(三)目标检测之 R-CNN系列
目标检测之 R-CNN系列
-
- 前言
- R-CNN系列
-
- 一、[R-CNN](https://arxiv.org/abs/1311.2524)
- 二、 [Fast R-CNN](https://arxiv.org/abs/1504.08083)
- 三、[Faster R-CNN](https://arxiv.org/abs/1506.01497)
- 四、 [Mask R-CNN](https://arxiv.org/abs/1703.06870)
- FPN
- 参考资料
前言
目标检测:找出图像中所有感兴趣的物体,包含物体定位和物体分类两个子任务,即同时确定物体的类别和位置。

目标检测的三个著名的数据集是PASCAL VOC,ImageNet和微软COCO。 PASCAL VOC包含20个物体的类别,而ImageNet包含一千多种物体类别, COCO有80个物体类别和150万个物体实例。
算法基本流程:

-
候选框:这一步是为了对目标的位置进行定位。由于目标可能出现在图像的任何位置,而且目标的大小、长宽比例也不确定,所以最初采用滑动窗口的策略对整幅图像进行遍历,而且需要设置不同的尺度,不同的长宽比。这种穷举的策略虽然包含了目标所有可能出现的位置,但是缺点也是显而易见的:时间复杂度太高,产生冗余窗口太多,这也严重影响后续特征提取和分类的速度和性能。
-
特 征 提 取 = { 底 层 特 征 : 颜 色 、 纹 理 、 形 状 中 层 特 征 : P C A 、 L D A 高 层 特 征 : 对 底 层 和 中 层 特 征 进 一 步 挖 掘 、 表 示 特征提取=\left\{ \begin{aligned} &底层特征:颜色、纹理、形状\\ &中层特征:PCA、LDA\\ &高层特征:对底层和中层特征进一步挖掘、表示 \end{aligned} \right. 特征提取=⎩⎪⎨⎪⎧底层特征:颜色、纹理、形状中层特征:PCA、LDA高层特征:对底层和中层特征进一步挖掘、表示
-
分类器:根据提取到的特征对目标进行分类,分类器主要有 SVM,AdaBoost 等
-
NMS:非极大值抑制,计算置信度,进行候选框的合并、过滤,寻找最佳物体检测位置
传统算法的缺点:一个是基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余;二是手工设计的特征对于多样性的变化并没有很好的鲁棒性。
基于深度学习的目标检测算法主要分为两类:
1.Two stage目标检测算法
先进行区域生成(region proposal,一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
任务:特征提取—>生成RP—>分类/定位回归。
常见的two stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等。
2.One stage目标检测算法
不用RP,直接在网络中提取特征来预测物体分类和位置。
任务:特征提取—>分类/定位回归。
常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等。
R-CNN系列
RCNN 解决的是,“为什么不用CNN做detection呢?”
Fast-RCNN 解决的是,“为什么不一起输出bounding box和label呢?”
Faster-RCNN 解决的是,“为什么还要用selective search呢?”
一、R-CNN
创新点:
(1) 使用CNN对候选区域进行特征提取,从经验驱动特征(SIFT、HOG)到数据驱动特征(CNN feature map),提高特征对样本的表示能力。
(2) 采用大样本下(ILSVRC)有监督预训练和小样本(PASCAL)微调(fine-tuning)的方法解决小样本难以训练甚至过拟合等问题。
因为CNN在图像分类任务中的表现很好,可以自动学习特征,一个自然的想法就是让CNN对每个候选区域进行特征提取。于是R-CNN在Selective Search得到的候选区域的基础上,将每个候选区域缩放到一个固定的大小,并且作为AlexNet(ImageNet 2012图像分类竞赛的冠军)的输入,依次对这些区域进行特征提取,然后再使用SVM对各个区域的特征分别进行分类。

步骤解释:
(1) 输入图像
(2) 利用selective search算法在图像中提取2000个左右的region proposal(候选区)
(3) 将每个region proposal缩放(warp)成227×227的大小并输入到CNN,将CNN的fc7层的输出作为特征
(4) 将每个region proposal提取到的CNN特征输入到SVM,对对象和背景进行分类

训练流程:
-
预训练模型。选择一个预训练 (pre-trained)神经网络(如AlexNet、VGG)
-
重新训练全连接层。使用需要检测的目标重新训练(re-train)最后的全连接层(connected layer)
-
提取 proposals并计算CNN 特征。利用选择性搜索(Selective Search)算法提取所有proposals,调整(resize/warp)它们成固定大小,以满足 CNN输入要求(因为全连接层的限制),然后将feature map 保存到本地磁盘
-
训练SVM。利用feature map 训练SVM来对目标和背景进行分类(每个类一个二分类SVM)
-
边界框回归(Bounding boxes Regression)。对于SVM分好类的region proposal做边框回归(bounding-box regression)。Slelective Search得到的候选区域并不一定与目标物体的真实边界相吻合,如果region proposal跟目标位置偏移较大,即便是分类正确了,但是由于IoU(region proposal与Ground Truth的窗口的交集比并集的比值)低于0.5,那么相当于目标还是没有检测到。因此R-CNN提出对物体的边界框做进一步的调整,使用线性回归来预测一个候选区域中物体的真实边界。该回归器的输入就是候选区域的特征,而输出是边界框的坐标。
总结
R-CNN的效果很不错,在PASCAL VOC2007上的检测结果从DPM HSC的34.3%直接提升到了66%(mAP)。如此大的提升使我们看到了region proposal+CNN的巨大优势。
R-CNN存在的问题:
(1) 候选区域的生成是一个耗时的过程
(2) 对候选区域特征提取需要在单张图像上使用AlexNet 2000多次
(3) 特征提取、图像分类、边框回归是三个独立的步骤,要分别进行训练,步骤繁琐。
(4) 训练占用磁盘空间大,5000张图像产生几百G的特征文件,处理图像速度慢,使用GPU, VGG16模型处理一张图像需要47s
二、 Fast R-CNN
创新点:
-
只对整幅图像进行一次特征提取,避免R-CNN中的冗余特征提取
-
用RoI pooling层替换最后一层的max pooling层
-
损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练,实现了end-to-end的多任务训练(候选框提取除外),也不需要额外的特征存储空间(R-CNN中的特征需要保持到本地,来供SVM和Bounding-box regression进行训练)
-
采用SVD对Fast R-CNN网络末尾并行的全连接层进行分解,减少计算复杂度,加快检测速度。在实现时,相当于把一个全连接层拆分为两个全连接层,第一个全连接层不含偏置,第二个全连接层含偏置

RoI Pooling层
RoI Pooling 是Pooling层的一种,而且是针对RoI的Pooling,其特点是输入特征图尺寸不固定,但是输出特征图尺寸固定(如7x7)。由于ROI Pooling可接受任意尺寸的输入,warp操作不再需要,这有效避免了物体的形变扭曲,保证了特征信息的真实性。
RoI
RoI是Region of Interest的简写,一般是指图像上的区域框,但这里指的是由Selective Search提取的候选框。

在R-CNN中,一张图像上要使用AlexNet 2000多次来分别得到各个区域的特征,但很多区域都是重合的。为了避免这些重复计算,只在一张图像上使用一次AlexNet,然后再得到不同区域的特征,Fast R-CNN提出了一个方法:
先对输入图像使用一次CNN前向计算,得到整个图像的特征图,再在这个特征图中分别提取各个候选区域的特征。由于候选区域的大小不一样,而对应的特征需要具有固定的大小,因此该方法对各个候选区域分别使用ROI Pooling, 其做法是:
假设第 i i i 个候选区域ROI的大小为 h i × w i h_{i}\times {w_i} hi×wi, 要使输出的大小为 h × w h\times w h×w,那么就将该区域分成 h × w h\times w h×w个格子,每一个格子的大小为 ( h i / h ) × ( w i / w ) (h_i/h)\times (w_i/w) (hi/h)×(wi/w), 然后对每一格子使用max-pooling得到大小为 h × w h\times w h×w的特征图像。
多任务损失函数
在 R-CNN中特征提取、图像分类、边框回归是三个独立的步骤,要分别进行训练,步骤繁琐。Fast R-CNN把之前独立的三个步骤放到一个统一的网络结构中。该网络结构同时预测一个候选区域的物体类别和该物体的边界框,将这两个任务进行同时训练,变成一个multi-task的模型,实现了特征的共享与速度的进一步提升。
总结
Fast R-CNN 采用了多项创新来提高训练和测试速度,同时提高检测精度。Fast R-CNN 训练VGG16 网络比 R-CNN 快 9 倍,在测试图像上的处理时间比R-CNN快 213 倍,并在 PASCAL VOC 2012 上实现更高的 MAP。与 SPPnet 相比,Fast R-CNN 训练 VGG16 的速度快 3 倍,测试速度快 10 倍,并且更准确。
如果不考虑生成候选区域的时间,可以达到实时检测。生成候选区域的Selective Search算法处理一张图像大概需要2s的时间,因此成为该方法的一个瓶颈。
三、Faster R-CNN
创新点
-
设计了RPN(Region Proposal Networks),利用CNN卷积操作后的特征图生成region proposals,代替了Selective Search、EdgeBoxes等方法,速度上提升明显;
-
训练 RPN与检测网络(Fast R-CNN)共享卷积层,大幅提高网络的检测速度。
上面两种方法都依赖于Selective Search生成候选区域,十分耗时。考虑到CNN如此强大,Faster R-CNN提出使用CNN来得到候选区域(region proposal)。
假设有两个卷积神经网络,一个是区域生成网络,得到图像中的各个候选区域,另一个是候选区域的分类和边框回归网络。这两个网络的前几层都要计算卷积,如果让它们在这几层共享参数,只是在末尾的几层分别实现各自的特定的目标任务,那么对一幅图像只需用这几个共享的卷积层进行一次前向卷积计算,就能同时得到候选区域和各候选区域的类别及边框。

四个损失函数:
• RPN calssification(object yes or no)
• RPN regression(anchor—>propoasal)
• Fast R-CNN classification(over classes)
• Fast R-CNN regression(proposal —>box)
Faster RCNN步骤:
(1) 输入图像到卷积网络中,生成特征图像
(2) 在特征图像上应用Region Proposal Network,返回object proposals和相应socres,并采用NMS算法对scores进行筛选将得分高的前 N N N个候选框输入ROI pooling层;
(3) 使用Rol pooling,将所有proposals修正到同样尺寸
(4) 将proposals传递到全连接层,对目标进行分类并预测边界框
RPN
候选区域生成网络(Region Proposal Network, RPN)的核心思想是使用卷积神经网络直接产生region proposal,使用的方法本质上就是滑动窗口。RPN的设计比较巧妙,RPN只需在最后的卷积层上滑动一遍,通过anchor机制和边框回归可以得到多尺度、多长宽比的region proposal。滑动窗口的位置提供了物体的大体位置信息,框的回归提供了框更精确的位置。


RPN网络首先经过3x3卷积,然后分为2条线,上面一条通过softmax分类anchors获得positive和negative分类,下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接层和softmax网络作classification(即分类proposal到底是什么object)
Anchor
一张图片里面有远近、大小、尺度的不同,对于目标检测任务的准确度至关重要,于是我们引入了一个 Anchor 的概念。
Anchor boxes是固定尺寸的边界框,它们有不同的形状和大小。对每个anchor,RPN都会预测两点:
(1)anchor就是目标物体的概率(不考虑类别)
(2)anchor经过调整能更合适目标物体的边界框回归量
RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
从上图可以知道现有的三种解决尺度不同的办法:缩放图片、多尺度卷积核以及 Anchor 方法。
生成多种尺寸的图片势必会增加大量的训练量,训练时间扩展到原来的三倍;多尺寸卷积核势必会增多参数量,从而减缓训练而预测速度。那么前两种方法不可取,只有最后一种 Anchor 方法——不增加额外的参数量,在每个滑窗里面采集不同尺寸 Anchor 视野的特征。
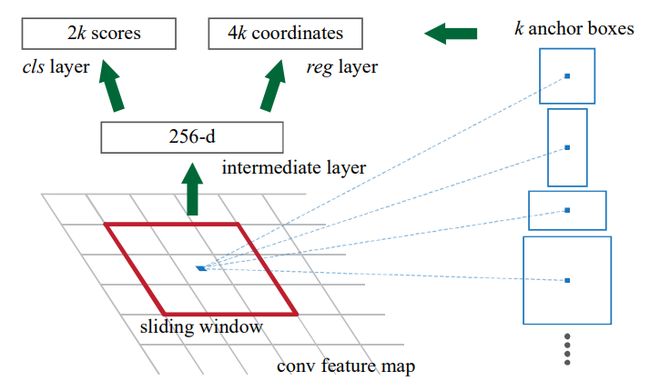
以 3 × 3 3\times 3 3×3 卷积为例,我们在卷积神经网络最后一个卷积层输出的 feature maps 进行滑窗,每滑窗一次就在视野中获取 k 个尺寸的特征,在本文中使用了 3 种大小(128,256,512)和 3 种长宽比(1:1,1:2,2:1),共 9 种尺寸的 Anchor 。

对于一张卷积过后尺寸为 W × H W\times H W×H 的 feature map 而言,约有 W H k WHk WHk 个 anchors,我们将这些 anchors 的 256d 特征再分别通过两个 1x1 卷积层,最后分别塞入 softmax 和 Bbox Reg 层。
其中,每个 anchor 送入 softmax 层会得到两个分数(概率),分别是前景的概率和背景的概率;每个 anchor 还会生成 4 个数,代表着 anchor 的平移和缩放参数。
使用RPN得到候选区域后,对候选区域的分类和边框回归仍然使用Fast R-CNN。这两个网络使用共同的卷积层。 由于Fast R-CNN的训练过程中需要使用固定的候选区域生成方法,不能同时对RPN和Fast R-CNN使用反向传播算法进行训练。论文中作者描述了交替训练、近似联合训练和联合训练三种方法。
交替训练
(1) 训练 RPN 网络,采用 ImageNet 预训练的模型进行初始化,并进行微调
(2) 利用 (1) 的RPN生成 proposal,由 Fast R-CNN 训练一个单独的检测网络,该网络同样由ImageNet预训练模型进行初始化。此时,两个网络还未共享卷积层
(3) 用检测网络初始化 RPN 训练,固定共享的卷积层,只微调 RPN 独有的层,现在两个网络实现了卷积层共享
(4) 保持共享的卷积层固定,微调 Fast R-CNN 的 fc 层。这样,两个网络共享相同的卷积层,构成一个统一的网络
总结
Faster R-CNN的精度和Fast R-CNN差不多,但是训练时间和测试时间都缩短了10倍。
上述讨论过的所有对象检测算法都使用区域来识别对象,且网络不会一次查看完整图像,而是按顺序关注图像的某些部分,这样会带来两个复杂性的问题:
- 该算法需要让单张图像经过多个步骤才能提取出所有目标
- 由于不是端到端的算法,多个步骤嵌套,整体系统的性能取决于前面步骤的表现水平

四、 Mask R-CNN
Mask R-CNN有哪些创新点?
- RoI Align替换RoI Pooling,解决了mask的偏移问题。同时对检测性能也有提升
- mask:每类单独产生一个mask,依靠class分支获取类别标签。 将掩模预测和分类预测拆解,没有引入类间竞争,从而大幅提高了性能。
Mask R-CNN是一个实例分割(Instance segmentation)算法,通过在Faster R-CNN基础上添加了一个用于预测目标掩模的新分支(mask branch), 在没有增加太多计算量,且没有使用各种trick的前提下,在COCO的一系列挑战任务中都取得了领先的结果。

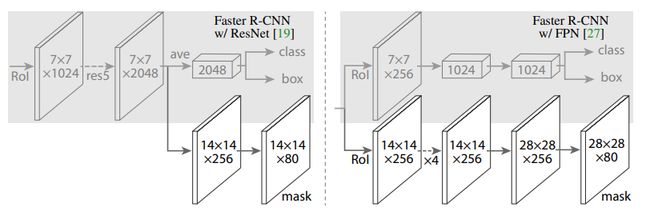
Mask R-CNN算法步骤
- 输入一幅图片,然后进行对应的预处理操作;
- 将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
- 对这个feature map中的每一点设定预定个的RoI,从而获得多个候选RoI;
- 将这些候选的RoI送入RPN网络进行二值分类(前景或背景)和 边框回归,过滤掉一部分候选的RoI;
- 对这些剩下的RoI进行RoI Align操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
- 对这些RoI进行分类(N类别分类)、BB回归和MASK生成(在每一个RoI里面进行FCN操作)。
ROI Align
在 Mask R-CNN 中提出了ROI Align,实践发现ROI Align 比ROI Pooling 的效果要好。
- ROI Pooling: x = [ x / S ] + 1 x = [x/S] + 1 x=[x/S]+1
- ROI Align: x = x / S x = x/S x=x/S
前者使用 [] 对结果进行了取整,损失了小数点,而后者保留了小数点。卷积后 feature map 的 1 个点代表着原图的 S S S个点。以 S = 16 S=16 S=16为例,假设目标框 x = 600 x=600 x=600,转换到卷积后就是 600 / 16 = 37.5 600/16 = 37.5 600/16=37.5,卷积后 feature map 差 0.5 意味着原图差 8。
从数字上理解,ROI Align 保留了更多的信息,减少了卷积前和卷积后的位置误差,允许了 pixel-to-piexl 的训练和预测。
操作
取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。在具体的算法操作上,RoI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程,如下图所示:
-
遍历每一个候选区域,保持浮点数边界不做量化。
-
将候选区域分割成 k × k k\times k k×k个单元,每个单元的边界也不做量化。
-
在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。

FPN
特征图金字塔网络FPN(Feature Pyramid Networks)是2017年提出的一种网络,FPN主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体(small object)检测的性能。
创新点
- 多层特征
- 特征融合
在物体检测里面,有限计算量情况下,网络的深度(对应到感受野)与 stride 通常是一对矛盾的东西,常用的网络结构对应的 stride 一般会比较大(如 32),而图像中的小物体甚至会小于 stride 的大小,造成的结果就是小物体的检测性能急剧下降。
传统解决这个问题的思路包括:
- 图像金字塔(image pyramid),即多尺度训练和测试。但该方法计算量大,耗时较久。
- 特征分层,即每层分别预测对应的scale分辨率的检测结果,如SSD算法。该方法强行让不同层学习同样的语义信息,但实际上不同深度对应于不同层次的语义特征,浅层网络分辨率高,学到更多是细节特征,深层网络分辨率低,学到更多是语义特征。
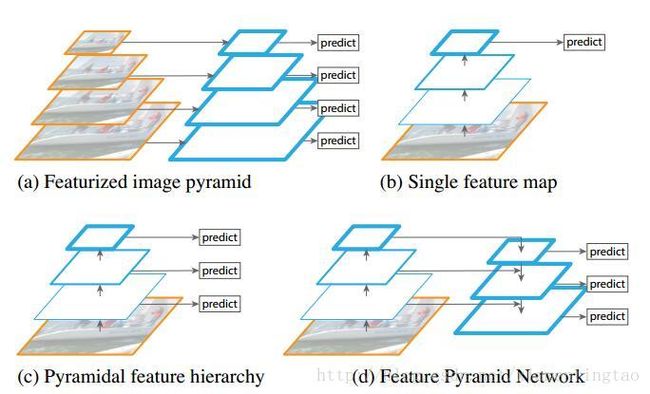
FPN算法主要由三个模块组成,分别是:
- 自底向上,骨干网络,以卷积和降采样的方式提取特征
- 自顶向下,上采样深层粗粒度特征,提高深层特征的分辨率
- 横向连接,采用1×1的卷积核进行连接(减少特征图数量),融合浅层特征和深层特征

Faster R-CNN with FPN

作者实验了将 FPN 应用在 Faster RCNN 上的性能,在 COCO 上达到了 state-of-the-art 的单模型精度。在RPN上,FPN增加了8.0个点的平均召回率(average recall,AR);在后面目标检测上,对于COCO数据集,FPN增加了2.3个点的平均精确率(average precision,AP),对于VOC数据集,FPN增加了3.8个点的AP。
参考资料
- 一文读懂Faster RCNN
- 图像目标检测技术进展
- 目标检测
- 一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
- 目标检测:Mask R-CNN 论文阅读
- Feature Pyramid Networks for Object Detection 总结
- RPN 解析
- 高分辨率遥感图像目标检测和场景分类研究进展
- 常见特征金字塔网络FPN及变体