夹是不为空的则报错。
(3)shutil.rmtree()
>>> import shutil
>>> shutil.rmtree("C:\\demo")
这会把 C 盘的整个 demo 目录删掉,无论它是不是为空。
3.7 glob模块
glob模块是最简单的模块之一,内容非常少。用它可以查找符合特定规则的文件路径名。跟使用windows下的文件搜索差不多。查找文件只用到三个匹配符:””, “?”, “[]”。””匹配0个或多个字符;”?”匹配单个字符;”[]”匹配指定范围内的字符,如:[0-9]匹配数字。
- glob.glob
返回所有匹配的文件路径列表。它只有一个参数pathname,定义了文件路径匹配规则,这里可以是绝对路径,也可以是相对路径。下面是使用glob.glob的例子:
import glob
#获取指定目录下的所有图片
print (glob.glob(r"/home/qiaoyunhao/*/*.png"),"\n")#加上r让字符串不转义
#获取上级目录的所有.py文件
print (glob.glob(r'../*.py')) #相对路径在这里插入代码片
3.8 其他方法
- os.path.dirname(path)
语法:os.path.dirname(path)
功能:去掉文件名,返回目录
例子:
print(os.path.dirname('W:\Python_File\juan之购物车.py'))
#结果
#W:\Python_File
print(os.path.dirname('W:\Python_File'))
#结果
#W:\
- os.path.exist(path)
语法:os.path.dirname(path)
功能:判断路径是否存在
- os.getcwd()
功能:获取当前工作路径
参考:python慎用os.getcwd() ,除非你知道【文件路径与当前工作路径的区别】
4 正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
正则表达式语法
详见正则表达式
正则表达式 re.findall()用法
返回string中所有与pattern相匹配的全部字串,返回形式为列表
语法:
findall(pattern, string, flags=0)
正则表达式 re.findall()用法
应用:分离字符串中的数字和字母
import re
a = findall(r'[0-9]+|[a-z]+','hdeuhw2382378dhai3')
5 numpy用法
5.0 一文彻底明白随机数生成器numpy.random.RandomState!
- 要点1:只要随机种子相同,伪随机数发生器产生的随机数序列就相同。
举个栗子:
import numpy
for i in range(4):
# 伪随机数生成
# 产生一个随机状态种子
rdm = numpy.random.RandomState(seed=None)
# 生成2*2的随机数
X = rdm.rand(2, 2)
print(X)
[[0.2782821 0.96782013]
[0.44786374 0.47873287]]
[[0.68179287 0.5806421 ]
[0.60807524 0.05133981]]
[[0.63060324 0.69216438]
[0.58396857 0.24728733]]
[[0.26476759 0.26102395]
[0.64752814 0.23368233]]
import numpy
for i in range(4):
# 伪随机数生成
# 产生一个随机状态种子
rdm = numpy.random.RandomState(seed=1)
# 生成2*2的随机数
X = rdm.rand(2, 2)
print(X)
[[4.17022005e-01 7.20324493e-01]
[1.14374817e-04 3.02332573e-01]]
[[4.17022005e-01 7.20324493e-01]
[1.14374817e-04 3.02332573e-01]]
[[4.17022005e-01 7.20324493e-01]
[1.14374817e-04 3.02332573e-01]]
[[4.17022005e-01 7.20324493e-01]
[1.14374817e-04 3.02332573e-01]]
- 要点2:RandomState会生成一个一维的随机数列表,每次rng.rand()时依次往后取随机值。(可以保证每次得到的随机数一定不同)
栗子:
import numpy as np
def rng2():
rng = np.random.RandomState(0)
print(rng.rand(8))
rng1 = np.random.RandomState(0) # 就算是改成rng1了也一点不影响
print(rng1.rand(3,2))
print(rng1.rand(3,2))
rng2()
输出:
[0.5488135 0.71518937 0.60276338 0.54488318 0.4236548 0.64589411
0.43758721 0.891773 ]
[[0.5488135 0.71518937] #这个列表中的数就是和上面的数一样样的
[0.60276338 0.54488318]
[0.4236548 0.64589411]]
[[0.43758721 0.891773 ]
[0.96366276 0.38344152]
[0.79172504 0.52889492]]
5.1 数组和列表的互相转化
python中 list 与数组的互相转换
(1)list转array
np.array(a)
(2)array 转list
a.tolist()
5.1 数组增加维度:None和np.newaxis
None和np.newaxis效果完全相同
import numpy as np
a=np.array([[11,12,13,14],[21,22,23,24],[31,32,33,34],[41,42,43,44]])
print(a[None,0:4])
print(a[0:4,:, None])
print(a[0:4,:, np.newaxis])
[[[11 12 13 14]
[21 22 23 24]
[31 32 33 34]
[41 42 43 44]]]
[[[11]
[12]
[13]
[14]]
[[21]
[22]
[23]
[24]]
[[31]
[32]
[33]
[34]]
[[41]
[42]
[43]
[44]]]
[[[11]
[12]
[13]
[14]]
[[21]
[22]
[23]
[24]]
[[31]
[32]
[33]
[34]]
[[41]
[42]
[43]
[44]]]
5.2 数组的拼接:hstack()、vstack()、stack()、concatenate()方法
详见:
1:numpy中的hstack()、vstack()、stack()、concatenate()函数详解
2:stack和concatenate区别
3:stack过程最直观的描述
concatenate() :
(1)一个已经存在的维度上连接数组列;
(2)待排列数组shape可以不同;拼接的维度的长度可以不同,但其他维度的长度必须相同
(3)不增加维度。
stack():
(1)更像是数组中元素的组合。
(2)待排列数组shape相同;
(3)增加一个新维度。

5.3 numpy的运算
5.3.1 点积和哈达玛积
对应元素相乘: np.multiply(), 或 *
矩阵乘法:np.dot()
5.3.2 np.linalg.norm(求范数)
1、linalg=linear(线性)+algebra(代数),norm则表示范数。
2、函数参数
x_norm=np.linalg.norm(x, ord=None, axis=None, keepdims=False)
①x: 表示矩阵(也可以是一维)
②ord:范数类型
5.3.3 获得数组的最大、小值索引
np.unravel_index(a.argmax(), a.shape)用法:
a.argmax()用于得出数组全局最大值序号;
np.unravel_index()用于将最大值序号转化为坐标。
a = np.array([[1, 2, 3],
[4, 5, 6]])
print(a.argmax()) #最大值是第几个
index = np.unravel_index(a.argmax(), a.shape) #最大值在数组中的位置
print(index)
输出:
5
(1, 2)
对于二维数组:
import numpy as np
a = np.array([[1, 2, 3],
[4, 5, 6]])
index = np.unravel_index(a.argmax(), a.shape)
print(index)
>>>(1, 2)
三维数组:
import numpy as np
a = np.array([[[1, 2, 3],
[4, 5, 6]]])
index = np.unravel_index(a.argmax(), a.shape)
print(index)
>>>(0, 1, 2)
一句话搞定,获得二维或多维数组最值的索引。
argmin()的用法
用来检索数组中最小值的位置,并返回其下标值。同理,argmax()函数就是用来检索最大值的下标,与argmin()函数用法相同。在argmin()函数的标准语法中,numpy.argmin(a, axis=None, out=None),其中的axis参数为默认和给定值时输出情况是不一样的。
在没有指定axis值的情况下,默认为None。在默认情况下,就相当于将n维的arry平铺在一起。举个简单的例子,当二维arry([1,2,3],[4,5,6])平铺开来就是([1,2,3,4,5,6])。
a = np.array([[2,5,6],[7,6,1]])
print(np.argmin(a))
对于这个二维arry来说,它的最小值是1,而1的下标为5,所以最后输出的值就是5。
当axis = 1时,按照方向来,对于[2,5,6]来说最小值的下标是0,对于[7,6,1]来说最小值的下标是2。所以,最后输出的值就是[0,2]。
当axis = 0时,这时按照方向来,[2,7],[5,6],[6,1]分别在一个轴上,所以检索每个轴上的最小值,并返回下标,最后就可以得到输出值[0,0,1]。
5.4 数组复制的坑——np.copy()
复制数组时一定要用np.copy(),如果直接用等号将旧数组赋值给新数组,那么改变新数组会影响旧数组。
import numpy as np
# numpy 数组的复制和 python的list数组的复制是不同的
# 对于python的数组, 可以通过索引,完全复制新的数组
a = [1,2,3,4]
b = a[:]
#这里的 a 和 b是两个完全独立的数组,但是对于numpy并非如此
a_np = np.array([1,2,3,4])
b_np = a[:]
a_np[1] = 100
print(a_np)
print(b_np)
print(type(a_np))
print(type(b_np))
# 这里输出的a_np和b_np都是1, 100, 3, 4
# 要想完全复制a_np,要通过调用copy()
# 实际上这里的b_np并不是np数组,而是python的list
c_np = a_np.copy()
a_np[2] = 100
print(a_np)
print(c_np)
print(type(a_np))
print(type(c_np))
# 这里的输出结果是不同的,
# a_np是1, 100, 100, 4
# c_np是1, 100, 3, 4
5.5 np.unique( )去除数组中的重复数字
该函数是去除数组中的重复数字,并进行排序之后输出。

5.6 reshape的坑——IndexError: invalid index to scalar variable.
生成了一个长度为10的一维数组,然后使用reshape转换成2x5的矩阵,但是在取矩阵值的时候出现索引错误
import numpy as np
a = np.arange(0,10)
a.reshape(2,5)
a[1][1]
原因:数组a经过reshape后,a中的内容没有变,需要重新赋值
import numpy as np
a = np.arange(0,10)
b = a.reshape(2,5)
b[1][1]
6
输出了正确值
5.7 np.where()——获取数组中指定元素的索引位置
import numpy as np
a = np.array([1,2,3,4,5,6,6,7,6])
b = np.where(a == 6)
# b = np.argwhere(a ==6 )
print(b)
6 集合的运算
# 在对集合做运算时,不会影响原来的集合,而是返回一个运算结果
# 创建两个集合
s = {1,2,3,4,5}
s2 = {3,4,5,6,7}
# & 交集运算
result = s & s2 # {3, 4, 5}
# | 并集运算
result = s | s2 # {1,2,3,4,5,6,7}
# - 差集
result = s - s2 # {1, 2}
# ^ 异或集 获取只在一个集合中出现的元素
result = s ^ s2 # {1, 2, 6, 7}
更多用法请看:python集合的运算
7 绘图专区
7.1 分图的画法
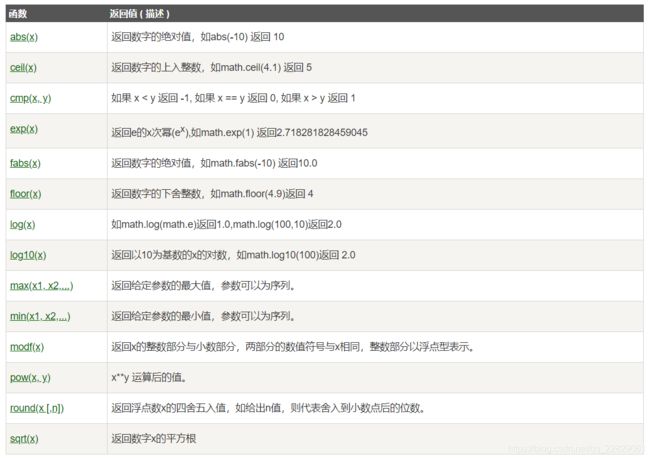
import matplotlib.pyplot as plt
import numpy as np
def f(t):
return np.exp(-t) * np.cos(2 * np.pi * t)
t1 = np.arange(0, 5, 0.1)
t2 = np.arange(0, 5, 0.02)
plt.figure(12)
plt.subplot(221) #子图两行两列,第一个
plt.plot(t1, f(t1), 'bo', t2, f(t2), 'r--')
plt.subplot(222) #子图两行两列,第二个
plt.plot(t2, np.cos(2 * np.pi * t2), 'r--')
plt.subplot(212) #子图两行一列,第二个
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.show()
8 其他方法
8.1 for循环中常用的——enumerate() 函数
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
>>>seq = ['one', 'two', 'three']
>>> for i, element in enumerate(seq):
... print i, element
...
0 one
1 two
2 three
8.2 函数修饰符@
一、函数修饰符
‘@’ 用做函数的修饰符,对函数进行修饰,
出现在函数定义的前一行,不允许和函数定义在同一行
一个修饰符就是一个函数,它将被修饰的函数作为参数
二、 @装饰器的作用
-
装饰器符号“@”属于语法糖,什么意思呢?就是说,我不按照@装饰器的语法要求来写,而是按照一般python的语法要求来写完全可以。那么用@装饰器的格式来写的目的就是为了书写简单方便
-
装饰器的作用是什么呢? 简单的理解就是:装饰原有的函数。什么意思呢?比如有一个函数func(a, b),它的功能是求a,b的差值,我现在有一个需求,就是想对函数功能再装饰下,求完差值后再取绝对值,但是不能在func函数内部实现,这时候就需要装饰器函数了,比如func = decorate(func)函数,将func函数作为参数传递给decorate函数,由decorate来丰富func函数,丰富完成后再返回给func,此时func的功能就丰富了
参考:python中的@
8.3 assert(断言)
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况,例如我们的代码只能在 Linux 系统下运行,可以先判断当前系统是否符合条件。
9 迭代器与生成器
9.1 迭代器
参考:迭代器
(1)对迭代器与可迭代对象的理解
-
凡是可作用于for循环的对象都是Iterable(可迭代)类型;
-
凡是可作用于next()函数的对象都是Iterator(迭代器)类型,它们表示一个惰性计算的序列;
-
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
-
Python的for循环本质上就是通过不断调用next()函数实现的,例如:
for x in [1, 2, 3, 4, 5]:
pass
实际上完全等价于:
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循环
break
(2)关键的方法
next() 函数要和生成迭代器的iter() 函数一起使用
- iter(object ) 生成迭代器。
object – 可迭代的集合对象。 - next()
Iterator对象可被next()函数调用并不断返回下一个数据。
9.2 生成器
参考:爽朗大神的python中yield的用法详解——最简单,最清晰的解释
yield 的核心作用:
带yield的函数是一个生成器,而不是一个函数了,这个生成器有一个函数就是next函数,next就相当于“下一步”生成哪个数,这一次的next开始的地方是接着上一次的next停止的地方执行的,所以调用next的时候,生成器并不会从foo函数的开始执行,只是接着上一步停止的地方开始,然后遇到yield后,return出要生成的数,此步就结束。
def foo():
print("starting...")
while True:
res = yield 4
print("res:",res)
g = foo()
print(next(g))
print("*"*20)
print(next(g))
输出:
starting...
4
********************
res: None
4
10 脚本相关的模块
10.1 Argparse模块
10.1.1 子命令subparsers()方法
功能比较多的命令端程序常常将功能分解到不同子命令中,如在Python中常见的pip install、pip uninstall等。当程序比较复杂且不同功能都需要不同参数时,子命令是一个不错的方式。(转载自Python 关于argparse子命令subparsers()方法)
举例:
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="")
subparsers = parser.add_subparsers(dest='mode')
parser_train = subparsers.add_parser('train')
parser_train.add_argument('--tr_hdf5_path', type=str)
parser_train.add_argument('--te_hdf5_path', type=str)
parser_train.add_argument('--scaler_path', type=str)
parser_train.add_argument('--out_model_dir', type=str)
parser_recognize = subparsers.add_parser('recognize')
parser_recognize.add_argument('--te_hdf5_path', type=str)
parser_recognize.add_argument('--scaler_path', type=str)
parser_recognize.add_argument('--model_dir', type=str)
parser_recognize.add_argument('--out_dir', type=str)
parser_get_stat = subparsers.add_parser('get_stat')
parser_get_stat.add_argument('--pred_dir', type=str)
parser_get_stat.add_argument('--stat_dir', type=str)
parser_get_stat.add_argument('--submission_dir', type=str)
args = parser.parse_args()
if args.mode == 'train':
train(args)
elif args.mode == 'recognize':
recognize(args, at_bool=False, sed_bool=True)
elif args.mode == 'get_stat':
get_stat(args, at_bool=False, sed_bool=True)
else:
raise Exception("Incorrect argument!")
使用:
# Train SED
python main_crnn_sed.py train --tr_hdf5_path=$WORKSPACE"/packed_features/logmel/training.h5" --te_hdf5_path=$WORKSPACE"/packed_features/logmel/testing.h5" --scaler_path=$WORKSPACE"/scalers/logmel/training.scaler" --out_model_dir=$WORKSPACE"/models/crnn_sed"
# Recognize SED
python main_crnn_sed.py recognize --te_hdf5_path=$WORKSPACE"/packed_features/logmel/evaluation_no0.h5" --scaler_path=$WORKSPACE"/scalers/logmel/training.scaler" --model_dir=$WORKSPACE"/models/crnn_sed" --out_dir=$WORKSPACE"/preds/crnn_sed"
## Get stat of SED
#python main_crnn_sed.py get_stat --pred_dir=$WORKSPACE"/preds/crnn_sed" --stat_dir=$WORKSPACE"/stats/crnn_sed" --submission_dir=$WORKSPACE"/submissions/crnn_sed"
10 深度学习相关
10.1 conda
10.1.1 conda 创建/删除 环境
创建新环境:
conda create -n rcnn python=3.6
删除环境:
conda remove -n rcnn --all
10.1.2 conda换为国内源
参考欢呼、雀跃,Anaconda 清华源又回来了!
11 python常见异常分类与处理方法
参考:Python常见异常分类与处理方法
-
AssertionError:当assert断言条件为假的时候抛出的异常
-
AttributeError:当访问的对象属性不存在的时候抛出的异常
-
IndexError:超出对象索引的范围时抛出的异常
-
KeyError:在字典中查找一个不存在的key抛出的异常
-
NameError:访问一个不存在的变量时抛出的异常
-
OSError:操作系统产生的异常
-
SyntaxError:语法错误时会抛出此异常
-
TypeError:类型错误,通常是不同类型之间的操作会出现此异常
-
ZeroDivisionError:进行数学运算时除数为0时会出现此异常
12 一些模块
12.1 hdf5模块
参考: h5py使用基础笔记
12.1.1 常用方法
- 建立文件:a = h5py.File(‘gxx.h5’,‘w’)
- hdf5的数据结构:文件下是group,group的成员是dataset,在为组创建成员的时候其实就是在组中创建了不同的数据集。但也可以直接对h5py文件创建数据集。下面这个例子就没用组
- 建立数据集:a.create_dataset(‘name’,shape = (2,),dtype=‘S80’)
(注意:为简单起见,每一个数据集中只有一维数据,比如数据集1里装name,数据集2里装age) - 为数据集赋值的方式有两种:(1)a1[‘name’][0],用数据集的索引(2)a[‘name’][0] = name.encode() ,用文件的索引和数据集名字。具体如下:
import h5py
name = 'guanxixi'
a = h5py.File('gxx.h5','w') #建立h5文件
a1 = a.create_dataset('name',shape = (2,),dtype='S80') #建立数据集。注意,字符串类型的dtype='S80'
a2 = a.create_dataset('age', shape= (2,), dtype = float)
# a1[0] = name.encode() #用数据集的索引来输出数据
# 注意:字符串类型要编码
a['name'][0] = name.encode() #用文件的索引和数据集名字来输出数据
print(a1[()])
输出:
[b'guanxixi' b'']
12.1.2 创建不定长数据集
如果在创建数据集f.create_dataset时指定的数据长度过长,可能比较浪费资源,因此,可先指定一个很小的shape,同时指定maxshape为None(不定长),当添加数据的时候可以增加长度。
关键的点:
- 定义f.create_dataset时指定maxshape=(None, 3)
- 加数据时用resize确定数据集的大小
例1:
import h5py
f = h5py.File('foo.hdf5', 'w')
d = f.create_dataset('data', (3, 3), maxshape=(None, 3), dtype='i8', chunks=True)
d.resize((6, 3))
例2:
定义数据集:

添加数据
![]()
12.2 librosa模块
参考:python librosa音频处理库 Core IO and DSP(翻译文档)
12.2.1 音频处理
-
librosa.core.load
-
用法:加载音频,一般都把音频处理成wav格式然后通过该函数加载。
-
参数为:
path:路径 sr:采样率 mono:该值为true时候是单通道、否则为双通道 offset:读音频的开始时间,也就是可以不从头开始读取音频 duration:持续时间,可以不加载全部时间,通过与offset合作读取其中一段音频 dtype:返回的音频信号值的格式,一般不设置 res_type:重采样的格式,一般不用 -
返回值:
y:音频的信号值 sr:音频的采样值,如果参数没有设置返回的是原始采样率
12.2.2 特征提取
12.3 pickle模块
参考Python pickle模块学习(超级详细)
简介:pickle提供了一个简单的持久化功能。可将对象以文件的形式存放在磁盘上。pickle模块只能在python中使用,python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化。
用法:
-
pickle.dump(obj, file[, protocol])
序列化对象,并将结果数据流写入到文件file中。参数protocol是序列化模式,默认值为3。 -
pickle.load(file)
反序列化对象。将文件中的数据解析为一个Python对象。 -
注意:在load(file)的时候,要让python能够找到类的定义,否则会报错:
例子:
import pickle
class Person:
def __init__(self,n,a):
self.name=n
self.age=a
def show(self):
print self.name+"_"+str(self.age)
aa = Person("JGood", 2)
aa.show()
f=open('d:\\p.txt','w')
pickle.dump(aa,f,0)
f.close()
#del Person
f=open('d:\\p.txt','r')
bb=pickle.load(f)
f.close()
bb.show()
如果不注释掉del Person的话,那么会报错如下:
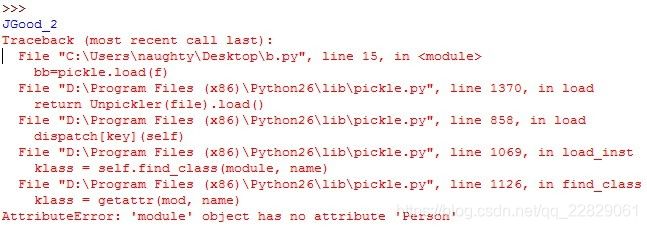
意思就是当前模块找不到类的定义了。
13 python的数学方法