运用Python分析公募基金【量化投资】
运用Python分析公募基金
1、背景
学校财富管理课程的期末论文是分析中国各种投资标的的收益,笔者分配到的研究的细分类别为:通过大集合转公募基金的方式,成立的公募基金的收益分析。Python在量化投资,尤其是投资的分析、策略回测等方面有着广泛的运用,所以笔者结合在政胤老师课程中学习的知识,运用Python对基金的收益进行分析。
2、数据来源
“巧妇难为无米之炊”,寻找高质量的数据是分析的第一步。本文的数据来自于Wind客户端。数据分为两个:

链接:https://pan.baidu.com/s/1JzJWxM9CyxTotldu5BjbjA 提取码:clki
3、数据分析
3.1 导入数据
def day_data(self):
day_data = pd.read_csv(root_path+'/data/大集合转公募基金复权净值day.CSV', encoding='gbk')
day_data.rename(columns={'Unnamed: 0': '交易日期'}, inplace=True)
day_data['交易日期'] = pd.to_datetime(day_data['交易日期'])
#day_rtn.set_index('交易日期', inplace=True)
day_data.dropna(axis=1, how='any', inplace=True)
return day_data
def index_day_data(self):
index_day_rtn = pd.read_csv(root_path+'/data/中国基金加权指数day.csv',
encoding='gbk')
index_day_rtn.rename(columns={'Unnamed: 0': '交易日期'}, inplace=True)
index_day_rtn['交易日期'] = pd.to_datetime(index_day_rtn['交易日期'])
index_day_rtn['中国基金加权总指数'] = index_day_rtn['中国基金加权总指数'].pct_change()
return index_day_rtn
在导入数据时,我们发现有许多缺失值,这是因为大部分大集合在2021年才转为公募基金,所以仅有几个月的收益。我们在此处采取最简单的数据清洗方式:将含有缺失值的基金删除。
这是整理后的数据:

3.2数据信息提取
观察数据,发现这些公募基金的名字既长又复杂,分析的时候一个一个输入名字肯定非常费时间。通过观察发现,这些基金的名字有个特点:基金名字的前两个或多个字,为基金公司的名字。如:海通的基金就命名为:海通量化价值精选一年持有B、海通海升六个月持有A等。
那么我们运用正则表达式,实现输入证券资管的名称,就得到其旗下的公募基金的名称。
def get_col_name(self):
day_data = self.day_data()
# 匹配正则表达式
pattern = re.compile('^%s'% self.company)
col_name = day_data.columns.tolist()
choose_name = []
for name in col_name:
if pattern.match(name):
choose_name.append(name)
print(choose_name)
return choose_name
def col_num(self):
choose_name = self.get_col_name()
num = len(choose_name)
# print(num)
return num
3.3 指数信息和基金信息按日期合并
def choose_data(self):
choose_name = self.get_col_name()
day_data = self.day_data()
day_data = day_data[['交易日期', choose_name[self.fund_num]]]
day_data[choose_name[self.fund_num]] = day_data[choose_name[self.fund_num]].pct_change()
day_rtn = day_data
# 和指数信息合并
index_day_rtn = self.index_day_data()
equity_day = pd.merge(day_rtn, index_day_rtn, on='交易日期', how='left' )
equity_day.dropna(axis=0, how='any', inplace=True)
equity_day.rename(columns={choose_name[self.fund_num]: '涨跌幅', '中国基金加权总指数': '指数涨跌幅'}, inplace=True)
return equity_day
此处计算基金收益时运用了dataframe.pct_change()函数(Pandas dataframe.pct_change()函数计算当前元素与之前元素之间的百分比变化。默认情况下,此函数计算前一行的百分比变化)。
此处我们使用的是环比增长,假如想用对数收益率,则不可以使用dataframe.pct_change()函数。
3.4画收益率曲线
为了能够在以后的研究中,方便调用绘画收益率曲线的函数,我们新建一个专门存放自建函数的文档,将函数保存。
# ===绘制收益率曲线
# 绘制策略曲线
def draw_equity_curve(df, data_dict, time=None, pic_size=[16, 9], dpi=72, font_size=25, save_path='fig.jpg'):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# plt.style.use('dark_background')
plt.figure(figsize=(pic_size[0], pic_size[1]), dpi=dpi)
plt.xticks(fontsize=font_size)
plt.yticks(fontsize=font_size)
for key in data_dict:
if time:
plt.plot(df[time], df[data_dict[key]], label=key)
else:
plt.plot(df.index, df[data_dict[key]], label=key)
plt.legend(fontsize=font_size)
plt.grid()
#plt.show(
plt.savefig(save_path)
在主程序中调用绘画收益率曲线的函数:
def yield_curve(self):
equity = self.choose_data()
equity['equity_curve'] = (equity['涨跌幅'] + 1).cumprod()
equity['benchmark'] = (equity['指数涨跌幅'] + 1).cumprod()
equity = equity[['交易日期', 'equity_curve', 'benchmark', '涨跌幅', '指数涨跌幅']]
return equity
def draw_curve(self, save_path = r'fig.jpg'):
choose_name = self.get_col_name()
equity = self.yield_curve()
equity = equity.reset_index(drop=True)
equity['交易日期'] = pd.to_datetime(equity['交易日期'])
draw_equity_curve(equity, time='交易日期', data_dict={choose_name[self.fund_num]: 'equity_curve', '中国基金加权总指数': 'benchmark'},
save_path=save_path)
3.5 评价指标
对于基金的收益,仅仅看收益率曲线,获得的评价较为主观,要客观比较收益的好坏,还要借助指标,比如:年化收益率、最大回撤等,更加复杂的还有夏普比率、Jensen指数等,需要的评价指标加入一下自定义的函数strategy_evaluate()即可。
# 计算策略评价指标
def strategy_evaluate(equity):
# ===新建一个dataframe保存回测指标
results = pd.DataFrame()
# ===计算累积净值
results.loc[0, '累积净值'] = round(equity['equity_curve'].iloc[-1], 2)
# ===计算年化收益
annual_return = (equity['equity_curve'].iloc[-1]) ** (
'1 days 00:00:00' / (equity['交易日期'].iloc[-1] - equity['交易日期'].iloc[0]) * 365) - 1
results.loc[0, '年化收益'] = str(round(annual_return * 100, 2)) + '%'
# 计算当日之前的资金曲线的最高点
equity['max2here'] = equity['equity_curve'].expanding().max()
# 计算到历史最高值到当日的跌幅,drowdwon
equity['dd2here'] = equity['equity_curve'] / equity['max2here'] - 1
# 计算最大回撤,以及最大回撤结束时间
end_date, max_draw_down = tuple(equity.sort_values(by=['dd2here']).iloc[0][['交易日期', 'dd2here']])
# 计算最大回撤开始时间
start_date = equity[equity['交易日期'] <= end_date].sort_values(by='equity_curve', ascending=False).iloc[0]['交易日期']
# 将无关的变量删除
equity.drop(['max2here', 'dd2here'], axis=1, inplace=True)
results.loc[0, '最大回撤'] = format(max_draw_down, '.2%')
results.loc[0, '最大回撤开始时间'] = str(start_date)
results.loc[0, '最大回撤结束时间'] = str(end_date)
return results.T
在主程序中调用业绩评价函数
def evaluate(self):
equity = self.yield_curve()
choose_name = self.get_col_name()
# ===计算策略评价指标
rtn_data= strategy_evaluate(equity)
rtn_data.rename(columns={0: choose_name[self.fund_num]}, inplace=True)
#print(rtn_data)
return rtn_data
3.6运行程序
在运行程序前,要在目录里面建好保存收益率曲线和收益率评价的文件夹,如图所示:

在company_name处输入基金公司的简称,num即返回基金公司下的基金数量,程序自动遍历其旗下基金,并将其收益曲线图存入chart,将其收益评价指标合并后存入sheet。
if __name__ == '__main__':
company_name = '光大'
analyse = Analyse(company=company_name, fund_num = 0)
num = analyse.col_num()
df_ret_analyse = pd.DataFrame()
for i in range(num):
name = analyse.get_col_name()[i]
try:
analyse = Analyse(company=company_name, fund_num=i)
analyse.draw_curve(save_path = root_path + r'/result\chart/%s.jpg' % name)
df = analyse.evaluate()
df_ret_analyse = pd.concat([df_ret_analyse, df], axis=1)
except:
print(name + '数据错误')
print(df_ret_analyse)
df_ret_analyse.to_csv(root_path + f'/result\sheet\{company_name}retns.csv')
4、运行效果展示
在company_name处输入'光大',查看光大资管的公募基金收益情况。运行后,收益率曲线已经全部保存至/result/chart

点开其中一个查看:
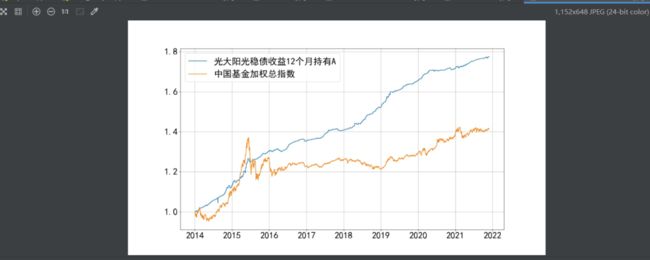
收益指标则保存到了/result/sheet下:

5、完整代码
5.1 函数
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# ===获取项目根目录
_ = os.path.abspath(os.path.dirname(__file__)) # 返回当前文件路径
root_path = os.path.abspath(os.path.join(_, '..')) # 返回根目录文件夹
# ===绘制收益率曲线
# 绘制策略曲线
def draw_equity_curve(df, data_dict, time=None, pic_size=[16, 9], dpi=72, font_size=25, save_path='fig.jpg'):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# plt.style.use('dark_background')
plt.figure(figsize=(pic_size[0], pic_size[1]), dpi=dpi)
plt.xticks(fontsize=font_size)
plt.yticks(fontsize=font_size)
for key in data_dict:
if time:
plt.plot(df[time], df[data_dict[key]], label=key)
else:
plt.plot(df.index, df[data_dict[key]], label=key)
plt.legend(fontsize=font_size)
plt.grid()
#plt.show(
plt.savefig(save_path)
# 计算策略评价指标
def strategy_evaluate(equity):
# ===新建一个dataframe保存回测指标
results = pd.DataFrame()
# ===计算累积净值
results.loc[0, '累积净值'] = round(equity['equity_curve'].iloc[-1], 2)
# ===计算年化收益
annual_return = (equity['equity_curve'].iloc[-1]) ** (
'1 days 00:00:00' / (equity['交易日期'].iloc[-1] - equity['交易日期'].iloc[0]) * 365) - 1
results.loc[0, '年化收益'] = str(round(annual_return * 100, 2)) + '%'
# 计算当日之前的资金曲线的最高点
equity['max2here'] = equity['equity_curve'].expanding().max()
# 计算到历史最高值到当日的跌幅,drowdwon
equity['dd2here'] = equity['equity_curve'] / equity['max2here'] - 1
# 计算最大回撤,以及最大回撤结束时间
end_date, max_draw_down = tuple(equity.sort_values(by=['dd2here']).iloc[0][['交易日期', 'dd2here']])
# 计算最大回撤开始时间
start_date = equity[equity['交易日期'] <= end_date].sort_values(by='equity_curve', ascending=False).iloc[0]['交易日期']
# 将无关的变量删除
equity.drop(['max2here', 'dd2here'], axis=1, inplace=True)
results.loc[0, '最大回撤'] = format(max_draw_down, '.2%')
results.loc[0, '最大回撤开始时间'] = str(start_date)
results.loc[0, '最大回撤结束时间'] = str(end_date)
return results.T
5.2主程序
import pandas as pd
import re
from 基金收益分析.func.myfunc import *
class Analyse(object):
def __init__(self, company='海通', fund_num = 0):
self.company = company
self.fund_num = fund_num
pass
def day_data(self):
day_data = pd.read_csv(root_path+'/data/大集合转公募基金复权净值day.CSV', encoding='gbk')
day_data.rename(columns={'Unnamed: 0': '交易日期'}, inplace=True)
day_data['交易日期'] = pd.to_datetime(day_data['交易日期'])
#day_rtn.set_index('交易日期', inplace=True)
day_data.dropna(axis=1, how='any', inplace=True)
return day_data
def index_day_data(self):
index_day_rtn = pd.read_csv(root_path+'/data/中国基金加权指数day.csv',
encoding='gbk')
index_day_rtn.rename(columns={'Unnamed: 0': '交易日期'}, inplace=True)
index_day_rtn['交易日期'] = pd.to_datetime(index_day_rtn['交易日期'])
index_day_rtn['中国基金加权总指数'] = index_day_rtn['中国基金加权总指数'].pct_change()
return index_day_rtn
def get_col_name(self):
day_data = self.day_data()
# 匹配正则表达式
pattern = re.compile('^%s'% self.company)
col_name = day_data.columns.tolist()
choose_name = []
for name in col_name:
if pattern.match(name):
choose_name.append(name)
print(choose_name)
return choose_name
def col_num(self):
choose_name = self.get_col_name()
num = len(choose_name)
# print(num)
return num
def choose_data(self):
choose_name = self.get_col_name()
day_data = self.day_data()
day_data = day_data[['交易日期', choose_name[self.fund_num]]]
day_data[choose_name[self.fund_num]] = day_data[choose_name[self.fund_num]].pct_change()
day_rtn = day_data
# 和指数信息合并
index_day_rtn = self.index_day_data()
equity_day = pd.merge(day_rtn, index_day_rtn, on='交易日期', how='left' )
equity_day.dropna(axis=0, how='any', inplace=True)
equity_day.rename(columns={choose_name[self.fund_num]: '涨跌幅', '中国基金加权总指数': '指数涨跌幅'}, inplace=True)
return equity_day
def yield_curve(self):
equity = self.choose_data()
equity['equity_curve'] = (equity['涨跌幅'] + 1).cumprod()
equity['benchmark'] = (equity['指数涨跌幅'] + 1).cumprod()
equity = equity[['交易日期', 'equity_curve', 'benchmark', '涨跌幅', '指数涨跌幅']]
return equity
def draw_curve(self, save_path = r'fig.jpg'):
choose_name = self.get_col_name()
equity = self.yield_curve()
equity = equity.reset_index(drop=True)
equity['交易日期'] = pd.to_datetime(equity['交易日期'])
draw_equity_curve(equity, time='交易日期', data_dict={choose_name[self.fund_num]: 'equity_curve', '中国基金加权总指数': 'benchmark'},
save_path=save_path)
def evaluate(self):
equity = self.yield_curve()
choose_name = self.get_col_name()
# ===计算策略评价指标
rtn_data= strategy_evaluate(equity)
rtn_data.rename(columns={0: choose_name[self.fund_num]}, inplace=True)
#print(rtn_data)
return rtn_data
if __name__ == '__main__':
company_name = '光大'
analyse = Analyse(company=company_name, fund_num = 0)
num = analyse.col_num()
df_ret_analyse = pd.DataFrame()
for i in range(num):
name = analyse.get_col_name()[i]
try:
analyse = Analyse(company=company_name, fund_num=i)
analyse.draw_curve(save_path = root_path + r'/result\chart/%s.jpg' % name)
df = analyse.evaluate()
df_ret_analyse = pd.concat([df_ret_analyse, df], axis=1)
except:
print(name + '数据错误')
print(df_ret_analyse)
df_ret_analyse.to_csv(root_path + f'/result\sheet\{company_name}retns.csv')
6、结语
此处的分析作为分析的一个框架,可以添加更多的有趣的研究内容,比如:对基金的收益数据可以计算其期望,方差,峰度,偏度等指标,对收益率也可以计算夏普比率等指标。可以更加深入的分析基金的收益的变动。
最后强烈推荐。政胤老师的python课程,科班程序员出生的帅帅老师,代码写的非常规范,初学者可以少走弯路。并且政胤老师的答疑非常及时,仔细回复每个问题,笔者每次遇到网上查询不到答案的问题时,都会马上请教政胤老师,节省了许多自己debug的时间!(友情推送)
总之,无论是初学者从头学习,还是老手查漏补缺,找一位专家答疑,政胤的课程都物超所值。