python分层抽样
import pandas as pd
import numpy as np
import random
df_credit = pd.read_csv("./train.csv")
print(df_credit["Credit Default"].value_counts())
n_sample=1000
print(pd.__version__)
aa=df_credit.groupby('Credit Default').sample(n=n_sample,replace=True) ## 这个是分成抽样
print("分层抽样")
print(aa["Credit Default"].value_counts())

案例2
https://www.geeksforgeeks.org/stratified-sampling-in-pandas/
import pandas as pd
# Create a dictionary of students
students = {
'Name': ['Lisa', 'Kate', 'Ben', 'Kim', 'Josh',
'Alex', 'Evan', 'Greg', 'Sam', 'Ella'],
'ID': ['001', '002', '003', '004', '005', '006',
'007', '008', '009', '010'],
'Grade': ['A', 'A', 'C', 'B', 'B', 'B', 'C',
'A', 'A', 'A'],
'Category': [2, 3, 1, 3, 2, 3, 3, 1, 2, 1]
}
# Create dataframe from students dictionary
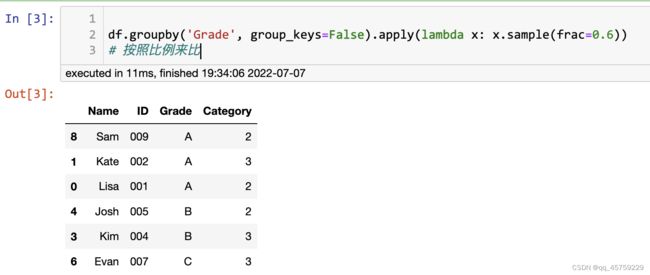
df = pd.DataFrame(students)
# view the dataframe
df
结果如下
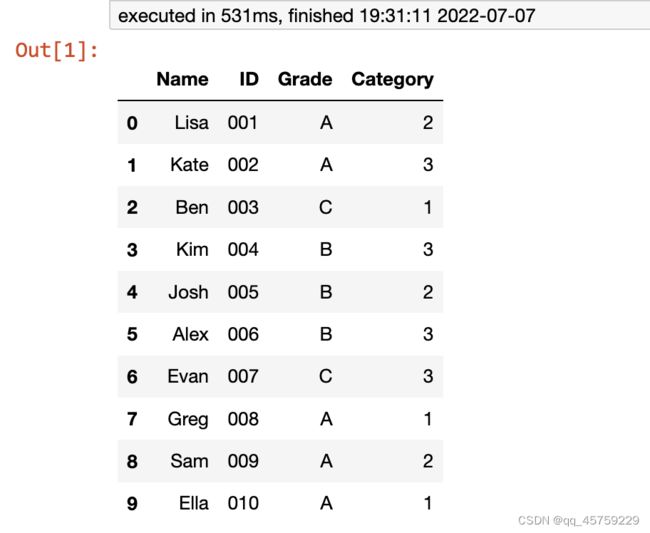
等样本抽样
df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(2))
结果如下
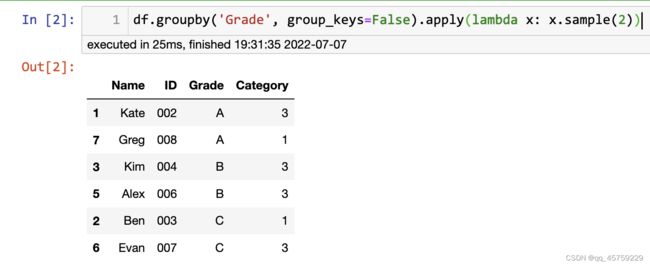
等比例抽样
df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(frac=0.6))
# 按照比例来比