支持向量机与SMO算法详解
文章目录
-
-
-
- 一、支持向量机基本型
- 二、问题求解
-
- 2.1 对偶问题
- 2.2 使用SMO算法
- 三、处理线性不可分的情况
-
- 3.1 软间隔与正则化
- 3.2 核函数
- 四、SMO算法
-
- 4.1 参数选择
- 4.2 更新 α i , α j \alpha_i,\alpha_j αi,αj
- 4.3 计算 w , b w,b w,b
-
-
一、支持向量机基本型
在一个二维平面上划分两种类型的样本点可能有多种方案,那么如何选择最优的划分方案呢?最直观的方法是选择一条距离两种样本点“最远的”直线。例如下图中的加粗分割线:

拓展到高纬空间,划分不同样本的超平面则可以表示为: w T x + b = 0 w^Tx+b=0 wTx+b=0。那么如何寻找到距离两种样本最远的超平面呢,可以将平面 w T x + b = 0 w^Tx+b=0 wTx+b=0进行平移得到平面 w T x + b = ξ w^Tx+b=\xi wTx+b=ξ、 w T x + b = − ξ w^Tx+b=-\xi wTx+b=−ξ使这两个平面正好与两种样本点相切。对平面的表达式进行变形:
{ w T x + b = + ξ w T x + b = − ξ ⇒ { w T ξ x + b ξ = + 1 w T ξ x + b ξ = − 1 \begin{cases} w^Tx+b=+\xi\\w^Tx+b=-\xi \end{cases} \Rightarrow \begin{cases} \frac{w^T}{\xi}x+\frac{b}{\xi}=+1\\\frac{w^T}{\xi}x+\frac{b}{\xi}=-1 \end{cases} {wTx+b=+ξwTx+b=−ξ⇒{ξwTx+ξb=+1ξwTx+ξb=−1
令 w T = w T ξ w^T=\frac{w^T}{\xi} wT=ξwT, b = b ξ b=\frac{b}{\xi} b=ξb,则有下图:
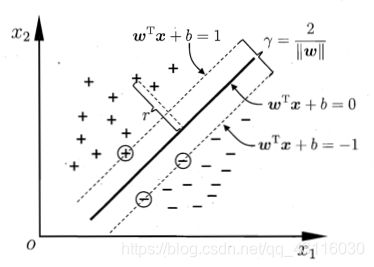
其中,与超平面 w T x + b = 1 w^Tx+b=1 wTx+b=1, w T x + b = − 1 w^Tx+b=-1 wTx+b=−1相切的样本点被称为支持向量,这两个平面我简称为支持平面,那么 r = 2 ∥ w ∥ r=\frac{2}{\|w\|} r=∥w∥2则为两个支持平面之间的间隔。
想要使超平面 w T x + b = 0 w^Tx+b=0 wTx+b=0正确划分样本点,同时尽量使 r r r最大,则可以建立如下数学模型:
arg max w , b 2 ∥ w ∥ s . t . { w T x i + b ≥ + 1 , y i = + 1 w T x i + b ≤ − 1 , y i = − 1 \argmax_{w,b}\frac{2}{\|w\|}\\ s.t.\; \begin{cases} w^Tx_i+b≥+1,\qquad y_i=+1\\ w^Tx_i+b≤-1,\qquad y_i=-1 \end{cases} w,bargmax∥w∥2s.t.{wTxi+b≥+1,yi=+1wTxi+b≤−1,yi=−1
其中 s t st st条件可以简化为: y i ( w T x i + b ) ≥ 1 y_i(w^Tx_i+b)≥1 yi(wTxi+b)≥1。整个问题则可以简化为:
arg min w , b ∥ w ∥ 2 2 s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , 3... , m \argmin_{w,b}\frac{\|w\|^2}{2}\\ s.t.\;y_i(w^Tx_i+b)≥1,i=1,2,3...,m w,bargmin2∥w∥2s.t.yi(wTxi+b)≥1,i=1,2,3...,m
这便是支持向量机的基本数学模型。
二、问题求解
2.1 对偶问题
通过对偶问题往往能有效解决一些复杂的问题,这里可以通过拉格朗日乘数法求出支持向量机基本型的对偶问题。
L ( w , b , α ) = ∥ w ∥ 2 2 + ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) ) , α i ≥ 0 L(w,b,\alpha)=\frac{\|w\|^2}{2}+\sum_{i=1}^m{\alpha_i(1-y_i(w^Tx_i+b))},\alpha_i≥0 L(w,b,α)=2∥w∥2+i=1∑mαi(1−yi(wTxi+b)),αi≥0
使拉格朗日函数 L L L分别对 w , b w,b w,b求偏导,可得:
∂ L ∂ w = w − ∑ i = 1 m α i y i x i ∂ L ∂ b = − ∑ i = 1 m α i y i \frac{\partial L}{\partial w}=w-\sum_{i=1}^m{\alpha_iy_ix_i}\qquad \frac{\partial L}{\partial b}=-\sum_{i=1}^m{\alpha_iy_i} ∂w∂L=w−i=1∑mαiyixi∂b∂L=−i=1∑mαiyi
令值为0,可得:
w = ∑ i = 1 m α i y i x i ∑ i = 1 m α i y i = 0 w=\sum_{i=1}^m{\alpha_iy_ix_i}\qquad \sum_{i=1}^m{\alpha_iy_i}=0 w=i=1∑mαiyixii=1∑mαiyi=0
代入拉格朗日函数:
L = 1 2 ∑ i = 1 m α i y i x i T ∑ i = 1 m α i y i x i + ∑ i = 1 m α i ( 1 − y i ( ∑ j = 1 m α j y j x j T x i + b ) ) = 1 2 ∑ i = 1 m ∑ j = 1 m α i y i x i T α j y j x j + ∑ i = 1 m α i − ∑ i = 1 m α i y i ( ∑ j = 1 m α j y j x j T x i + b ) = − 1 2 ∑ i = 1 m ∑ j = 1 m α i y i x i T α j y j x j + ∑ i = 1 m α i \begin{aligned} L &=\frac{1}{2}\sum^{m}_{i=1}{\alpha_iy_ix_i^T}\sum^{m}_{i=1}{\alpha_iy_ix_i}+\sum_{i=1}^m{\alpha_i(1-y_i( \sum_{j=1}^m{\alpha_jy_jx_j^T}x_i+b))}\\ &=\frac{1}{2}\sum^{m}_{i=1}\sum^{m}_{j=1}{\alpha_iy_ix_i^T\alpha_jy_jx_j}+\sum_{i=1}^m\alpha_i-\sum_{i=1}^m{\alpha_iy_i}(\sum_{j=1}^m{\alpha_jy_jx_j^Tx_i}+b)\\ &=-\frac{1}{2}\sum^{m}_{i=1}\sum^{m}_{j=1}{\alpha_iy_ix_i^T\alpha_jy_jx_j}+\sum_{i=1}^m\alpha_i \end{aligned} L=21i=1∑mαiyixiTi=1∑mαiyixi+i=1∑mαi(1−yi(j=1∑mαjyjxjTxi+b))=21i=1∑mj=1∑mαiyixiTαjyjxj+i=1∑mαi−i=1∑mαiyi(j=1∑mαjyjxjTxi+b)=−21i=1∑mj=1∑mαiyixiTαjyjxj+i=1∑mαi
固定 w , b w,b w,b,设 L ( w , b ) = max L ( w , b , α ) L(w, b)=\max L(w,b,\alpha) L(w,b)=maxL(w,b,α),则有:
arg min w , b L ( w , b ) = arg min w , b max α L ( w , b , α ) = arg max α min w , b L ( w , b , α ) = arg max α L ( α ) \arg\min_{w,b}L(w,b)=\arg\min_{w,b}\max_{\alpha}L(w,b,\alpha)=\arg\max_{\alpha}\min_{w,b}L(w,b,\alpha)=\argmax_{\alpha}L(\alpha) argw,bminL(w,b)=argw,bminαmaxL(w,b,α)=argαmaxw,bminL(w,b,α)=αargmaxL(α)
即,原问题可以转换为如下的对偶问题:
arg min α ( 1 2 ∑ i = 1 m ∑ j = 1 m α i y i x i T α j y j x j − ∑ i = 1 m α i ) s . t . ∑ i = 1 m α i y i = 0 \argmin_{\alpha}(\frac{1}{2}\sum^{m}_{i=1}\sum^{m}_{j=1}{\alpha_iy_ix_i^T\alpha_jy_jx_j}-\sum_{i=1}^m\alpha_i)\\ s.t.\sum_{i=1}^m{\alpha_iy_i}=0 αargmin(21i=1∑mj=1∑mαiyixiTαjyjxj−i=1∑mαi)s.t.i=1∑mαiyi=0
由KKT条件第三条定理可得:
{ α ≥ 0 y i ( w T x i + b ) ≥ 1 ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) ) = 0 \begin{cases} \alpha≥0\\ y_i(w^Tx_i+b)≥1\\ \sum_{i=1}^m{\alpha_i(1-y_i(w^Tx_i+b))}=0 \end{cases} ⎩⎪⎨⎪⎧α≥0yi(wTxi+b)≥1∑i=1mαi(1−yi(wTxi+b))=0
2.2 使用SMO算法
SMO算法,即序列最小优化算法,这是一种针对SVM的高效优化算法。其基本思想如下:
想要优化整个 α \alpha α序列,则可以考虑先固定其余的 α \alpha α,剩余一个 α i \alpha_i αi,并通过求函数在 α i \alpha_i αi上的极值点来更新 α i \alpha_i αi,从而可以依次求解出所有的 α \alpha α。
然而,由于约束 ∑ i = 1 m α i y i = 0 \sum_{i=1}^m{\alpha_iy_i}=0 ∑i=1mαiyi=0的存在,一旦固定 m − 1 m-1 m−1个 α \alpha α,那么剩下的那个 α i \alpha_i αi也将被固定。所以实际上SMO算法通常选取两个 α \alpha α,即 α i \alpha_i αi与 α j \alpha_j αj。通过不断地迭代选取和更新 α i \alpha_i αi与 α j \alpha_j αj直至收敛,即可完成优化。
以上是通过SMO算法优化2.1中提出的对偶问题的基本思路,其具体数学推导过程将在四、SMO算法中详细介绍。
三、处理线性不可分的情况
设想有如下情况:数据集中出现异常数据,导致少量样本点远离其同类样本点群,如果SVM还按照原本的规则进行划分,则可能找到一个狭窄的超平面导致过拟合,甚至还可能根本找不到可行的超平面,例如:

为了防止这种情况的产生,SVM采用了一些新的技巧。
3.1 软间隔与正则化
引入软间隔的目的是为了允许SVM在一些样本上出错,即允许部分样本不服从以下约束:
y i ( w T x i + b ) ≥ 1 y_i(w^Tx_i+b)≥1 yi(wTxi+b)≥1
但是,不满足条件的样本应当尽可能少,所以优化函数可以改写为:
arg min w , b 1 2 ∥ w ∥ 2 + λ ∑ i = 1 m l ( y i ( w T x i + b ) − 1 ) \argmin_{w,b}\frac{1}{2}\|w\|^2+\lambda\sum^{m}_{i=1}{l(y_i(w^Tx_i+b)-1)} w,bargmin21∥w∥2+λi=1∑ml(yi(wTxi+b)−1)
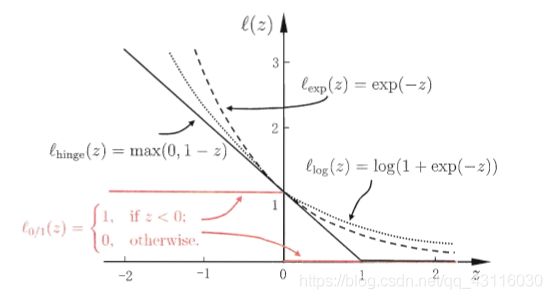
l ( x ) = { 1 , if x < 0 ; 0 , otherwise. l(x)= \begin{cases} 1,\qquad\text{if}\,x<0;\\0,\qquad\text{otherwise.} \end{cases} l(x)={1,ifx<0;0,otherwise.
通过这样的“罚分”技巧以及正则化,可以有效控制SVM对错误样本的容忍度。但是函数 l ( x ) l(x) l(x)是一个阶跃函数,数学性质不好,所以一般使用如下函数来进行代替:
- hinge损失函数: l h i n g e ( x ) = max ( 0 , 1 − x ) l_{hinge}(x)=\max(0,1-x) lhinge(x)=max(0,1−x);
- 指数损失函数: l e x p ( x ) = e − x l_{exp}(x)=e^{-x} lexp(x)=e−x;
- 对率损失函数: l l o g ( x ) = log ( 1 + e − z ) l_{log}(x)=\log(1+e^{-z}) llog(x)=log(1+e−z)。
根据上面的罚分函数,可以引入一个松弛变量 ξ i ≥ 0 \xi_i≥0 ξi≥0,然后将优化函数简写为:
arg min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 m ξ i s . t . y i ( w T x i + b ) ≥ 1 − ξ i ξ i ≥ 0 \argmin_{w,b}\frac{1}{2}\|w\|^2+C\sum^{m}_{i=1}\xi_i\\s.t.\;y_i(w^Tx_i+b)≥1-\xi_i\quad\xi_i≥0 w,bargmin21∥w∥2+Ci=1∑mξis.t.yi(wTxi+b)≥1−ξiξi≥0
同样使用拉格朗日乘数法,写出上述优化函数的拉格朗日函数:
L ( w , b , ξ , α , μ ) = 1 2 ∥ w ∥ 2 + C ∑ i = 1 m ξ i + ∑ i = 1 m α i ( 1 − ξ i − y i ( w T x i + b ) ) − ∑ i = 1 m μ i ξ i α ≥ 0 , μ ≥ 0 L(w,b,\xi,\alpha,\mu)=\frac{1}{2}\|w\|^2+C\sum^{m}_{i=1}\xi_i+\sum^{m}_{i=1}{\alpha_i(1-\xi_i-y_i(w^Tx_i+b))-\sum^{m}_{i=1}{\mu_i\xi_i}}\\\alpha≥0,\;\mu≥0 L(w,b,ξ,α,μ)=21∥w∥2+Ci=1∑mξi+i=1∑mαi(1−ξi−yi(wTxi+b))−i=1∑mμiξiα≥0,μ≥0
令上式分别对 w w w、 b b b、 ξ \xi ξ的偏导为0可得:
w = ∑ i = 1 m α i y i x i 0 = ∑ i = 1 m α i y i C = α i + μ i w=\sum^{m}_{i=1}{\alpha_iy_ix_i}\qquad0=\sum^{m}_{i=1}{\alpha_iy_i}\qquad C=\alpha_i+\mu_i w=i=1∑mαiyixi0=i=1∑mαiyiC=αi+μi
将上面的三个式子代入原式可得原问题的对偶问题:
arg min α ( 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j − ∑ i = 1 m α i ) s . t . ∑ i = 1 m α i y i = 0 , 0 ≤ α ≤ C \argmin_\alpha(\frac{1}{2}\sum^{m}_{i=1}\sum^{m}_{j=1}{\alpha_i\alpha_jy_iy_jx_i^Tx_j}-\sum^{m}_{i=1}\alpha_i)\\ s.t. \sum^{m}_{i=1}{\alpha_iy_i}=0,\;0≤\alpha≤C αargmin(21i=1∑mj=1∑mαiαjyiyjxiTxj−i=1∑mαi)s.t.i=1∑mαiyi=0,0≤α≤C
由KKT条件可得:
{ ξ ≥ 0 α ≥ 0 , μ ≥ 0 α i + μ i = C y i ( w T x i + b ) ≥ 1 − ξ i ∑ i = 1 m α i ( y i ( w T x i + b ) − 1 + ξ i ) = 0 ∑ i = 1 m μ i ξ i = 0 \begin{cases} \xi≥0\\ \alpha≥0,\quad\mu≥0\\ \alpha_i+\mu_i=C\\ y_i(w^Tx_i+b)≥1-\xi_i\\ \sum_{i=1}^m\alpha_i(y_i(w^Tx_i+b)-1+\xi_i)=0\\ \sum_{i=1}^m\mu_i\xi_i=0 \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧ξ≥0α≥0,μ≥0αi+μi=Cyi(wTxi+b)≥1−ξi∑i=1mαi(yi(wTxi+b)−1+ξi)=0∑i=1mμiξi=0
通过观察可以发现,软间隔SVM的对偶问题和硬间隔的在形式上一致,只是约束条件由 α ≥ 0 \alpha≥0 α≥0变成了 0 ≤ α ≤ C 0≤\alpha≤C 0≤α≤C,其求解方法和硬间隔SVM一致。
3.2 核函数
对于一个线性不可分的数据集,可以考虑通过函数映射将其映射到更高维度的空间内使之线性可分,例如:
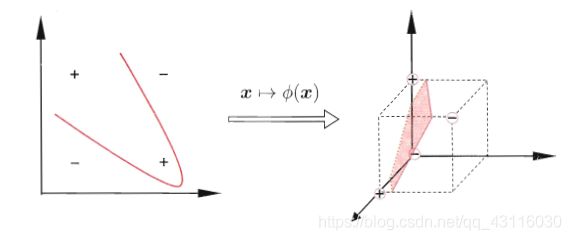
事实上,只要原始空间是有限维,即特征数量有限,那么便一定存在一个更高维度的特征空间使样本线性可分。假设映射后的样本为 x ∗ x^* x∗,那么对偶问题就变成了:
arg min α ( 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ∗ T x j ∗ − ∑ i = 1 m α i ) s . t . ∑ i = 1 m α i y i = 0 , 0 ≤ α ≤ C \argmin_\alpha(\frac{1}{2}\sum^{m}_{i=1}\sum^{m}_{j=1}{\alpha_i\alpha_jy_iy_jx_i^{*T}x_j^*}-\sum^{m}_{i=1}\alpha_i)\\ s.t. \sum^{m}_{i=1}{\alpha_iy_i}=0,\;0≤\alpha≤C αargmin(21i=1∑mj=1∑mαiαjyiyjxi∗Txj∗−i=1∑mαi)s.t.i=1∑mαiyi=0,0≤α≤C
这里涉及了 x ∗ T x ∗ x^{*T}x^* x∗Tx∗的运算,由于映射后的空间维度可能很高从而导致计算的代价极大,这里可以设计一个函数:
κ ( x i , x j ) = x i ∗ T x i ∗ \kappa(x_i,x_j)=x^{*T}_ix^*_i κ(xi,xj)=xi∗Txi∗
这个函数就叫做核函数。通过核函数,可以避免计算映射后的高维空间内积,这种方法叫做核技巧。于是对偶问题可以改写为:
arg min α ( 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j κ ( x i , x j ) − ∑ i = 1 m α i ) s . t . ∑ i = 1 m α i y i = 0 , 0 ≤ α ≤ C \argmin_\alpha(\frac{1}{2}\sum^{m}_{i=1}\sum^{m}_{j=1}{\alpha_i\alpha_jy_iy_j\kappa(x_i,x_j)}-\sum^{m}_{i=1}\alpha_i)\\ s.t. \sum^{m}_{i=1}{\alpha_iy_i}=0,\;0≤\alpha≤C αargmin(21i=1∑mj=1∑mαiαjyiyjκ(xi,xj)−i=1∑mαi)s.t.i=1∑mαiyi=0,0≤α≤C
下面列举一些常用的核函数:
| 名称 | 表达式 | 参数 |
|---|---|---|
| 线性核 | κ ( x i , x j ) = x i T x j \kappa(x_i,x_j)=x_i^Tx_j κ(xi,xj)=xiTxj | 无 |
| 多项式核 | κ ( x i , x j ) = ( x i T x j ) d \kappa(x_i,x_j)=(x_i^Tx_j)^d κ(xi,xj)=(xiTxj)d | d≥1为多项式的次数 |
| 高斯核(RBF核) | κ ( x i , x j ) = exp ( − ∥ x i − x j ∥ 2 2 σ 2 ) \kappa(x_i,x_j)=\exp(-\frac{\|x_i-x_j\|^2}{2\sigma^2}) κ(xi,xj)=exp(−2σ2∥xi−xj∥2) | σ > 0 \sigma>0 σ>0为高斯核的带宽 |
| 拉普拉斯核 | κ ( x i . x j ) = exp ( − ∥ x i − x j ∥ σ ) \kappa(x_i.x_j)=\exp(-\frac{\|x_i-x_j\|}{\sigma}) κ(xi.xj)=exp(−σ∥xi−xj∥) | σ > 0 \sigma>0 σ>0 |
| Sigmoid核 | κ ( x i , x j ) = tanh ( β x i T x j + θ ) \kappa(x_i,x_j)=\tanh(\beta x_i^Tx_j+\theta) κ(xi,xj)=tanh(βxiTxj+θ) | β > 0 , θ < 0 \beta>0,\;\theta<0 β>0,θ<0 |
除此之外,对于核函数 κ 1 , κ 2 \kappa_1,\kappa_2 κ1,κ2,有以下结论:
- 核函数的线性组合也是核函数: κ 3 = α κ 1 + β κ 2 \kappa_3=\alpha\kappa_1+\beta\kappa_2 κ3=ακ1+βκ2;
- 核函数的直积也是核函数: κ 3 ( x , y ) = κ 1 ( x , y ) κ 2 ( x , y ) \kappa_3(x,y)=\kappa_1(x,y)\kappa_2(x,y) κ3(x,y)=κ1(x,y)κ2(x,y);
- 对于任意函数 g g g,有: κ 3 ( x , y ) = g ( x ) κ 1 ( x , y ) g ( y ) \kappa_3(x,y)=g(x)\kappa_1(x,y)g(y) κ3(x,y)=g(x)κ1(x,y)g(y)。
四、SMO算法
先给出带核函数的软间隔SVM待优化问题:
arg min α ( 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j κ ( x i , x j ) − ∑ i = 1 m α i ) s . t . ∑ i = 1 m α i y i = 0 , 0 ≤ α ≤ C \argmin_\alpha(\frac{1}{2}\sum^{m}_{i=1}\sum^{m}_{j=1}{\alpha_i\alpha_jy_iy_j\kappa(x_i,x_j)}-\sum^{m}_{i=1}\alpha_i)\\ s.t. \sum^{m}_{i=1}{\alpha_iy_i}=0,\;0≤\alpha≤C αargmin(21i=1∑mj=1∑mαiαjyiyjκ(xi,xj)−i=1∑mαi)s.t.i=1∑mαiyi=0,0≤α≤C
KKT条件如下:
{ ξ ≥ 0 α ≥ 0 , μ ≥ 0 α i + μ i = C y i ( w T x i + b ) ≥ 1 − ξ i ∑ i = 1 m α i ( y i ( w T x i + b ) − 1 + ξ i ) = 0 ∑ i = 1 m μ i ξ i = 0 \begin{cases} \xi≥0\\ \alpha≥0,\quad\mu≥0\\ \alpha_i+\mu_i=C\\ y_i(w^Tx_i+b)≥1-\xi_i\\ \sum_{i=1}^m\alpha_i(y_i(w^Tx_i+b)-1+\xi_i)=0\\ \sum_{i=1}^m\mu_i\xi_i=0 \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧ξ≥0α≥0,μ≥0αi+μi=Cyi(wTxi+b)≥1−ξi∑i=1mαi(yi(wTxi+b)−1+ξi)=0∑i=1mμiξi=0
下面对 α i \alpha_i αi进行讨论:
- α i = 0 \alpha_i=0 αi=0:
α i = 0 , α i + μ i = C ⇒ μ i > 0 μ i > 0 , ∑ i = 1 m μ i ξ i = 0 ⇒ ξ i = 0 ξ i = 0 , y i ( w T x i + b ) ≥ 1 − ξ i ⇒ y i ( w T x i + b ) ≥ 1 \begin{aligned} \alpha_i=0,\alpha_i+\mu_i=C\Rightarrow&\mu_i>0\\ \mu_i>0,\sum_{i=1}^m{\mu_i\xi_i}=0\Rightarrow&\xi_i=0\\ \xi_i=0,y_i(w^Tx_i+b)≥1-\xi_i\Rightarrow&y_i(w^Tx_i+b)≥1 \end{aligned} αi=0,αi+μi=C⇒μi>0,i=1∑mμiξi=0⇒ξi=0,yi(wTxi+b)≥1−ξi⇒μi>0ξi=0yi(wTxi+b)≥1 - α i = C \alpha_i=C αi=C:
α i = C , α i + μ i = C ⇒ μ i = 0 μ i = 0 , ∑ i = 1 m μ i ξ i = 0 ⇒ ξ i ≥ 0 α i = C , ∑ i = 1 m α i ( y i ( w T x i + b ) − 1 + ξ i ) = 0 ⇒ y i ( w T x i + b ) = 1 − ξ i ξ i ≥ 0 , y i ( w T x i + b ) = 1 − ξ i ⇒ y i ( w T x i + b ) ≤ 1 \begin{aligned} \alpha_i=C,\alpha_i+\mu_i=C\Rightarrow&\mu_i=0\\ \mu_i=0,\sum_{i=1}^m{\mu_i\xi_i}=0\Rightarrow&\xi_i≥0\\ \alpha_i=C,\sum_{i=1}^m\alpha_i(y_i(w^Tx_i+b)-1+\xi_i)=0\Rightarrow&y_i(w^Tx_i+b)=1-\xi_i\\ \xi_i≥0,y_i(w^Tx_i+b)=1-\xi_i\Rightarrow&y_i(w^Tx_i+b)≤1 \end{aligned} αi=C,αi+μi=C⇒μi=0,i=1∑mμiξi=0⇒αi=C,i=1∑mαi(yi(wTxi+b)−1+ξi)=0⇒ξi≥0,yi(wTxi+b)=1−ξi⇒μi=0ξi≥0yi(wTxi+b)=1−ξiyi(wTxi+b)≤1 - 0 < α i < C 0<\alpha_i
0<αi<C :
0 < α i < C , α i + μ i = C ⇒ 0 < μ i < C 0 < μ i < C , ∑ i = 1 m μ i ξ i = 0 ⇒ ξ i = 0 0 < α i < C , ∑ i = 1 m α i ( y i ( w T x i + b ) − 1 + ξ i ) = 0 ⇒ y i ( w T x i + b ) = 1 − ξ i ξ i = 0 , y i ( w T x i + b ) = 1 − ξ i ⇒ y i ( w T x i + b ) = 1 \begin{aligned} 0<\alpha_i
总结出新的KKT条件如下:
{ y i ( w T x i + b ) ≥ 1 , α i = 0 y i ( w T x i + b ) = 1 , 0 < α i < C y i ( w T x i + b ) ≤ 1 , α i > C \begin{cases} y_i(w^Tx_i+b)≥1,\quad\alpha_i=0\\ y_i(w^Tx_i+b)=1,\quad0<\alpha_i
4.1 参数选择
SMO算法需要从 α \alpha α序列中选择出合适的 α i \alpha_i αi和 α j \alpha_j αj进行迭代更新。由于只要有一个选中的 α \alpha α不满足KKT条件,目标函数就会减小,所以可以从 α \alpha α中选择出一个不满足KKT条件的作为 α i \alpha_i αi,然后再选择一个和 α i \alpha_i αi对应样本差距最大的 α \alpha α作为 α j \alpha_j αj。这个所谓“差距”的衡量方法是计算 ∣ y i ∗ − y i − ( y j ∗ − y j ) ∣ |y_i^*-y_i-(y_j^*-y_j)| ∣yi∗−yi−(yj∗−yj)∣,原因通过后面的公式推导可以知道。
4.2 更新 α i , α j \alpha_i,\alpha_j αi,αj
假设选择出的两个 α \alpha α分别为 α 1 , α 2 \alpha_1,\alpha_2 α1,α2,则原目标函数可以简化为:
arg min α 1 , α 2 f ( α 1 , α 2 ) = 1 2 α 1 2 κ 11 + 1 2 α 2 2 κ 22 + α 1 α 2 y 1 y 2 κ 12 + α 1 y 1 u 1 + α 2 y 2 u 2 − α 1 − α 2 − u 3 s . t . α 1 y 1 + α 2 y 2 = c \argmin_{\alpha_1,\alpha_2}f(\alpha_1,\alpha_2)=\frac{1}{2}\alpha_1^2\kappa_{11}+\frac{1}{2}\alpha_2^2\kappa_{22}+\alpha_1\alpha_2y_1y_2\kappa_{12}+\alpha_1y_1u_1+\alpha_2y_2u_2-\alpha_1-\alpha_2-u_3\\ s.t.\alpha_1y_1+\alpha_2y_2=c α1,α2argminf(α1,α2)=21α12κ11+21α22κ22+α1α2y1y2κ12+α1y1u1+α2y2u2−α1−α2−u3s.t.α1y1+α2y2=c
其中,
u 1 = ∑ i = 3 m α i y i κ 1 i u 2 = ∑ i = 3 m α i y i κ 2 i u 3 = ∑ i = 3 m α i c = − ∑ i = 3 m α i y i u_1=\sum_{i=3}^m{\alpha_iy_i\kappa_{1i}}\quad u_2=\sum_{i=3}^m{\alpha_iy_i\kappa_{2i}}\quad u_3=\sum_{i=3}^m\alpha_i\quad c=-\sum_{i=3}^m{\alpha_iy_i} u1=i=3∑mαiyiκ1iu2=i=3∑mαiyiκ2iu3=i=3∑mαic=−i=3∑mαiyi
在 α 1 y 1 + α 2 y 2 = c \alpha_1y_1+\alpha_2y_2=c α1y1+α2y2=c两边乘 y 1 y_1 y1,可得: α 1 = y 1 c − α 2 y 1 y 2 \alpha_1=y_1c-\alpha_2y_1y_2 α1=y1c−α2y1y2,代入目标函数:
arg min α 2 f ( α 2 ) = 1 2 α 1 2 κ 11 + 1 2 α 2 2 κ 22 + α 1 α 2 y 1 y 2 κ 12 + α 1 y 1 u 1 + α 2 y 2 u 2 − α 1 − α 2 − u 3 = 1 2 κ 11 c 2 + 1 2 α 2 2 κ 11 − α 2 y 2 κ 11 c + 1 2 α 2 2 κ 22 + α 2 y 2 κ 12 c − α 2 2 κ 12 + u 1 c − α 2 y 2 u 1 + α 2 y 2 u 2 − y 1 c + α 2 y 1 y 2 − α 2 − u 3 = 1 2 ( κ 11 + κ 22 − 2 κ 12 ) α 2 2 + ( y 2 κ 12 c − y 2 κ 11 c − y 2 u 1 + y 2 u 2 + y 1 y 2 − 1 ) α 2 + c o n s t \begin{aligned} \argmin_{\alpha_2}f(\alpha_2)=&\frac{1}{2}\alpha_1^2\kappa_{11}+\frac{1}{2}\alpha_2^2\kappa_{22}+\alpha_1\alpha_2y_1y_2\kappa_{12}+\alpha_1y_1u_1+\alpha_2y_2u_2-\alpha_1-\alpha_2-u_3\\ =&\frac{1}{2}\kappa_{11}c^2+\frac{1}{2}\alpha_2^2\kappa_{11}-\alpha_2y_2\kappa_{11}c+\frac{1}{2}\alpha_2^2\kappa_{22}+\alpha_2y_2\kappa_{12}c-\alpha_2^2\kappa_{12}+u_1c-\alpha_2y_2u_1\\&+\alpha_2y_2u_2-y_1c+\alpha_2y_1y_2-\alpha_2-u_3\\ =&\frac{1}{2}(\kappa_{11}+\kappa_{22}-2\kappa_{12})\alpha_2^2+(y_2\kappa_{12}c-y_2\kappa_{11}c-y_2u_1+y_2u_2+y_1y_2-1)\alpha_2+const \end{aligned} α2argminf(α2)===21α12κ11+21α22κ22+α1α2y1y2κ12+α1y1u1+α2y2u2−α1−α2−u321κ11c2+21α22κ11−α2y2κ11c+21α22κ22+α2y2κ12c−α22κ12+u1c−α2y2u1+α2y2u2−y1c+α2y1y2−α2−u321(κ11+κ22−2κ12)α22+(y2κ12c−y2κ11c−y2u1+y2u2+y1y2−1)α2+const
将函数 f ( α 2 ) f(\alpha_2) f(α2)对 α 2 \alpha_2 α2求导,
∂ f ∂ α 2 = ( κ 11 + κ 22 − 2 κ 12 ) α 2 + y 2 κ 12 c − y 2 κ 11 c − y 2 u 1 + y 2 u 2 + y 1 y 2 − 1 \frac{\partial f}{\partial\alpha_2}=(\kappa_{11}+\kappa_{22}-2\kappa_{12})\alpha_2+y_2\kappa_{12}c-y_2\kappa_{11}c-y_2u_1+y_2u_2+y_1y_2-1 ∂α2∂f=(κ11+κ22−2κ12)α2+y2κ12c−y2κ11c−y2u1+y2u2+y1y2−1
设更新后的 α \alpha α为 α ∗ \alpha^* α∗,最终学得的SVM模型为 f ( x ) = w T x + b = ∑ i = 1 m α i y i κ ( x i , x ) + b f(x)=w^Tx+b=\sum_{i=1}^m\alpha_iy_i\kappa(x_i,x)+b f(x)=wTx+b=∑i=1mαiyiκ(xi,x)+b,误差则为 E i = f ( x i ) − y i E_i=f(x_i)-y_i Ei=f(xi)−yi。同时,还有:
c = α 1 y 1 + α 2 y 2 = α 1 ∗ y 1 + α 2 ∗ y 2 u 1 = ∑ i = 3 m α i y i κ ( x i , x 1 ) = f ( x 1 ) − ∑ i = 1 2 α i y i κ i 1 − b u 2 = ∑ i = 3 m α i y i κ ( x i , x 2 ) = f ( x 2 ) − ∑ i = 1 2 α i y i κ i 2 − b c=\alpha_1y_1+\alpha_2y_2=\alpha_1^*y_1+\alpha_2^*y_2\\ u_1=\sum_{i=3}^m{\alpha_iy_i\kappa(x_i,x_1)}=f(x_1)-\sum_{i=1}^2{\alpha_iy_i\kappa_{i1}}-b\\ u_2=\sum_{i=3}^m{\alpha_iy_i\kappa(x_i,x_2)}=f(x_2)-\sum_{i=1}^2{\alpha_iy_i\kappa_{i2}}-b c=α1y1+α2y2=α1∗y1+α2∗y2u1=i=3∑mαiyiκ(xi,x1)=f(x1)−i=1∑2αiyiκi1−bu2=i=3∑mαiyiκ(xi,x2)=f(x2)−i=1∑2αiyiκi2−b
将 E i , c , u 1 , u 2 E_i,c,u_1,u_2 Ei,c,u1,u2代入导数,同时令导数为0,可得:
( κ 11 + κ 22 − 2 κ 12 ) α 2 ∗ = 1 − y 2 κ 12 c + y 2 κ 11 c + y 2 f ( x 1 ) − y 2 ∑ i = 1 2 α i y i κ i 1 − y 2 b − y 2 f ( x 2 ) + y 2 ∑ i = 1 2 α i y i κ i 2 + y 2 b − y 1 y 2 ⇒ ( κ 11 + κ 22 − 2 κ 12 ) α 2 ∗ = ( κ 11 + κ 22 − 2 κ 12 ) α 2 + y 2 ( f ( x 1 ) − y 1 − ( f ( x 2 ) − y 2 ) ) ⇒ ( κ 11 + κ 22 − 2 κ 12 ) α 2 ∗ = ( κ 11 + κ 22 − 2 κ 12 ) α 2 + y 2 ( E 1 − E 2 ) ⇒ α 2 ∗ = α 2 + y 2 E 1 − E 2 κ 11 + κ 22 − 2 κ 12 \begin{aligned} (\kappa_{11}+\kappa_{22}-2\kappa_{12})\alpha_2^*=&1-y_2\kappa_{12}c+y_2\kappa_{11}c+y_2f(x_1)-y_2\sum_{i=1}^2{\alpha_iy_i\kappa_{i1}}-y_2b-y_2f(x_2)+y_2\sum_{i=1}^2{\alpha_iy_i\kappa_{i2}}\\&+y_2b-y_1y_2\\ \Rightarrow(\kappa_{11}+\kappa_{22}-2\kappa_{12})\alpha_2^*=&(\kappa_{11}+\kappa_{22}-2\kappa_{12})\alpha_2+y_2(f(x_1)-y_1-(f(x_2)-y_2))\\ \Rightarrow(\kappa_{11}+\kappa_{22}-2\kappa_{12})\alpha_2^*=&(\kappa_{11}+\kappa_{22}-2\kappa_{12})\alpha_2+y_2(E_1-E_2)\\ \Rightarrow\alpha_2^*=&\alpha_2+y_2\frac{E_1-E_2}{\kappa_{11}+\kappa_{22}-2\kappa_{12}} \end{aligned} (κ11+κ22−2κ12)α2∗=⇒(κ11+κ22−2κ12)α2∗=⇒(κ11+κ22−2κ12)α2∗=⇒α2∗=1−y2κ12c+y2κ11c+y2f(x1)−y2i=1∑2αiyiκi1−y2b−y2f(x2)+y2i=1∑2αiyiκi2+y2b−y1y2(κ11+κ22−2κ12)α2+y2(f(x1)−y1−(f(x2)−y2))(κ11+κ22−2κ12)α2+y2(E1−E2)α2+y2κ11+κ22−2κ12E1−E2
记 η = κ 11 + κ 22 − 2 κ 12 \eta=\kappa_{11}+\kappa_{22}-2\kappa_{12} η=κ11+κ22−2κ12,则有如下更新公式:
α 2 ∗ = α 2 + y 2 E 1 − E 2 η \alpha_2^*=\alpha_2+y_2\frac{E_1-E_2}{\eta} α2∗=α2+y2ηE1−E2
从这个更新公式不难看出,之所以第二个参数要选择使 ∣ E 1 − E 2 ∣ |E_1-E_2| ∣E1−E2∣最大的,是为了让参数更新得更快。
此时计算的参数没有考虑约束,下面讨论参数的范围:
- y 1 = y 2 y_1=y_2 y1=y2:则有 α 1 + α 2 = α 1 ∗ + α 2 ∗ = c \alpha_1+\alpha_2=\alpha_1^*+\alpha_2^*=c α1+α2=α1∗+α2∗=c,进一步讨论:
- i f : α 1 ∗ = 0 ⇒ α 2 m a x ∗ = min ( C , α 1 + α 2 ) if:\alpha_1^*=0\Rightarrow\alpha_{2max}^*=\min(C,\alpha_1+\alpha_2) if:α1∗=0⇒α2max∗=min(C,α1+α2)
- i f : α 1 ∗ = C ⇒ α 2 m i n ∗ = max ( 0 , α 1 + α 2 − C ) if:\alpha_1^*=C\Rightarrow\alpha_{2min}^*=\max(0,\alpha_1+\alpha_2-C) if:α1∗=C⇒α2min∗=max(0,α1+α2−C)
- y 1 ≠ y 2 y_1≠y_2 y1=y2:则有 α 1 − α 2 = α 1 ∗ − α 2 ∗ = c \alpha_1-\alpha_2=\alpha_1^*-\alpha_2^*=c α1−α2=α1∗−α2∗=c,进一步讨论:
- i f : α 1 ∗ = 0 ⇒ α 2 m i n ∗ = max ( 0 , α 2 − α 1 ) if:\alpha_1^*=0\Rightarrow\alpha_{2min}^*=\max(0,\alpha_2-\alpha_1) if:α1∗=0⇒α2min∗=max(0,α2−α1)
- i f : α 1 ∗ = C ⇒ α 2 m a x ∗ = min ( C , C + α 2 − α 1 ) if:\alpha_1^*=C\Rightarrow\alpha_{2max}^*=\min(C,C+\alpha_2-\alpha_1) if:α1∗=C⇒α2max∗=min(C,C+α2−α1)
上面便是 α 2 ∗ \alpha_2^* α2∗的参数范围,进行修正后通过下述公式便可以计算出 α 1 ∗ \alpha_1^* α1∗:
α 1 ∗ = α 1 y 1 + α 2 y 2 − α 2 ∗ y 2 y 1 \alpha_1^*=\frac{\alpha_1y_1+\alpha_2y_2-\alpha_2^*y_2}{y_1} α1∗=y1α1y1+α2y2−α2∗y2
4.3 计算 w , b w,b w,b
w w w的计算很简单,由于之间已经推导出公式: w = ∑ i = 1 m α i y i x i w=\sum^{m}_{i=1}{\alpha_iy_ix_i} w=i=1∑mαiyixi直接计算即可。
b b b的计算通过KKT条件: y i ( w T x i + b ) = 1 ⇒ w T x i + b = y i ⇒ b = y i − w T x i y_i(w^Tx_i+b)=1\Rightarrow w^Tx_i+b=y_i\Rightarrow b=y_i-w^Tx_i yi(wTxi+b)=1⇒wTxi+b=yi⇒b=yi−wTxi可以计算得到。此KKT条件要求 0 < α i < C 0<\alpha_i
b ∗ = { b 1 ∗ , 0 < α 1 < C b 2 ∗ , 0 < α 2 < C ( b 1 ∗ + b 2 ∗ ) / 2 , o t h e r s b^*= \begin{cases} b_1^*,0<\alpha_1