python pandas 教学,入门介绍
我用python 想分析新冠病毒数据,别人建议我学习pandas。这里就把我的学习笔记整理一下。
我学习的网站是:
https://www.learndatasci.com/tutorials/python-pandas-tutorial-complete-introduction-for-beginners/
整个内容基本上可以从这个网站看到。
进一步的学习资料是: https://pandas.pydata.org/pandas-docs/stable/getting_started/tutorials.html
1: pandas 与数据科学工具包
pandas库不仅是数据科学工具包的重要组成部分,而且与该包中的其他库一起使用。
Pandas构建在NumPy包的顶部,这意味着NumPy的许多结构都在Pandas中使用或复制。 pandas中的数据通常用于SciPy中的统计分析,Matplotlib中的绘图功能以及Scikit-learn中的机器学习算法。
2:安装和导入
安装方法:
pip install pandas
导入:
import pandas
3: pandas 的核心: Series 和 DataFrames
Series 就是1列, DataFrame 就是很多列(Series 的组合)形成一个2维的表
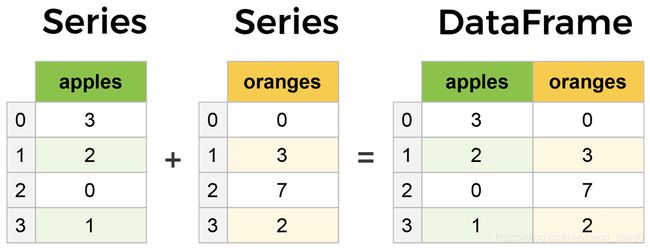
4:建立一个简单的pandas
import pandas as pd
data = {
'apples': [3, 2, 0, 1],
'oranges': [0, 3, 7, 2]
}
purchases = pd.DataFrame(data)
print(purchases)输出的结果是:
apples oranges
0 3 0
1 2 3
2 0 7
3 1 2
那是怎么工作的?
数据中的每个(键,值)项都对应于结果DataFrame中的一列。
该数据帧的索引在创建时就以数字0-3的形式提供给我们,但是在初始化数据帧时也可以创建自己的索引。
下面以客户名称作为索引,添加如下行:
purchases = pd.DataFrame(data, index=['June', 'Robert', 'Lily', 'David'])结果就是这样了:
apples oranges
June 3 0
Robert 2 3
Lily 0 7
David 1 2
如果显示一行呢?
purchases.loc['June']结果显示为:
apples 3
oranges 0
Name: June, dtype: int64
5:读写dandas交互
很多情况下都是从文件,数据库,网络获取数据到dandas的变量里。
保存到csv 数据文件里:
purchases.to_csv('purchases.csv')
可以看到目录下保存的文件。
从csv文件里读取数据:
df = pd.read_csv('purchases.csv')df 显示为:
index apples oranges
0 June 3 0
1 Robert 2 3
2 Lily 0 7
3 David 1 2
如果是:
df = pd.read_csv('purchases.csv', index_col=0)df显示为:
apples oranges
June 3 0
Robert 2 3
Lily 0 7
David 1 2
读写json 文件如下:
写如下:purchases.to_json('purchases.json')
读如下:
df = pd.read_json('purchases.json')
如果和数据库交互需要安装和导入,比如保存如下:
import sqlite3
con = sqlite3.connect("database.db")
purchases.to_sql('purchases', con)导入命令是:
df = pd.read_sql_query("SELECT * FROM purchases", con)下面代码是从网上得到json 文件,然后导入数据到df
import pandas as pd
import requests
url = 'https://lab.isaaclin.cn/nCoV/api/area?latest=1'
r = requests.request('GET', url)
data = r.json()
df = pd.DataFrame.from_records(data['results'])6:一些常用操作:
看前面数据:
df.head()缺省是5行,可以
df.head(10)
看尾部数据
df.tail()
df.tail(10)
获取数据表信息:
df.info()
显示为:
Index: 4 entries, June to David
Data columns (total 2 columns):
apples 4 non-null int64
oranges 4 non-null int64
dtypes: int64(2)
memory usage: 96.0+ bytes
行列信息:
df.shape
结果为]: (4, 2)
复制,后面添加
temp_df = df.append(df)
temp_df.shape
显示: (8, 2)
去点重复项:
temp_df.drop_duplicates(inplace=True)显示列信息
df.columns
结果为:Index(['apples', 'oranges'], dtype='object')
判断空值,还有求和
df.isnull()
df.isnull().sum()
切片,过滤,抽取
取一列
genre_col =df['apples']
type(genre_col)
显示: pandas.core.series.Series
子集:
subset = df[['apples', 'oranges']]
这里实际是全集,多列的时候可以的
下面得到行数据
df.iloc[1]
Out[110]:
apples 2
oranges 3
Name: Robert, dtype: int64
df.loc['Robert']
Out[111]:
apples 2
oranges 3
Name: Robert, dtype: int64
范围如下:
df.loc['Robert':'David']
Out[112]:
apples oranges
Robert 2 3
Lily 0 7
David 1 2
df.iloc[0:2]
Out[113]:
apples oranges
June 3 0
Robert 2 3
过滤和条件选择
condition = (df['apples'] == 2)
condition
Out[115]:
June False
Robert True
Lily False
David False
Name: apples, dtype: bool
df[df['apples'] == 2]
Out[116]:
apples oranges
Robert 2 3
isin()函数
df[df['apples'].isin([1,2])]
Out[117]:
apples oranges
Robert 2 3
David 1 2
函数应用
定义一个函数如下:
def rating_function(x):
if x >= 2:
return "good"
else:
return "bad"
然后添加一列
df["applelike"] = df["apples"].apply(rating_function)
df 显示为
apples oranges applelike
June 3 0 good
Robert 2 3 good
Lily 0 7 bad
David 1 2 bad
简单画图
pandas的一个优点是它与Matplotlib集成在一起,因此可以直接从DataFrames和Series中进行绘制。 首先,我们需要导入Matplotlib
import matplotlib.pyplot as plt
plt.rcParams.update({'font.size': 20, 'figure.figsize': (10, 8)}) # set font and plot size to be larger绘图提示
对于类别变量,请使用“条形图” *和“箱线图”(Bar Charts* 和 Boxplots)。
对于连续变量,请使用直方图,散点图,折线图和箱形图(Histograms, Scatterplots, Line graphs, 和 Boxplots)
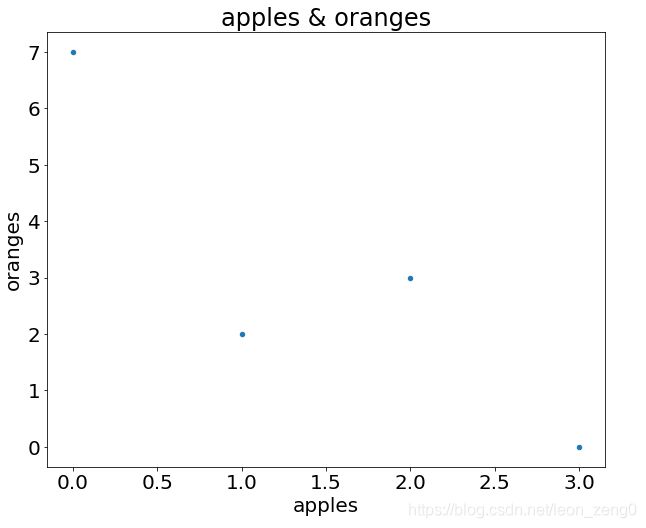
下面代码:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams.update({'font.size': 20, 'figure.figsize': (10, 8)})
data = {
'apples': [3, 2, 0, 1],
'oranges': [0, 3, 7, 2]
}
purchases = pd.DataFrame(data)
purchases.plot(kind='scatter', x='apples', y='oranges', title='apples & oranges');
运行结果为:
pandas 简单入门就介绍这么多。
补充:python pandas 入门进阶