论文笔记:WWW 2018 Variational Autoencoders for Collaborative Filtering
前言
论文链接:https://export.arxiv.org/pdf/1802.05814
github:https://github.com/dawenl/vae_cf
本文主要提出将变分自动编码器 variational autoencoders (vaes) 引入到协同过滤任务中,作者认为这种非线性概率模型可以超越线性因素模型有限的建模能力,同时线性因素模型在很大程度上主导着协同过滤。基于此,作者引入了一个多项式似然生成模型,并利用贝叶斯推理进行参数估计。尽管多项式似然在语言建模和经济学中得到了广泛的应用,但在推荐系统的研究中却很少受到关注。
1. Bag-of-words
Bag-of-words模型是信息检索领域常用的文档表示方法。
在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。(是不关顺序的)
也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。那么到底是什么意思呢?那么给出具体的例子说明:
Wikipedia[1]上给出了如下例子:
John likes to watch movies. Mary likes too.
John also likes to watch football games.
根据上述两句话中出现的单词, 我们能构建出一个字典 (dictionary):
{“John”: 1, “likes”: 2, “to”: 3, “watch”: 4, “movies”: 5, “also”: 6, “football”: 7, “games”: 8, “Mary”: 9, “too”: 10}
该字典中包含10个单词, 每个单词有唯一索引, 注意它们的顺序和出现在句子中的顺序没有关联. 根据这个字典, 我们能将上述两句话重新表达为下述两个向量:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
这两个向量共包含10个元素, 其中第 i i i 个元素表示字典中第 i i i 个单词在句子中出现的次数. 因此BOW模型可认为是一种统计直方图 (histogram). 在文本检索和处理应用中, 可以通过该模型很方便的计算词频.
但是从上面我们也能够看出,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序(这也是bag of words的一个缺点,很多情况简单的用bow特征产生的结果就比较好了)
适用场景
现在想象在一个巨大的文档集合 D D D,里面一共有 M M M 个文档,而文档里面的所有单词提取出来后,一起构成一个包含 N N N 个单词的词典,利用Bag-of-words模型,每个文档都可以被表示成为一个N维向量。
变为 N N N 维向量之后,很多问题就变得非常好解了,计算机非常擅长于处理数值向量,我们可以通过余弦来求两个文档之间的相似度,也可以将这个向量作为特征向量送入分类器进行主题分类等一系列功能中去。
总之通过有效的办法转换为向量之后,后面的一切都变得明朗起来了,因为至少得想办法让计算机理解。
2. Method
在本文中分别使用 u ∈ { 1 , … , U } u \in\{1,\dots,U\} u∈{1,…,U} 和 i ∈ { 1 , … , I } i \in\{1,\dots,I\} i∈{1,…,I} 代表用户集合和物品集合。其中用户恶化物品的交互矩阵为点击矩阵 X ∈ N U × I \mathbf{X}\in\mathbb{N}^{U\times I} X∈NU×I。值得注意的是 x u = [ x u 1 , … , x u I ] T ∈ N I \mathbf{x}_u=[x_{u1},\dots,x_{uI}]^T \in \mathbb{N}^I xu=[xu1,…,xuI]T∈NI,其中内容为每一个物品对于用户点击的次数的BOW向量。
2.1 Model
对于每一个用户 u u u,模型首先通过标准的高斯分布采样一个 K 维的潜在表示 z u \mathbf{z}_u zu。之后这个潜在表示 z u \mathbf{z}_u zu 通过一个非线性激活函数 f θ ( ⋅ ) f_{\theta}(\cdot) fθ(⋅) 转换成 π ( z u ) ∈ R I \pi(\mathbf{z}_u) \in \mathbb{R}^I π(zu)∈RI 来得到 I I I 的概率分布。点击历史 x u \mathbf{x}_u xu 的预测可以通过如下公式计算得到:
z u ∼ N ( 0 , I K ) , π ( z u ) ∝ e x p { f θ ( z u ) } , x u ∼ M u l t ( N u , π ( z u ) ) (1) z_u \sim\mathcal{N}(0,\mathbf{I}_K),\\\pi(\mathbf{z}_u) ∝exp\{f_{\theta}(\mathbf{z}_u)\},\\\mathbf{x}_u\sim Mult(N_u,\pi(\mathbf{z}_u)) \tag{1} zu∼N(0,IK),π(zu)∝exp{fθ(zu)},xu∼Mult(Nu,π(zu))(1)
其中 非线性激活函数 f θ ( ⋅ ) f_{\theta}(\cdot) fθ(⋅) 是以 θ \theta θ 为参数的多层感知机。该多层感知机的输出经过一个 softmax 函数得到概率向量 π ( z u ) ∈ S I − 1 \pi(\mathbf{z}_u) \in\mathbb{S}^{I-1} π(zu)∈SI−1。其中 N u = ∑ i x u i N_u=\sum_ix_{ui} Nu=∑ixui 是用户 u u u 所有点击次数的综合。基于 N u N_u Nu 和 π ( z u ) \pi(\mathbf{z}_u) π(zu) ,可以通过从多项式 π ( z u ) \pi(\mathbf{z}_u) π(zu) 中进行抽样得到 BOW 向量 x u \mathbf{x}_u xu。该生成模型对潜在因子模型进行了推广,通过将 f θ ( ⋅ ) f_{\theta}(\cdot) fθ(⋅)设为线性且使用高斯似然,就是经典的矩阵分解模型。
用户 u u u 的对数似然(以潜在表示为条件)为:
l o g p θ ( x u ∣ z u ) = ∑ i x u i l o g π i ( z u ) (2) log\mathcal{p}_{\theta}(\mathbf{x}_u|\mathbf{z}_u)=\sum_ix_{ui}log\pi_{i}(\mathbf{z}_u)\tag{2} logpθ(xu∣zu)=i∑xuilogπi(zu)(2)
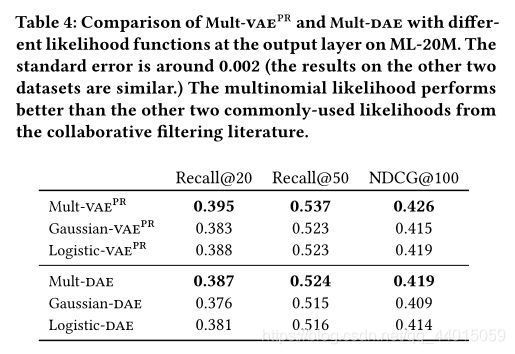
该多项式似然常用于语言模型,如狄利克雷分布和经济学模型。它还被用于多类分类的交叉熵损失。例如,它已被用于基于会话的顺序推荐的递归神经网络。多项似然在诸如矩阵分解和自编码器等潜在因子模型的背景下研究得较少。本文的出发点是相信多项式分布很适合建模点击数据。点击矩阵(Eq. 2)的可能性奖励在 x u x_u xu 的非零条目上,并且存在一定的局限性,因为 π ( z u ) \pi(z_u) π(zu) 必须为1。因此,该模型应该为更有可能被点击的项目分配更多的概率质量。在一定程度上,它适用于 top-N 。通过比较,我们提出了两种常用的似然函数用于潜在因素协同过滤:高斯似然和逻辑似然。首先定义生成模型 f θ ( ⋅ ) f_{\theta}(\cdot) fθ(⋅) 的输出 f θ ( z u ) = [ f u 1 , … , f u I ] T f_{\theta}(\mathbf{z}_u)=[f_{u1},\dots,f_{uI}]^T fθ(zu)=[fu1,…,fuI]T。对于用户 u u u 的高斯对数似然为:
l o g p θ ( x u ∣ z u ) = − ∑ i c u i 2 ( x u i − f u i ) 2 (3) logp_{\theta}(\mathbf{x}_u|\mathbf{z}_u)=-\sum_i\frac{c_{ui}}{2}(x_{ui}-f_{ui})^2\tag{3} logpθ(xu∣zu)=−i∑2cui(xui−fui)2(3)
本文引入一个“置信”权重 c x u i = c u i c_{x_{ui}}=c_{ui} cxui=cui,其中 c 1 > c 0 c_1 \gt c_0 c1>c0 来平衡点击数据中未观察到的0。这也等价于用非加权高斯似然和负抽样训练模型。用户 u u u 的逻辑对数似然为:
l o g p θ ( x u ∣ z u ) = ∑ i x u i l o g σ ( f u i ) + ( 1 − x u i ) l o g ( 1 − σ ( f u i ) ) (4) logp_{\theta}(\mathbf{x}_u|\mathbf{z}_u)=\sum_ix_{ui}log\sigma(f_{ui})+(1-x_{ui})log(1-\sigma(f_{ui})) \tag{4} logpθ(xu∣zu)=i∑xuilogσ(fui)+(1−xui)log(1−σ(fui))(4)
其中 σ ( x ) = 1 / ( 1 + e x p ( − x ) ) \sigma(x) = 1 /(1 + exp(−x)) σ(x)=1/(1+exp(−x)) 是logistic函数。在后文中将多项式似然与高斯似然以及逻辑似然进行了对比。
2.2 Variational inference ( M u l t − V A E P R Mult-VAE^{PR} Mult−VAEPR)
为了学习Eq. 1中的生成模型,来估计 θ \theta θ ( f θ ( ⋅ ) f_{\theta}(\cdot) fθ(⋅)的参数)。为此需要近似每个数据点的后验分布 p ( z u ∣ x u ) p(\mathbf{z}_u | \mathbf{x}_u) p(zu∣xu)。本文采用变分推理。变分推理用一种更简单的变分近似来估计真正的后验:
q ( z u ) = N ( μ u , d i a g { σ u 2 } ) q(\mathbf{z}_u)=\mathcal{N}(\mu_u,diag\{\sigma^2_u\}) q(zu)=N(μu,diag{σu2})
变分推理的目的是优化自由变分参数 { μ μ , σ u 2 } \{\mu_{\mu},\sigma^2_u\} {μμ,σu2},使KL散度 K L ( q ( z u ) ∥ p ( z u ∣ x u ) KL(q(\mathbf{z}_u)∥p(\mathbf{z}_u |\mathbf{x}_u) KL(q(zu)∥p(zu∣xu)最小。
2.2.1 Amortized inference and the variational autoencoder
随着用户和物品的数量增多,用来优化 { μ u , σ u 2 } \{\mu_u,\sigma_u^2\} {μu,σu2} 的参数量大大增加,这可能成为拥有数百万用户和项目的商业推荐系统的瓶颈。变分自编码器(vae)用一个依赖数据的函数(通常称为推理模型)替换单个变分参数:
g ϕ ( x u ) = [ μ ϕ ( x u ) , σ ϕ ( x u ) ] ∈ R 2 K g_{\phi}(\mathbf{x}_u)=[\mu_{\phi}(\mathbf{x}_u),\sigma_{\phi}(\mathbf{x}_u)] \in \mathbb{R}^{2K} gϕ(xu)=[μϕ(xu),σϕ(xu)]∈R2K
其中 μ ϕ ( x u ) , σ ϕ ( x u ) \mu_{\phi}(\mathbf{x}_u),\sigma_{\phi}(\mathbf{x}_u) μϕ(xu),σϕ(xu) 的维度均为 K K K。因此我们得到近似估计的表示形式为:
q ϕ ( z u ∣ x u ) = N ( μ ϕ ( x u ) , d i a g { σ ϕ 2 ( x u ) } ) q_{\phi}(\mathbf{z}_u|\mathbf{x}_u)=\mathcal{N}(\mu_{\phi}(\mathbf{x}_u),diag\{\sigma^2_{\phi}(\mathbf{x}_u)\}) qϕ(zu∣xu)=N(μϕ(xu),diag{σϕ2(xu)})
即推理模型以观测数据 x u \mathbf{x}_u xu 作为输入,输出相应的变分分布 q ϕ ( z u ∣ x u ) q_\phi(\mathbf{z}_u | \mathbf{x}_u) qϕ(zu∣xu) 的变分参数,优化后期望近似于 p ( z u ∣ x u ) p(\mathbf{z}_u | \mathbf{x}_u) p(zu∣xu)。在图2c中将 q ϕ ( z u ∣ x u ) q_\phi (\mathbf{z}_u | \mathbf{x}_u) qϕ(zu∣xu) 和生成模型 p θ ( x u ∣ z u ) p_\theta(\mathbf{x}_u | \mathbf{z}_u) pθ(xu∣zu) 放在一起,最终得到了一个类似于自动编码器的体系结构——变分自动编码器。
损失函数:
l o g p ( x u ; θ ) ≥ E q ϕ ( z u ∣ x u ) [ l o g p θ ( x u ∣ z u ) ] − K L ( q ϕ ( z u ∣ x u ) ∣ ∣ p ( z u ) ) = L ( x u ; θ , ϕ ) (5) logp(\mathbf{x}_u;\theta)\geq\mathbb{E}_{q_{\phi}(\mathbf{z}_u|\mathbf{x}_u)}[logp_{\theta}(\mathbf{x}_u|\mathbf{z}_u)]-KL(q_\phi(\mathbf{z}_u|\mathbf{x}_u)||p(\mathbf{z}_u))\\ =\mathcal{L}(\mathbf{x}_u;\theta,\phi) \tag{5} logp(xu;θ)≥Eqϕ(zu∣xu)[logpθ(xu∣zu)]−KL(qϕ(zu∣xu)∣∣p(zu))=L(xu;θ,ϕ)(5)
L ( x u ; θ , ϕ ) \mathcal{L}(\mathbf{x}_u;\theta,\phi) L(xu;θ,ϕ) 通常被称为 evidence lower bound (ELBO) 。ELBO 是 θ \theta θ 和 ϕ \phi ϕ 的函数。可以通过采样 z u ∼ q ϕ z_u \sim q_\phi zu∼qϕ 来获得 ELBO 的无偏估计,并执行随机梯度进行优化。然而不能简单地通过这个采样过程对 ϕ \phi ϕ 取梯度。解决方案是:对 ϵ ∼ N ( 0. I K ) \epsilon \sim \mathcal{N}(0.\mathbf{I}_K) ϵ∼N(0.IK),并且 z u = μ ϕ ( x u ) + ϵ ⊙ σ ϕ ( x u ) \mathbf{z}_u=\mu_{\phi}(\mathbf{x}_u)+\epsilon \odot\sigma_\phi(\mathbf{x}_u) zu=μϕ(xu)+ϵ⊙σϕ(xu)。通过这样做,采样过程中的随机性被隔离,并且 ϕ \phi ϕ 的梯度可以通过采样的 z u z_u zu 反向传播。
训练过程:

2.2.2 Alternative interpretation of ELBO
式(5)中的 ELBO 的第一项可以理解为(负)重构误差,第二项KL可以理解为正则化。进而引入权重参数 β \beta β 调整正则化强度,进而可以表示为
L β ( x u ; θ , μ ) = E q ϕ ( z u ∣ x u ) [ l o g p θ ( x u ∣ z u ) ] − β ⋅ K L ( q ϕ ( z u ∣ x u ) ∣ ∣ p ( z u ) ) (6) \mathcal{L}_\beta(\mathbf{x}_u;\theta,\mu)=\mathbb{E}_{q_{\phi}(\mathbf{z}_u|\mathbf{x}_u)}[logp_{\theta}(\mathbf{x}_u|\mathbf{z}_u)]-\beta \cdot KL(q_\phi(\mathbf{z}_u|\mathbf{x}_u)||p(\mathbf{z}_u)) \tag{6} Lβ(xu;θ,μ)=Eqϕ(zu∣xu)[logpθ(xu∣zu)]−β⋅KL(qϕ(zu∣xu)∣∣p(zu))(6)
通过引入权重参数 β \beta β 可以更好的拟合数据。如果 β < 1 \beta \lt 1 β<1,相当于削弱先验约束的影响,相当于 1 U ∑ u q ( z ∣ x u ) ≈ p ( z ) = N ( z ; 0 ; I k ) \frac{1}{U}\sum_uq(\mathbf{z}|\mathbf{x}_u)\approx p(\mathbf{z})=\mathcal{N}(\mathbf{z};0;\mathbf{I}_k) U1∑uq(z∣xu)≈p(z)=N(z;0;Ik),这意味着该模型不太能够通过原始的抽样来生成新的用户历史记录。
但最终我们的目标是做出好的推荐,而不是最大化可能性或生成想象中的用户历史。因此,将 β \beta β 作为自由正则化参数处理并产生显著的性能改进。对于超参 β \beta β 的选择,作者提出了一个简单的启发式方法:开始训练时设置 β = 0 \beta = 0 β=0,并逐渐增加 β \beta β 到1。线性退火 KL 项缓慢更新 θ \theta θ, ϕ \phi ϕ 和记录最佳 β \beta β 时,其性能达到峰值。该方法不需要对不同 β \beta β 值的多模型进行训练,这是一种训练 VAE 模型的启发式算法。
识别出基于峰值验证度量的最佳 β \beta β,我们可以用相同的退火方法重新训练模型,但在达到该值后停止增加 β \beta β(如图1中的红点虚线所示)。作者将这种部分正则化的 vae 用多项似然表示为 M u l t − V A E p r Mult - VAE^{pr} Mult−VAEpr。

2.2.3 Computational Burden
之前的神经网络协同过滤模型采用随机梯度下降训练,在每一步中,从点击矩阵中随机抽取单个(用户、项目)条目来执行梯度更新。在算法1中,作者对用户进行子样本,并获取他们的整个点击历史(点击矩阵的完整行)来更新模型参数。这消除了通常用于(用户、项目)条目子抽样方案的负抽样(以及用于选择负示例数量的超参数调优)的必要性。
然而该方法带来的一个计算挑战是,当项目的数量很大时,计算 π ( z u ) \pi(\mathbf{z}_u) π(zu) 的多项概率的计算成本较高,因为它需要为标准化计算所有项目的预测。这是语言建模中常见的挑战,因为词汇表的大小是几百万甚至更多。对于项目较大的数据集中,可以采用前人提出的归一化因子 π ( z u ) \pi(\mathbf{z}_u) π(zu) 在一定程度上解决这个问题。
2.3 A taxonomy of autoencoders ( M u l t − D A E Mult-DAE Mult−DAE)
在第2.2节中介绍了在非线性生成模型下使用近似贝叶斯推理的最大似然边际估计(如式1)。从学习自动编码器的角度来理解此方法。最大似然估计在一个常规的自动编码器中采取以下形式
θ A E , ϕ A E = a r g m a x θ , ϕ ∑ u E δ ( z u − g ϕ ( x u ) ) [ l o g p θ ( x u ∣ z u ) ] = a r g m a x θ , ϕ ∑ u l o g p θ ( x u ∣ g ϕ ( x u ) ) (7) \theta^{AE},\phi^{AE}=argmax_{\theta,\phi}\sum_u\mathbb{E}_{\delta(\mathbf{z}_u-g_{\phi}(\mathbf{x}_u))}[logp_{\theta}(\mathbf{x}_u|\mathbf{z}_u)]\\=argmax_{\theta,\phi}\sum_ulogp_{\theta}(\mathbf{x}_u|g_{\phi}(\mathbf{x}_u))\tag{7} θAE,ϕAE=argmaxθ,ϕu∑Eδ(zu−gϕ(xu))[logpθ(xu∣zu)]=argmaxθ,ϕu∑logpθ(xu∣gϕ(xu))(7):
有两个关键区别的注意:(1) auto-encoder (和去噪 auto-encoder )有效地优化 vae 的第一项(式(5)和式(6)),具体来说使用一个 δ \delta δ 变量分布 q ϕ ( z u ∣ x u ) = δ ( z u − g ϕ ( x u ) ) q_{\phi}(\mathbf{z}_u | \mathbf{x}_u) =\delta (\mathbf{z}_u−g_{\phi}(\mathbf{x}_u)) qϕ(zu∣xu)=δ(zu−gϕ(xu)) —它不规范 q ϕ ( z u ∣ x u ) q_{\phi}(\mathbf{z}_u | \mathbf{x}_u) qϕ(zu∣xu) 对任何先验分布的影响。(2) δ ( z u − g ϕ ( x u ) ) \delta(\mathbf{z}_u-g_{\phi}(\mathbf{x}_u)) δ(zu−gϕ(xu)) 是只有在 g ϕ ( x u ) ) g_{\phi}(\mathbf{x}_u)) gϕ(xu))输出时的 δ \delta δ分布。将此与vae相比较,后者的学习是使用一种变分分布,即 g ϕ ( x u ) ) g_{\phi}(\mathbf{x}_u)) gϕ(xu)) 输出高斯分布的参数(meanandvariance)。这意味着vae有能力捕获潜在状态 z u z_u zu 中的每个数据点的差异。
在实践中,作者发现自编码器非常容易过拟合,因为网络学习把所有的概率权重放到 x u x_u xu 中的非零项。通过在输入层引入dropout,去噪自编码器(DAE)不太容易过度拟合,同时模型性能良好。此外,作者还研究了一种具有多项似然的去噪自编码器。我们表示这个模型为 M u l t i − V A E P R Multi-VAE^{PR} Multi−VAEPR。
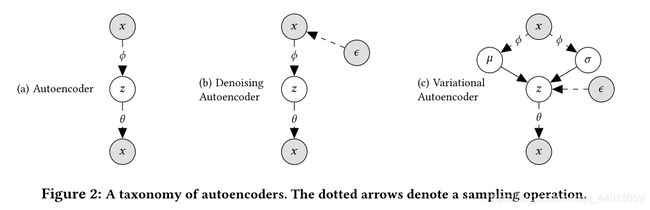
2.4 Prediction
以 M u l t − V A E P R Mult-VAE^{PR} Mult−VAEPR 为例说明在基于此生成模型得到最终的预测结果。给定用户的点击历史记录 x \mathbf{x} x,根据未标准化的预测多项式概率 f θ ( z ) f_{\theta}(\mathbf{z}) fθ(z) 对所有物品进行排序。对 x \mathbf{x} x 的潜表示 z \mathbf{z} z 构造如下:对于 M u l t − V A E P R Mult-VAE^{PR} Mult−VAEPR,只需取变分分布 z = μ ϕ ( x ) \mathbf{z} =\mu_\phi (\mathbf{x}) z=μϕ(x) 的均值;对于 M u l t − D A E Mult-DAE Mult−DAE,取输出 z = g ϕ ( x ) \mathbf{z} = g_\phi(\mathbf{x}) z=gϕ(x)。
使用自动编码器的优点很容易看出。通过对推理模型(编码器) g ϕ ( ⋅ ) g_\phi(\cdot) gϕ(⋅) 和生成模型(解码器) f θ ( ⋅ ) f_\theta(\cdot) fθ(⋅) 两个函数进行评估,可以有效地对用户进行预测。对于大多数协同过滤模型,如矩阵分解,当给定训练数据中不存在的用户点击历史时,通常需要进行某种形式的优化,以获得该用户的潜在因子。这使得自动编码器的使用在工业应用中特别有吸引力,在工业应用中,高效地进行预测和低延迟是很重要的。




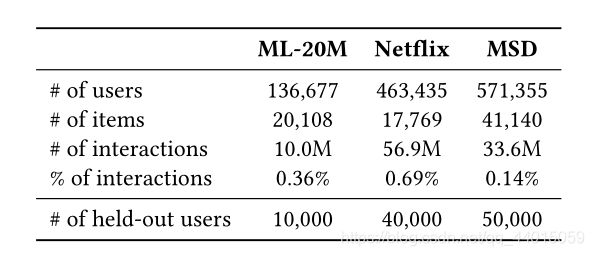
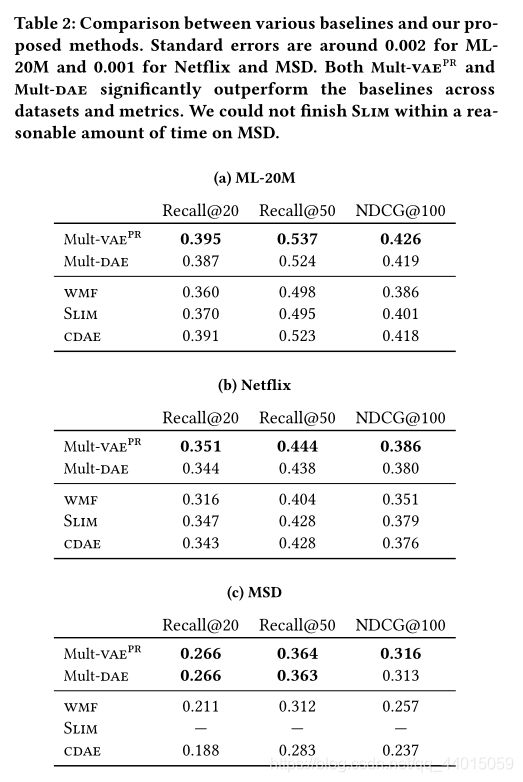
3. Experiment