来自CCNet的一种创新:语义分割中的十字交叉视觉注意力

来自CCNet的一种创新:语义分割中的十字交叉视觉注意力
- 写在文章开头
- 看个大概
- 引入
- CCNet之道
-
- 整体架构
- 十字交叉注意力
- 循环——RCCA
- 优化类别一致性损失
- CCNet效果一览
- 写在文章末尾
写在文章开头
不知何故,我很喜欢CCNet这个名字,也许是因为读起来朗朗上口、清新的感觉。CCNet是对Non-local模块(有关Non-local可以参看我的这篇文章)改进与进一步应用的典范,因此我觉得有必要对其进行深入剖析。
CCNet的原作是CCNet: Criss-Cross Attention for Semantic Segmentation,大家有兴趣可以Google Scholar一下,这里我就不给出原文地址了。与以往一致,还是这句话:本篇文章用作我个人笔记,面向人群是我自己,因此一些我本人已经熟悉的知识便不会详述,所以文章的知识体系可能会显得不够系统。
看个大概
先从摘要说起。作者提出的CCNet可以以非常有效的方式捕获完整图像的上下文信息。具体而言,作者提出了一种新颖的图像信息捕捉方式——criss-cross attention模块(我译作十字交叉注意力模块,接下的文章简称为CCA),该模块可以从每个像素点的criss-cross path(我译作十字交叉路径,接下的文章简称为CCP)获取图像的上下文信息。接着,通过进一步的循环处理(加上循环后,CCA还称为recurrent CCA,简称为RCCA,后文有提及),每个像素最终都可以理顺完整图像像素间的依赖关系(是不是有Non-local模块的味道了)。此外,本文还引入了一个概念叫做类别一致性损失(category consistent loss,CCL),该损失可以增强CCA模块的识别能力。
接下来作者吹个不停:
- GPU memory friendly. Compared with the non-local block, the proposed recurrent criss-cross attention module requires 11× less GPU memory usage.
- High computational efficiency. The recurrent criss-cross attention significantly reduces FLOPs by about 85% of the non-local block.
- The state-of-the-art performance.
好了,这篇文章不用看也知道CCNet很厉害了。
引入
作者称,Non-local模块内在的机制会产生比较大的时间和空间复杂度( O(N 2 ^2 2),N是输入图像的特征量即维度 ),这是因为NL模块为了衡量像素对间的关系会去生成巨大的attention map。
为解决这一问题,作者打算将NL模块原本的全连接图转换成稀疏连接。在满足一般性的前提下,作者使用了两个连续的CCA模块,其中每个模块在特征图中每个像素位置都只提供稀疏连接(大概是 N \sqrt N N)。而在每一个像素位置,CCA模块对其水平方向和垂直方向的上下文信息进行汇总。
接着,作者说了这样一句话:“ By serially stacking two criss-cross attention modules, each position can collect contextual information from all pixels in the given image ”实际上,我没太理解这句话,因为按理说CCA模块在某一像素点只是集成了该中心像素“上下左右”部分的像素,并没有对其它方位的像素做处理,即便两虚堆叠两个CCA模块也是这样的。既然如此,作者为什么要说是“ all pixels ”呢?
经过上述处理,时间和空间复杂度降为了O( N N N\sqrt N NN)。
接下来,我们简单对比一下Non-local与CCA模块:

首先来分析(a)图。(a)图是Non-local模块的抽象表示,具体表现其实在Non-local的原论文中就有说明,这里我直接给出:
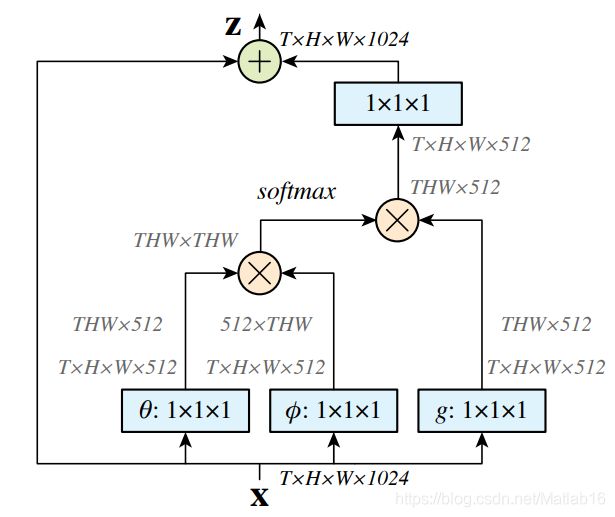
根据我的观察,我认为(a)图应该这样理解:我们观察(a)图中的带有绿色像素块的张量,其实它们就是c图中的 θ \theta θ和 ϕ \phi ϕ函数的联合输出;(a)图中的带有灰色像素块的张量就是 g g g函数的输出。具体来说是这样的:
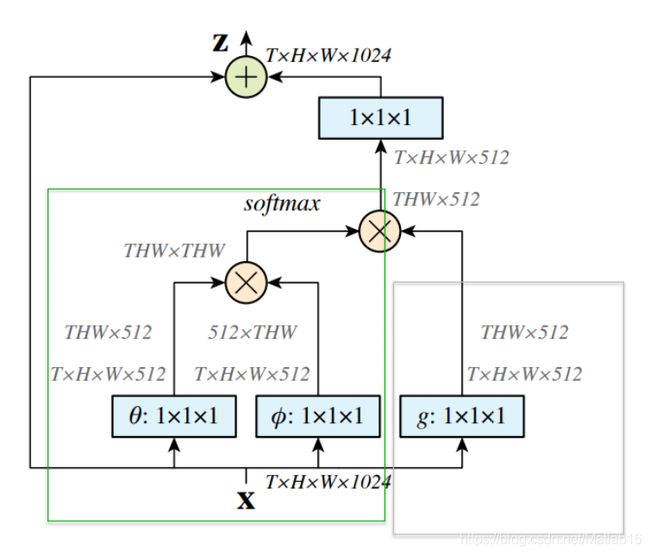
上图中绿色框就对应(a)图中的带有绿色像素块的张量,也就是attention map(应该是吧,毕竟图形结构只能这样对应,而残差连接结构作者也有说为了方便起见而在(a)图去掉了),灰色框则对应(a)图中的带有灰色像素块的张量。
从(a)图便可以知道,Non-local的attention map的的确确是稠密的,因为每个像素点都有对应的权重。接下来我们就来看看CCA模块对此的改进。
首先,整体来看CCA模块实际上与Non-local模块的大致结构基本相同,不同的是CCA对应的attention map不再是稠密的,而是呈现十字交叉稀疏形式。并且,CCA还加上了循环结构。虽说是循环结构,但其实(b)图中将该循环结构进行了 “ 剥离 ”,使之水平排列,而且(b)图只采用了两次循环。
我们知道,Non-local计算attention map时使用了 “ 1×1卷积-展平-矩阵乘法 ” 模式,从而输出了稠密的结果(也就是每个像素都有对应的权重)。那么,CCA模块所输出的十字交叉稀疏的结果是如何做到的呢?看到这里我并不清楚这个问题的答案,接着往下阅读也许可以知道答案。
为什么要采用循环操作呢?作者说这样是为了防止attention map的稀疏性可能导致的上下文信息捕捉不完整。
对于循环操作,作者只是定性解释了一下:“ In particular, the local features are firstly passed through one criss-cross attention module to collect the contextual information in horizontal and vertical directions. Then, by feeding the feature map produced by the first criss-cross attention module into the second one, the additional contextual information obtained from the criss-cross path finally enables the full image dependencies for all positions.” 我没能理解循环操作是如何“ enables the full image dependencies for all positions ”的。
原文还有一句比较重要的话:“ We share parameters of the criss-cross modules to keep our model slim. ”。
这句话是说CCA模块的参数是共享的,但具体怎样共享这里还没有提及。
此外,为了让RCCA学习到的特征具备多样性,作者还引入了类别一致性损失CCL。CCL强制网络将图像中每个像素映射到特征空间中的 n n n维向量,使得属于同一类别的像素对应的特征向量距离较小,而属于不同类别的像素对应的特征向量则相距很远。
到这里,论文的介绍部分就完毕了。接下来就是对上述部分的详细探讨。这里先插一句题外话吧,为了提出CCNet这样一个网络,作者们真是在前期花费了大量时间来阅读、沉潜,这里截取了部分作者参考的一些网络(绿色标记)。

所以说呀,学术领域从来没有骤然蹦现的灵感,只有深沉的积淀。所以之前我做深度生成模型相关研究时也学习了许多模型,比如DFCVAE,DirVAE,LVAE,NVAE,DisVAE,LIN,BAGAN,Alpha-GAN,E-MGAN,SteganoCNN等等,正是有了它们才会有S3VAE的诞生。尽管我们没办法完全掌握那么多模型、技巧,但是它们都是思想的利器呀。
CCNet之道
整体架构
与论文相关的一些工作就不提了,上面的截图也大致说明了问题。接着我们要做的就是深入学习CCNet。我们首先给出CCNet的完整网络框架
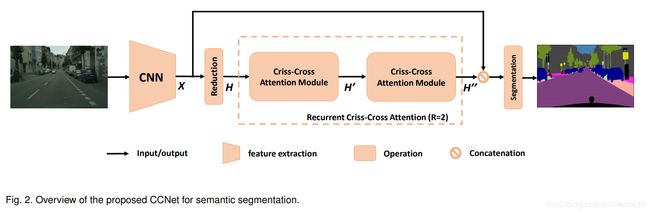
可见整个结构经过抽象后其实还是很简单的。其中的CNN模块是FCN型网络,并且为了保留更多的细节并且高效生成特征图,作者去除了CNN模块最后两层下采样操作,并在后继层中使用空洞(dilation)卷积将输出图像的长宽大小变为输入图像的 1 8 \frac{1}{8} 81。而关于整个CCNet的计算流程,为了节省时间我就不再重复叙述,这里给出作者的解释:



十字交叉注意力
我们结合CCA模块的示意图来进行深入学习。
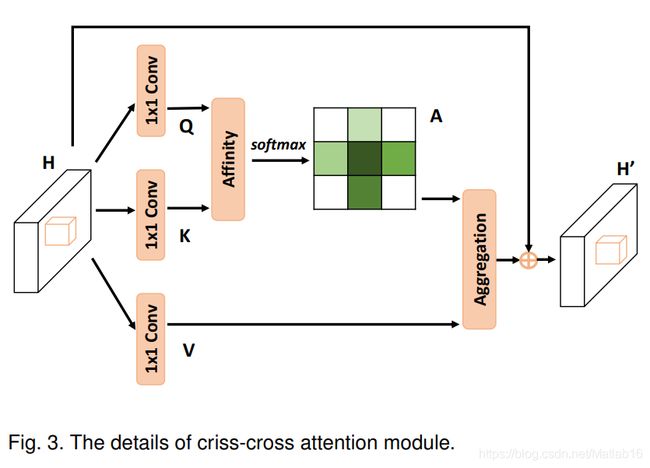

和Non-local模块一致,CCA的 θ \theta θ、 ϕ \phi ϕ和 g g g函数同样采用的是1×1卷积实现的矩阵变换。但不同的是,CCA模块还拥有一个Affinity操作。该操作具体来说,在 Q Q Q张量的某一像素位置 u u u处,我们可以得到一个向量 Q u Q_{u} Qu满足 Q u ∈ R C ′ Q_{u}∈\R^{C^{'}} Qu∈RC′。同样的道理,另一方面我们则从 K K K张量中获得一组,注意是一组,向量 Ω u ∈ R [ H + W − 1 ] C ′ \Omega_{u}∈\R^{[H+W-1]C^{'}} Ωu∈R[H+W−1]C′。这组向量的个数为什么是 [ H + W − 1 ] [H+W-1] [H+W−1]呢?实际上是因为我们从张量 K K K中提取这组向量时是按照十字交叉、水平-垂直方式进行提取的,而这样的方法它们会在中心像素点处有一次交叉,因此我们才减一。另外, Ω i , u ∈ R C ′ \Omega_{i,u}∈\R^{C^{'}} Ωi,u∈RC′代表的是向量组 Ω u \Omega_{u} Ωu的第 i i i个向量。说了这么多,Affinity操作的计算式如下:
d i , u = Q u Ω i , u T (1) d_{i,u}=Q_{u}\Omega_{i,u}^{T} \tag{1} di,u=QuΩi,uT(1)其中的 d i , u ∈ D d_{i,u}∈D di,u∈D代表的是特征 Q u Q_{u} Qu与特征 Ω i , u \Omega_{i,u} Ωi,u相关性的程度,并且满足 i ∈ [ 1 , . . . , ( H + W − 1 ) ] i∈[1,...,(H+W-1)] i∈[1,...,(H+W−1)]。由此可以看出视觉注意力机制实际上是针对两个像素点的一维向量表示而言的,而不是单独的像素点。而它们的相关性计算采用的是极其朴素的向量乘积运算(注意 d i , u d_{i,u} di,u是一个数值而不是矩阵或向量)。此外, D ∈ R [ H + W − 1 ] [ W × H ] D∈\R^{[H+W-1][W×H]} D∈R[H+W−1][W×H], d i , u d_{i,u} di,u的范围之所以包含 [ W × H ] [W×H] [W×H]范围内是因为像素点 u u u是局限于平面图像内部的。由此看出, d i , u d_{i,u} di,u处在一个二维张量面中,并且 i i i代表着通道维度, u u u代表着平面维度。经过整个Affinity操作后,将输出张量 A ∈ R [ H + W − 1 ] [ W × H ] A∈\R^{[H+W-1][W×H]} A∈R[H+W−1][W×H](实际上 d i , u d_{i,u} di,u可以表示为 A i , u A_{i,u} Ai,u)。
与上述同理,我们来关注剩下的一条非残差连接的支路(最下面那条)以及最后所有支路的集成操作。

到此,CCA模块结束。
循环——RCCA
其实所谓的RCCA不过是几个CCA模块的叠加而已,它的提出是为了解决这样一个问题:尽管十字交叉注意力模块可以在水平和垂直方向上捕获上下文信息,但是仍然缺少一个像素与其周围不在十字交叉路径中的像素之间的连接。
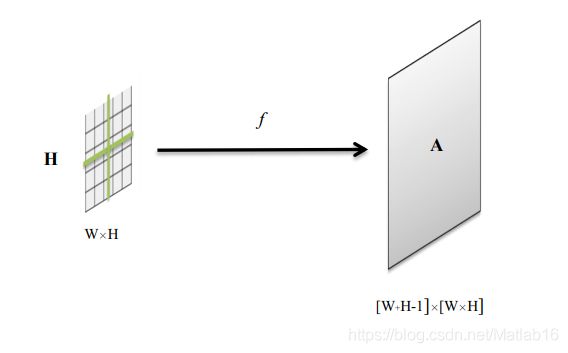
通过引入如下定义的函数 f f f,RCCA模块建立的特征图中任意两个空间位置之间的连接可以被清晰地定量描述。

这个函数实际上定义了一个映射关系,将输入 H H H上某个位置处的像素点 u u u及以它为中心的十字交叉路径上的某个点 通过某种变换 f f f映射到 Affinity操作输出 A A A上的某个点。对于这一关系示意图如下:
函数 f f f为我们带来了以下的好处:

下面这段话我认为非常重要(注意,上下两段话符号的定义有所变化),因为作者详细说明了RCCA模块为什么能够捕捉完整的上下文信息。

对应的示意图如下

其实看完这段话和示意图,我脑袋还是糊糊的一片。实际上Figure 4展示的是输入张量 H H H上的某一个像素点( θ x \theta_x θx, θ y \theta_y θy)与RCCA输出张量 H ′ ′ H^{''} H′′上的某一个像素点 ( u x , u y ) (u_x,u_y) (ux,uy)之间的信息传播过程,并且像素点 ( u x , u y ) (u_x,u_y) (ux,uy)并不在像素点( θ x \theta_x θx, θ y \theta_y θy)的十字交叉路径内。在这个传播过程中,函数 f f f就相当于一个传播媒介用以承载信息。从示意图中我们可以想象,从 ( u x , u y ) (u_x,u_y) (ux,uy)点到( θ x \theta_x θx, θ y \theta_y θy)点,有点类似定位的意思。也就是说,信息最终的流向是通过以下两个过程得到的:
- 在初始像素点的十字交叉路径上寻找两个点(loop 1)
- 各自从这两个点中取出一个横坐标和纵坐标,重新组成一个坐标,从而完成定位(loop 2)
可见 R = 2 R=2 R=2的RCCA模块总共用到了四次 f f f函数映射。
到这里,我有一个问题,说了这么半天,这个函数 f f f到底是什么样的形式?在我看来,作者明确说明了函数 f f f的抽象表达式(我重新写在下面):
也就是将输入映射到attention map的一个函数,那么根据前面的讨论,没理解错的话该映射不就是
d i , u = Q u Ω i , u T d_{i,u}=Q_{u}\Omega_{i,u}^{T} di,u=QuΩi,uT吗?
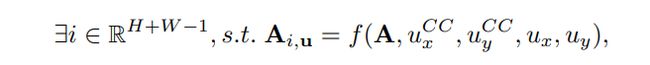
优化类别一致性损失
“ For semantic segmentation tasks, the pixels belonging to the same category should have the similar features, while the pixels from different categories should have far apart features”。其实这就是CCL提出的背景。“ We name such a characteristic as category consistency”。作者称,由RCCA模块输出的张量具有完整的上下文信息,但是the aggregated feature可能存在过度平滑的问题。这里的the aggregated feature其实就是CCA除开残差连接结构后的输出值。

接着是一些CCL有关的符号定义(方便起见,我就偷个懒粘上图片吧):

所谓的类别一致性损失函数就是式 ( 8 ) (8) (8)的定义。
其实我这里并没有讲清楚CCL的意义,因为CCL的提出是作者基于下面这篇文献来进行改进的,而我并没有看过这篇文章。
B. De Brabandere, D. Neven, and L. Van Gool, “Semantic instance segmentation with a discriminative loss function,” arXiv preprint arXiv:1708.02551, 2017. 5, 6
论文里还说明了3D Criss-Cross Attention,这里我就不再叙述了。毕竟我暂时只会用到二维的视觉注意力机制。
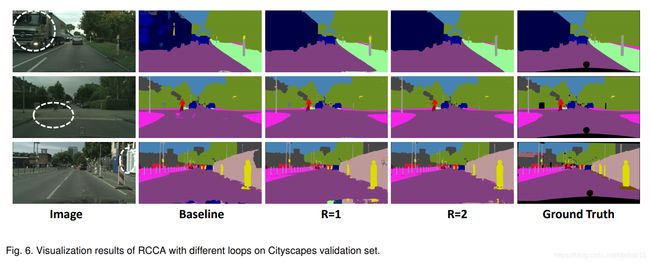
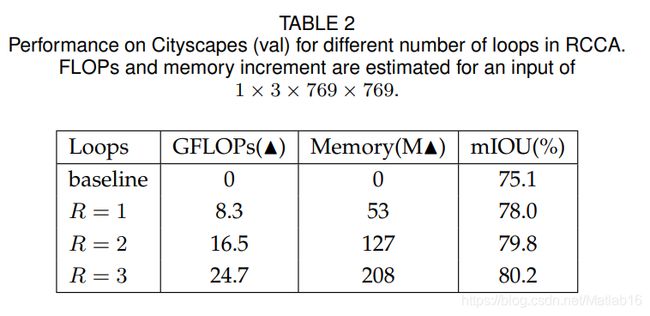
CCNet效果一览
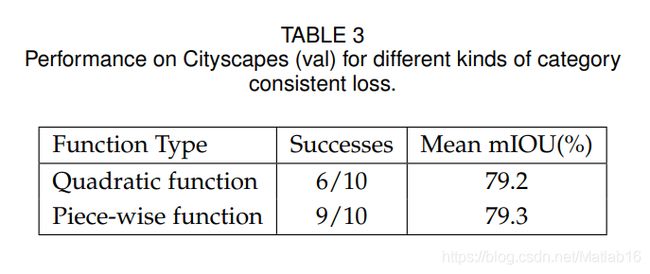



写在文章末尾
CCNet的理论部分就写到这里吧,接下来我会研究CCNet的具体代码实现和一些CCNet我尚未彻底弄懂的问题。等这些工作完成后,我再来完善本篇笔记。