安卓9可用的性能监视器_监视应用程序生态系统的性能和可用性
在这个三篇文章的系列的第1部分和第2部分中 ,我介绍了监视Java应用程序的技术和模式,重点是JVM和应用程序类。 在最后的最后一部分中,我将重点放在介绍用于从应用程序的依赖项(例如底层操作系统,网络或应用程序的支持操作数据库)收集性能和可用性数据的技术上。 最后,我将讨论收集的数据管理模式以及数据报告和可视化的方法。
Spring收藏家
在第2部分中 ,我实现了用于管理监视服务的基于Spring的基本组件模型。 此模型的原理和优点是:
- 基于XML的配置简化了配置更复杂的性能数据收集器所需的较大参数集的管理。
- 关注点分离结构允许更简单的组件通过Spring的依赖注入彼此交互。
- Spring为简单的收集bean提供了生命周期,包括初始化 , 启动和停止操作,以及向bean公开Java管理扩展(JMX)管理界面的选项,以便可以在运行时对其进行控制,监视和故障排除。
当适用时,我将在本文的每个部分中介绍基于Spring的收集器的更多详细信息。
监控主机和操作系统
Java应用程序始终在底层硬件和支持JVM的操作系统上运行。 全面监视基础结构中的关键组件是能够从硬件和操作系统(通常是通过操作系统)收集性能,运行状况和可用性指标的功能。 本节介绍了一些技术,这些技术用于通过第1部分中介绍的ITracer类来获取此数据并将其跟踪到应用程序性能管理(APM)系统。
典型的操作系统性能指标
以下摘要列出了与广泛的OS相关的典型指标。 尽管数据收集的细节可能有很大不同,并且必须在特定操作系统的上下文中考虑数据的解释,但这些度量在大多数标准主机上大致相同:
- CPU利用率 :这表示给定主机上CPU的繁忙程度。 单位通常是利用率百分比 ,在较低的水平下,它表示CPU忙碌的时间占特定时间段所经过的时钟时间的百分比。 主机可以有多个CPU,CPU可以包含多个内核,但是大多数操作系统通常都将多个内核抽象出来以分别代表一个CPU。 例如,将具有双核CPU的两CPU主机表示为四个CPU。 度量通常可以按CPU或总资源利用率收集,代表所有处理器的总利用率。 监视每个单独的CPU或聚合的需求通常由软件的性质及其内部体系结构确定。 默认情况下,标准的多线程Java应用程序通常会在所有可用CPU上平衡负载,因此可以接受聚合。 但是,在某些情况下,单个OS进程被“固定”到特定的CPU,并且聚合指标可能无法捕获适当的粒度级别。
CPU利用率通常分为四类:
- 系统 :执行系统级或操作系统内核级活动花费的处理器时间
- 用户 :处理器花费在执行用户活动上的时间
- I / O等待 :处理器等待I / O请求完成所花费的空闲时间
- 空闲 :隐式地,没有任何处理器活动
- 内存 :最简单的内存指标是可用或正在使用的物理内存的百分比。 其他注意事项与虚拟内存,内存分配和释放的速率以及有关正在使用哪些特定内存区域的更精细的指标有关。
- 磁盘和I / O :磁盘指标是对每个逻辑或物理磁盘设备可用或正在使用的磁盘空间以及对这些设备的读写速率的简单(但非常关键)报告。
- 网络 :这是网络接口上数据传输和错误的速率,通常分为高层次的网络协议分类,例如TCP和IP。
- 流程和流程组 :所有上述指标都可以表示为给定主机的总活动。 它们也可以分解为相同的度量标准,但可以由单个流程或相关流程组代表消费或活动。 通过进程监视资源利用率有助于解释主机上每个应用程序或服务所消耗的资源比例。 某些应用程序仅实例化一个过程。 在其他情况下,诸如Apache 2 Web Server之类的服务可以实例化一个进程池,这些进程池共同代表一个逻辑服务。
代理与无代理
不同的操作系统具有可访问性能数据的不同机制。 我将介绍多种收集数据的方式,但是您可能会在监视领域遇到的一个共同区别是基于 代理的监视与无代理的监视之间的对比。 这意味着在某些情况下,无需在目标主机上专门安装其他软件即可收集数据。 但是很显然,总会涉及某种代理,因为监视始终需要一个必须读取数据的接口。 这里的真正区别在于,使用通常总是存在于给定OS中的代理程序(例如Linux®服务器上的SSH)与安装存在的其他软件(其唯一目的是监视外部收集器并使收集的数据可用)之间的区别。 两种方法都需要权衡:
- 代理需要额外的软件安装,并且可能需要定期维护补丁。 在具有大量主机的环境中,软件管理工作可能会严重阻碍代理的使用。
- 如果代理在物理上与应用程序是同一进程的一部分,或者即使是单独的进程,则代理进程的失败也会使监视蒙蔽。 尽管主机本身可能仍在运行并且运行状况良好,但是APM必须假定它已关闭,因为无法访问该代理。
- 与无代理远程监视器相比,安装在主机上的本地代理可能具有更好的数据收集和事件监听功能。 此外,汇总指标的报告可能需要收集几个原始的基础指标,这些指标如果远程执行则效率不高。 本地代理可以有效地收集数据,对其进行聚合,并使聚合的数据可供远程监视器使用。
最终,一种最佳的解决方案可能是实施无代理和基于代理的监视,由负责收集大量指标的本地代理和检查诸如服务器启动状态和本地代理状态之类的基础知识的远程监视器来实现。
代理也可以有不同的选择。 自主代理按自己的时间表收集数据,而响应代理则根据请求传递数据。 有些代理只是将数据提供给请求者,而其他代理则直接或间接将数据跟踪到APM系统。
接下来,我将介绍用于监视具有Linux和UNIX®操作系统的主机的技术。
监视Linux和UNIX主机
可使用监视代理程序,这些监视程序代理程序实现专用的本机库以从Linux和UNIX OS收集性能数据。 但是Linux和大多数UNIX变体都有一组丰富的内置数据收集工具,这些工具可通过称为/ proc的虚拟文件系统访问数据。 这些文件在普通文件系统目录中似乎是普通的文本文件,但实际上它们是通过文本文件的外观抽象的内存中数据结构。 由于可以通过许多标准的命令行实用程序或自定义工具轻松地读取和解析此数据,因此这些文件易于使用,并且输出结果非常通用或非常具体。 它们的性能往往非常好,因为它们实际上是在直接从内存中拔出数据。
从/ proc用于提取性能数据的常用工具是ps , sar , iostat ,和vmstat (见相关主题对这些工具的参考文档)。 因此,监视Linux和UNIX主机的有效方法就是简单地执行shell命令并解析响应。 类似的监视器可以在各种Linux和UNIX实现中使用。 尽管它们可能都略有不同,但是以使收集过程完全可重用的方式格式化数据是微不足道的。 相反,可能需要为每个Linux和UNIX发行版重新编码或重建专用的本机库。 (很可能他们仍在读取相同的/ proc数据。)并且编写自定义的shell命令可以对特定情况进行专门的监视,或者对返回数据的格式进行标准化,非常简单,并且开销很低。
现在,我将演示几种调用Shell命令并跟踪返回的数据的方法。
Shell命令执行
要在Linux主机上执行数据收集监视,必须调用外壳程序。 它可以是bash , csh , ksh或任何其他受支持的shell,这些shell允许调用目标脚本或命令并检索输出。 最常见的选项是:
- 本地外壳程序 :如果您在目标主机上运行JVM,则线程可以通过调用
java.lang.Process来访问外壳程序。 - 远程Telnet或
rsh:这两个服务都允许调用shell和shell命令,但是它们相对较低的安全性已使它们的使用减少了。 在大多数现代发行版中,默认情况下禁用它们。 - 安全外壳(SSH) :SSH是最常用的远程外壳。 它提供对Linux Shell的完全访问权限,通常被认为是安全的。 这是本文基于shell的示例中将使用的主要机制。 SSH服务可用于多种操作系统,包括几乎所有类型的UNIX,Microsoft®Windows®,OS / 400和z / OS。
图1显示了本地外壳程序和远程外壳程序之间的概念差异:
图1.本地和远程shell
需要少量设置才能启动与服务器的无人参与SSH会话。 您必须创建一个由私钥和公钥组成的SSH 密钥对 。 公钥的内容放置在目标服务器上,而私钥的放置在数据收集器可以访问它的远程监视服务器上。 完成此操作后,数据收集器可以提供私钥和私钥的密码,并访问目标服务器上的安全远程外壳。 目标帐户的密码不是必需的,并且在使用密钥对时是多余的。 设置步骤为:
- 确保目标主机在本地已知主机文件中具有一个条目。 该文件列出了已知的IP地址或名称以及为每个IP地址或名称识别的关联的SSH公共密钥。 在用户级别,此文件通常是用户主目录中的〜/ .ssh / known_hosts文件。
- 使用监视帐户(例如Monitoruser)连接到目标服务器。
- 在主目录中创建一个名为.ssh的子目录。
- 将目录更改为.ssh目录,然后发出
ssh-keygen -t dsa命令。 该命令提示您输入密钥名称和密码。 然后生成两个文件,分别称为monitoruser_dsa(私钥)和monitoruser._dsa.pub(公钥)。 - 将私钥复制到一个安全的位置,可以从该位置运行数据收集器。
- 使用命令
cat monitoruser_dsa.pub >> authorized_keys将公共密钥内容附加到.ssh目录中的名为authorized_keys的文件中。
清单1显示了我刚刚概述的过程:
清单1.创建一个SSH密钥对
whitehen@whitehen-desktop:~$ mkdir .ssh
whitehen@whitehen-desktop:~$ cd .ssh
whitehen@whitehen-desktop:~/.ssh$ ssh-keygen -t dsa
Generating public/private dsa key pair.
Enter file in which to save the key (/home/whitehen/.ssh/id_dsa): whitehen_dsa
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in whitehen_dsa.
Your public key has been saved in whitehen_dsa.pub.
The key fingerprint is:
46:cd:d4:e4:b1:28:d0:41:f3:ea:3b:8a:74:cb:57:e5 whitehen@whitehen-desktop
whitehen@whitehen-desktop:~/.ssh$ cat whitehen_dsa.pub >> authorized_keys
whitehen@whitehen-desktop:~/.ssh$数据收集器现在可以与目标Linux主机建立SSH连接,该主机称为运行运行Ubuntu Linux的whitehen-desktop。
此示例的数据收集将使用名为org.runtimemonitoring.spring.collectors.shell.ShellCollector的通用收集器类完成。 此类的实例将在Spring上下文中以UbuntuDesktopRemoteShellCollector的名称进行UbuntuDesktopRemoteShellCollector 。 但是,需要一些剩余的依赖关系才能完成整个过程:
- 需要调度程序每分钟调用一次收集器。 这是通过
java.util.concurrent.ScheduledThreadPoolExeutor实例完成的,该实例提供了计划的回调机制和线程池。 它将在Spring以CollectionScheduler的名称进行部署。 - 需要SSH Shell实施才能针对服务器调用命令并返回结果。 这是由
org.runtimemonitoring.spring.collectors.shell.ssh.JSchRemoteShell实例提供的。 此类是称为org.runtimemonitoring.spring.collectors.shell.IRemoteShell的Shell接口的实现,将在Spring中以UbuntuDesktopRemoteShell的名称进行部署。 - 收集器不是对一组命令及其关联的解析例程进行硬编码,而是使用
org.runtimemonitoring.spring.collectors.shell.commands.CommandSet的实例,该实例将在Spring中以UbuntuDesktopCommandSet的名称进行部署。 从描述以下内容的XML文档中加载命令集:- Shell将针对其执行的目标平台
- 将要执行的命令
- 返回的数据将如何解析并映射到APM跟踪名称空间
图2.收集器,外壳和命令集
现在,我将深入研究一些特定的性能数据生成命令的简要示例,以及如何配置它们。 一个典型的例子是sar命令。 Linux手册页中sar的定义(请参阅参考资料 )是收集,报告或保存系统活动信息 。 该命令非常灵活,可以组合使用20多个参数。 一个简单的选项是调用sar -u 1 3 ,它报告在三个间隔(每个间隔一秒)中测得的CPU利用率。 清单2显示了输出:
清单2.示例sar命令输出
whitehen@whitehen-desktop:~$ sar -u 1 3
Linux 2.6.22-14-generic (whitehen-desktop) 06/02/2008
06:53:24 PM CPU %user %nice %system %iowait %steal %idle
06:53:25 PM all 0.00 0.00 0.00 0.00 0.00 100.00
06:53:26 PM all 0.00 35.71 0.00 0.00 0.00 64.29
06:53:27 PM all 0.00 20.79 0.99 0.00 0.00 78.22
Average: all 0.00 18.73 0.33 0.00 0.00 80.94 输出可以分解为前导,标题,三个间隔数据读数以及读数汇总平均值。 此处的目标是执行此shell命令,捕获输出,对其进行解析并跟踪到APM系统。 格式很简单,但输出格式可能因版本而异(略有不同),其他sar选项返回的数据完全不同(更不用说其他命令返回的格式也不同)。 例如,清单3显示了sar执行,显示了活动的套接字活动:
清单3.显示套接字活动的sar
whitehen@whitehen-desktop:~$ sar -n SOCK 1
Linux 2.6.22-14-generic (whitehen-desktop) 06/02/2008
06:55:10 PM totsck tcpsck udpsck rawsck ip-frag
06:55:11 PM 453 7 9 0 0
Average: 453 7 9 0 0 因此,需要一种解决方案,使您可以快速配置不同的格式而无需重新编码收集器。 在收集的迹线到达APM系统之前,能够将诸如totsck神秘单词totsck为更易读的短语(如Total Used Sockets)也totsck用。
在某些情况下,您可以选择以XML格式获取此数据。 例如, sadf在命令SysStat软件包(参见相关主题 )产生大量的通常收集在linux XML监控数据。 XML格式为数据提供了更多的可预测性和结构,并且实际上消除了解析,将数据映射到跟踪名称空间以及解密晦涩的单词的任务。 但是,这些工具并不总是可用于您可能希望监视的可通过shell访问的系统,因此灵活的文本解析和映射解决方案非常宝贵。
在前面两个使用sar示例之后,我现在将提供一个示例,该示例设置显着的Spring bean定义来监视此数据。 本文引用的示例代码中包含了所有引用的示例(请参阅下载 )。
首先, SpringCollector实现的主要入口点是org.runtimemonitoring.spring.collectors.SpringCollector 。 它有一个参数:Spring bean配置文件所在的目录名称。 SpringCollector加载任何扩展名为.xml的文件,并将其视为Bean描述符。 该目录是项目根目录中的./spring-collectors目录。 (在本文后面,我将概述该目录中的所有文件。多个文件是可选的,所有定义都可以捆绑为一个,但是用概念功能将它们分隔开有助于使事情井井有条。)此示例中的bean定义表示外壳收集器,外壳和命令集。 清单4中显示了描述符:
清单4.用于外壳收集器,外壳和命令集的Bean描述符
清单4中的CommandSet bean仅具有一个id ( UbuntuDesktopCommandSet )和一个指向另一个XML文件的URL。 这是因为命令集很大,我不想让它们杂乱的Spring文件。 我将在短期内介绍CommandSet 。
清单3中的第一个bean是UbuntuDesktopRemoteShellCollector 。 它的bean id值纯粹是任意的和描述性的,尽管从另一个bean引用该bean时确实需要保持一致。 在这种情况下,该类是org.runtimemonitoring.spring.collectors.shell.ShellCollector ,这是一个用于通过类似shell的接口收集数据的通用类。 其他显着属性是:
-
shell:收集器将用来调用和检索shell命令中的数据的shell类的实例。 Spring注入具有UbuntuDesktopCommandSet的beanid的shell实例。 -
commandSet:CommandSet实例,它代表一组命令以及关联的解析和跟踪名称空间映射指令。 Spring注入具有UbuntuDesktopRemoteShell的beanid的命令集实例。 -
scheduler:对调度线程池的引用,该线程池管理数据收集的调度并分配一个线程来完成工作。 -
tracingNameSpace:跟踪名称空间前缀,用于控制这些指标在APM树中的跟踪位置。 -
frequency:数据收集的频率,以毫秒为单位。
清单4中的第二个bean是外壳程序,它是SSH外壳程序的实现,该外壳程序称为org.runtimemonitoring.spring.collectors.shell.ssh.JSchRemoteShell 。 该类使用JSch从JCraft.com实现(参见相关主题 )。 其其他显着特性是:
-
userName:以其身份连接到Linux服务器的用户名。 -
hostName:要连接的Linux服务器的名称(或IP地址)。 -
port:sshd监听的Linux服务器端口。 -
knownHostFile:一个文件,其中包含运行SSH客户端的本地主机“已知”的SSH服务器的主机名和SSH证书。 (SSH中的此安全机制是对传统安全体系结构的一种有趣的逆转,在传统的安全体系结构中,除非主机是“已知的”并且出示匹配的证书,否则客户端可能不信任主机,并且不会进行连接。) -
privateKey:用于对SSH服务器进行身份验证的SSH私钥文件。 -
passPhrase:用于解锁私钥的密码。 它的外观就像一个密码,只不过它不会传输到服务器,仅用于本地解密私钥。
清单5显示了CommandSet的内部结构:
清单5. CommandSet内部
sar -u 1
\n\n
PM
Average:.*
\n
sar -n SOCK 1
\n\n
PM
Average:.*
\n
CommandSet负责管理Shell命令和解析指令。 因为每个Linux或UNIX系统的输出(即使对于相同的命令)也会有稍微不同的输出,所以对于每种被监视的唯一主机类型,通常会有一个CommandSet 。 对CommandSet后面的XML中的每个选项的详细描述将花费很长时间,因为它不断发展并针对新情况进行了调整,但是以下是其中一些标记的简要概述:
-
-
- 它们包含的
-
id属性中从零开始的索引来定义要从结果中选择哪个段落,并且该段落中的所有跟踪指标都位于在段落名称中定义的跟踪名称下。 -
entryName,则每行中的索引列将添加到跟踪名称空间。 这是针对左侧列包含度量标准界线的情况。 例如,sar一个选项将报告每个单独的CPU的CPU利用率,并且CPU编号在第二列中列出。 在清单5中 ,entryName提取all限定符,指示该报告是所有CPU的汇总摘要。values属性表示应跟踪每行中的哪些列,而offset说明了数据行中的列数与对应的标题之间的任何不平衡。 -
entryName关联的值定义不同的跟踪器类型。 -
-
图3显示了此示例的APM树:
图3.用于Ubuntu桌面监控的APM树
如果您不喜欢这棵树的外观,则还有其他选择。 可以轻松地修改发送到服务器的命令,以通过一系列grep , awk和sed命令进行管道传输,以将数据重新格式化为需要更少解析的格式。 例如,参见清单6:
清单6.在命令中格式化命令输出
whitehen@whitehen-desktop:~$ sar -u 1 | grep Average | \
awk '{print "SINT/User:"$3"/System:"$5"/IOWait:"$6}'
SINT/User:34.00/System:66.00/IOWait:0.00提供配置,灵活性和性能的最佳组合的另一个选项是使用动态脚本,尤其是在可能无法使用其他格式化工具且输出格式特别笨拙的情况下。 在下一个示例中,我配置了一个Telnet Shell,以从Cisco CSS负载平衡器收集负载平衡状态数据。 输出格式和内容对于任何种类的标准化解析都特别有问题,并且Shell支持有限的命令集。 清单7显示了该命令的输出:
清单7. CSS Telnet命令的输出
Service Name State Conn Weight Avg State
Load Transitions
ecommerce1_ssl Alive 0 1 255 0
ecommerce2_ssl Down 0 1 255 0
admin1_ssl Alive 0 1 2 2982
admin2_ssl Down 0 1 255 0
clientweb_ssl Alive 0 1 255 0 清单8显示了用于执行命令和解析的命令集。 请注意STRING类型。 敏锐的观察者会注意到,没有该名称的列,但是Groovy脚本的一部分工作是修复似乎有两个列称为State的事实(您可以看到原因),因此该脚本将第一个重命名为一个到状态。
清单8. CSS CommandSet
show service summary
\n\n\n\n
Status
\n
Groovy bean有很多好处。 该脚本是可动态配置的,因此可以在运行时进行更改。 Bean检测到源已更改,并在下一次调用时调用Groovy编译器,因此性能足够。 该语言还具有丰富的解析功能并且易于编写。 清单9显示了Groovy Bean,其中包含内联源代码的文本:
清单9. Groovy格式化bean
图4显示了用于CSS监视的APM度量树:
图4.用于CSS监视的APM树
SSH连接
Linux / UNIX Shell收集的最后一个考虑因素是SSH连接问题。 所有shell类的基本接口是org.runtimemonitoring.spring.collectors.shell.IShell 。 它定义了称为issueOSCommand()的方法的两种变体,其中命令作为参数传递,并返回结果。 在使用远程SSH类我的例子org.runtimemonitoring.spring.collectors.shell.ssh.JSchRemoteShell ,底层shell调用是根据实施SSHEXEC中的Apache Ant任务(见相关主题 )。 所使用的技术的优点是简单,但是有一个明显的缺点:为发出的每个命令建立新的连接。 这显然是低效的。 可能仅每隔几分钟就轮询一次远程外壳,但是每个轮询周期可以执行几个命令来获取适当范围的监视数据。 面临的挑战是,在监视窗口持续时间内(跨越多个轮询周期)保持打开的会话非常棘手。 它需要更详细地检查返回的数据并进行分析,以解决不同的shell类型和shell提示的持续出现的问题,当然,这不是您期望的返回值的一部分。
我一直在进行长期的会话外壳实现。 另一种选择是妥协:每个轮询周期模式保持一个连接,但尝试在一个命令中捕获所有数据。 这可以通过附加命令来完成,或者在某些情况下,可以针对一个命令使用多个选项。 例如,我的SuSE Linux服务器上的sar版本具有-A选项,该选项返回所有受支持的sar度量的样本; 该命令等效于sar -bBcdqrRuvwWy -I SUM -n FULL -P ALL 。 返回的数据将具有多个段落,但是使用命令集解析它应该没有问题。 有关此示例,请参见本文示例代码Suse9LinuxEnterpriseServer.xml中的命令集定义(请参阅下载 )。
监视Windows
性能数据收集也不例外,Microsoft Windows与Linux / UNIX之间存在实质性差异。 Windows实际上没有提供可比较数量的性能报告数据的本地命令行工具。 也无法通过相对简单的/ proc文件系统之类的东西来访问性能数据。 Windows Performance Manager(WPM)(也称为SysMon,System Monitor或Performance Monitor)是从Windows主机获取性能度量的标准界面。 它功能强大且有用的指标丰富。 此外,许多基于Windows的软件包都通过WPM发布自己的指标。 Windows还通过WPM提供了图表,报告和警报功能。 图5显示了WPM实例的屏幕截图:
图5. Windows Performance Manager
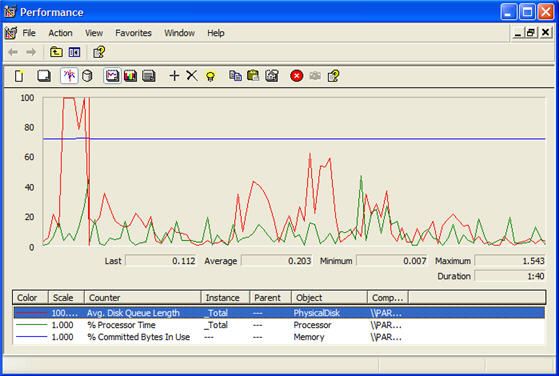
WPM管理一组性能计数器 ,这些性能计数器是引用特定度量的复合名称对象。 化合物名称的组成部分是:
- 性能对象 :性能指标的常规类别,例如“ 处理器”或“ 内存” 。
- 实例 :当多个可能的成员存在时,某些性能对象将由一个实例划分。 例如,处理器具有代表每个单独的CPU的实例和一个汇总的总实例。 相反,内存是一个“平坦的”性能对象,因为内存只有一种表现形式。
- 计数器 :实例(如果适用)和性能对象中指标的粒度名称。 例如,处理器实例0具有一个称为%空闲时间的计数器。
基于这些名称段,用于表达这些对象的命名约定和语法为:
- 带有实例: \性能对象(实例名称)\计数器名称
- 没有实例: \性能对象\计数器名称
WPM的显着缺点是,尤其是从远程访问此数据可能具有挑战性,而从非Windows平台访问则极具挑战性。 我将介绍许多使用基于ITracer的收集器捕获WPM数据的技术。 以下是主要选项的简短摘要:
- 日志文件读取 :可以将WPM配置为将所有收集的指标记录到日志文件中,然后可以读取,解析和跟踪该文件。
- 数据库查询 :WPM可以配置为将所有收集的指标记录到SQL Server数据库中,可以在其中读取,解析和跟踪它们。
- Win32 API :使用Win32 API(.NET,C ++,Visual Basic等)编写的客户端可以使用WPM的API直接连接到WPM。
- 自定义代理 :自定义代理可以安装在目标Windows服务器上,该代理可以充当非Windows客户端对WPM数据的外部请求的代理。
- 简单网络管理协议(SNMP) :SNMP是代理程序的一个实例,由于它具有监视设备,主机等的能力,因此更加注重虚拟化。 我将在本文稍后讨论SNMP。
- WinRM :WinRM是WS-Management规范的Windows实现,概述了Web服务在系统管理中的使用。 因为Web服务是语言和平台无关的,所以这无疑为非Windows客户端提供了对WPM指标的访问。 尽管可以将其视为代理的另一种形式,但它将成为Windows 2008的标准,并将其投放到无代理解决方案领域。 更有趣的是,Java Specification Request 262(JMX代理的Web服务连接器)承诺直接与基于Windows的WS-Management服务进行交互。
在下面的示例中,我将使用本地Windows Shell和代理实现提供理论上的概念证明。
本地Windows Shell
作为一个简单的概念证明,我已经用C#创建了一个Windows命令行可执行文件,称为winsar.exe 。 其目的是提供一些与Linux / UNIX sar命令相同的命令行访问性能统计信息。 命令行用法的语法很简单: winsar.exe Category Counter Raw Instance 。
实例名称是必需的,除非计数器不是实例计数器,并且可以全为( * )。 计数器名称是必填项,但可以全为( * )。 Raw是true还是false 。 Listing 10 displays example uses for an instance-based counter and a non-instance-based counter:
Listing 10. winsar examples with non-instance- and instance-based counters
C:\NetProjects\WinSar\bin\Debug>winsar Memory "% Committed Bytes In Use" false
%-Committed-Bytes-In-Use
79.57401
C:\NetProjects\WinSar\bin\Debug>winsar LogicalDisk "Current Disk Queue Length" false C:
Current-Disk-Queue-Length
C: 2 Based on my intention to recreate something like sar , the data output is in a rough (nonformatted) tabular form so it can be parsed using a standard shell command set. For instance-based counters, the instances are in the first column of the data lines, with the counter names across the header line. For non-instance-based counters, there are no names in the first field of the data lines. For parsing clarity, any names with spaces are filled with "-" characters. The result is fairly ugly but easily parsed.
Setting up a collector for these statistics (which are abbreviated for presentation) is fairly straightforward. The shell implementation is a org.runtimemonitoring.spring.collectors.shell.local.WindowsShell , and the command sets reference the winsar.exe and arguments. The shell can also be implemented as a remote shell using SSH, which requires the installation of an SSH server on the target Windows host. However, this solution is highly inefficient, primarily because the implementation is .NET-based; it's not efficient to start up a Common Language Runtime (CLR) for such a brief period on a repeating basis.
Another solution might be to rewrite winsar in native C++. I'll leave that to Windows programming experts. The .NET solution can be made efficient, but the program must remain running as a background process, servicing requests for WPM data through some other means and not terminating after every request. In pursuit of this, I implemented a second option in winsar in which an argument of -service starts the program, reads in a configuration file called winsar.exe.config , and listens for requests over a Java Message Service (JMS) topic. The contents of the file are fairly self-explanatory except for a couple of items. The jmsAssembly item refers to the name of a .NET assembly containing a .NET version of the JBoss 4.2.2 client libraries that are supplying the JMS functionality. This assembly was created using IKVM (see Related topics ). The respondTopic references the name of the public topic where responses are published, rather than using a private topic, so that other listeners can receive the data as well. The commandSet is a reference to the command set that should be used by the generic receiver to parse and trace the data. Listing 11 shows the winsar.exe.config file:
Listing 11. The winsar.exe.config file
Implementing the collector in Spring to use this service is conceptually similar to setting up the shells. In fact, the collector itself is an extension of org.runtimemonitoring.spring.collectors.shell.ShellCollector called org.runtimemonitoring.spring.collectors.shell.DelegatingShellCollector . The difference is that this shell acts like an ordinary collector and issues requests for data, but the data is received through JMS, parsed, and traced by another component. The shell implemented, called org.runtimemonitoring.spring.collectors.shell.jms.RemoteJMSShell , behaves like a shell but dispatches the command through JMS, as illustrated in Figure 6:
Figure 6. Delegating collector
Because this looks like a good strategy for deploying agents across the board, the same JMS-based agent is implemented in Java code and can be deployed on any JVM-supporting OS. A JMS publish/subscribe performance data collection system is illustrated in Figure 7:
Figure 7. JMS publish/subscribe monitoring
A further distinction can be drawn with respect to how the JMS agents function. The pattern illustrated in this example exhibits a request listening agent on the target hosts, in that the agents perform no activity after they are started until they receive a request from the central monitoring system. However, these agents could act autonomously by collecting data and publishing it to the same JMS server on their own schedule. However, the advantage of the listening agents is twofold. First, the collection parameters can be configured and maintained in one central location rather than reaching out to each target host. Second (although not implemented in this example), because the central requesting monitor is sending out requests, the monitor can trigger an alert condition if a specific known server does not respond. Figure 8 displays the APM tree for the combined servers:
Figure 8. APM tree for Windows and Linux servers
winsar is a simple and early prototype with several shortcomings, which include:
- Programmatic access to some WPM counters (such as the Processor object) produces empty or raw metrics. So it's impossible to read a metric such as CPU % Utilization directly. What is required is a means of taking more than one reading over a defined period of time, after which the CPU utilization can be calculated.
winsardoes not contain this functionality, but similar agents such as such as NSClient and NC_Net (see Related topics ) do provide for this. - Admittedly, using JMS as the transport for remote agents, while having some elegance, is limiting. NSClient and NC_Net both use a low-level but simple socket protocol to request and receive data. One of the original intents for these services was to provide Windows data to Nagios, a network-monitoring system almost exclusive to the Linux platform, so realistically there could be no Win32 APIs in the picture from the client side.
Finally, as I mentioned before, the SpringCollector application bootstraps with a single parameter, which is the directory containing the configuration XML files. This directory is /conf/spring-collectors in the root of the sample code package. The specific files used in the preceding examples are:
- shell-collectors.jmx : Contains the definitions for all the shell collectors.
- management.xml : Contains JMX management beans and the collection scheduler.
- commandsets.xml : Contains the definitions for the shell collector's command sets. These reference external XML files in /commands.
- shells.xml : Contains the definitions for all the shells.
- jms.xml : Contains the definitions for the JMS connection factory and topics and a Java Naming and Directory Interface (JNDI) context.
- groovy.xml : Contains the Groovy formatter bean.
This concludes my discussion of OS monitoring. Next, I'll cover the monitoring of database systems.
Monitoring database systems using JDBC
I have frequently encountered cultures that feel strongly that monitoring the database is the exclusive domain of the DBAs and their tools and applications. However, in pursuit of a nonsiloed and centralized APM repository for performance and availability data, it makes sense to complement the DBA efforts with some amount of monitoring from a consolidated APM. I will demonstrate some techniques using a Spring collector called JDBCCollector to gather data that in some cases is most likely not being monitored elsewhere and can usefully add to your arsenal of metrics.
The general categories of data collection that you should consider are:
- Simple availability and response time : This is a simple mechanism to make a periodic connection to a database, issue one simple query and trace the response time, or trace a server-down metric if the connection fails. A failure in the connection may not necessarily indicate that the database is experiencing a hard down, but it clearly demonstrates, at the very least, communication issues from the application side. Siloed database monitoring may never indicate a database connectivity issue, but it is useful to remember that just because you can connect to a service from there does not mean that you can connect from here .
- Contextual data : Revisiting the concept of contextual tracing from Part 1 , you can leverage some useful information from periodic sampling of your application data. In many cases, there is a strong correlation between patterns of data activity in your database and the behavior or performance of your application infrastructure.
- Database performance tables : Many databases expose internal performance and load metrics as tables or views, or through stored procedures. As such, the data is easily accessible through JDBC. This area clearly overlaps with traditional DBA monitoring, but database performance can usually be correlated so tightly to application performance that it is a colossal waste to collect these two sets of metrics and not correlate them through a consolidated system.
The JDBCCollector is fairly simple. At base, it is a query and series of mapping statements that define how the results of the queries are mapped to a tracing name space. Consider the SQL in Listing 12:
Listing 12. A sample SQL query
SELECT schemaname, relname,
SUM(seq_scan) as seq_scan,
SUM(seq_tup_read) as seq_tup_read
FROM pg_stat_all_tables
where schemaname = 'public'
and seq_scan > 0
group by schemaname, relname
order by seq_tup_read desc The query selects four columns from a table. I want to map each row returned from the query to a tracing namespace that consists in part of data in each row. Keep in mind that a namespace is made up of a series of segment names followed by a metric name. The mapping is defined by specifying these values using literals, row tokens, or both. A row token represents the value in a numbered column, such as {2} . When the segments and metric name are processed, literals are left as is while tokens are dynamically substituted with the respective column's value from the current row in the result of the query, as illustrated in Figure 9:
Figure 9. JDBCCollector mapping
In Figure 9, I'm representing a one-row response to the query, but the mapping procedure occurs once for each mapping defined for each row returned. The segment's value is {1},{2} , so the segment portion of the tracing namespace is {"public", "sales_order"} . The metric names are literals, so they stay the same, and the metric value is defined as 1 in the first mapping, and 2 in the second, representing 3459 and 16722637 , respectively. A concrete implementation should clarify further.
Contextual tracing with JDBC
The application data in your operational database probably has useful and interesting contextual data. The application data itself is not necessarily performance-related itself, but when it's sampled and correlated with historical metrics that represent the performance of your Java classes, JVM health, and your server performance statistics, you can draw a clear picture of what the system was actually doing during a specific period. As a contrived example, consider you are monitoring an extremely busy e-commerce Web site. Orders placed by your customers are logged in a table called sales_order along with a unique ID and the timestamp of when the order was placed. By sampling the number of records entered in the last n minutes, you can derive a rate at which orders are being submitted.
This is another place where the ITracer 's delta capabilities are useful, because I can set up a JDBCCollector to query the number of rows since a specific time, and simply trace that value as a delta. The result is a metric (probably among many others) that depicts how busy your site is. This also becomes a valuable historical reference. For example, if you know that when the rate of incoming orders hits 50 per cycle, your database starts slowing down. Hard and specific empirical data eases the process of capacity and growth planning.
Now I'll implement this example. The JDBCCollector uses the same scheduler bean as the prior examples, and it also has a JDBC DataSource defined that's identical to the ones I covered in Part 2 . These database collectors are defined in the /conf/spring-collectors/jdbc-collectors.xml file. Listing 13 shows the first collector:
Listing 13. Order-fulfillment rate collector
? and order_date < ?
]]>
The collector bean name in this case is OrderFulfilmentRateLast5s , and the class is org.runtimemonitoring.spring.collectors.jdbc.JDBCCollector . The standard scheduler collector is injected in, as is a reference to the JDBC DataSource, RuntimeDataSource . The query defines the SQL that will be executed. SQL queries can either use literals as parameters, or, as in this example, use bind variables. This example is somewhat contrived because the two values for order_date could easily be expressed in SQL syntax, but typically a bind variable would be used when some external value needed to be supplied.
To provide the capability to bind external values, I need to implement the org.runtimemonitoring.spring.collectors.jdbc.IBindVariableProvider interface and then implement that class as a Spring-managed bean. In this case, I am using two instances of org.runtimemonitoring.spring.collectors.jdbc.RelativeTimeStampProvider , a bean that supplies a current timestamp offset by the passed period property. These beans are RelativeTime , which returns the current time minus 5 seconds, and CurrentTime , which returns "now" plus 10 milliseconds. References to these beans are injected into the collector bean through the binds property, which is a map. It is critical that the value of each entry in the map match the bind variable in the SQL statement it is intended for; otherwise, errors or unexpected results can occur.
In effect, I am using these bind variables to capture the number of sales orders entered into the system in approximately the last five seconds. This is quite a lot of querying against a production table, so the frequency of the collection and the window of time (that is, the period of Relative ) should be adjusted to avoid exerting an uncomfortable load on the database. To assist in adjusting these settings correctly, the collector traces the collection time to the APM system so the elapsed time can be used as a measure of the query's overhead. More-advanced implementations of the collector could decay the frequency of collection as the elapsed time of the monitoring query increases.
The mapping I presented above is defined through the queryMaps property using an inner bean of the type org.runtimemonitoring.spring.collectors.jdbc.QueryMap . It has four simple properties:
-
valueColumn: The zero-based index of the column in each row that should be bound as the tracing value. In this case, I am binding the value ofcount(*). -
segments: The tracing namespace segment, which is defined as a single literal. -
metricName: The tracing namespace of the metric name, also defined as a literal. -
metricType: TheITracermetric type, which is defined as a stickyint.
The collector allows for multiple queryMap s to be defined per collector on the basis that you might want to trace more than one value from each executed query. The next example I'll show you uses rowToken s to inject values from the returned data into the tracing namespace, but the current example uses literals. However, to contrive an example using the same query, I could change the query to select count(*), 'Sales Order Activity', 'Order Rate' from sales_order where order_date > ? and order_date < ? 。 This makes my desired segment and metric names return in the query. To map them I can configure segments to be {1} and metricName to be {2} . In some stretch cases, the metricType might even come from the database, and that value can be represented by a rowToken too. Figure 10 displays the APM tree for these collected metrics:
Figure 10. Sales-order rate monitoring
Database performance monitoring
Using the same process, the JDBCCollector can acquire and trace performance data from database performance views. In the case of this example, which uses PostgreSQL, these tables — referred to as statistics views — have names prefixed with pg_stat . Many other databases have similar views and can be accessed with JDBC. For this example, I'll use the same busy e-commerce site and set up a JDBCCollector to monitor the table and index activity on the top five busiest tables. The exact SQL for this is shown in Listing 14:
Listing 14. Table and index activity monitor
0
group by schemaname, relname, idx_tup_fetch,
seq_tup_read, seq_scan, idx_scan
order by total desc
LIMIT 5 ]]>
The query retrieves the following values every 20 seconds for the top 5 busiest tables:
- The name of the database schema
- The name of the table
- The total number of sequential scans
- The total number of tuples retrieved by sequential scans
- The total number of index scans
- The total number of tuples retrieved by index scans
The last four columns are all perpetually increasing values, so I'm using a metric type of SDLONG , which is a sticky delta long . Note that in Listing 14 I have configured four QueryMap s to map these four columns into a tracing namespace.
In this scenario, I have contrived a useful example without creating an index on the sales_order table. Consequently, monitoring will reveal a high number of sequential scans (also referred to as table scans in database parlance), which is an inefficient mechanism for retrieving data because it reads every row in the table. The same applies to the sequential tuple reads — basically the number of rows that have been read using a sequential scan. There is a significant distinction between rows and tuples, but it is not relevant in this situation. You can refer to the PostgreSQL documentation site for clarification (see Related topics ). Looking at these statistics in the APM display, it is clear that my database is missing an index. This is illustrated in Figure 11:
Figure 11. Sequential reads
As soon as I notice this, I fire off a couple of SQL statements to index the table. The result shortly thereafter is that the sequential operations both drop down to zero, and the index operations that were zero are now active. This is illustrated in Figure 12:
Figure 12. After the index
The creation of the index has a rippling effect through the system. One of the other metrics that jumps out as visibly settled down is the User CPU % on the database host. This is illustrated in Figure 13:
Figure 13. CPU after the index
Database availability
The last JDBC aspect I'll address is the relatively simple one of availability. Database availability in its simplest form is an option in the standard JDBCCollector . If the collector is configured with a availabilityNameSpace value, the collector will trace two metrics to the configured namespace:
- Availability : A
1if the database could be connected to and a0if it could not - Connect time : The elapsed time consumed to acquire a connection
The connect time is usually extremely fast when a data source or connection pool is being used to acquire a connection. But most JDBC connection-pooling systems can execute a configurable SQL statement before the connection is handed out, so the test is legitimate. And under heavy load, connection acquisition can have a nonzero elapsed time. Alternatively, a separate data source can be set up for a JDBCCollector that is dedicated to availability testing. This separate data source can be configured not to pool connections at all, so every poll cycle initiates a new connection. Figure 14 displays the availability-check APM tree for my PostgreSQL runtime database. Refer to Listing 14 for an example of the use of the availabilityNameSpace property.
Figure 14. The runtime database availability check
I have seen situations in which the determination of a specific status requires multiple chained queries. For example, a final status requires a query against Database A but requires parameters that can only be determined by a query against Database B. This condition can be handled with two JDBCCollector s with the following special considerations:
- The chronologically first query (against Database B) is configured to be inert in that it has no schedule. (A collection frequency of zero means no schedule.) The instance of the
JDBCCollectoralso implementsIBindVariableProvider, meaning that it can provide bind variables and binding to another collector. - The second collector defines the first collector as a bind that will bind in the results of the first query.
This concludes my discussion of database monitoring. I should add that this section has focused on database monitoring specifically through the JDBC interface. Complete monitoring of a typical database should also include monitoring of the OS the database resides on, the individual or groups of database processes, and some coverage of the network resources where necessary to access the database services.
Monitoring JMS and messaging systems
This section describes techniques to monitor the health and performance of a messaging service. Messaging services such as those that implement JMS — also referred to as message-oriented middleware (MOM) — play a crucial role in many applications. They require monitoring, like any other application dependency. Frequently, messaging services provide asynchronous, or "fire-and-forget," invocation points. Monitoring these points can be slightly more challenging because from many perspectives, the service can appear to be performing well, with calls to the service being dispatched frequently and with very low elapsed times. What can remain concealed is an upstream bottleneck where messages are being forwarded to their next destination either very slowly, or not at all.
Because most messaging services exist either within a JVM, or as one or more native processes on a host (or group of hosts), the monitoring points include some of the same points as for any targeted service. These might include standard JVM JMX attributes; monitoring resources on the supporting host; network responsiveness; and characteristics of the service's processes, such as memory size and CPU utilization.
I'll outline four categories of messaging-service monitoring, three of them being specific to JMS and one relating to a proprietary API:
- In order to measure the throughput performance of a service, a collector periodically sends a group of synthetic test messages to the service and then waits for their return delivery. The elapsed time of the send, receive, and total round trip elapsed time is measured and traced, along with any failures or timeouts.
- Many Java-based JMS products expose metrics and monitoring points through JMX, so I will briefly revisit implementing a JMX monitor using the Spring collector.
- Some messaging services provide a proprietary API for messaging-broker management. These APIs typically include the ability to extract performance metrics of the running service.
- In the absence of any of the preceding options, some useful metrics can be retrieved using standard JMS constructs such as a
javax.jms.QueueBrowser.
Monitoring messaging services through synthetic test messages
The premise of synthetic messages is to schedule the sending and receiving of test messages to a target messaging service and measure the elapsed time of the messages' send, receive, and total round trip. To contrive the message's return, and also potentially to measure the response time of message delivery from a remote location, an optimal solution is to deploy a remote agent whose exclusive task is to:
- Listen for the central monitor's test messages
- Receive them
- Add a timestamp to each received message
- Resend them back to the messaging service for delivery back to the central monitor
The central monitor can then analyze the returned message and derive elapsed times for each hop in the process and trace them to the APM system. This is illustrated in Figure 15:
Figure 15. Synthetic messages
Although this approach covers the most monitoring ground, it does have some downsides:
- It requires the deployment and management of a remote agent.
- It requires the creation of additional queues on the messaging services for the test message transmission.
- Some messaging services allow for the dynamic creation of first-class queues on the fly, but many require manual queue creation through an administrative interface or through a management API.
An alternative that is outlined here as specific to JMS (but may have equivalents in other messaging systems) is the use of a temporary queue or topic. A temporary queue can be created on the fly through the standard JMS API, so no administrative intervention is required. These temporary constructs have the added advantage of being invisible to all other JMS participants except the originating creator.
In this scenario, I'll use a JMSCollector that creates a temporary queue on startup. When prompted by the scheduler, its sends a number of test messages to the temporary queue on the target JMS service and then receives them back again. This effectively tests the throughput on the JMS server and does not require the creation of concrete queues or the deployment of a remote agent. This is illustrated in Figure 16:
Figure 16. Synthetic messages with a temporary queue
The Spring collector class for this scenario is org.runtimemonitoring.spring.collectors.jms.JMSCollector . The configuration dependencies are fairly straightforward, and most of the dependencies are already set up from previous examples. The JMS connectivity requires a JMS javax.jms.ConnectionFactory . I acquire this using the same Spring bean that was defined to acquire a JMS connection factory in the Windows WPM collection example. As a recap, this required one instance of a Spring bean of type org.springframework.jndi.JndiTemplate that provides a JNDI connection to my target JMS service, and one instance of a Spring bean of type org.springframework.jndi.JndiObjectFactoryBean that uses the JNDI connection to lookup the JMS connection factory.
To provide some flexibility in the makeup of the synthetic message payload, the JMSCollector is configured with a collection of implementations of an interface called org.runtimemonitoring.spring.collectors.jms.ISyntheticMessageFactory . Objects that implement this interface provide an array of test messages. The collector calls each configured factory and executes the round-trip test using the supplied messages. In this way, I can test throughput on my JMS service with payloads that vary by message size and message count.
Each ISyntheticMessageFactory has a configurable and arbitrary name that's used by the JMSCollector to add to the tracing name space. The full configuration is shown in Listing 15:
Listing 15. Synthetic message JMSCollector
org.jnp.interfaces.NamingContextFactory
localhost:1099
org.jboss.naming:org.jnp.interfaces
The two message factories implemented in Listing 15 are:
- A
javax.jms.MapMessagefactory that loads the current JVM's system properties into the payload of each message and is configured to send 10 messages per cycle - A
javax.jms.ByteMessagefactory that loads the bytes from a JAR file into the payload of each message and is configured to send 10 messages per cycle
Figure 17 displays the APM tree for the synthetic-message monitoring. Note that the size of the byte payload is appended to the end of the javax.jms.ByteMessage message factory name.
Figure 17. APM tree for synthetic messages with a temporary queue
Monitoring messaging services through JMX
Messaging services such as JBossMQ and ActiveMQ expose a management interface through JMX. I introduced JMX-based monitoring in Part 1 . I'll briefly revisit it now and introduce the Spring collector based on the org.runtimemonitoring.spring.collectors.jmx.JMXCollector class and how it can be used to monitor a JBossMQ instance. Because JMX is a constant standard, the same process can be used to monitor any JMX-exposed metrics and is widely applicable.
The JMXCollector has two dependencies:
- A
javax.management.MBeanServerConnectionfor the local JBossMQ is provided by the bean namedLocalRMIAdaptor. In this case, the connection is acquired by issuing a JNDI lookup for a JBossorg.jboss.jmx.adaptor.rmi.RMIAdaptor. Other providers are usually trivial to acquire, assuming that any applicable authentication credentials can be supplied, and the Springorg.springframework.jmx.supportpackage supplies a number of factory beans to acquire different implementations ofMBeanServerConnections (see Related topics ). - A profile of JMX collection attributes packaged in a collection bean containing instances of
org.runtimemonitoring.spring.collectors.jmx.JMXCollections. These are directives to theJMXCollectorabout which attributes to collect.
The JMXCollection class exhibits some attributes common to JMX monitors. The basic configuration properties are:
-
targetObjectName: This is the full JMXObjectNamename of the MBean that is targeted for collection, but it can also be a wildcard. The collector queries the JMX agent for all MBeans matching the wildcard pattern and then collects data from each one. -
segments: The segments of the APM tracing namespace where the collected metrics are traced. -
metricNames: An array of metric names that each MBean attribute should be mapped to, or a single*character that directs the collector to use the attribute name provided by the MBean. -
attributeNames: An array of MBean attribute names that should be collected from each targeted MBean. -
metricTypesordefaultMetricType: An array of metric types that should be used for each attribute, or one single metric type that should be applied to all attributes.
The MBean ObjectName wildcarding is a powerful option because is effectively implements discovery of monitoring targets rather than needing to configure the monitor for each individual target. In the case of JMS queues, JBossMQ creates a separate MBean for each queue, so if I want to monitor the number of messages in each queue (referred to as the queue depth ) I can simply specify a general wildcard such as jboss.mq.destination:service=Queue,* that all instances of JMS queue MBeans will be collected from. However, I have the additional challenge of dynamically figuring out what the queue name is, because these objects are discovered on the fly. In this case, I know that the value of the MBean's ObjectName name property of the discovered MBeans is the name of the queue. For example, a discovered MBean might have an object name of jboss.mq.destination:service=Queue, name=MyQueue . Accordingly, I need a way of mapping properties from discovered objects to tracing namespaces in order to demarcate traced metrics from each source. This is achieved using tokens in similar fashion to the rowToken in the JDBCCollector . The supported tokens in the JMXCollector are:
-
{target-property: name }: The token is substituted with the named property from the target MBean'sObjectName. Example:{target-property:name}. -
{this-property: name }: The token is substituted with the named property from the collector'sObjectName. Example:{this-property:type}. -
{target-domain: index }: The token is substituted with the indexed segment of the target MBean'sObjectNamedomain. Example:{target-domain:2}. -
{this-domain: index }: The token is substituted with the indexed segment of the collector'sObjectNamedomain. Example:{target-domain:0}.
Listing 16 shows the abbreviated XML configuration for the JBossMQ JMXCollector :
Listing 16. Local JBossMQ JMXCollector
Figure 18 displays the APM tree for the JBossMQ server's JMS queues monitored using the JMXCollector :
Figure 18. APM tree for JMX monitoring of JBossMQ queues
Monitoring JMS queues using queue browsers
In the absence of an adequate management API for monitoring your JMS queues, it is possible to use a javax.jms.QueueBrowser . A queue browser behaves almost exactly like a javax.jms.QueueReceiver , except that acquired messages are not removed from the queue and are still delivered once retrieved by the browser. Queue depth is typically an important metric. It is commonly observed that in many messaging systems, message producers outpace message consumers. The severity of that imbalance can be viewed in the number of messages being queued in the broker. Consequently, if queue depths cannot be accessed in any other way, using a queue browser is a last resort. The technique has a number of downsides. In order to count the number of messages in a queue, the queue browser must retrieve every message in the queue (and then discard them). This is highly inefficient and will have a much higher elapsed time to collect than using a management API — and probably take a higher toll on the JMS server's resources. An additional aspect of queue browsing is that for busy systems, the count will most likely be wrong by the time the browse is complete. Having said that, for the purposes of monitoring an approximation is probably acceptable, and in a highly loaded system even a highly accurate measurement of a queue depth at any given instant will be obsolete in the next instant anyway.
Queue browsing has one benefit: In the course of browsing a queue's messages, the age of the oldest message can be determined. This is a difficult metric to come by, even with the best JMS-management APIs, and in some cases it can be a critical monitoring point. Consider a JMS queue used in the transmission of critical messages. The message producer and message consumer have typical differentials, and the pattern of traffic is such that a standard poll of the queue depth typically shows one or two messages. Ordinarily, this is due to a small amount of latency, but with a polling frequency of one minute, the messages in the queue are not the same messages from poll to poll. 还是他们? They might not be the same ones, in which case the situation is normal. But it could be that both the message producer and message consumer simultaneously failed, and the couple of messages being observed in the queue are the same messages every single poll. In this scenario, monitoring the age of the oldest message in parallel with the queue depth makes the condition clear: normally the message ages are less than a few seconds, but if a double failure in the producer/consumer occurs, it will only take the time between two polling cycles for conspicuous data to start emerging from the APM.
This functionality is demonstrated in the Spring collector's org.runtimemonitoring.spring.collectors.jmx.JMSBrowserCollector . Its two additional configuration properties are a javax.jms.ConnectionFactory , just like the JMSCollector , and a collection of queues to browse. The configuration for this collector is shown in Listing 17:
Listing 17. Local JBossMQ JMSBrowserCollector
The APM tree for this collector is displayed in Figure 19:
Figure 19. APM tree for JMSBrowserCollector
As a testing mechanism, a load script looped, sending a few hundred messages to each queue on a loop. In every loop, a queue was picked at random to purge. Accordingly, the maximum message age in each queue varied randomly over time.
Monitoring messaging systems using proprietary APIs
Some messaging systems have a proprietary API for implementing management functions such as monitoring. Several of these use their own messaging system in a request/response pattern to submit management requests. ActiveMQ (see Related topics ) provides a JMS messaging-management API as well as a JMX-management API. Implementing a proprietary management API requires a custom collector. In this section I'll present a collector for WebSphere® MQ (formerly referred to as MQ Series). The collector uses a combination of two APIs:
- MS0B: WebSphere MQ Java classes for PCF : The PCF API is an administrative API for WebSphere MQ.
- The core WebSphere MQ Java classes : An API formerly referred to as MA88 has been integrated into the core WebSphere MQ Java class library (see Related topics ).
The use of the two APIs is redundant, but the example exhibits the use of two different proprietary APIs.
The Spring collector implementation is a class called org.runtimemonitoring.spring.collectors.mq.MQCollector . It monitors all queues on a WebSphere MQ server, gathering each one's queue depth and the number of current open input and output handles. The configuration for the org.runtimemonitoring.spring.collectors.mq.MQCollector is shown in Listing 18:
Listing 18. WebSphere MQ collector
The unique configuration properties here are:
-
host: The IP address of the WebSphere MQ server's host name -
port: The port that the WebSphere MQ process is listening on for connections -
channel: The WebSphere MQ channel to connect to
Note that this example does not contain any authentication aspects.
Figure 20 displays the APM tree generated for the org.runtimemonitoring.spring.collectors.mq.MQCollector :
Figure 20. APM tree for MQCollector
This concludes my discussion of messaging-service monitoring. As I promised earlier, I'll now cover monitoring with SNMP.
Monitoring using SNMP
SNMP was originally created as an application-layer protocol for exchanging information between network devices such as routers, firewalls, and switches. This is still probably its most commonly used function, but it also serves as a flexible and standardized protocol for performance and availability monitoring. The whole subject of SNMP and its implementation as a monitoring tool is larger than the summary scope of this article. However, SNMP has become so ubiquitous in the monitoring field that I would be remiss in not covering the topic to some extent.
One of the core structures in SNMP is the agent , which is responsible for brokering SNMP requests targeted at a specific device. The relative simplicity and low-level nature of SNMP makes it straightforward and efficient to embed an SNMP agent into a wide range of hardware devices and software services. Consequently, SNMP promises one standardized protocol to monitor the most number of services in an application's ecosystem. In addition, SNMP is widely used to execute discovery by scanning a range of IP addresses and ports. From a monitoring perspective, this can save some administrative overhead by automatically populating and updating a centralized inventory of monitoring targets. In many respects, SNMP is a close analog to JMX. Despite some of the obvious differences, it is possible to draw several equivalencies between the two, and interoperability between JMX and SNMP is widely supported and implemented. Table 1 summarizes some of the equivalencies:
Table 1. SNMP and JMX comparison
| SNMP structure | Equivalent JMX structure |
|---|---|
| 代理商 | Agent or MBeanServer |
| 经理 | Client, MBeanServerConnection , Protocol Adapter |
| MIB | MBean , ObjectName , MBeanInfo |
| OID | ObjectName and ObjectName + Attribute name |
| 陷阱 | JMX Notification |
GET , SET |
getAttribute , setAttribute |
BULKGET |
getAttributes |
From a simple monitoring perspective, the critical factors I need to know when issuing an SNMP inquiry are:
- Host address : The IP address or host name where the target SNMP agent resides.
- Port : The port the target SNMP agent is listening on. Because a single network address may be fronting a number of SNMP agents, each one needs to listen on a different port.
- Protocol version : The SNMP protocol has gone through a number of revisions and support levels vary by agent. Choices are: 1, 2c, and 3.
- Community : The SNMP community is a loosely defined administrative domain. An SNMP client cannot issue requests against an agent unless the community is known, so it serves in part as a loose form of authentication.
- OID : This is a unique identifier of a metric or group of metrics. The format is a series of dot-separated integers. For example, the SNMP OID for a Linux host's 1 Minute Load is
.1.3.6.1.4.1.2021.10.1.3.1and the OID for the subset of metrics consisting of 1, 5, and 15 Minute Loads is.1.3.6.1.4.1.2021.10.1.3
Aside from the community, some agents can define additional layers of authentication.
Before I dive into SNMP APIs, note that SNMP metrics can be retrieved using two common command-line utilities: snmpget , which retrieves the value of one OID, and snmpwalk , which retrieves a subset of OID values. With this in mind, I can always extend my ShellCollector CommandSet to trace SNMP OID values. Listing 19 demonstrates an example of snmpwalk with raw and cleaned outputs retrieving the 1, 5, and 15 Minute Loads on a Linux host. I am using version 2c of the protocol and the public community.
Listing 19. Example of snmpwalk
$> snmpwalk -v 2c -c public 127.0.0.1 .1.3.6.1.4.1.2021.10.1.3
UCD-SNMP-MIB::laLoad.1 = STRING: 0.22
UCD-SNMP-MIB::laLoad.2 = STRING: 0.27
UCD-SNMP-MIB::laLoad.3 = STRING: 0.26
$> snmpwalk -v 2c -c public 127.0.0.1 .1.3.6.1.4.1.2021.10.1.3 \
| awk '{ split($1, name, "::"); print name[2] " " $4}'
laLoad.1 0.32
laLoad.2 0.23
laLoad.3 0.22The second command can be easily represented in my Linux command set, as shown in Listing 20:
Listing 20. CommandSet for handling a snmpwalk command
\n
There are several commercial and open source SNMP Java APIs. I have implemented a basic Spring collector called org.runtimemonitoring.spring.collectors.snmp.SNMPCollector , which uses an open source API called joeSNMP (see Related topics ). The collector has the following critical configuration properties:
-
hostName: The IP address or host name of the target host. -
port: The port number the target SNMP agent is listening on (defaults to161). -
targets: A set of SNMP OID targets made up of instances oforg.runtimemonitoring.spring.collectors.snmp.SNMPCollection. The configuration properties for that bean are:-
nameSpace: The tracing namespace suffix. -
oid: The SNMP OID of the target metric.
-
-
protocol: The SNMP protocol:0for v1 and1for v2 (defaults to v1). -
community: The SNMP community (defaults topublic). -
retries: The number of times to attempt the operation (defaults to1). -
timeOut: The timeout of the SNMP call in ms (defaults to5000).
A sample configuration of an SNMPCollector setup to monitor my local JBoss application server is shown in Listing 21:
Listing 21. Configuration for the SNMPCollector
The collector does have some shortcomings in that the configuration is somewhat verbose, and the runtime is inefficient because it makes one call per OID instead of bulk collecting. The snmp-collectors.xml file in the sample code (see Download ) also contains an example SNMP collector configuration for Linux server monitoring. Figure 21 displays the APM system metric tree:
Figure 21. APM tree for SNMPCollector
At this stage, you probably get the idea of how to create collectors. Full coverage of an environment may require several different types of collectors, and this article's source code contains additional examples of collectors for other monitoring targets if you are interested. They are all in the org.runtimemonitoring.spring.collectors package. These are summarized in Table 2:
Table 2. Additional collector examples
| Collection target | 类 |
|---|---|
| Web services: Checks the response time and availability of secure Web services | webservice.MutualAuthWSClient |
| Web services and URL checks | webservice.NoAuthWSClient |
| Apache Web Server, performance and availability | apacheweb.ApacheModStatusCollector |
| 平 | network.PingCollector |
| NTop: A utility for collecting detailed network statistics | network.NTopHostTrafficCollector |
数据管理
One of the most complex challenges of a large and busy availability and performance data gathering system is the efficient persistence of the gathered data to a common metrics database. The considerations for the database and the persistence mechanism are:
- The metrics database must support reasonably fast and simple querying of historical metrics for the generation of data visualizations, reporting, and analysis.
- The metrics database must retain history and granularity of data to support the time windows, accuracy, and the required precision of reporting.
- The persistence mechanism must perform sufficiently well and concurrently to avoid affecting the liveliness of the front-end monitoring.
- The retrieval and storage of metric data must be able to run concurrently without one having a negative impact on the other.
- Requests for data from the database should be able to support aggregation over periods of time.
- The data in the database should be stored in a way that allows the retrieval of data in a time-series pattern or some mechanism that guarantees that multiple data points are significantly correlated if associated with the same effective time period.
In view of these considerations, you need:
- A good-performing and scalable database with a lot of disk space.
- A database with efficient search algorithms. Essentially, because metrics will be stored by compound name, one solution is to store the compound name as a string and use some form of pattern matching in order to specify the target query metrics. Many relational databases have support for regex built into the SQL syntax, which is ideal for querying by compound names but tends to be slow because it typically precludes the use of indexes. However, many relational databases also support functional indexes that could be used to speed up queries when using a pattern matching search. Another alternative is to completely normalize the data and break out the individual segments of the compound name (see Normalized vs. flat database structure below).
- A strategy for limiting the number of writes and the total data volume written to the database is to implement a series of tiered aggregation and conflation. This can be done before the data is written to the database by keeping a rollup buffer of metrics. For a fixed period of time, you write all metrics tagged for storage to an accumulating buffer, which keeps the metric effective start time and end time, and the average, minimum, and maximum values of the metric for that period. In this way, metric values are conflated and aggregated before being written to the database. For example, if a collector's frequency is 15 seconds, and the aggregation period is 1 minute, 4 individual metrics will be conflated to 1. This assumes some tolerance for loss of granularity in persisted data, so there's a trade-off between lower granularity with lower data volume and higher granularity at the cost of higher data volume. At the same time, real-time visualization of metrics can be achieved by rendering graphics from preaggregation in-memory circular buffers so only persisted data is aggregated. Of course, you can be selective about which metrics actually need to be persisted.
- An additional strategy for reducing data volume stored is to implement a sampling frequency where only x out of every y raw metrics are stored. Again, this reduces granularity of persisted data but will use fewer resources (especially memory) than maintaining aggregation buffers.
- Metric data can also be rolled up and purged in the metric database after persistence. Again, within the tolerance for loss of granularity, you can roll up periods of data in the database into summary tables for each hour, day, week, month, and so on; purge the raw data; and still retain reasonable and useful sets of metric data.
- In order to avoid affecting the data collectors themselves through the activity of the data-persistence process, it is critical to implement noninvasive background threads that can flush discrete collections of metric data to a data-storage process.
- It can be challenging to create accurate time-series-like reports after the fact from multiple data sets that do not have the same effective time window. Consider the x axis of a graph, which represents time, and the y axis, which represents the value of a specific metric and multiple series (lines or plots) that represent readings for the same metric from a set of different sources. If the effective timestamp of the readings for each series is significantly different, the data must be massaged to keep the graph representation valid. This can be done by aggregating the data up to the lowest common consistent time window between all the plotted series, but again, this loses granularity. A much simpler solution is to maintain a consistent effective timestamp across all metric values. This is a feature of time-series databases. A commonly used one is RRDTool , which effectively enforces consistent and evenly spaced timestamps across different data values in a series. In order to keep effective timestamps consistent in a relational database, a good strategy is to take samplings of all metrics in line with a single uniform scheduler. For example, a single timer might fire off every two minutes, resulting in a single "swipe" of all metrics captured at that time, and all are tagged with the same timestamp and then queued for persistence at the persistor's leisure.
Obviously, it is challenging to address each and every one of these issues in a completely optimal way, and compromises must be considered. Figure 22 illustrates a conceptual data-persistence flow for a data collector:
Figure 22. Data-management flow
Figure 22 represents the data flow from a conceptual data collector like the Spring collectors presented in this article. The objective is to push individual-metric trace measurements through a series of tiers until they are persisted. The process is:
- The data collector is optionally configured for metric persistence with the following properties:
- Persistence enabled : True or false.
- Metric name filter : A regular expression. Metric names that match the regular expression are marked for persistence beyond the historical cache.
- Sampling count : The number of metric collections that should skip persistence for every one that is. 0 would mean no skips.
- Historical cache size : The number of metrics traced that should be stored in cache. For real-time visualization purposes, most metrics should be enabled for historical cache even if not marked for persistence so that they can be rendered into real-time charts.
- The collector cache is a number of discrete metric readings equal to the number of distinct metrics being generated by the collector. The cache is first in, first out (FIFO), so when the historical cache reaches full size, the oldest metrics are discarded to make room for the newest. The cache supports the registration of cache event listeners that can be notified of individual metrics being added and dropped from the cache.
- The collector rollup is a series of two or more circular caches of one instance of each metric being generated by the collector. As each cache instance in the circular buffer becomes active, it registers new trace events for historical cache and aggregates each incoming new value, effectively conflating the stream of data for a given period. The rollup contains:
- The start and end time of the period. (The end time isn't set until the end of the period.)
- The minimum, maximum, and average reading for the period.
- The metric type.
- A central timer fires a flush event at the end of every period. When the timer fires, the collector rollup circular buffer index is incremented, and historical cache events are delivered to the next cache in the buffer. Then each aggregated rollup in the "closed" buffer has a common timestamp applied to it and is written to a persistence queue waiting to be stored to the database.
Note that when the circular buffer increments, the minimum, maximum, and average values in the next buffer element will be zero, except for sticky metric types.
- A pool of threads in the persistence thread pool reads the rollup items from the persistence queue and writes them to the database.
The length of the aggregation period during which the same collector rollups are being conflated is determined by the frequency of the central flush timer. The longer the period, the less data is written to the database, at the cost of data granularity.
Normalized vs. flat database structure
Several specialized databases, such as RRDTool , might be considered for metric storage, but relational databases are used frequently. When you implement metric storage in a relational database, you have two general options to consider: normalizing the data or keeping a flatter structure. This is mostly applicable to how the compound metric names are stored; all other reference data should probably be normalized in line with your data-modeling best practices.
The benefit of a completely normalized database structure is that by breaking out the metric compound names into their individual segments, virtually any database can take advantage of indexing to speed up queries. They also store less redundant data, which in turn leads to a smaller database, higher density of data, and better performance. The downside is the complexity and size of the queries: even a relatively simple compound metric name, or pattern of metric names (for example, % User CPU on hosts 11 through 93) requires that the SQL contain several joins and many predicates. This can be mitigated through the use of database views and the hard storage of common metric name decodes. The storage of each individual metric requires the decomposition of the compound name to locate the metric reference data item (or create a new one), but this performance overhead can be mitigated by caching all the reference data in the persistence process.
Figure 23 shows a model for storing compound metrics in a normalized structure:
Figure 23. A normalized model for metric storage
In Figure 23, each individual unique compound metric is assigned a unique METRIC_ID , and each individual unique segment is assigned a SEGMENT_ID . Then compound names are built in an associative entity that contains the METRIC_ID , SEGMENT_ID , and the sequence that the segments appear in. The metric types are stored in the reference table METRIC_TYPE , and the metric values themselves are stored in METRIC_INSTANCE with value, timestamp start and end properties, and then references to the metric type and the unique METRIC_ID .
On the other hand, a flat model is compelling in its simplicity, as illustrated in Figure 24:
Figure 24. A flat model for metric storage
In this case, I have separated out the metric name from the compound name, and the remaining segments are retained in their original pattern in the segments column. Again, if the database engine implemented is capable of performing queries that perform well on wide text columns with pattern-based predicates such a regular expression, this model has the virtue of being simple to query against. This aspect should not be undervalued. The building of data-analysis, visualization, and reporting tools is significantly streamlined with a simplified query structure, and speed of query writing during an emergency triage session is possibly the most important aspect of all!
If you need persistent data storage, picking the right database is a crucial step. Using a relational database is workable, provided it performs well enough and you can extract data from it formatted to your needs. The generation of time-series-driven data can be challenging, but through correct grouping and aggregation — and the use of additional tools such as JFreeChart (see Related topics ) — you can generate good representative reports and graphics. If you elect instead to implement a more specialized database such as RRDTool, be prepared to go the long way around when it comes to extracts and reports after the fact. If the database does not support standards such as ODBC and JDBC, this will exclude the use of commonly available and standardized reporting tools.
This concludes my discussion of data management. This article's final section presents techniques for visualizing data in real time.
Visualization and reporting
At some point, you will have implemented your instrumentation and performance data collectors, and data will be streaming into your APM system. The next logical step is to see a visual representation of that data in real time. I use the term real time loosely here to mean that visualizations represent data that was collected very recently.
The commonly used term for data visualizations is dashboard . Dashboards can present virtually any aspect of data pattern or activity that you can think of, and they are limited only by the quality and quantity of the data being collected. In essence, a dashboard tells you what's going on in your ecosystem. One of the real powers of dashboards in APM systems is the capability to represent vastly heterogeneous data (that is, data collected from different sources) in one uniform display. For example, one display can simultaneously show recent and current trends in CPU usage on the database, network activity between the application servers, and the number of users currently logged into your application. In this section, I'll present different styles of data visualization and an example implementation of a visualization layer for the Spring collector I presented earlier in this article.
The premises of the Spring collector visualization layer are:
- An instance of a cache class is deployed as a Spring bean. The cache class is configurable to retain any number of historical
ITracertraces but is fixed-size and FIFO. A cache might be configured with a history size of 50, meaning that once the cache is fully populated, it retains the last 50 traces. - Spring collectors are configured in the Spring XML configuration file with a
cacheConfigurationthat wraps the instance ofITracerwith a caching process. The configuration also associates the collector to the defined cache instance. Collected traces are processed as they normally are, but are added the cache instance associated with the collector. Using the preceding example, if the cache has a history size of 50 and the collector collects data every 30 seconds, the cache, when fully populated, retains the last 25 minutes of all traces collected by the collector. - The Spring collector instance has a number of rendering classes deployed. Renderers are classes that implement the
org.runtimemonitoring.spring.rendering.IRendererinterface. Their job is to acquire arrays of data from the caches and render some form of visualization from that data. Periodic retrieval of the visualization media from a renderer generates fresh and up-to-date presentations, or as up to date as the cache data is. - The rendered content can then be delivered to a client within the context of a dashboard such as a Web browser or some form of rich client.
Figure 25 outlines this process:
Figure 25. Caching and rendering
The cache implementation in this example is org.runtimemonitoring.spring.collectors.cache.TraceCacheStore . Other objects can register to be cache event listeners, so among other events, the renderers can listen on new cache item events indicating a new value has been added to the cache. In this way, the renderers can actually cache the content they generate but invalidate the cache when new data is available. The content from the renderers is delivered to client dashboards through a servlet called org.runtimemonitoring.spring.rendering.MediaServlet . The servlet parses the requests it receives, locates the renderer, and requests the content (all content is rendered and delivered as a byte array) and the content's MIME type. The byte array is then streamed to the client along with the MIME type so the client can interpret the stream. Serving graphical content from a URL-based service is ideal, because it can be consumed by Web browsers, rich clients, and everything between. When the renderers receive a request for content from the media server, the content is delivered from cache unless the cache has been marked dirty by a cache event. In this way, the renderers do not need to regenerate their content on every request.
Generating, caching, and delivering visual media in byte-array format is useful because it is the lowest common denominator, and most clients can reconstitute the content when provided the MIME type. Because this implementation caches generated content in memory, I use a compression scheme. The total memory consumption adds up significantly for a lot of cached content; once again, if the compression-algorithm symbol is provided with the content, most clients can decompress. Most contemporary browsers, for example, support gzip decompression. However, reasonable compression levels are not especially high (I'm seeing from 30 to 40 percent on larger images), so rendering implementations can either cache to disk, or if disk access is more overhead, regenerating content on the fly might be less resource-intensive.
A specific example will be useful here. I set up two Apache Web Server collectors to monitor the number of busy worker threads. Each collector has an assigned cache, and I set up a small number of renderers to provide charts to display the number of busy workers on each server. In this case, the renderer generates a PNG file displaying a time-series line graph with series for both servers. The collector and cache setup for one server is shown in Listing 22:
Listing 22. An Apache Web Server collector and cache
Note the cacheConfiguration property in the collector and how it references the cache object called Apache2-AP02-Cache .
I also set up a renderer that is an instance of org.runtimemonitoring.spring.rendering.GroovyRenderer . This renderer delegates all rendering to an underlying Groovy script on the file system. This is ideal, because I can tweak it at run time to fine-tune details of the generated graphic. This renderer's general properties are:
-
groovyRenderer: A reference to aorg.runtimemonitoring.spring.groovy.GroovyScriptManager, which is configured to load a Groovy script from a directory. This is the same class I used to massage data returned from the Telnet session to my Cisco CSS. -
dataCaches: A set of caches that the renderer requests data from and renders. The renderer also registers to receive events from the caches when they add new items. When it does, it marks its content as dirty, and it is regenerated on the next request. -
renderingProperties: Default properties passed to the renderer that direct specific details of the generated graphic, such as the image's default size. As you'll see below, these properties can be overridden by the client request. -
metricLocatorFilters: A collector cache contains cached traces for every metric generated by the collector. This property allows you to specify an array of regular expressions to filter down which metrics you want.
The cache setup is shown in Listing 23:
Listing 23. Graphic renderer for Apache Web Server busy worker monitoring
xSize=700
ySize=300
title=Apache Servers Busy Workers
xAxisName=Time
yAxisName=# of Workers Busy
Renderers are fairly straightforward to implement, but I find that I constantly want to tweak them, so the Groovy approach outlined here works well to prototype a new chart type, or perhaps a new graphics package, quickly. Once the Groovy code compiles, the performance is good and with good content caching should not be an issue. The dynamic hot update and highly functional Groovy syntax make it easy to make updates on the fly. Later on, when I have figured out exactly what I want the renderer to do and what all the options that it should support are, I'll port them over to Java code.
The naming of metrics is generated by the org.runtimemonitoring.tracing.Trace class. Each instance of this class represents one ITracer reading, so it is an encapsulation of the value traced, the time stamp, and the full namespace. The name of the metric is the full namespace, including the metric name. In this case, the metric I am displaying is WebServers/Apache/Apache2-AP01/Busy Workers , so the filters defined in the renderer in Listing 23 zones in on this one metric for rendering. The JPG generated is shown in Figure 26:
Figure 26. Rendered Apache busy workers
Different clients may require differently rendered graphics. For instance, one client may require a smaller image. Images resized on the fly typically get blurred. Another client may require an image that is smaller still and may want to dispense with the title (and provide a title in its own UI). The MediaServlet allows additional options to be implemented during content requests. These options are appended the content request's URL and are processed in REST format. The basic format is the media servlet path (this is configurable) followed by the cache name, or /media/Apache2-All-BusyWorkers-Line . Each renderer can support different options. For the renderer used above, the following options provide a good example of this:
- Default URI : /media/Apache2-All-BusyWorkers-Line
- Reduced to 300 X 300 : /media/Apache2-All-BusyWorkers-Line/300/300
- Reduced to 300 X 300 with minimal title and axis names : /media/Apache2-All-BusyWorkers-Line/300/300/BusyWorkers/Time/#Workers
Figure 27 shows two reduced pie charts with no title using the URI Apache2-AP02-WorkerStatus-Pie/150/150/ /:
Figure 27. Reduced images of Apache Server worker pools
Renderers can generate content in virtually any format that can be displayed by the client requesting it. Image formats can be JPG, PNG, or GIF. Other image formats are supportable, but for static images targeted for Web browser clients, PNG and GIF probably work best. Other options for formats are text-based using markup such as HTML. Browsers and rich clients can both render fragments of HTML, which can be ideal for displaying individual data fields and cross-tabular tables. Plain text can also be useful. For example, a Web browser client might retrieve text from a renderer that represents system-generated event messages and insert it into a text box or list box. Other types of markup are also highly adaptable. Many rich clients and client-side rendering packages for browsers read in XML documents defining graphics that can then be generated on the client side, which is optimal for performance.
Client-side rendering offers an additional opportunity for optimization. If a client can render its own visualizations, then it is possible to stream cache updates directly to the client, bypassing the renderers unless they are needed to add markup tags. In this way, a client can subscribe to cache update events and, on receipt of them, update its own visualizations. Streaming data to clients can be done in a number of ways. In browser clients, a simple Ajax-style poller can periodically check the server for updates and implement a handler that inserts any updates into the data structure handling the rendering in the browser. Other options that are slightly more complicated involve real streaming of data using the Comet pattern, whereby a connection to the server remains open at all times and data is read by the client as it is written by the server (see Related topics ). For rich clients, using a messaging system is ideal where clients subscribe to data-update feeds. ActiveMQ has the ability to do both in that in conjunction with the Jetty Web server and its Comet capabilities, it is possible to create a browser-based JavaScript JMS client and subscribe to queues and topics.
The rich rendering possible on the client side also adds capabilities not available with flat images, such as the ability to click on elements for drill-down — a common requirement in APM dashboards where drill-down is used to navigate or see specific items represented in charts in more detail. An example of this is Visifire, an open source charting tool that works with Silverlight (see Related topics ). Listing 24 shows a fragment of XML that generates a bar chart showing CPU utilization across database servers:
Listing 24. Graphic renderer for database average CPU utilization
The XML is fairly trivial, so it is simple to create a renderer for it, and the presentation is quite nice. Client-side renderers can also animate visualizations, which for an APM system display is of variable value, but in some cases, may be helpful. Figure 28 shows the graph generated in a browser with the Silverlight client enabled:
Figure 28. A VisiFire Silverlight rendered chart
The standard chart types all have a place in APM dashboards. The most common are line, multiline, bar, and pie charts. Often charts are combined, such as bar and lines to display overlaps of two different types of data. In other cases, a line chart has a double y -axis so that data series representing values of significantly different magnitudes can be represented on the same graph. This might be the case when plotting a percentage value against a scalar value such as % CPU Utilization on a router against the number of bytes transferred.
In some scenarios, specialized widgets can be created to represent data in a customized manner, or because they display data in an intuitive display. For example, enumerated symbols display a specific icon in accordance with the status of the monitoring target. Because a status is usually represented by a limited number of potential values, charting is overkill, so something like a traffic-light display represents red for down, amber for warning, and green for okay. Another popular widget for this is the dial (often represented as a speedometer). I think dials are a waste of screen space, because they display only one vector of data with no history. A line graph shows the same data and the historical trend to boot. One exception is that multineedle dials can show ranges such as high/low/current. But for the most part, they're for visual appeal, like the ones in Figure 29 showing database block buffer gets per second with the high/low/current for the past hour:
Figure 29. Example dial widgets
In my view, the premium for visualization is on density of information. Screen space is limited, and I want to see as much data as possible. Data density can be achieved in several ways, but some of the more interesting ones are custom graphic representations that combine multiple dimensions of data in one small picture. A good example, shown in Figure 30, is from a (sadly) retired database-monitoring product:
Figure 30. Savant cache hit ratio display
Figure 30 displays several vectors of data revolving around database buffer hit ratios:
- The horizontal axis represents the percentage of data found in cache.
- The vertical axis represents the current hit ratio.
- The X represents the trending hit ratio.
- The gray circle (barely visible in this image) is the standard variation. The larger the diameter of the gray circle, the more variation there has been in cache performance.
- The yellow ball represents cache performance over the last hour.
A second approach to data density that takes a more minimalist approach is Sparklines. This term was coined by data visualization expert Edward Tufte (see Related topics ) for "small, high resolution graphics embedded in a context of words, numbers, images." They are commonly used to display a large number of financial statistics. Although they lack context, their purpose is to display relative trends across many metrics. A Sparkline renderer is implemented by the org.runtimemonitoring.spring.rendering.SparkLineRenderer class, which implements the open source Sparklines for Java library. (see Related topics ) An example of two (magnified) Sparklines is illustrated in Figure 31, showing bar- and line-based displays:
Figure 31. Sparklines showing Apache 2 busy workers
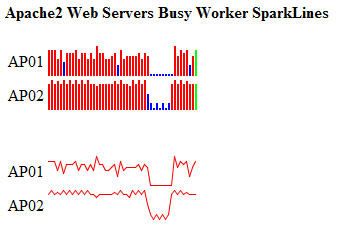
The examples outlined here and in the attached code are fairly basic, but clearly an APM system requires highly advanced and detailed dashboards. Moreover, most users will not want to create dashboards from scratch. APM systems usually have some form of dashboard generator that allows a user to view or search a repository of available metrics and pick which ones to embed in the dashboard and in what format they should be displayed. Figure 32 displays a section of a dashboard I created with my APM system:
Figure 32. Dashboard example
结论
This concludes my series . I have presented guidelines, some general performance-monitoring techniques, and specific development patterns you can implement to enhance or build your own monitoring system. Collecting and analyzing good data can significantly improve your application uptime and performance. I encourage developers to participate in the process of monitoring production applications: there is no better source of information to determine and experience what is really going on with the software you've written as it runs under load. This feedback is invaluable as part of an ongoing improvement cycle. Happy monitoring!
Acknowledgment
A big thanks to Sandeep Malhotra for his assistance with the Web service collectors.
翻译自: https://www.ibm.com/developerworks/java/library/j-rtm3/index.html