最新对话系统综述
前言
首先介绍一篇对话系统领域综述最新的paper,写的非常好
2021年南洋理工大学发表的论文: https://arxiv.org/pdf/2105.04387.pdf
第一章:简要介绍对话系统和深度学习。
第二章:讨论现代对话系统中流行的神经模型及其相关工作。
第三章:介绍面向任务对话系统的原理和相关工作,并讨论研究挑战和热门话题。
第四章:介绍开放域对话系统中的热门话题。
第五章:对话系统的主要评估方法。
第六章:常用的数据集
第七章:总结并提供有关研究趋势的一些见解。
同时这里推荐一个英文领域有关对话系统最新消息的平台,其上提供了一些常见模型以及数据集下载等资源
ParlAI: https://parl.ai/about/
由于对话系统领域有很多研究方向,比如大的方面可以分为“面向任务型的对话系统”和“开放领域对话系统”、又比如“开放领域对话系统”又有专门研究带有感情、知识对话特色的系统等等,从模型方面考虑又有检索,生成甚至是检索+生成等。
所以这里大概会分多篇介绍,尽可能的同步当前业界研究的水平和动向~,欢迎关注文末笔者公众号~
作为开胃菜,本次主要介绍一下开放领域end-to-end的一些耳熟能详的模型,说白了就是近两年火过的模型,尤其提一嘴的是目前在中文领域,百度的PLATO应该是效果最好的了,大家可以试玩一下。这里展示一下笔者实验过的一个聊天片段:
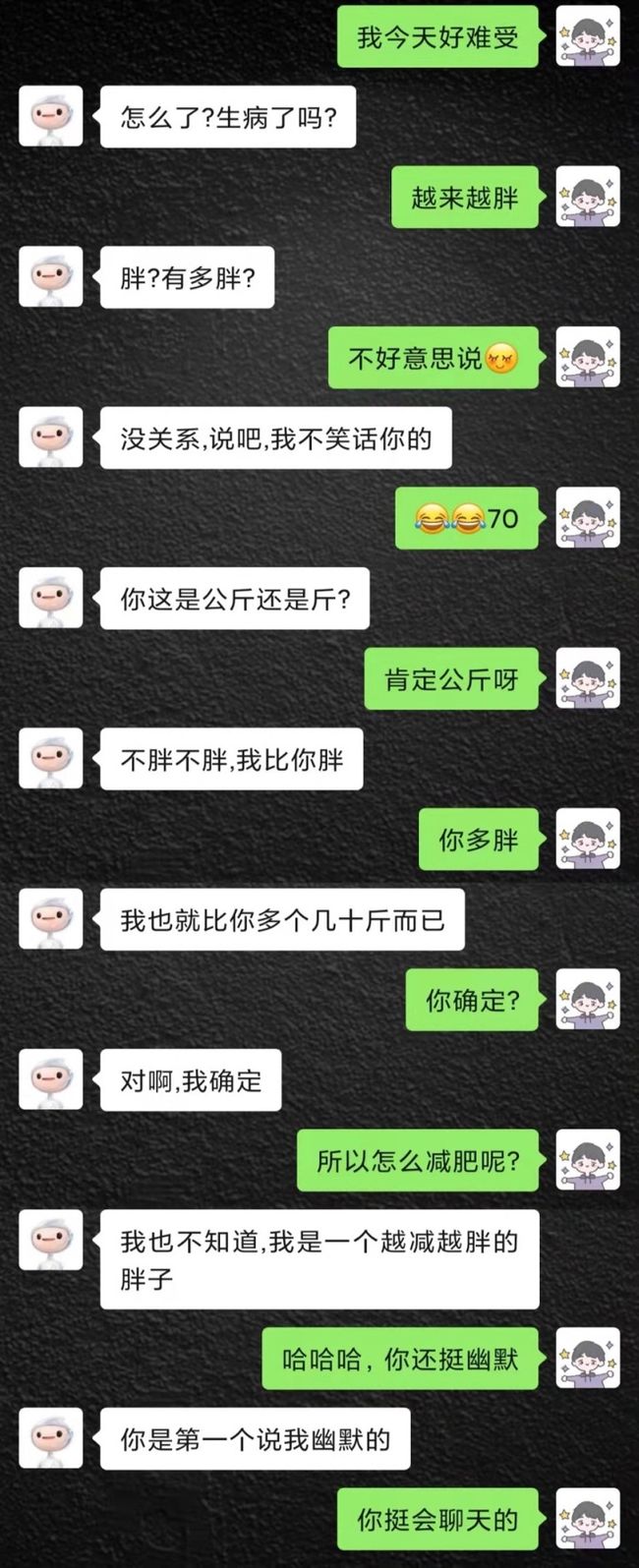
左面为PLATO,右面为笔者
下面涉及总结的图片均来自笔者自己的PPT,为了省时间,直接截图啦。
背景
对话系统一般包括领域内(任务型)对话比如订票,订餐等等和开放领域对话。前者主要是靠识别特定的意图+反复确认来实现,整体来说难度不高,而后者实现起来相对来说较为困难,目前也较为不成熟。
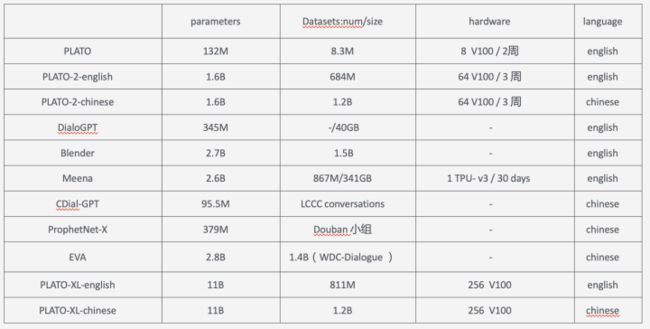
之前一些开发领域对话的解决方案如微软的小冰都是一套很复杂的架构,但是随着最近几年预训练模型取得的成功,对话系统领域也开始探索端到端的实现方式,尤其在2019,2020,2021这三年涌现出了很多相关研究。比如2020年1月份google发表的Meena、4月份Facebook的Blender以及百度PLATO系列包括PLATO、PLATO-2、PLATO-XL等等,前两篇分别发表在ACL2020和ACL-IJCNLP2021,PLATO-XL则是今年9月在arxiv上预印,目前效果比较好的就是百度的PLATO-XL系列。
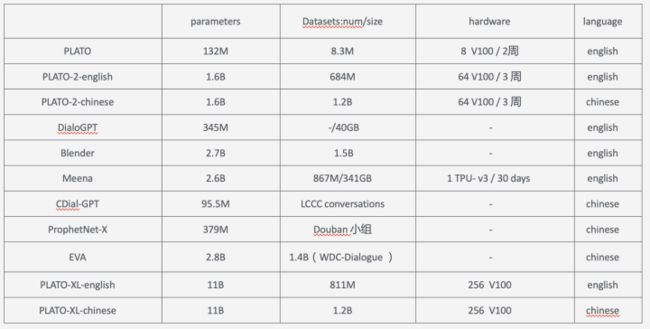
这里做一个简单的总结
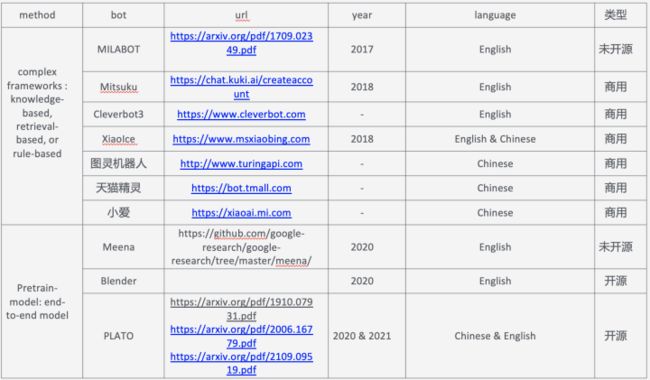
更多的对话Bot可以看二文看懂百度对话系统PLATO系列(上) - 知乎
本文从关注中文领域聊天的角度出发,且目前效果较好的基本上就是百度的PLATO,所以下面介绍paper的时候,PLATO的笔墨会偏多和篇细一点,其它的paper的一些细节,感兴趣可以去看原论文,都已附上链接。
Datasets & Evaluation & Spend
这里主要介绍一下常用的公开数据集和评价方式以及训练这些模型需要的一个资源。
英文公开数据集:
Reddit and Twitter 爬取的数据集

中文公开数据集:
chatterbot,豆瓣多轮,PTT八卦语料,青云语料,电视剧对白语料,贴吧论坛回语料,微博语料,小黄鸡语料

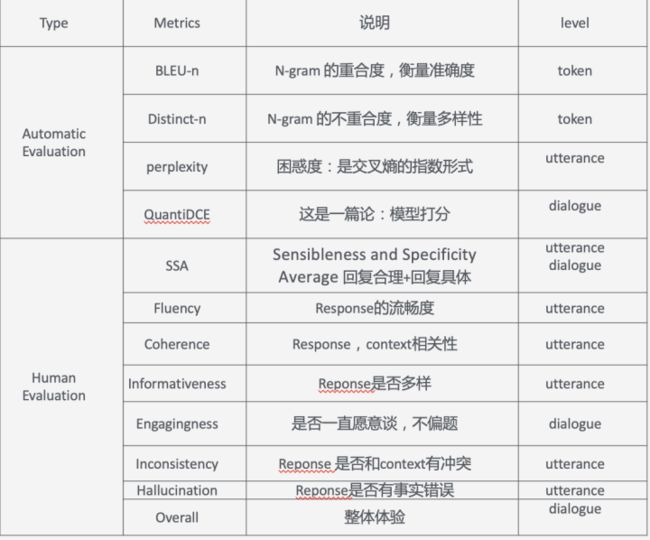
评价方式
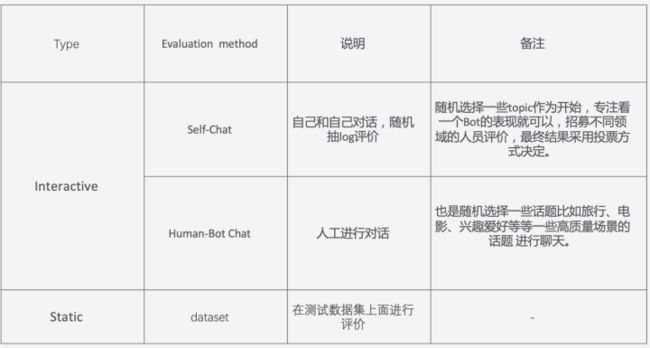
评价的一些指标
训练模型需要的资源
DialoGPT
论文链接:https://arxiv.org/abs/1911.00536
代码:GitHub - microsoft/DialoGPT: Large-scale pretraining for dialogue
项目:https://www.microsoft.com/en-us/research/project/large-scale-pretraining-for-response-generation/
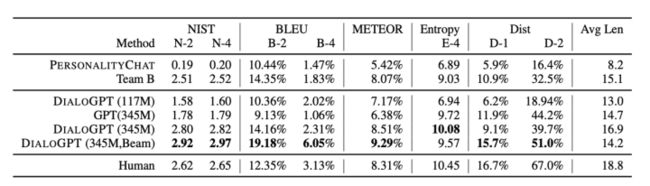
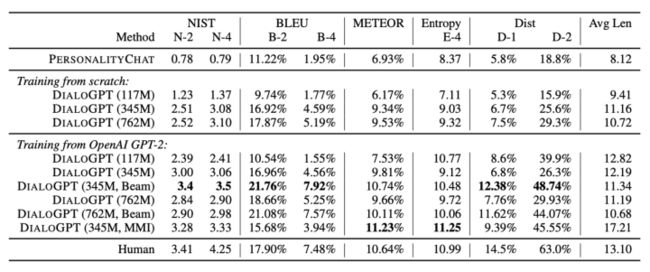
这是微软的一篇paper,也是比较早的一篇探索使用Transformer来做对话的工作,思想比较简单,用的就是GPT-2这一生成模型,只不过语料用的是对话文本进而达到对话生成的目的。
使用的数据集就是DSTC-7和Reddit 。
GPT-2
MMI:后向模型,直观来看,最大化后向模型似然会对所有枯燥的假设施加惩罚,因为频繁的和重复性的假设可能与很多可能的查询有关,因此在任意特定查询下得到的概率会更低。
效果
DSTC
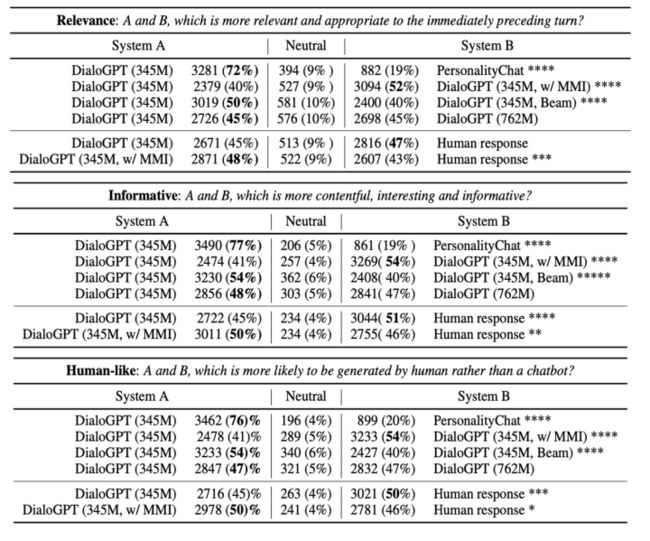

case: Human-Bot Chat

case: Self-chat
Meena
论文链接:https://arxiv.org/pdf/2001.09977.pdf
效果对比:https://github.com/google-research/google-research/tree/master/meena/
这是google提出的,之前闲聊都是基于很复杂的框架,比如基于知识、检索、规则等等,本文主要是想
探索End-to-end的可行性。
主要贡献点就是:
(1) 提出了评估多轮对话效果的指标SSA;
(2) PPL和SSA高度负相关,所以可用PPL自动评估模型效果;
(3) 足够大的端到端模型可以打败复杂架构的对话系统。
Dataset
从Reddit爬取,创建了tree ,任何根节点到叶子结点都说一次对话即(context, response) pair训练样本,最多7 turns。
然后过滤掉一些低质的对话样本,最后获得了867M条训练样本,总计341GB。
Model
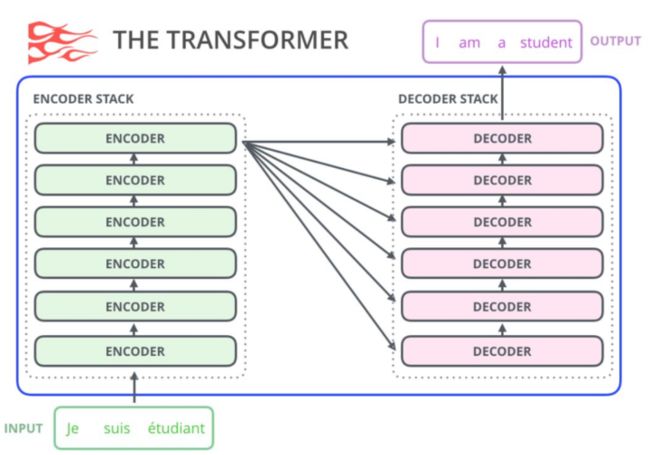
Meena采用的是19年Google通过NAS方法得到的进化版transformer模型Evolved Transformer如下。Meena由1个ET编码器和13个ET解码器构成,ET解码器和标准Transformer解码器的对比如下图所示:
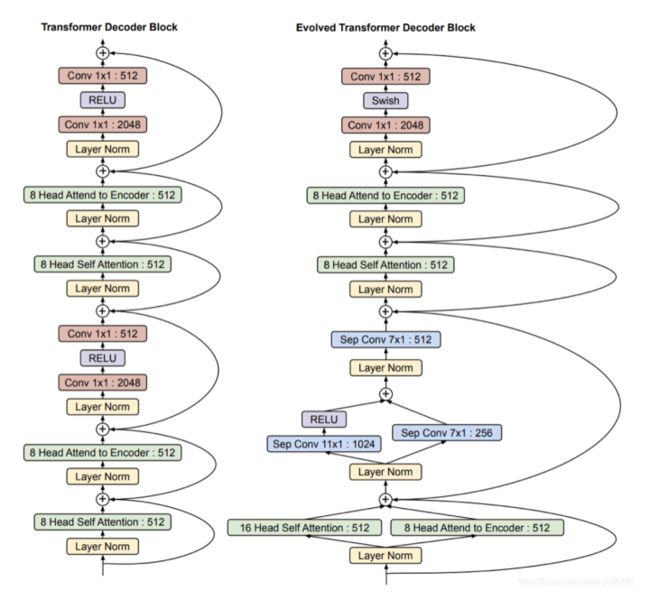
具体的其是2560 hidden size,32 attention heads。
Decoder
没有使用常规的Beam search,而是使用了Sample-and-rank: T越小越倾向于常规词汇,相反倾向使用上下文词汇,比如实体等等。具体公式:
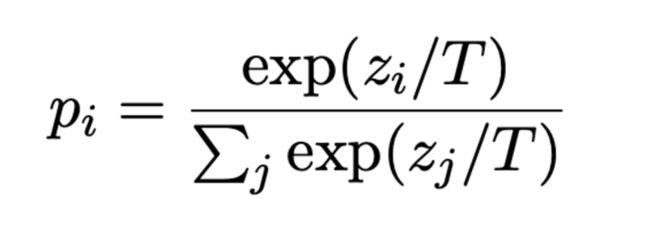
SSA
Sensibleness and Specificity Average
咋一看,这个指标挺朴素的,没啥创新点,但是最近的一些研究表明,那些自动评价的指标结果和人的评价结果
还是有很多gap的,所以这里作者通过SSA明确量化结果,认为这是一个很好的点。
具体的是设置两个问题:
(1)Sensibleness : a response is completely reasonable in context
(2)Specificity : if it is specific to the given context
这里为了说明,作者假设有一个机器人(GenericBot)对所有questions都说“I do not know”,对所有称述都说“ok”,那其实其回答的结果是Sensibleness的,对比DialoGPT , GenericBot70%的回答都是sensible的, 而DialoGPT 才62%,但是DialoGPT其实更像人说话。为了解决这个gap,所以又加了一个Specificity,即回答的要明确。
Evaluation
(1)Static Evaluation
Mini-Turing Benchmark (MTB) :
1477 examples :315 single-turn 、500 two-turn 、662 three-turn
包含了一些 personality questions ?比如:Do you like cats?
(2)Interactive Evaluation
最少进行14 turns ,其中7 turns来着Bot,随机评价100conversations,也就是说最少7 * 100 =700 label的句子。这里会给培训人员说一下,不鼓励其极端对话(知道是和机器人聊,故意会问一下刁钻的问题)
result

Sampling outputs

Beam search outputs
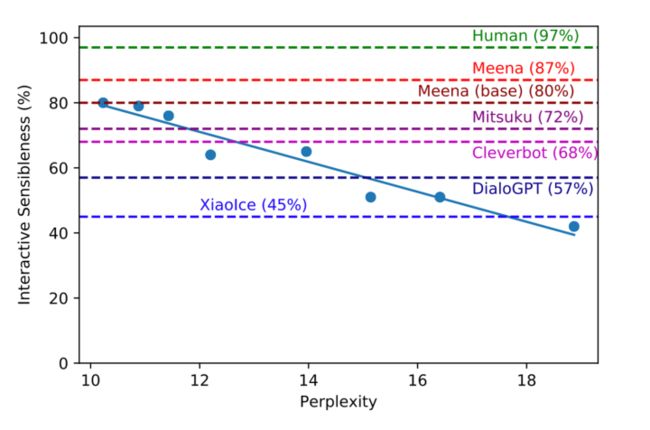
(1)人的评价是具有高的sensibleness,但是低的specificity。
(2)目前而人总体平均是86% Meena总体最好是79%。
(3) PPL和SSA的负相关,进而相比其它静态指标如BLUE,可以利用PPL来更好的作为模型评估指标。
Blender
论文链接:https://arxiv.org/pdf/2004.13637.pdf
代码和模型:https://parl.ai/projects/recipes/
这是facebook提出的,创新没有多少,更像是对之前所有技术的一个汇总实验。
其提出之前的工作证明了数据量+参数量可以提升效果。
(1)但是作者考虑了另外一个方向即不同风格的训练数据其实也是影响对话质量的一个重要因素,其列举了一个高质量的对话大概有的skill是:愿意倾听、知识渊博、同情心等等。
(2) 解码方式
(3) 另外也实验了三种模型:检索、生成、检索+生成
Dataset
BST 这个数据集对话就是包含了上诉说的skill
解码方式
没有采用Meena的Sample方式,而是认为如果合适的调一些 beam search超参结果还是很强的,比如长度:
太短了的回答比较无趣,太长了的回答又比较啰嗦,表现的不愿意倾听。
(1)Minimum length:要求回复长度必须大于设定的值。长度不达标时,强制不产生结束token;
(2) Predictive length:把长度分成四段,例如 < 10, < 20, < 30, 和 > 30 tokens,然后利用四分类模型预测当前回复应该落在哪个长度段。模型使用的依旧是 poly-encoder。
(3) 屏蔽重复的子序列(Subsequence Blocking):不允许产生当前句子和前面对话(context)
中已经存在的 3-grams。
框架
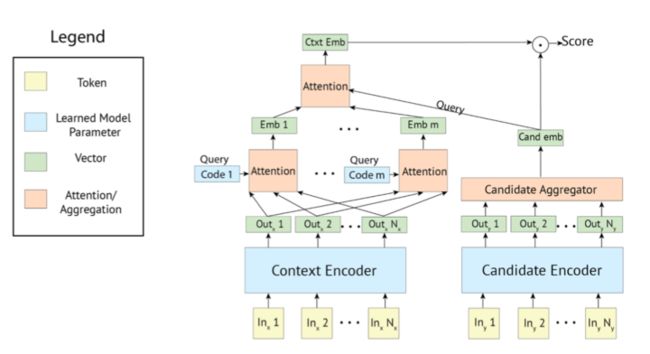
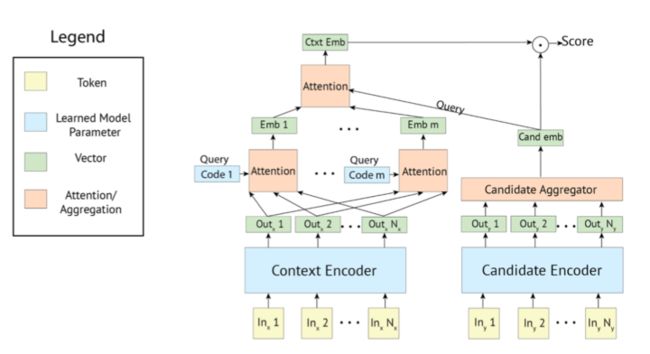
(1)Retriever
双塔结构:Poly-encoders。
极端情况下整个training set就是candidate set
(2)Generator
Seq2seq(Transformer): Unlikelihood Loss: 容易组合成常见n-grams的tokens, 如
果一个token组成的n-grams比真实答案中n-grams比例高
(3)Retrieve and Refine
先retriever 再 generate
Retrieval : Dialogue & Knowledge
其中Knowledge 可以用 TF-IDF-based
在Refine训练阶段,部分用gold reponse
Pretrain
在Reddit 数据集上面训练
Fine-tuning
ConvAI2 : personality & engaging
Empathetic Dialogues : empathy
Wizard of Wikipedia : knowledge
Blended Skill Talk : blending these skills
总体流程就是:Reddit -> (ConvAI2, Empathetic Dialogues, Wizard of Wikipedia ) -> Blended Skill Talk
ConvAI2,Empathetic Dialogues,Wizard of Wikipedia是各个谈话技巧的数据。
实验结果
这里就贴一个case吧,更多对比实验,大家感兴趣可以去看看paper

作者也说了目前其实模型还是不够好,有很多缺点比如被深入质询后就不行了,缺乏知识回答不上来,倾向于
使用简单的语言,并且有用重复短语的倾向。对此目前还没有一个解决的定论,只是展开的讨论了一下。比如考虑使用retrieve-and-refine 。
PLATO
论文链接:https://arxiv.org/pdf/1910.07931.pdf
代码链接:Research/NLP/Dialogue-PLATO at master · PaddlePaddle/Research · GitHub
这是百度PLATO系列的开山之作,之前很多工作证明了直接使用 bert 在对话语料上进行finetune效果不太好,可能的原因就是:
(1)数据分布的gap: 对话领域和通用领域的潜在语义存在gap
(2) 模型的差异:单向生成和双向bert
(3) 多样性:一对多,对待同一句话不应该每次只回答同一句respons
针对上诉问题,解决方法:
(1)使用Reddit and Twitter 数据集
(2) 采用unified language modeling :unified transformer
(3) 提出latent speech act
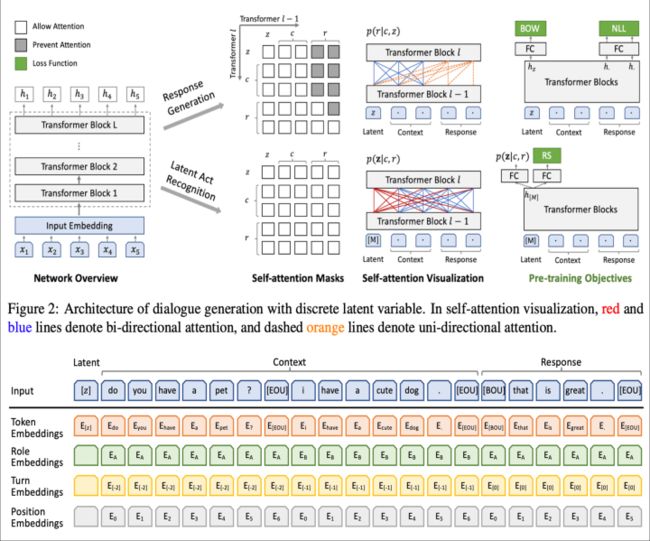
其中最大的看点就是(3),作者希望通过隐变量来表征不同的说话风格进而生成多样的回答。
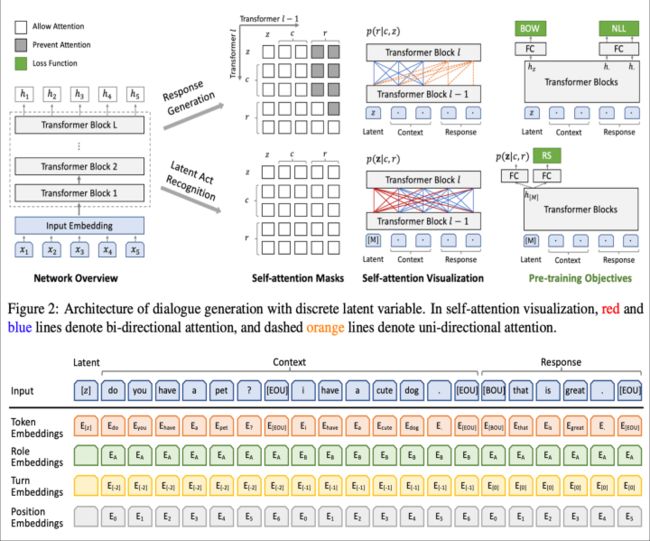
[z]就是上文说的latent speech act ,注意一点的就是[z] 的 role, turn, position 都是空。
对于问答类型的话c就是背景知识,对于聊天就是之前的聊天。
那么不禁要问[z]是怎么学习呢?这里很简单,采用的是负采用方法,即通过构造(context,response) pair来训练,具体的使用随机采样response来作为context的负样本pair,总的来说就是一个二分类任务。
所以训练目标就是两大类:
Response Generation : NLL、BOW
Response Selection :RS
其中NLL和BOW没什么说的,就是常见的两个生成类loss,具体如下:
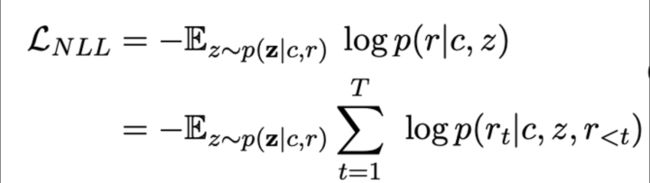
NLL
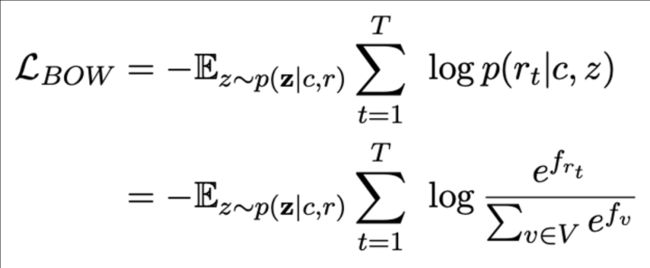
BOW:不关注词的顺序,关注全局信息
RS就是我们上面说的二分类
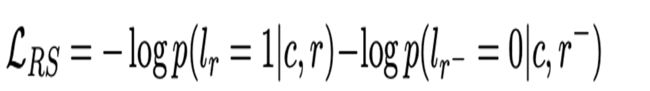
所以最后的总loss就是上述三者相加:
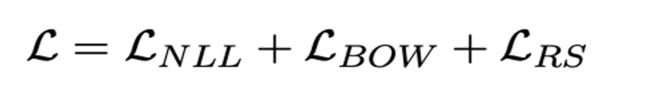
这里为了更好的说明上述训练过程,我们实际去看一下其代码(c:context,r:response):
每个pair(c, r)过两次模型,第一次计算得到RS,第二次计算得到NLL和BOW,然后相加loss更新网络。
其实总共一个样本要过三次预训练模型!!!
Fine-tuning and Inference :
从k个里面选取一个score 最大的latent value 作为最后的输出 。
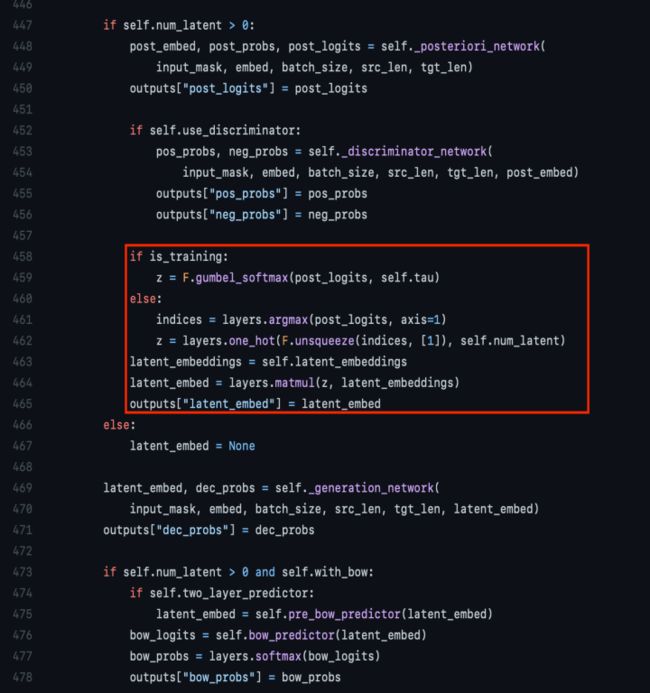
代码说明:
b: batch k : num latent h: hidden size
447-450和452-456行其实为了计算RS,注意这里是过了两次模型,batch内抽负样本。
458-465行就是核心代码,这里z是[b, k],self.latent_embeddings是[k,h]所以最后的464行是 [b,h]即【M】这个隐变量的表征。
只不过训练的时候是z是一个关于k的概率分布,而infer的时候是一个max 的one-hot,实际中k=20
实验结果

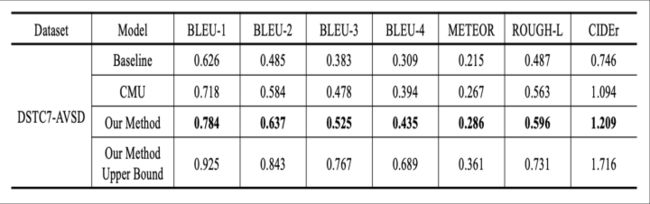
(1)在DSTC7-AVSD最下面的一行是给出了模型的上限,即假设所产生的k个response中最好的那个100% score最高即被选中。说明select部分还有很多可做空间。
(2) Seq2Seq是RNN的一种网络,LIC是一种基于transformer的网络。没有哪种结果在所有数据集和指标上都获得压倒性的胜利。
(3)Transformer的网络还是要好于RNN的,起码在human Evaluation上面上。
case analysis:

每个context 选了5个候选的response,附录中进一步展示了persona-chat、Daily Dialog和DSTC7-AVSD三个数据集场景下多个模型的输出case,感兴趣的可以看paper。
消融实验
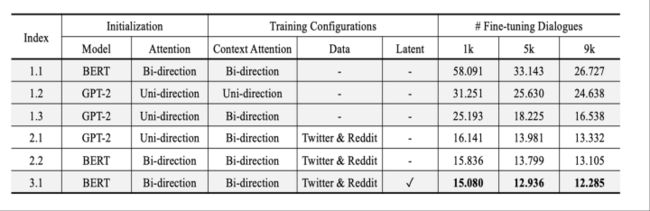
在persona-chat数据集上面做的,指标是perplexity。
1系列是直接finetune;2系列是先在Reddit and Twitter数据集上面预训练一把;3是使用了latent
从1.2和1.3可以看到双向context的要好
从2系列和1系列对比来看,使用了对话数据预训练是要好于普通文本
3.1和2.2的相比,证明了latent的有效性。
PLATO-2
论文链接:https://arxiv.org/pdf/2006.16779.pdf
代码链接:https://github.com/PaddlePaddle/Knover/tree/develop/projects/PLATO-2
这是PLATO系列的第二篇,DialoGPT ,Meena,Blender 都是使用了更大的数据量,更大的模型进行训练,为此PLATO就想也上一下数据量和参数量。
但是一个问题就是,直接训练遇到训练不稳定和效率问题。作者猜测原因可能是让模型一上来就学习one-to-many挺难。于是想到了从简到难的学习过程即本文提到的curriculum learning。
总的来说相比于PLATO,PLATO-2 在框架上基本上没有太多改动,主要就是使用了一种多阶段训练方式扩大了数据量和模型参数量。
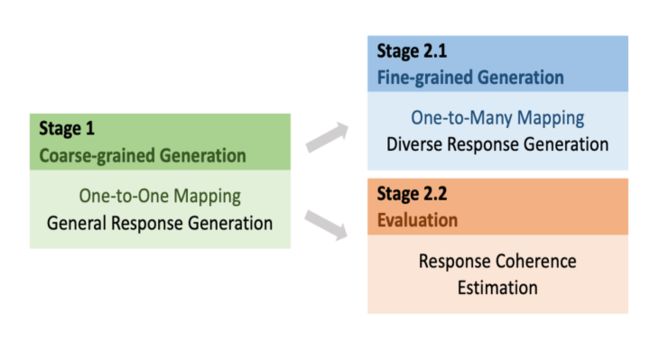
curriculum learning
这次同时训练了英文和中文,不过遵循了一贯的风格,哈哈,只开源了英文。
本文介绍的训练方式叫做curriculum learning 课程学习,即分阶段训练
第一阶段是one-to-one
第二阶段是one-to-many
具体来说其实是三个阶段
Coarse-grained : 粗粒度的学习,单纯的one-to-one生成模型,学一些通用性的response,缺乏多样性。
Fine-grained: 使用latent进行学习diverse response generation
Evaluation: 学习score (还记得 PLATO中的上限吗?估计在这里思考了下) 即response coherence
之所以分开训练,是决定多任务会影响,具体可以看
http://proceedings.mlr.press/v119/standley20a.html
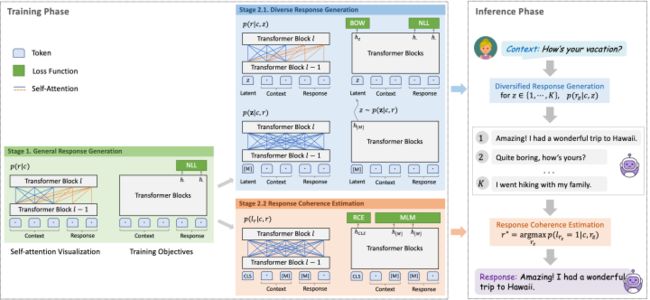
Coarse-grained: NLL
Fine-grained: NLL & BOW
Evaluation : RCE & MLM
RCE: 就是PLATO中的RS
训练了多个版本,大概可以总结如下
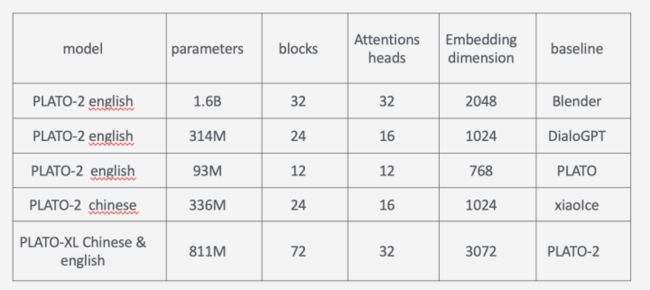
实验结果
英文 Self-Chat
中文 Human-Bot Chat
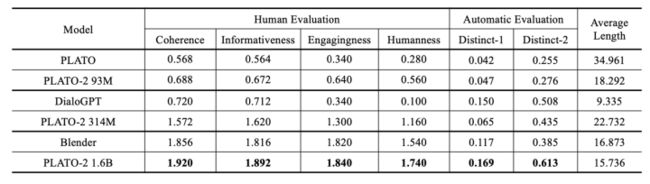
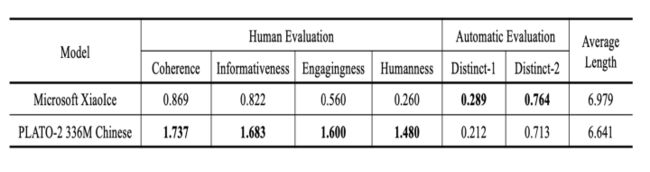
一些数据集上Static评价
Case 分析

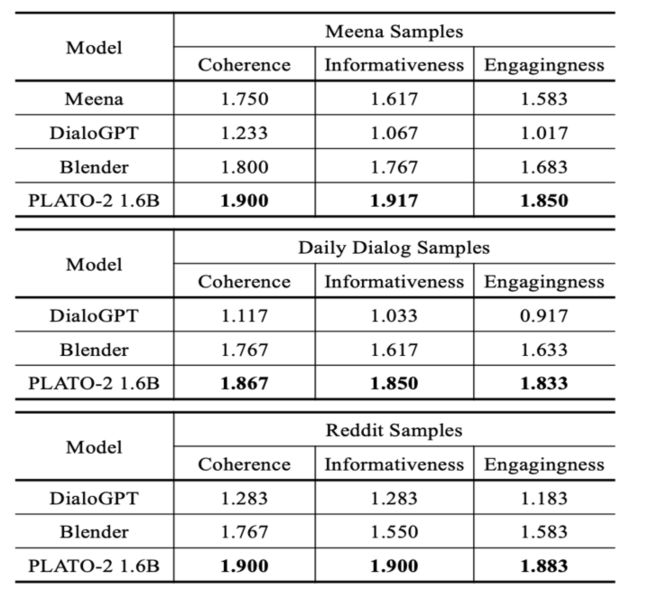
两者都很好,Blender和plato-2都是比较高质量的聊天,但是前者偏向于频繁换话题,后者偏向于深层面的聊天。原因可能是Blender使用的训练数据BST就是这种风格,plato-2就是因为有隐变量产生丰富的response并且有select的过程,选出一个更好的深层次的response,这里也做了一个实验,就是看深层次对话对比,发现确实PLATO-2更好。
同时在比赛DSTC9 ,三个任务:
一个是交互的任务Track3-task2 、一个静态的知识聊天Track3-task1 、一个专业领域的对话Track2-task1都取得了第一。
PLATO–XL
论文链接:https://arxiv.org/pdf/2109.09519.pdf
代码链接:https://github.com/PaddlePaddle/Knover/tree/develop/projects/PLATO-XL
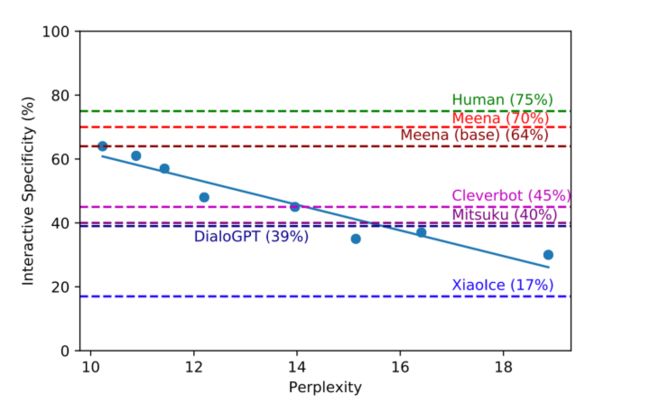
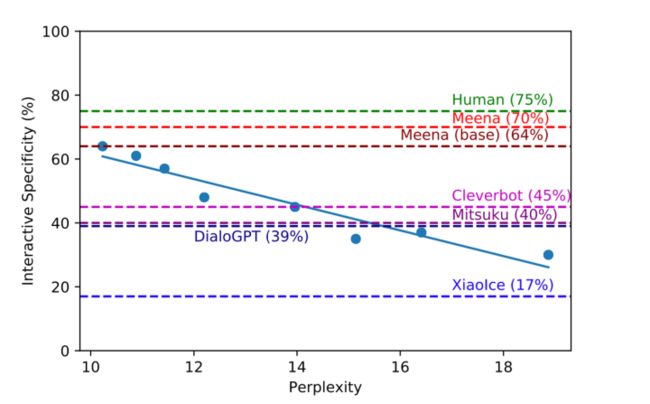
这是第三篇,也是最新的一篇,也是开头展示测试效果的对应模型。其背景是在对话生成领域,目前没有一个关于模型大小和对话质量的明确的结论。如下图

最好的模型却不是最大的模型。
本文就是试图探索:
在适当的设计好预训练框架的前提下,恐怕对话质量还是会继续收益于大模型。
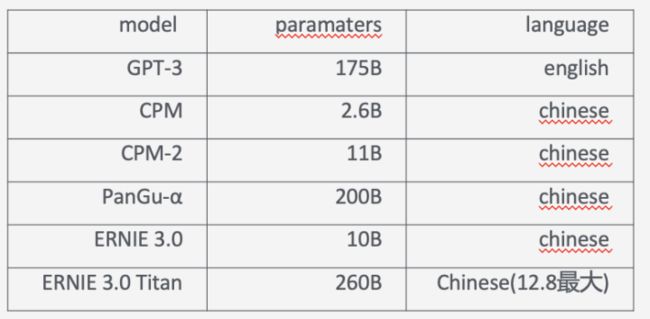
从上面可以看出一些大的趋势是:模型越来越大。
PLATO有一个基本假设就是只出现两个角色并且交替对话,这个人工标注的对话数据集大概率符合,但是在社交媒体的对话中就变得复杂了。

框架

主要就是强调了这里的Role编码多个角色,框架等都没变,甚至loss只使用了一个NLL这一个。
小插曲:至于为什么没用其它的花里胡俏的loss,作者也是提都没提,个人猜测:
(1)本文重点就是探索上数据和参数量能否带来效果,在绝对量面 前,这些trick 都不用上就可以碾压之前的效果。
(2) 另外就是猜测可能是之前的方式太费时间了,一个样本要过好多次模型。本来现在模型就大,耗费时间。
所以paper没有过多的在loss 上面下功夫,主要目的就是上模型参数量+数据量,所以重点关注 computation and parameter efficiency :
(1) 使用unified transformer ,相比于encoder-decoder 这种网络,共享了参数。
(2) 另外一个是训练的时候batch使用尽可能一样长的样本可以达到即BlockShuffle。
(3) data parallelism & gradient checkpointing
实验结果
由于自动评估的结果和人为评估的结果一致性相差还是比较远,所以本篇主要采用了人工评价方式。
和其它一些大模型比较:
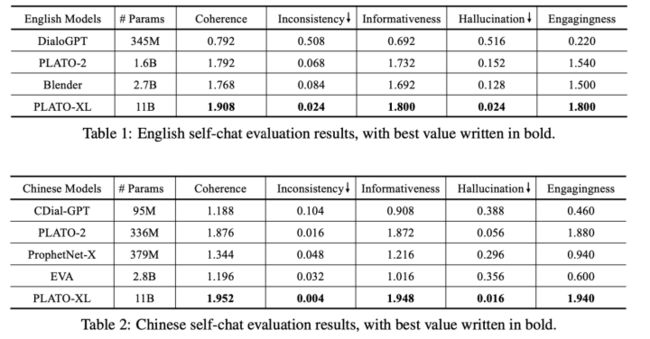
Self-Chat
和一些商业机器人比较
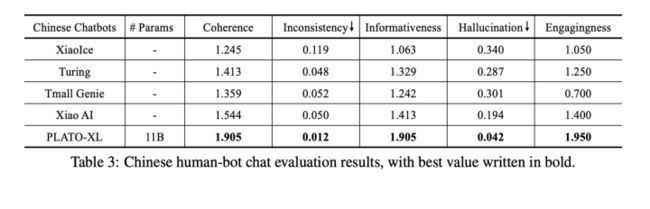
Human-Bot
Case

Self-chat
(1)对核能和马里亚纳海沟的讨论说明其包含了一些知识。
(2)左边的对话可以体现角色,P2担任了小白提问者,一直提问,P1担任了expert,耐心讲解。

Human-chat
能够利用一些诗词以及给出理由
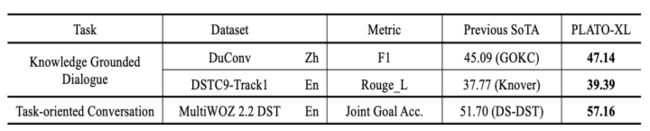
knowledge grounded dialogue, and task-oriented conversation
总结
(1) 预训练模型,单纯要想效果上数据量上参数量,猛训就完事了,相比花里胡俏的trick ,数据量和大模型更能带来大的甚至是质的提升,相对来说简单粗暴。
(2) 目前的一个训练样本都是深度遍历对话tree,是否可以进一步考虑宽度遍历,使得其学到大家讨论这一层面信息?
(3) 在闲聊领域端到端的这种大模型应该是个趋势。
(4)关于open-domain领域,对话技巧的研究目前是个热门,已经有部分工作进行了探索,大部分涌现的paper时间都在最近2年即2019年开始,但是在中文领域目前还没有很多工作,目前高质量、深度聊天这块还有很大提升空间。
彩蛋
机器之所以还不能代替人进行聊天,或者说聊一会人还是能感觉其是一个机器,本质上是什么原因呢?
其没有感情,冷冰冰?不理解你?不会主动分享事情等等?业界其实也注意到这个事情了,也针对性的进行了相关的研究,比如研究的领域分为:
Context Awareness :怎么用好历史上下文?
Response Coherence :回复的连贯性。
Response Diversity :回复的多样性。
Personality-based Response :有必要意识到自己的角色,并基于固定的角色做出回应。
Empathetic Response :富有同情心。
Conversation Topic :识别出想聊的主题,能主动切换相关话题促进聊天。
Knowledge-Grounded System :包含知识,知识渊博,能够给出正向引导。
Interactive Training :交互式训练, 不需要很完善,边聊边学。
由于篇幅有限,下次我们将重点分析有关研究上述聊天技巧的文章~
关注
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubMryangkaitong has 12 repositories available. Follow their code on GitHub. https://github.com/Mryangkaitong
https://github.com/Mryangkaitong
知乎:
小小梦想 - 知乎 https://www.zhihu.com/people/sa-tuo-de-yisheng/posts
https://www.zhihu.com/people/sa-tuo-de-yisheng/posts
首先介绍一篇对话系统领域综述最新的paper,写的非常好
2021年南洋理工大学发表的论文: https://arxiv.org/pdf/2105.04387.pdf
第一章:简要介绍对话系统和深度学习。
第二章:讨论现代对话系统中流行的神经模型及其相关工作。
第三章:介绍面向任务对话系统的原理和相关工作,并讨论研究挑战和热门话题。
第四章:介绍开放域对话系统中的热门话题。
第五章:对话系统的主要评估方法。
第六章:常用的数据集
第七章:总结并提供有关研究趋势的一些见解。
同时这里推荐一个英文领域有关对话系统最新消息的平台,其上提供了一些常见模型以及数据集下载等资源
ParlAI: https://parl.ai/about/
由于对话系统领域有很多研究方向,比如大的方面可以分为“面向任务型的对话系统”和“开放领域对话系统”、又比如“开放领域对话系统”又有专门研究带有感情、知识对话特色的系统等等,从模型方面考虑又有检索,生成甚至是检索+生成等。
所以这里大概会分多篇介绍,尽可能的同步当前业界研究的水平和动向~,欢迎文末关注笔者公众号~
作为开胃菜,本次主要介绍一下开放领域end-to-end的一些耳熟能详的模型,说白了就是近两年火过的模型,尤其提一嘴的是目前在中文领域,百度的PLATO应该是效果最好的了,大家可以试玩一下。这里展示一下笔者实验过的一个聊天片段:

左面为PLATO,右面为笔者
下面涉及总结的图片均来自笔者自己的PPT,为了省时间,直接截图啦。
背景
对话系统一般包括领域内(任务型)对话比如订票,订餐等等和开放领域对话。前者主要是靠识别特定的意图+反复确认来实现,整体来说难度不高,而后者实现起来相对来说较为困难,目前也较为不成熟。
之前一些开发领域对话的解决方案如微软的小冰都是一套很复杂的架构,但是随着最近几年预训练模型取得的成功,对话系统领域也开始探索端到端的实现方式,尤其在2019,2020,2021这三年涌现出了很多相关研究。比如2020年1月份google发表的Meena、4月份Facebook的Blender以及百度PLATO系列包括PLATO、PLATO-2、PLATO-XL等等,前两篇分别发表在ACL2020和ACL-IJCNLP2021,PLATO-XL则是今年9月在arxiv上预印,目前效果比较好的就是百度的PLATO-XL系列。
这里做一个简单的总结
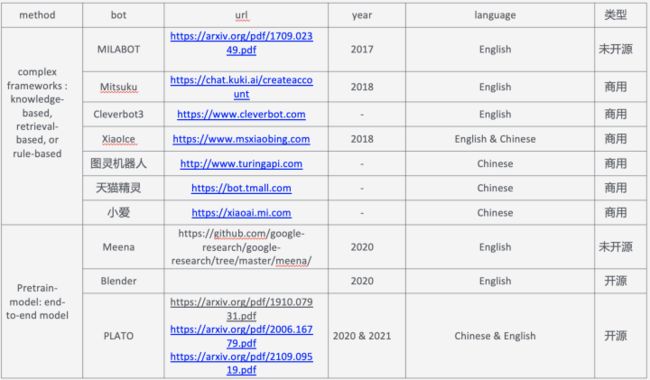
更多的对话Bot可以看二文看懂百度对话系统PLATO系列(上) - 知乎
本文从关注中文领域聊天的角度出发,且目前效果较好的基本上就是百度的PLATO,所以下面介绍paper的时候,PLATO的笔墨会偏多和篇细一点,其它的paper的一些细节,感兴趣可以去看原论文,都已附上链接。
Datasets & Evaluation & Spend
这里主要介绍一下常用的公开数据集和评价方式以及训练这些模型需要的一个资源。
英文公开数据集:
Reddit and Twitter 爬取的数据集

中文公开数据集:
chatterbot,豆瓣多轮,PTT八卦语料,青云语料,电视剧对白语料,贴吧论坛回语料,微博语料,小黄鸡语料
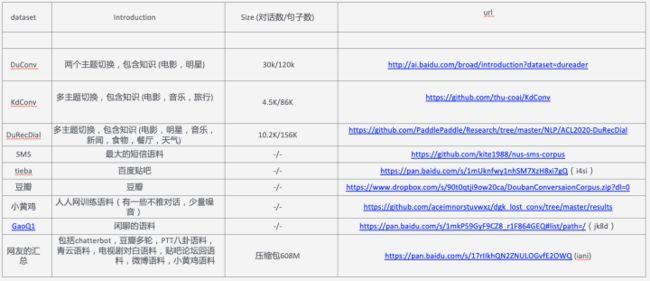
评价方式
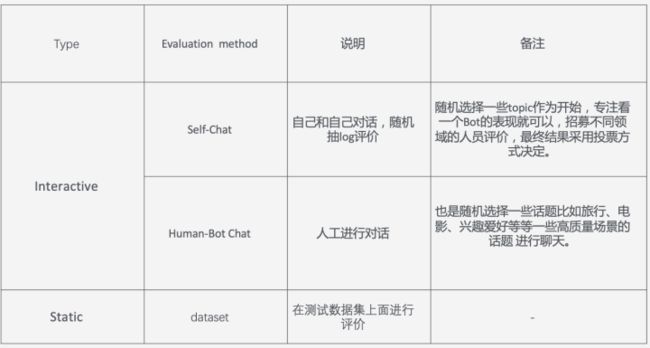
评价的一些指标
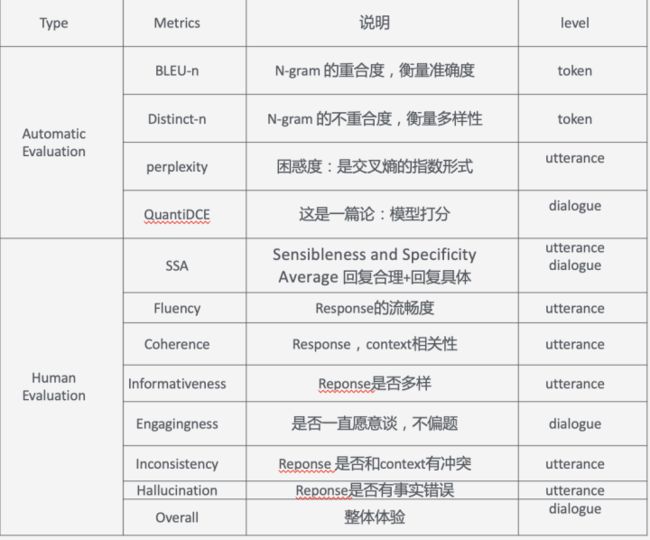
训练模型需要的资源
DialoGPT
论文链接:https://arxiv.org/abs/1911.00536
代码:https://github.com/microsoft/DialoGPT
项目:https://www.microsoft.com/en-us/research/project/large-scale-pretraining-for-response-generation/
这是微软的一篇paper,也是比较早的一篇探索使用Transformer来做对话的工作,思想比较简单,用的就是GPT-2这一生成模型,只不过语料用的是对话文本进而达到对话生成的目的。
使用的数据集就是DSTC-7和Reddit 。
GPT-2
MMI:后向模型,直观来看,最大化后向模型似然会对所有枯燥的假设施加惩罚,因为频繁的和重复性的假设可能与很多可能的查询有关,因此在任意特定查询下得到的概率会更低。
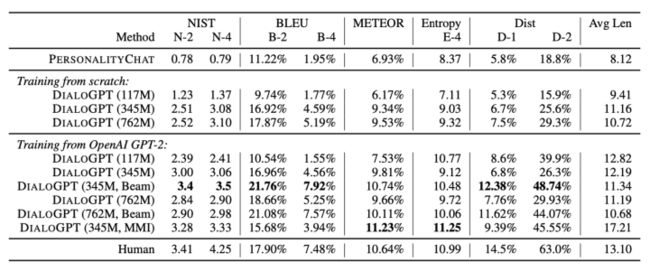
效果
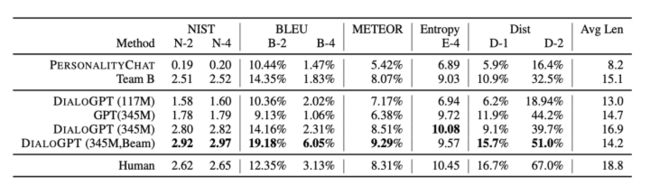
DSTC
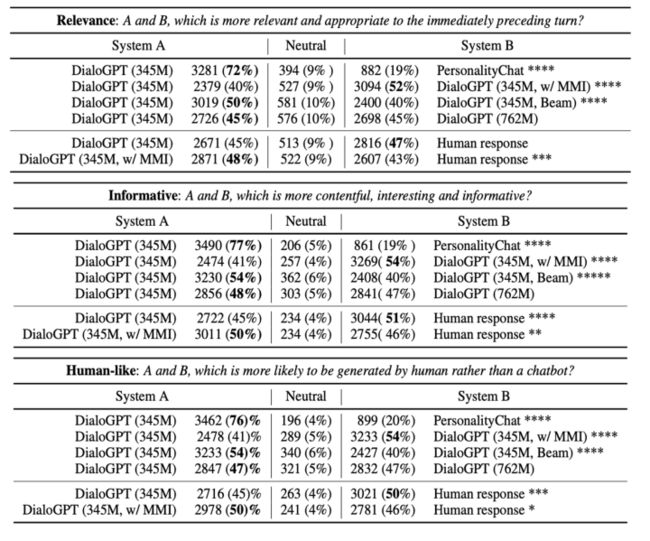

case: Human-Bot Chat

case: Self-chat
Meena
论文链接:https://arxiv.org/pdf/2001.09977.pdf
效果对比:https://github.com/google-research/google-research/tree/master/meena/
这是google提出的,之前闲聊都是基于很复杂的框架,比如基于知识、检索、规则等等,本文主要是想
探索End-to-end的可行性。
主要贡献点就是:
(1) 提出了评估多轮对话效果的指标SSA;
(2) PPL和SSA高度负相关,所以可用PPL自动评估模型效果;
(3) 足够大的端到端模型可以打败复杂架构的对话系统。
Dataset
从Reddit爬取,创建了tree ,任何根节点到叶子结点都说一次对话即(context, response) pair训练样本,最多7 turns。
然后过滤掉一些低质的对话样本,最后获得了867M条训练样本,总计341GB。
Model
Meena采用的是19年Google通过NAS方法得到的进化版transformer模型Evolved Transformer如下。Meena由1个ET编码器和13个ET解码器构成,ET解码器和标准Transformer解码器的对比如下图所示:
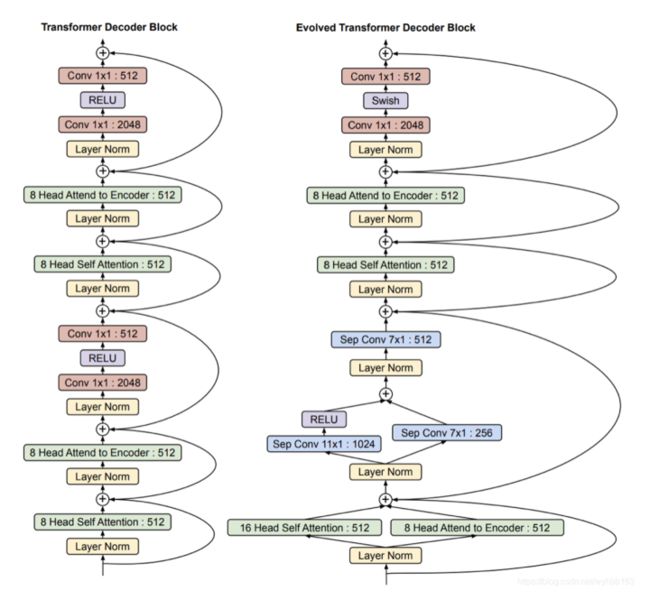
具体的其是2560 hidden size,32 attention headsDecoder
没有使用常规的Beam search,而是使用了Sample-and-rank: T越小越倾向于常规词汇,相反倾向使用上下文词汇,比如实体等等。具体公式:
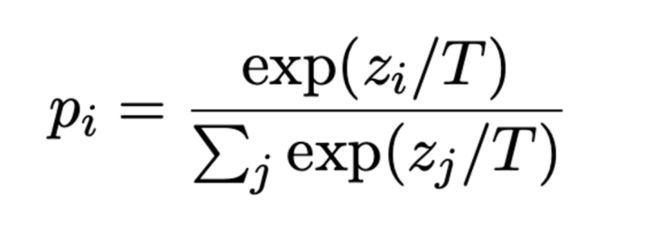
SSA
Sensibleness and Specificity Average
咋一看,这个指标挺朴素的,没啥创新点,但是最近的一些研究表明,那些自动评价的指标结果和人的评价结果
还是有很多gap的,所以这里作者通过SSA明确量化结果,认为这是一个很好的点。
具体的是设置两个问题:
(1)Sensibleness : a response is completely reasonable in context
(2)Specificity : if it is specific to the given context
这里为了说明,作者假设有一个机器人(GenericBot)对所有questions都说“I do not know”,对所有称述都说“ok”,那其实其回答的结果是Sensibleness的,对比DialoGPT , GenericBot70%的回答都是sensible的, 而DialoGPT 才62%,但是DialoGPT其实更像人说话。为了解决这个gap,所以又加了一个Specificity,即回答的要明确。
Evaluation
(1)Static Evaluation
Mini-Turing Benchmark (MTB) :
1477 examples :315 single-turn 、500 two-turn 、662 three-turn
包含了一些 personality questions ?比如:Do you like cats?
(2)Interactive Evaluation
最少进行14 turns ,其中7 turns来着Bot,随机评价100conversations,也就是说最少7 * 100 =700 label的句子。这里会给培训人员说一下,不鼓励其极端对话(知道是和机器人聊,故意会问一下刁钻的问题)
result

Sampling outputs

Beam search outputs
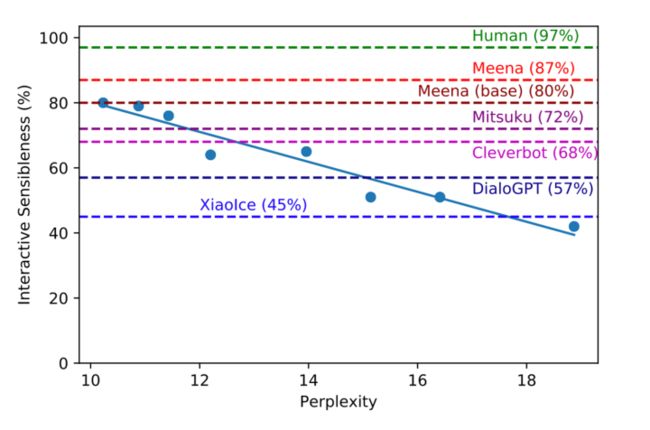
(1)人的评价是具有高的sensibleness,但是低的specificity。
(2)目前而人总体平均是86% Meena总体最好是79%。
(3) PPL和SSA的负相关,进而相比其它静态指标如BLUE,可以利用PPL来更好的作为模型评估指标。
Blender
论文链接:https://arxiv.org/pdf/2004.13637.pdf
代码和模型:https://parl.ai/projects/recipes/
这是facebook提出的,创新没有多少,更像是对之前所有技术的一个汇总实验。
其提出之前的工作证明了数据量+参数量可以提升效果。
(1)但是作者考虑了另外一个方向即不同风格的训练数据其实也是影响对话质量的一个重要因素,其列举了一个高质量的对话大概有的skill是:愿意倾听、知识渊博、同情心等等。
(2) 解码方式
(3) 另外也实验了三种模型:检索、生成、检索+生成
Dataset
BST 这个数据集对话就是包含了上诉说的skill
解码方式
没有采用Meena的Sample方式,而是认为如果合适的调一些 beam search超参结果还是很强的,比如长度:
太短了的回答比较无趣,太长了的回答又比较啰嗦,表现的不愿意倾听。
(1)Minimum length:要求回复长度必须大于设定的值。长度不达标时,强制不产生结束token;
(2) Predictive length:把长度分成四段,例如 < 10, < 20, < 30, 和 > 30 tokens,然后利用四分类模型预测当前回复应该落在哪个长度段。模型使用的依旧是 poly-encoder。
(3) 屏蔽重复的子序列(Subsequence Blocking):不允许产生当前句子和前面对话(context)
中已经存在的 3-grams。
框架
(1)Retriever
双塔结构:Poly-encoders。
极端情况下整个training set就是candidate set
(2)Generator
Seq2seq(Transformer): Unlikelihood Loss: 容易组合成常见n-grams的tokens, 如
果一个token组成的n-grams比真实答案中n-grams比例高
(3)Retrieve and Refine
先retriever 再 generate
Retrieval : Dialogue & Knowledge
其中Knowledge 可以用 TF-IDF-based
在Refine训练阶段,部分用gold reponse
Pretrain
在Reddit 数据集上面训练
Fine-tuning
ConvAI2 : personality & engaging
Empathetic Dialogues : empathy
Wizard of Wikipedia : knowledge
Blended Skill Talk : blending these skills
总体流程就是:Reddit -> (ConvAI2, Empathetic Dialogues, Wizard of Wikipedia ) -> Blended Skill Talk
ConvAI2,Empathetic Dialogues,Wizard of Wikipedia是各个谈话技巧的数据。
实验结果
这里就贴一个case吧,更多对比实验,大家感兴趣可以去看看paper

作者也说了目前其实模型还是不够好,有很多缺点比如被深入质询后就不行了,缺乏知识回答不上来,倾向于
使用简单的语言,并且有用重复短语的倾向。对此目前还没有一个解决的定论,只是展开的讨论了一下。比如考虑使用retrieve-and-refine 。
PLATO
论文链接:https://arxiv.org/pdf/1910.07931.pdf
代码链接:Research/NLP/Dialogue-PLATO at master · PaddlePaddle/Research · GitHub
这是百度PLATO系列的开山之作,之前很多工作证明了直接使用 bert 在对话语料上进行finetune效果不太好,可能的原因就是:
(1)数据分布的gap: 对话领域和通用领域的潜在语义存在gap
(2) 模型的差异:单向生成和双向bert
(3) 多样性:一对多,对待同一句话不应该每次只回答同一句respons
针对上诉问题,解决方法:
(1)使用Reddit and Twitter 数据集
(2) 采用unified language modeling :unified transformer
(3) 提出latent speech act
其中最大的看点就是(3),作者希望通过隐变量来表征不同的说话风格进而生成多样的回答。
[z]就是上文说的latent speech act ,注意一点的就是[z] 的 role, turn, position 都是空。
对于问答类型的话c就是背景知识,对于聊天就是之前的聊天。
那么不禁要问[z]是怎么学习呢?这里很简单,采用的是负采用方法,即通过构造(context,response) pair来训练,具体的使用随机采样response来作为context的负样本pair,总的来说就是一个二分类任务。
所以训练目标就是两大类:
Response Generation : NLL、BOW
Response Selection :RS
其中NLL和BOW没什么说的,就是常见的两个生成类loss,具体如下:
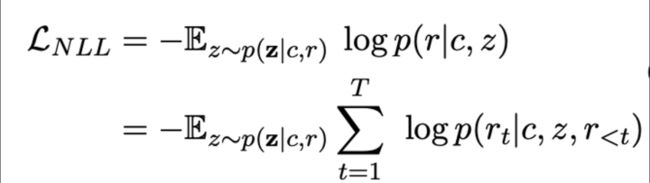
NLL
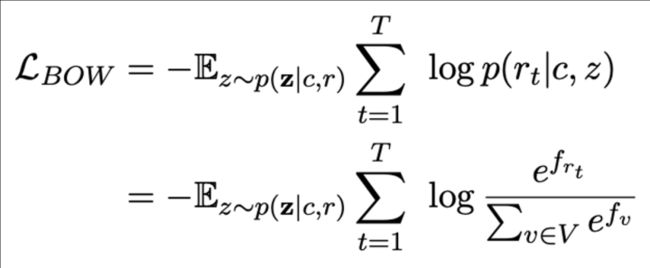
BOW:不关注词的顺序,关注全局信息
RS就是我们上面说的二分类
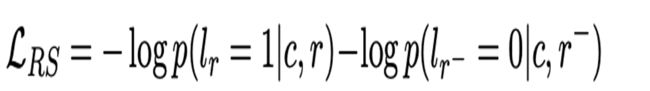
所以最后的总loss就是上述三者相加:
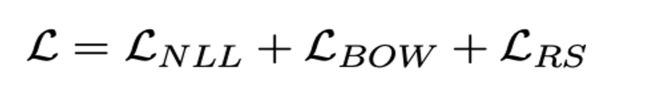
这里为了更好的说明上述训练过程,我们实际去看一下其代码(c:context,r:response):
每个pair(c, r)过两次模型,第一次计算得到RS,第二次计算得到NLL和BOW,然后相加loss更新网络。
其实总共一个样本要过三次预训练模型!!!
Fine-tuning and Inference :
从k个里面选取一个score 最大的latent value 作为最后的输出 。
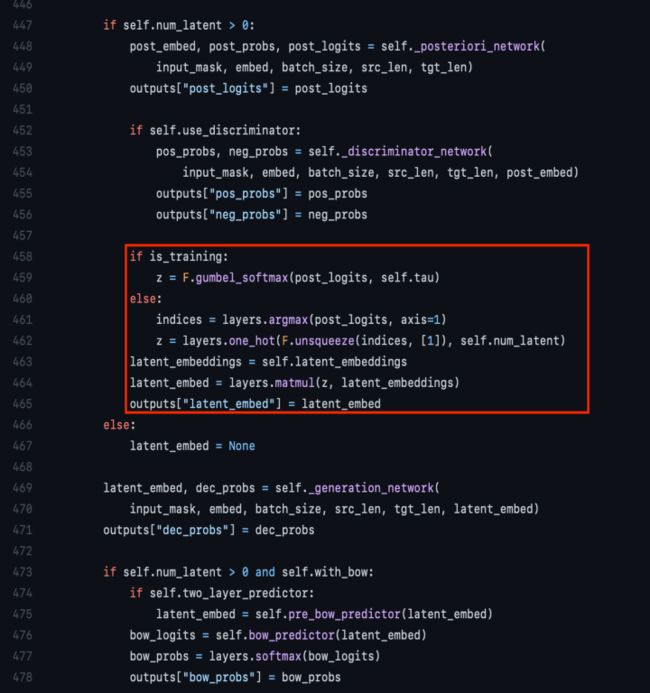
代码说明:
b: batch k : num latent h: hidden size
447-450和452-456行其实为了计算RS,注意这里是过了两次模型,batch内抽负样本。
458-465行就是核心代码,这里z是[b, k],self.latent_embeddings是[k,h]所以最后的464行是 [b,h]即【M】这个隐变量的表征。
只不过训练的时候是z是一个关于k的概率分布,而infer的时候是一个max 的one-hot,实际中k=20
实验结果
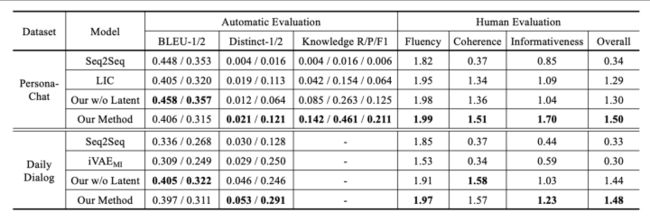
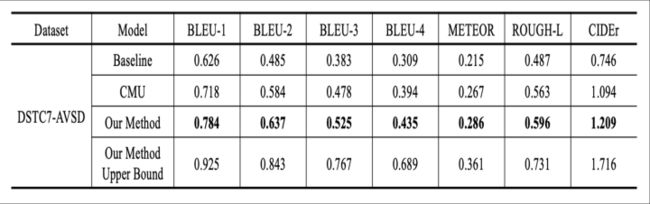
(1)在DSTC7-AVSD最下面的一行是给出了模型的上限,即假设所产生的k个response中最好的那个100% score最高即被选中。说明select部分还有很多可做空间。
(2) Seq2Seq是RNN的一种网络,LIC是一种基于transformer的网络。没有哪种结果在所有数据集和指标上都获得压倒性的胜利。
(3)Transformer的网络还是要好于RNN的,起码在human Evaluation上面上。
case analysis:

每个context 选了5个候选的response,附录中进一步展示了persona-chat、Daily Dialog和DSTC7-AVSD三个数据集场景下多个模型的输出case,感兴趣的可以看paper。
消融实验

在persona-chat数据集上面做的,指标是perplexity。
1系列是直接finetune;2系列是先在Reddit and Twitter数据集上面预训练一把;3是使用了latent
从1.2和1.3可以看到双向context的要好
从2系列和1系列对比来看,使用了对话数据预训练是要好于普通文本
3.1和2.2的相比,证明了latent的有效性。
PLATO-2
论文链接:https://arxiv.org/pdf/2006.16779.pdf
代码链接:https://github.com/PaddlePaddle/Knover/tree/develop/projects/PLATO-2
这是PLATO系列的第二篇,DialoGPT ,Meena,Blender 都是使用了更大的数据量,更大的模型进行训练,为此PLATO就想也上一下数据量和参数量。
但是一个问题就是,直接训练遇到训练不稳定和效率问题。作者猜测原因可能是让模型一上来就学习one-to-many挺难。于是想到了从简到难的学习过程即本文提到的curriculum learning。
总的来说相比于PLATO,PLATO-2 在框架上基本上没有太多改动,主要就是使用了一种多阶段训练方式扩大了数据量和模型参数量。
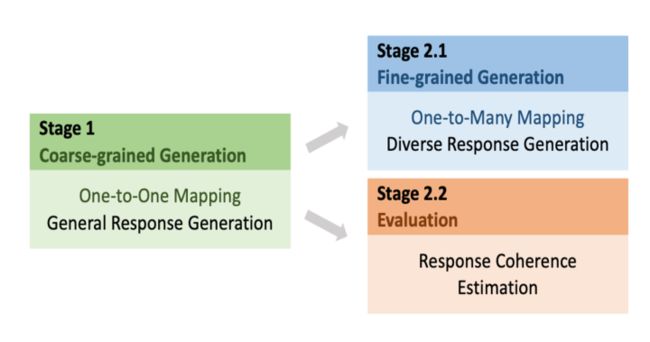
curriculum learning
这次同时训练了英文和中文,不过遵循了一贯的风格,哈哈,只开源了英文。
本文介绍的训练方式叫做curriculum learning 课程学习,即分阶段训练
第一阶段是one-to-one
第二阶段是one-to-many
具体来说其实是三个阶段
Coarse-grained : 粗粒度的学习,单纯的one-to-one生成模型,学一些通用性的response,缺乏多样性。
Fine-grained: 使用latent进行学习diverse response generation
Evaluation: 学习score (还记得 PLATO中的上限吗?估计在这里思考了下) 即response coherence
之所以分开训练,是决定多任务会影响,具体可以看
http://proceedings.mlr.press/v119/standley20a.html
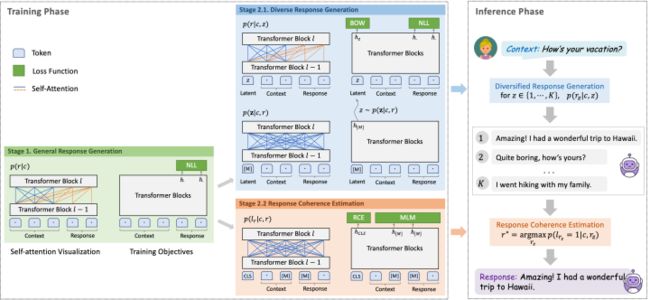
Coarse-grained: NLL
Fine-grained: NLL & BOW
Evaluation : RCE & MLM
RCE: 就是PLATO中的RS
训练了多个版本,大概可以总结如下
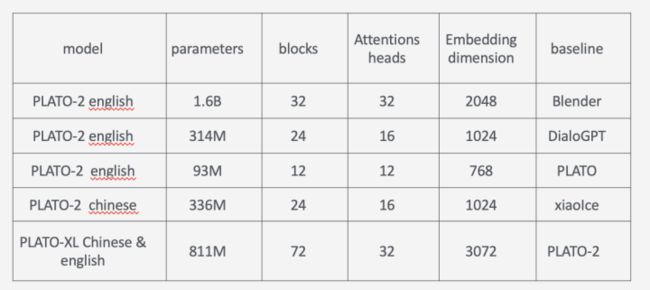
实验结果
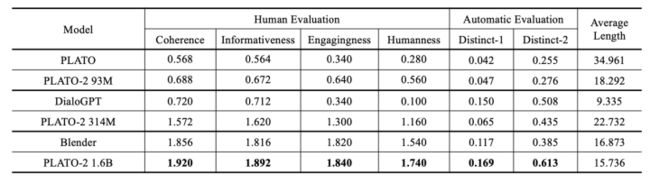
英文 Self-Chat
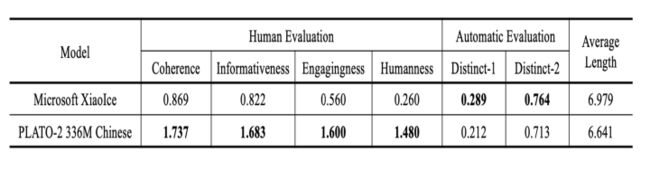
中文 Human-Bot Chat
一些数据集上Static评价
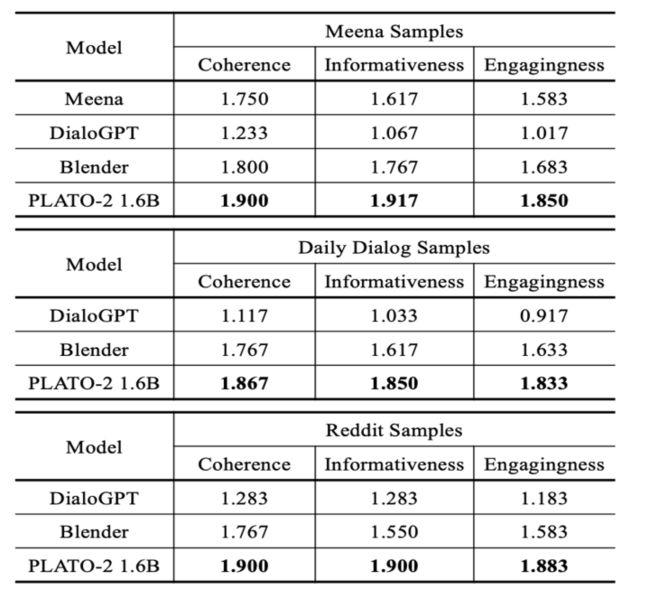
Case 分析

两者都很好,Blender和plato-2都是比较高质量的聊天,但是前者偏向于频繁换话题,后者偏向于深层面的聊天。原因可能是Blender使用的训练数据BST就是这种风格,plato-2就是因为有隐变量产生丰富的response并且有select的过程,选出一个更好的深层次的response,这里也做了一个实验,就是看深层次对话对比,发现确实PLATO-2更好。
同时在比赛DSTC9 ,三个任务:
一个是交互的任务Track3-task2 、一个静态的知识聊天Track3-task1 、一个专业领域的对话Track2-task1都取得了第一。
PLATO–XL
论文链接:https://arxiv.org/pdf/2109.09519.pdf
代码链接:https://github.com/PaddlePaddle/Knover/tree/develop/projects/PLATO-XL
这是第三篇,也是最新的一篇,也是开头展示测试效果的对应模型。其背景是在对话生成领域,目前没有一个关于模型大小和对话质量的明确的结论。如下图

最好的模型却不是最大的模型。
本文就是试图探索:
在适当的设计好预训练框架的前提下,恐怕对话质量还是会继续收益于大模型。
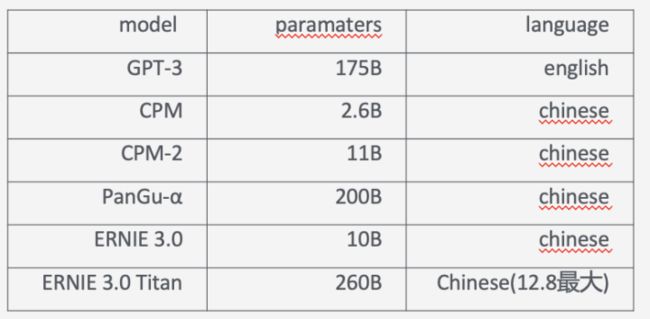
从上面可以看出一些大的趋势是:模型越来越大。
PLATO有一个基本假设就是只出现两个角色并且交替对话,这个人工标注的对话数据集大概率符合,但是在社交媒体的对话中就变得复杂了。
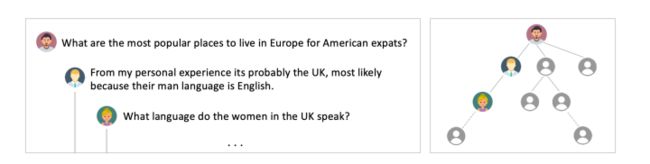
框架
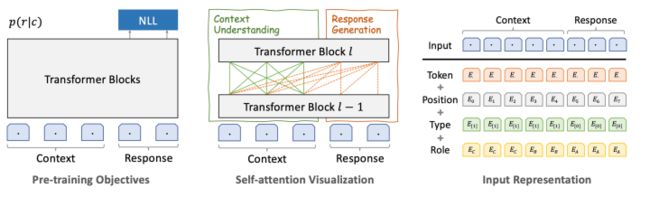
主要就是强调了这里的Role编码多个角色,框架等都没变,甚至loss只使用了一个NLL这一个。
小插曲:至于为什么没用其它的花里胡俏的loss,作者也是提都没提,个人猜测:
(1)本文重点就是探索上数据和参数量能否带来效果,在绝对量面 前,这些trick 都不用上就可以碾压之前的效果。
(2) 另外就是猜测可能是之前的方式太费时间了,一个样本要过好多次模型。本来现在模型就大,耗费时间。
所以paper没有过多的在loss 上面下功夫,主要目的就是上模型参数量+数据量,所以重点关注 computation and parameter efficiency :
(1) 使用unified transformer ,相比于encoder-decoder 这种网络,共享了参数。
(2) 另外一个是训练的时候batch使用尽可能一样长的样本可以达到即BlockShuffle。
(3) data parallelism & gradient checkpointing
实验结果
由于自动评估的结果和人为评估的结果一致性相差还是比较远,所以本篇主要采用了人工评价方式。
和其它一些大模型比较:
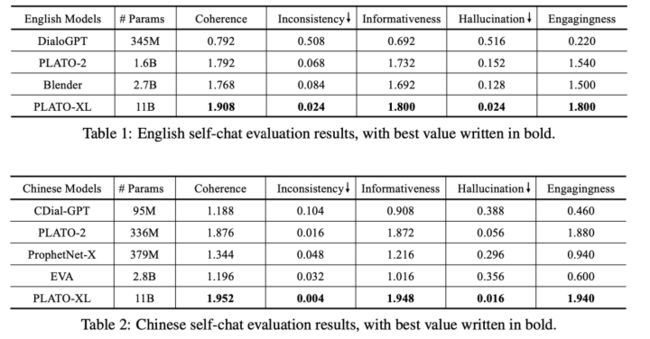
Self-Chat
和一些商业机器人比较
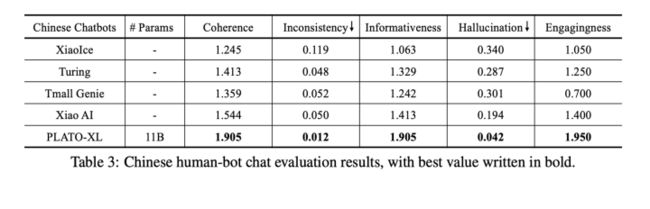
Human-Bot
Case

Self-chat
(1)对核能和马里亚纳海沟的讨论说明其包含了一些知识。
(2)左边的对话可以体现角色,P2担任了小白提问者,一直提问,P1担任了expert,耐心讲解。

Human-chat
能够利用一些诗词以及给出理由
knowledge grounded dialogue, and task-oriented conversation
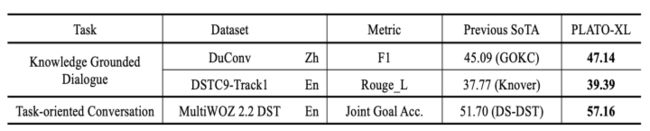
总结
(1) 预训练模型,单纯要想效果上数据量上参数量,猛训就完事了,相比花里胡俏的trick ,数据量和大模型更能带来大的甚至是质的提升,相对来说简单粗暴。
(2) 目前的一个训练样本都是深度遍历对话tree,是否可以进一步考虑宽度遍历,使得其学到大家讨论这一层面信息?
(3) 在闲聊领域端到端的这种大模型应该是个趋势。
(4)关于open-domain领域,对话技巧的研究目前是个热门,已经有部分工作进行了探索,大部分涌现的paper时间都在最近2年即2019年开始,但是在中文领域目前还没有很多工作,目前高质量、深度聊天这块还有很大提升空间。
彩蛋
机器之所以还不能代替人进行聊天,或者说聊一会人还是能感觉其是一个机器,本质上是什么原因呢?
其没有感情,冷冰冰?不理解你?不会主动分享事情等等?业界其实也注意到这个事情了,也针对性的进行了相关的研究,比如研究的领域分为:
Context Awareness :怎么用好历史上下文?
Response Coherence :回复的连贯性。
Response Diversity :回复的多样性。
Speaker Consistency and Personality-based Response :有必要意识到自己的角色,并基于固定的角色做出回应。
Empathetic Response :同情心。
Conversation Topic :识别出想聊的主题,能主动切换相关话题。
Knowledge-Grounded System :包含知识,知识渊博。
Interactive Training :交互式训练, 不需要很完善,边聊边学。
Visual Dialogue :其它模态对话,会视频等等。
由于篇幅有限,下次我们将重点分析有关研究上述聊天技巧的文章~
关注
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubMryangkaitong has 12 repositories available. Follow their code on GitHub.https://github.com/Mryangkaitong
知乎:
小小梦想 - 知乎https://www.zhihu.com/people/sa-tuo-de-yisheng/posts