ECCV2022 | 激光雷达点云的开放世界语义分割
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【领域综述】获取自动驾驶全栈近80篇综述论文!
论文链接:https://arxiv.org/abs/2207.01452
代码链接:https://github.com/Jun-CEN/Open_world_3D_semantic_segmentation
论文方法
三维激光雷达传感器在自主车辆感知系统中发挥着重要作用。近年来,激光雷达点云的语义分割发展非常迅速,受益于包括SemanticKITTI和nuScenes在内的注释良好的数据集。然而,现有的激光雷达语义分割方法都是封闭集和静态的。闭集网络将所有输入视为训练过程中遇到的类别,因此它会错误地将旧类的标签分配给新类,这可能会带来灾难性后果。同时,静态网络受限于某些场景,因为它无法更新自身以适应新环境。此外,从头开始训练以适应新场景非常耗时,并且由于隐私限制,旧类的注释有时不可用。
为了解决闭集和静态问题,我们提出了激光雷达点云的开放世界语义分割,它由两个任务组成:
1) 开放集语义分割(OSeg)将未知标签分配给新类,并将正确标签分配给旧类;
2)增量学习(IL),在标签商提供新类的标签后,将新类逐渐合并到知识库中;
下图显示出了激光雷达点云的开放世界语义分割的示例:

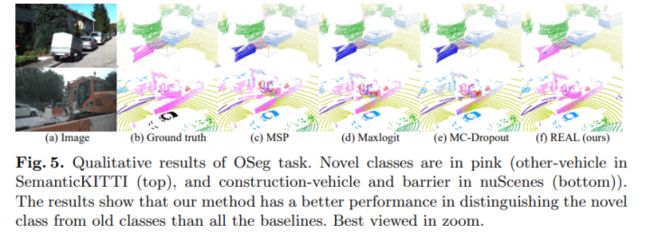
封闭集模型Mc错误地将旧类的标签分配给新对象(A:建筑车辆被分类为ManMade、卡车甚至行人;B:障碍物被分类为道路、ManMade和其他平面;C:交通标志被分类为Manmade)。在开放集语义分割(OSeg)任务之后,开放集模型Mo可以识别新对象并为它们分配未知标签。在增量学习(IL)任务之后,模型Mi可以对旧类和新类进行分类。
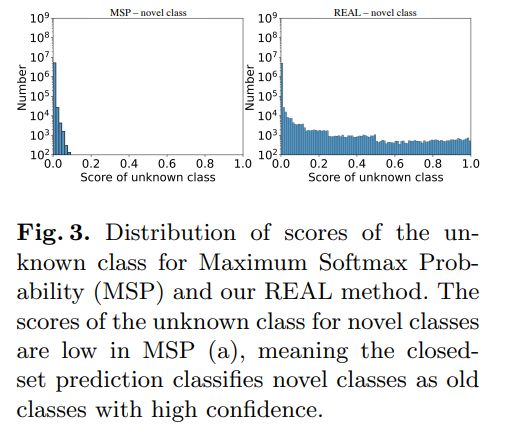
由于论文是第一个在3D激光雷达点云领域研究OSeg任务,参考了2D图像域中的现有方法,可分为两种类型,基于生成网络的方法[1,20,32]和基于不确定性的方法[11,14,18],尽管它们都不能直接使用。基于生成网络的方法采用条件生成对抗网络(cGAN),[24]基于闭集预测结果重构输入,并假设新区域在重构输入和原始输入之间具有较大的外观差异。然而,cGAN不适合重建点云,因为所有信息都由几何信息(即点的坐标)确定,并且cGAN只能重建通道信息(即RGB值),同时保持几何信息(包括像素的坐标和图像的形状)不变。基于不确定性的方法也工作得很差,因为我们发现网络将新类预测为具有高置信分数的旧类,如下图所示。除了OSeg任务的挑战,灾难性遗忘增量学习中的旧类是另一个需要解决的问题。仅使用新类的标签直接微调网络将使网络将一切分类为新类。因此,需要一种方法来增量学习新类,同时保持旧类的性能。
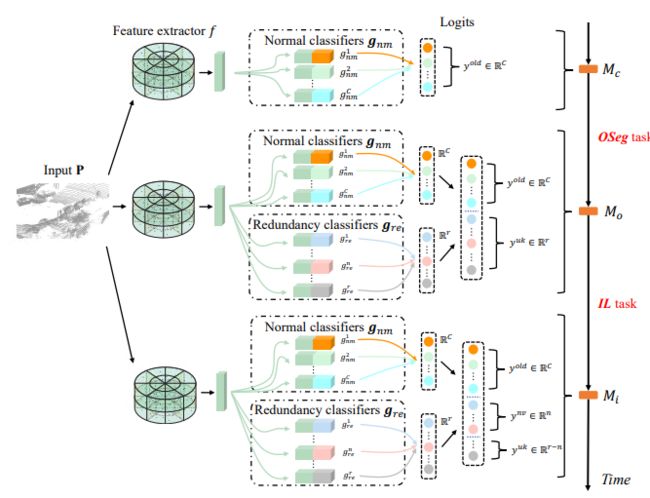
论文提出了一种冗余分类器(REAL)框架,以提供一种动态分类器架构,使模型适应OSeg和IL任务。对于OSeg任务,在原始网络的基础上添加了多个冗余分类器(RCs),以预测未知类的概率。然后,在IL任务期间,训练几个RCs对新引入的类进行分类,而剩余的RCs仍然负责未知类,如下图所示,基于未知对象合成、预测分布校准和伪标签生成,为实际情况下的OSeg和IL任务提供了训练策略。
领域方案
闭集激光雷达语义分割:激光雷达点云的语义分割可分为基于点和基于体素的方法。典型的基于点的方法使用PointNet和PointNet++直接对激光雷达点云进行操作。然而,由于激光雷达点云的密度变化和大规模,它们的性能有限。另一种基于点的方法将激光雷达点云转换为2D网格,然后应用2D卷积运算进行语义分割。SqueezeSeg和RangeNet++将点云转换为距离图像,而PolarNet将点云转换为极坐标下的鸟瞰图。然而,2D表示不可避免地丢失一些3D拓扑和几何信息。Cylinder 3D是一种基于体素的方法,它通过圆柱形分区和非对称三维卷积网络处理激光雷达点云的稀疏性和变密度问题。Cylinder 3D在SemanticKITTI和nuScenes上实现了最先进的性能,因此我们将其作为我们工作的基础架构。
开放集2D分类:开放集2D的分类方法有两种趋势:基于不确定性的方法和基于生成模型的方法。最大Softmax概率(MSP)是基于不确定性的方法的基线,而Dan等人[13]发现最大Logit(MaxLogit)是更好的选择。MC Dropout[11]和Ensembles[18]用于近似贝叶斯推理[17,21],后者从概率角度考虑网络。
同时,基于生成的方法,包括SynthCP[32]和DUIR[20],采用条件GAN(cGAN)[24]来重构输入,并通过将重构输入与原始输入进行比较来找到新区域。然而,这些方法不能直接适用于3D激光雷达点云域。[28,35]建议使用冗余分类器(RCs)直接输出未知类的分数,并采用流形混合和基于随机梯度Langevin动力学(SGLD)[29]的采样器来近似未知类分布。论文从中汲取了灵感,并进一步将RCs用于OSeg和IL,以及为3D点云领域开发合适的训练策略。
开放世界分类和检测:开放世界问题首先由Abhijit等人提出[4],他们认为网络应该能够处理在现实世界中实用的动态类别集。因此,他们引入了开放世界分类管道:首先识别已知和未知图像,然后在给定标签时逐渐学习对未知图像进行分类。他们提出了最近非离群值方法来管理开放世界分类任务。Joseph等人[16]将开放世界问题扩展到2D对象检测领域,并提出了一种基于对比聚类、未知感知建议网络和基于能量的未知识别的方法,以应对开放世界检测的挑战。Jun等人[7]后来采用深度度量学习对2D图像进行开放世界语义分割。在这里,论文将开放世界问题扩展到三维激光雷达云点域,而包括用于三维激光雷达点云的OSeg和IL在内的两个子任务尚未研究。
冗余分类器框架(REAL)
训练的闭集模型Mc由特征提取器f和常规分类器gnm组成,能够很好地分类旧类K0,针对一个确定输入P,输出为:
OSeg任务是使封闭集模型Mc适应开放集模型使得Mo可以将新类U识别为未知。为了实现这一目标,我们在gre中添加了r冗余分类器(RCs):
上图Mo中的所有RCs用于预测未知类别的分数y,将y的最大响应设为未知类的分数,由类0表示。这样,开放集模型Mo的输出为:

IL任务是将开放集模型Mo训练为Mi,以便新引入的类Kn从未知变为已知,Mi表示为:
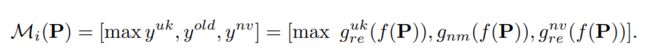

实验
论文对开放世界语义分割的两个任务进行了实验,包括OSeg和IL任务,在两个大规模数据集SemanticKITTI和nuScenes上评估了提出的方法,REAL方法在开放集上的性能如下所示,相比于之前的方法,有明显提升!

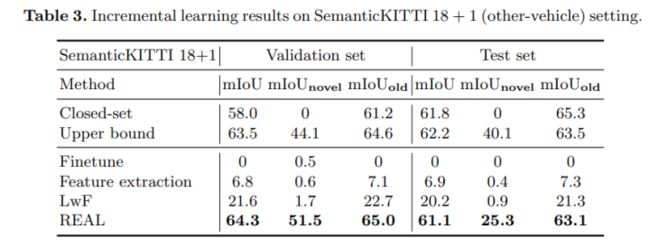
增量学习在SemanticKITTI上的性能对比,接近或超过上限:
参考文献
[1] Open-world Semantic Segmentation for LIDAR Point Clouds
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
