import csv
filename = 'sitka_weather_07-2018_simple.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
print(header_row)
['STATION', 'NAME', 'DATE', 'PRCP', 'TAVG', 'TMAX', 'TMIN']
with open(filename) as f:打开一个文件,并将结果文件存储在f中。- 调用
csv.reader(),并将前面存储的文件对象作为实参传给它,从而创建一个与改文件相关联的阅读器(reader)对象。
- csv模块包含函数
next(),调用它并将阅读器对象传递给它时,它将返回文件的下一行。这里只调用了一次,所以返回的是文件的第一行
import csv
filename = 'sitka_weather_07-2018_simple.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
for index, column_header in enumerate(header_row):
print(index, column_header)
0 STATION
1 NAME
2 DATE
3 PRCP
4 TAVG
5 TMAX
6 TMIN
enumerate()函数来获取每个元素的索引及其值,分别赋值给index和column_header
import csv
filename = 'sitka_weather_07-2018_simple.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
highs = []
for row in reader:
highs.append(int(row[5]))
print(highs)
[62, 58, 70, 70, 67, 59, 58, 62, 66, 59, 56, 63, 65, 58, 56, 59, 64, 60, 60, 61, 65, 65, 63, 59, 64, 65, 68, 66, 64, 67, 65]
- 阅读器对象从其停留的地方继续向下读取CSV文件,每次都自动返回当前所处位置的下一行。由于我们已经读取了文件头行,这个循环将从第二行开始。
- 将每一行的第5号列的值转换为int型数字存储在highs列表中,即最高温度
import matplotlib.pyplot as plt
fig = plt.figure(dpi = 128, figsize = (10, 6))
plt.plot(highs, c = 'red')
plt.title("Daily high temperatures, July 2018", fontsize = 24)
plt.xlabel('', fontsize = 16)
plt.ylabel("Temperature(F)", fontsize = 16)
plt.tick_params(axis = 'both', which = 'major', labelsize = 16)
plt.show()
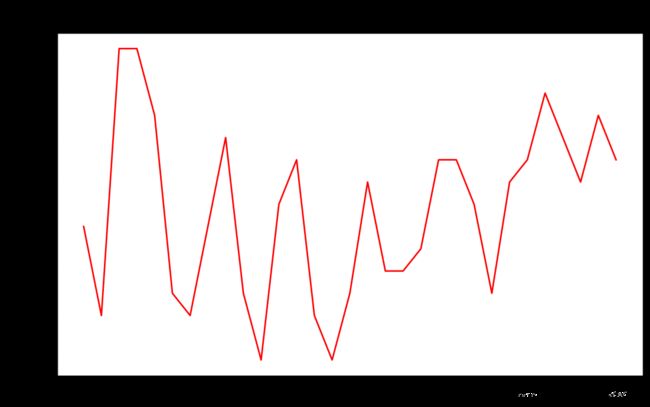
下面在图表中添加日期
import csv
from datetime import datetime
import matplotlib.pyplot as plt
filename = 'sitka_weather_2018_full.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs = [], []
for row in reader:
if row[8] == '':
continue
current_date = datetime.strptime(row[2], "%Y-%m-%d")
dates.append(current_date)
highs.append(int(row[8]))
fig = plt.figure(dpi = 128, figsize = (10, 6))
plt.plot(dates, highs, c = 'red')
plt.title("Daily high temperatures - 2018", fontsize = 24)
plt.xlabel('', fontsize = 16)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)", fontsize = 16)
plt.tick_params(axis = 'both', which = 'major', labelsize = 16)
plt.show()
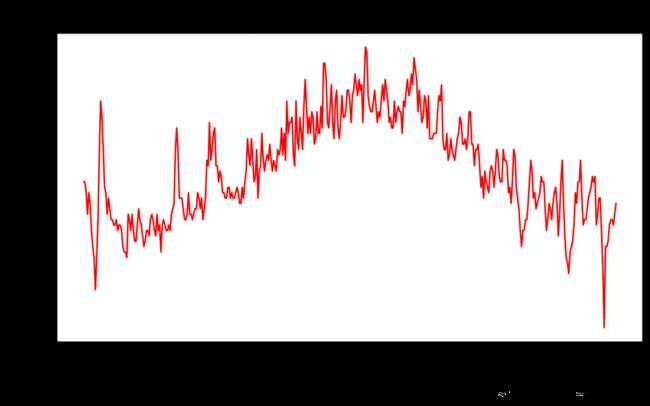
- 在图形中添加日期并且使用全年的气温数据
- 在读取最高气温的时候出现了问题,原因是有全年气温数据中有一行没有记录气温值,也就是row[8]这一栏不全是数字,有一格是空白的,这就导致
int(row[8])语句错误。于是在前面添加一条判断语句当有空白数据时跳过。注意这个判断语句要添加在for循环的开头,假如当天的气温未记录,那么这一天的日期也不应该读取,否则会导致日期数据数量比气温数据数量多(因为只跳过了气温数据,这一天的日期数据是能读到的)
import csv
from datetime import datetime
import matplotlib.pyplot as plt
filename = 'sitka_weather_2018_full.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs, lows = [], [], []
for row in reader:
if row[8] == '':
continue
current_date = datetime.strptime(row[2], "%Y-%m-%d")
dates.append(current_date)
highs.append(int(row[8]))
lows.append(int(row[9]))
fig = plt.figure(dpi = 128, figsize = (10, 6))
plt.plot(dates, highs, c = 'red')
plt.plot(dates, lows, c = 'blue')
plt.title("Daily high and low temperatures - 2018", fontsize = 24)
plt.xlabel('', fontsize = 16)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)", fontsize = 16)
plt.tick_params(axis = 'both', which = 'major', labelsize = 16)
plt.show()
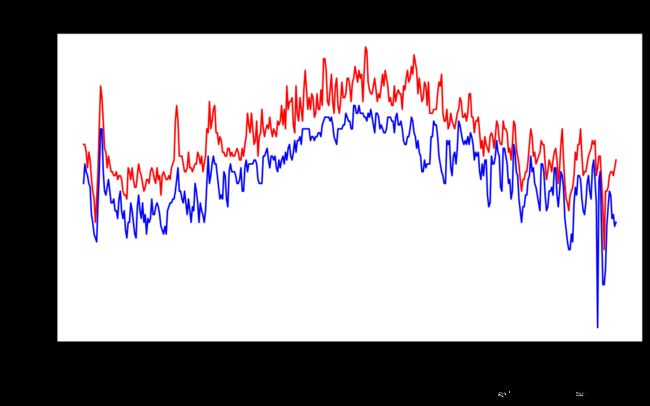
fig = plt.figure(dpi = 128, figsize = (10, 6))
plt.plot(dates, highs, c = 'red')
plt.plot(dates, lows, c = 'blue')
plt.plot(dates, highs, c = 'red', alpha = 0.5)
plt.plot(dates, lows, c = 'blue', alpha = 0.5)
plt.fill_between(dates, highs, lows, facecolor = 'blue', alpha = 0.1)
plt.title("Daily high and low temperatures - 2018", fontsize = 24)
plt.xlabel('', fontsize = 16)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)", fontsize = 16)
plt.tick_params(axis = 'both', which = 'major', labelsize = 16)
plt.show()
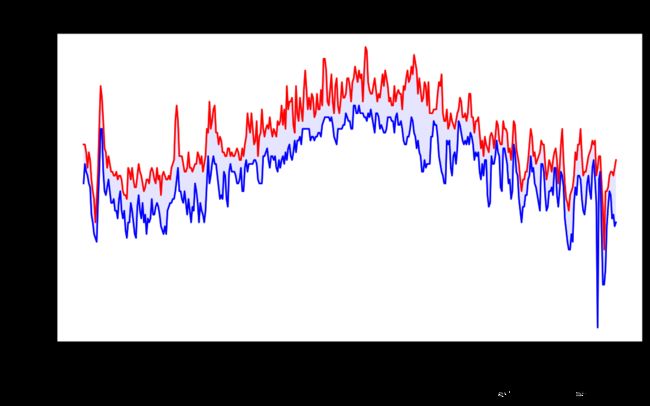
- 在最高温和最低温曲线之间填充色彩。使用方法
fill_between(),它接收一个x值系列和两个y值系列,并填充两个y值系列之间的空间
- 实参alpha制定颜色的透明度。alpha为0表示完全透明,1表示完全不透明。
- 实参facecolor指定填充区的颜色