task-oriented dialogues 面向任务型对话综述
task-oriented对话系统主要是为解决特定任务的,比如订票任务(订机票,电影票等),预定饭店等。
区别于问答系统和闲聊机器人,任务是否能成功完成是衡量系统的一大重要因素,也是很多论文中的一个评价指标:task sucess rate。
目前主要有两种实现方式,pipeline结构和end-to-end结构。
1.end-to-end 结构
end-to-end结构则是不将具体步骤模块化,而是直接学习输入到输出的映射关系,用一个总的神经网络结构(RNN/LSTM/Attention)来代替上述的各个模块。

end-to-end结构对话系统
2.pipeline 结构
pipeline结构主要包括四个部分。
自然语言理解(nature language understanding, NLU):以用户对话为输入(经ASR识别得到的可能会有误差),输出的得到话语中包含的语义信息(domain、intent、slot-value)。
对话状态跟踪(dialog state track, DST):对话状态包含了到对话当前轮为止关于用户意图的所有信息,学习对话状态的变化,以供系统做出正确策略。
对话策略学习(dialog policy learning, DPL):根据对话状态,判断用户意图,返回系统行为,对用户的话进行回复。
自然语言生成(nature language generation):根据系统行为,生成正确合语法的自然语句回复。

2.1 自然语言理解(nature language understanding, NLU)
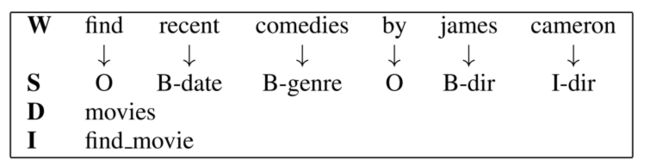
NLU模块以用户话语为输入,执行三个任务:领域识别、意图检测和槽填充[3]。如图W是用户话语,S是slot filling任务,D是domain detection任务,I是Intent determination任务。
领域识别和意图检测通常被建模为分类问题,槽填充被建模为序列标注问题。
对于这三个任务可以分开来做,也可以联合来做(类似于multi-task learning)。目前的一些方向:
1.考虑mutli-class classification任务。
2.考虑多轮对话中的contextual information来完成slot filling任务。
3.考虑零样本学习(zero-shot learning)解决训练数据不足问题。
2.1.1 SLot filling
这里简单介绍下slot是什么,slot filling任务又是做什么。
slot可以理解为有专家预定义的一些标签,这些标签有具体的值。比如在订电影票的任务中,有一个slot是movie_name,表示电影名这个标签,而这个标签具体对应的值要根据用户的意图来填空,可能是“Titanic”,可能是”Three fools"等,要根据对话看哪个值是用户提到的或者想看的。
此外,slot一般分为两类: informable 和 requestable。
a slot is called informable if the value for this slot can be used to constrain the conversation, such as phone_number;
a slot is called requestable if the speaker can ask for its value, such as ticket_price.
Note that a slot can be both informable and requestable, an example being movie_name.
即:
informable slot 一般是由用户告知系统的,用来约束对话的一些条件,系统为了完成任务必须满足这些约束。
requestable slot 一般是用户向系统咨询的,可以来做选择的一些slot。
一个slot可能既是informable的也是requestable的。
2.2 对话状态跟踪(dialog state track, DST)
对话状态包含了到对话当前轮为止关于用户意图的所有信息,之后对话策略学习部分将把对话状态作为输入来做决策(即决定系统行为dialog act)。
对话状态可能包含的部分:
1.每个informable slot的目标约束,以槽值对的形式表示。
2.用户向系统咨询的requested slot的值。
3.上一轮系统做出的决策,系统行为。
4.当前轮的用户意图。
最近出来比较流行的DST模型就是17年的Neural Belief Tracker(NBT)[4]。
该模型使用了神经网络的方法。该模型有三个输入:系统话语,用户话语,正在 被DST追踪的任意槽值对。前两个首先分别(通过多层感知机和 卷积神经网络)被映射为一个内部的 向量表示。 第三个候选的slot-value对也会被表示 为向量。这三个向量之间互相作用来获得上下文 模型,用来从对话中获得未来的上下文 信息和语义解码,来决定用户是否清晰 表达了一个对应于输入的槽值对的意图。最后上下文模型和语义解码向量经过一 个softmax层来得到最后的预测。 对于每一个候选的槽值对都会重复上述 过程。

另一个新出的是18年的Sequicity framework。这是一个将DST和DPL结合起来训练的端到端方法。
该篇论文提出使用belief spans来表示对话状态。belief spans包含两个部分:一个用于informable slot,一个用于requestable slots。每个部分收集到目前为止为对话中的各个插槽找到的值。
另外DST领域有个很著名的比赛DSTC。(感兴趣的可以自行搜索。
2.3 对话策略学习(dialog policy learning, DPL)
DPL是我目前主要学习和研究的方向。之前一直在学习和研究NLU。
对话策略可以由标准强化学习算法优化。有两种使用强化学习的方法:online和batch。online方法是指代理与用户进行交互来改进其策略;batch方法是指系统事先假定了一系列的用户对话的转变,并且只基于数据优化策略。
2.3.1 DQN
这里只主要介绍下DQN作为典型。(其他强化学习的内容这里先不讨论)
DQN是指用深度学习的方法(MLP/RNN/CNN等)实现Q-learning。DQN的输入是当前对话状态的编码。一种方法是将其编码为特征向量,由(1)上一轮用户行为和与之相关的slots的one-hot编码;(2)上一轮系统行为和与之相关的slots的one-hot编码;(3)到目前为止之前对话中所有填过值得一组槽;(4)当前的轮数;(5)来自KB(knowledge base)的满足之前所有informed slots的约束的结果;组成。假设这些组成的输入向量为s。
DQN输出一个实值向量,所有可能被系统选择的(dialogue act, slot)对。假设输出向量为q。
整个模型有 L ≥ 1 层隐藏层,参数矩阵为W1,W2,…,WL。则有
h0=s
hl=g(Wlhl−1),l=1,2,…,L−1
q=WLhL−1
g(•)是激活函数,ReLU或者sigmoid函数。最后输出的q是Q(s,·)的近似,在状态s时的Q-values。学习网络中的参数可以使用现有的强化学习算法。当学到这些参数后,网络会得到一个贪心的系统行为选择策略:对于当前的对状态 s, 使用网络中的前向过程计算 q,所有系统行为的 Q-values。通过选择 q 中最大值来选择了某个行为(dialogue act 和 与之相关的 slots)。但是这里有个问题就是,由于需要exploration,上述的贪心地选择系统的策略可能不是长期以来最好的。这里解释下 exploration,在使用强化学习方法学习策略时我们不仅要选择当前可以预见的最好的回复,还要去探寻那些可能产生更好的回复的系统行为,这样可能是在长期来说对学习策略的一个好处,这就是 exploration。与之相对的就是 exploitation 。
2.3.2 Policy Gradient
Policy Gradient是另一类强化学习方法。这个算法直接优化策略,而不学习Q函数。在这种算法中策略本身由θ参数化,π(s,θ)是关于系统行为的分布。给定参数θ,策略可以通过轮次为H,τ=(s1,a1,r1,…,sH,aH,rH)的对话中的平均长期奖励来评估:
J(θ):=E[∑t=1Hγt−1rt|at∼π(st;θ)]
θ←θ+α∇θJ(θ)
2.3.3 Policy Learning 目前的几个方向
- Effient Exploration
这个问题主要是考虑如何权衡exploitation 和 exporation 之间的关系。
在用强化学习方法来学习策略时,在没有老师的情况下,基于RL的代理通过与最初未知的环境交互,然后从收集的交互数据中学习。通常,代理需要在新的状态时尝试新的系统行为来发现潜在的可能更好的策略(这就是exploration),但有时候也要考虑:根据目前收集到的信息,选择好的行为来最大化奖励(这就是exploitation)。所以这时候我们就要考虑如何进行有效的exploration。在对话策略学习的语境中,策略学习者尝试新的方式与用户交互通常是希望可以发现一个从长远来看更好的策略。
现在研究的两个方向,一是finite-state RL,另一个是参数化模型是神经网络这种的。目前第二种的论文会更多一些,主要是出现在NIPS上的。
- Domain Extension
领域扩展问题是指在系统部署后,随着时间可能需要添加更多的intent和slot使得系统更丰富。这个问题也使得exploration更具有挑战性:因为agent需要明确地量化intents/slot参数中的不确定性,以便更积极地探索新内容,同时避免探索已经学习过的内容。
主要方法有18年提出的BBQ网络,受到了Thompson Sampling的启发。
- Composite-task Dialogues
在许多现实生活问题中,一个任务可能由一系列需要解决的子任务共同组成。而同样,复合任务对话,指的是可以被分解为一系列相关的子对话,每个子对话集中在一个子主题上。比如说一个旅行规划对话系统,需要以一种协同的方式订机票,旅馆,汽车租赁,以满足所谓的slot constraints 的特定交叉子任务的约束。slot constraints是对应于特定应用的。在旅行规划问题中,一个很平常的约束就是出站航班的到达时间要早于旅馆的办理入住时间。
这类问题的策略学习有两个挑战:(1)由于每个子任务对应于一个域,有其自己领域内的槽定义,这些所有槽的集合组成了复合问题的槽集。由于槽的约束,这些字任务无法独立解决,因此状态空间也会比一般任务大很多。(2)复合任务通常需要更多轮次来完成,一般的奖励函数只在整个对话结束后给出成功与否的奖励,因此整个奖励信号是稀疏和有延迟的,使得优化更困难。
目前的一种方法是分级强化学习[6]。任务等级有两级。顶层策略πg选择哪个子任务g来解决,底层策略πa,g解决由上级选择的特定子任务。另外有论文将deepRL换成了Gaussian processRL来完成策略学习。
这里引发出来的一个问题是:基于子目标的分级强化学习需要合理的子任务和选项分类。如何去定义这些子任务,专家?ML?DL?。
另一种分级RL是Feudal RL(封疆强化学习)。上述的分级RL是在时间维上分为多个子任务,FRL是在空间上将任务进行了分解。在每轮对话,feudal policy首先决定是information-gathering行为还是information-providing行为,然后在相关的高水平类别中选择一个行为。
- Multi-domain Dialogues
多域对话里的属于不同域的子对话是独立的任务,没有跨任务的时隙约束。因为涉及到多域对话,因此也需要更大的对话状态空间,因此,需要学习可重用策略,这些策略的参数可以跨多个域共享,只要它们是相关的。介绍几种方法:
1.15年提出的BCM(Bayesian Committee Machine),提出在训练的时候在不同的可能很小的数据集上学习得到多个策略,在测试阶段这些策略都提议一个行为,然后所有的建议最终由BCM policy聚集为一个行为。
2.16年提出来的NDQN(Network of DQNs),每个DQN被训练为可以在特定的子对话中对话。meta-policy来控制如何在这些DQN中转换。
3.18年有论文提出通过描述一个域的一组特征,针对不同域优化的策略可以被共享。
- Integration of Planning and Learning
优化针对人类的以任务为导向的对话策略是代价高昂的,因为它需要对话系统和人之间进行许多互动。模拟用户为基于RL的策略优化提供了一种廉价的替代方法,但可能不是一个足够真实的近似人类用户。在这里,我们关注的是在优化对话系统时使用用户模型来生成更多的数据,从而提高示例的复杂性。受Dyna-Q框架的启发(Sutton, 1990),Peng et al.(2018)提出Deep Dyna-Q (DDQ)来处理深度学习模型的大规模问题,直观地说,DDQ允许与人类用户和模拟用户进行交互。DDQ的训练包括三个部分:
(1)直接强化学习:对话系统与真实用户交互,收集真实对话,通过模仿学习或强化学习来改进策略;
(2)环境模型学习:使用直接强化学习收集的真实对话细化环境模型(用户模拟器);
(3)规划:通过强化学习,针对模拟用户改进对话策略。
DDQ的一个挑战是平衡来自真实用户(直接强化学习)和模拟用户(计划)的样本。19年ACL有篇论文在上述模型基础上提出BCS(Budget-Conscious Scheduling)模块根据预算合理分配各部分强化学习。
18年另一篇论文提出受到生成对抗网络启发的Discriminative Deep Dyna-Q(D3Q),它整合了一个经过训练的判别器来区分模拟用户和真实用户的体验。在规划步骤中,根据判别器,只有当模拟经验看起来是真实用户经验时,才使用模拟经验进行策略训练。
- Reward Function Learning
在与用户交互时,对话策略通常被优化为最大化长期回报。因此,奖励功能对于创建高质量的对话系统至关重要。一种可能性是让用户在对话期间或对话结束时提供反馈,以对质量进行评估,但这样的反馈是干扰性的,而且成本高昂。通常,较容易测量的量(如时间流逝)被用来计算奖励函数。但是在实践中,设计一个合适的奖励函数并不总是显而易见的,需要大量的领域知识。目前有的方法:
(1)利用机器学习从数据中学习更好的与用户喜好相关的奖励函数;
(2)领用RNN和CNN来评估对话的成功程度,但是这种方法需要数据标签(dialogue, success-or-not)对,比较难获得;
(3)在与人类用户交互时,同时学习奖励功能和策略;
(4)对话成功只是衡量对话政策质量的一个方面,针对信息搜索任务,作者提出了一种新的基于交互质量的奖励评估器,它平衡了对话策略的多个方面;
(5)将奖励功能视为区分人类产生的对话与对话策略产生的对话的判别器,利用对话学习同时学习判别器和策略。
2.4 自然语言生成(nature language generation)
(待补充)