Learning Deep Ship Detector in SAR Images From Scratch
Learning Deep Ship Detector in SAR Images From Scratch
-
- 1.主要内容
-
- 存在的问题:
- 提出的方法:
- 结论:
- 2.网络结构
-
- backbone
- SPN---Ship Proposal Network
- SDN---Ship Discrimination Network
- Focal loss
- 3.实验结果
论文地址:百度网盘链接,提取码:5whq
发表期刊:IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING, VOL. 57, NO. 6, JUNE 2019
论文作者:国防科技大学
干货满满的文章,强推!
1.主要内容
存在的问题:
- pre-trained:神经网络的参数众多,往往需要大量的数据进行训练,然而有标注的数据集数量却比较少。如果采用ImageNet pre-trained的权重,那么则会因为SAR images和ImageNet images在大领域上的不匹配,产生learning bias
- small object detection:在SAR图像中的舰船都是相对小尺寸和密集聚类的目标,但是由于大部分检测器用于检测的是rough feature map,并且前景和背景的极度不平衡,在小目标检测上的表现都不怎么好。
提出的方法:
从零开始训练ship detector
- condensed backbone:由dense block组成。因此,earlier layers可以通过密集的连接从目标函数(objective function)接受额外的监督,这使得训练变得容易。另外,采用了feature reuse策略,使其具有较高的参数效率。因此,backbone可以自由设计和有效地从头开始训练,而不需要使用大量带标注的样本。
- improved cross-entropy loss:改进了cross-entropy loss,来解决前景和背景不平衡的问题,并且从从多个intermediate layers输出多尺度舰船proposals,以提高召回率。
- position-sensitive score maps:position-sensitive score maps用于将位置信息编码到每个ship proposal,用以区分。
结论:
- 从零开始训练的ship detector相比与在 ImageNet pre-trained detector能获得更好的性能
- 我们的方法在检测小型和密集的船舶的任务上,比现有的算法更有效
如果觉得文章不错,欢迎点赞收藏评论交流,这也是不断更新的动力!
2.网络结构
在当时,DSOD是唯一一个不使用pre-trianed进行图像检测的网络,DSOD采用了dense layer-wise connections的方法来reuse feature,即condensed block。作者也是受到DSOD的启发,遵循了DSOD的设计方法。
但是DSOD是基于SSD回归的方法完成的目标检测,作者认为二阶段网络可以更好地用于小目标的密集检测,所以采用了proposal-based的方法
SSD网络结构:
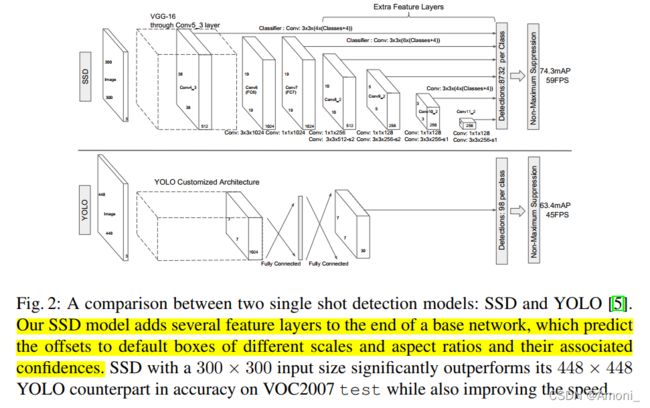
DSOD网络结构:
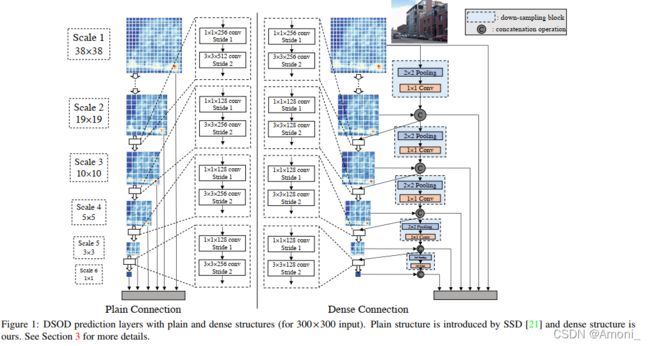
本文的网络结构:
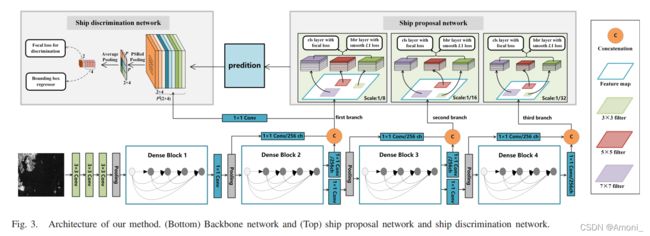
网络的整体结构 = backbone + SPN(Ship Proposal Network) + SDN(Ship Discrimination Network)
下面的表格可以后面再看
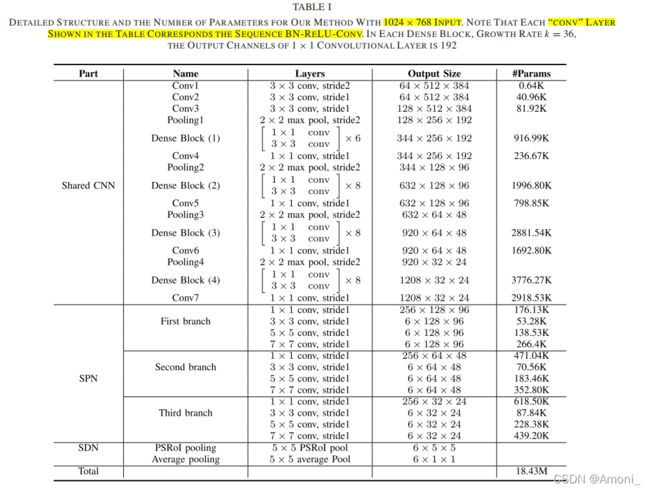
backbone

整个backbone分成4个stage,分别由dense block组成。
- 在进入stage 1之前,通过conv stride 2 的方式,对原始输入进行2倍降采样
- 在进入每个dense block之前,都通过2 * 2 max pooling 的方式进行2倍降采样
- 两个dense block 通过1 * 1 cnn 和 2 * 2 max pooling连接
- Dense block = 3 * 3 cnn + 1 * 1 cnn + BN + Scale layer + Relu
【Scale layer是啥操作???】
Dense block的内部结构

为了保证网络中各层之间的信息流最大化,采用了Dense block,以前馈的方式将每一层连接到其余层。
由于每一层都可以直接从loss function和原始输入信号中获得梯度,所以包含dense block的网络容易训练。
此外,来自浅层的特征被深层重用,从而减少了参数的数量。
SPN—Ship Proposal Network
RPN网络的对比:
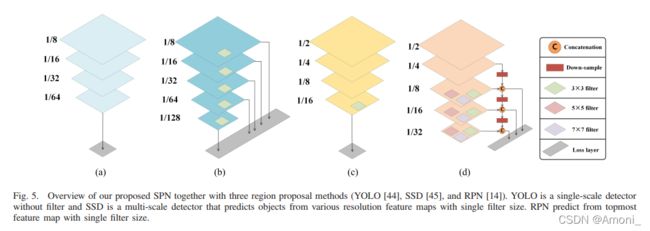
传统CNN网络难以检测小物体的原因:
- 用于检测的feature map尺寸太小,难以覆盖小物体,会导致定位模糊(fp中的一个pixel可能包含多个小物体)
- 小物体往往会导致很严重前景背景失衡。
- 因为大部分区域都很容易判断为负样本,这对于网络学习来说是无效的信号,因此训练往往是低效的;
- 简单的负样本会成为影响训练的主要因素,进而导致模特退化。
【在Fast CNN中,会通过sampling的方式进行政府样本的采样,但是采样得到的负样本并不能完全表达背景】
解决inconsistency的方法:
- 采用不同尺寸大小的卷积从不同的中间层中生成ship-like regions
- 可以从浅层中提取更多ship的细节信息,可以从深层中提取更多全局上下文信息
- 通过这种方式可以有效提高ship的召回率
SPN网络结构:

SPN网络并没有直接采样每个dense block的输出作为输入,而是每条branch都融合了不同dense block的输出用于生成ship proposals。并且通过1 * 1 cnn进行了降维后,再进行不同dense block fp之间的concate。
这样做,一方面可以融合不同尺度的fp,来产生更准确的预测;另一方面,通过 1 * 1 cnn的降维,可以有效降低参数。
下面介绍RPN网络的细节,实际上就是Faster RCNN的过程,但这篇文章有所改进。
首先简单回顾一下Faster RCNN的思路:
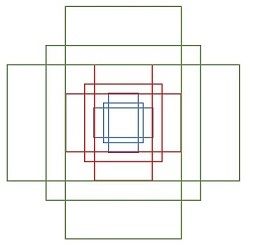
在Faster RCNN中,通过遍历Conv layers计算获得的feature maps,为每一个点都配备9种anchors作为初始的检测框,然后通过2次bounding box regression在初始anchor的基础上修正检测框位置。第一次修正在RPN网络,第二次修正是在Detection网络。

然后,再看看这篇文章中提出的方法:
同样都是有9中尺寸的anchor,但是分成三条branch进行,每一条branch分支都设置三种不同尺寸的anchor,然后在每条branch中,由三种不同尺寸的filter,生成不同尺寸anchor对应的proposals。
生成的proposals有6个通道,其中前面两个通道用于分类,后面四个通道用于回归位置。
具体而言,前两个通道,通过softmax分类anchors获得positive和negative分类(注意与后面的用于训练的正负样本的分配做好区分);后面四个通道,用于计算proposals对于anchors的偏移量,以获得精确的proposals(对应前面提到的第一次修正)。
在每一个划窗的位置,都会根据不同的filter预测出一个region box(x,y,w,h),其中x,y表示region左上点的坐标,w,h表示predicted region的尺寸。实际上,region box的结果是通过anchor + offset得到。具体设置如下方的表格:

为了建立一个proposals training samples,位于图像边界外的regions会被丢弃,剩下的regions会按照正负样本分配的设置进行划分。在文章中,如果regions box与某个gt_boxes的IOU最大,则将这个region box划分为正样本;如果IOU低于0.2,则将其划分为负样本;其他的regions都会被丢弃,不参与后续的训练过程。
至此,SPN网络的简单介绍结束。
实际上,SPN网络中还有用到作者提出的用于缓解前景背景不平的improved CE loss,我们后面再介绍。
SDN—Ship Discrimination Network
二阶段SDN网络的必要性:
一方面,sliding操作没有很好地覆盖ship,来自多个分支的ship proposals相互高度重叠。
另一方面,每个预测区域框 Bi 的局部特征表示不足以进行更好的区分。
因此,为了提高检测精度,在SPN网络之后加入了SDN网络
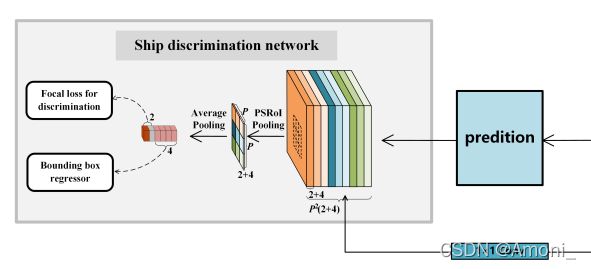
SDN网络的流程:
将带有预测区域框(由 SPN 生成)的图像作为输入,并同时输出refined的类别和位置。由于这些ship proposals具有不同的大小,因此通常对每个边界框采用 ROI pooling来提取固定维度的特征(eg.,7 × 7 × 512)。 然后,这些特征输入到后面的的全连接层,并分成两条分支,分别用于进一步的分类和边界框回归(对应前面提到的第二次修正)。
【在Faster RCNN中,是将原始图像作为输入;但是在这篇文章的网络结构图中是将浅层的fp作为输入,像是与论文有出入???】
Focal loss
交叉熵损失函数:S+表示正样本,S-表示负样本
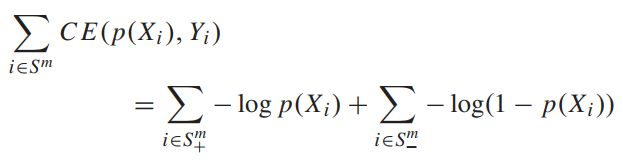
只有当采样的到正样本和负样本proposals比例为1:1的时候,CE loss用于训练才是effective的。
因为为了处理前景背景不平衡的问题,采用了何凯明大神的Focal loss,这样可以将所有的proposals都用于训练。
Focal Loss:β是balancing parameter,用于防止负样本在training loss中占主要地位
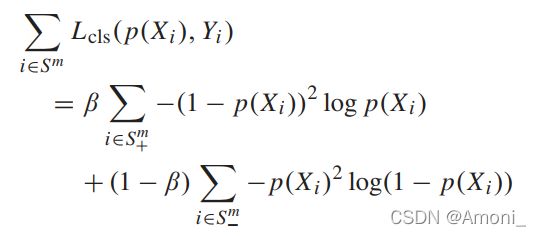
对用分类错误的情况,Focal loss等同于CE loss。当一个正样本被错误分类时,p(xi)的值很小,此时调节因子(1-p(xi))2<\sup>接近于1;当一个负样本被错误分类时,p(xi)的值很大,此时调节因子p(xi)2<\sup>接近于1。
对于分类正确的情况,Focal loss可以平滑地降低(smoothly downweighted)。当一个正样本被正确分类时,p(xi)的值很大,此时调节因子(1-p(xi))2<\sup>接近于0;当一个负样本被正确分类时,p(xi)的值很小,此时调节因子p(xi)2<\sup>接近于0。
因此,Focal loss可以防止在训练的过程中,大量的容易分类的负样本主导训练过程。
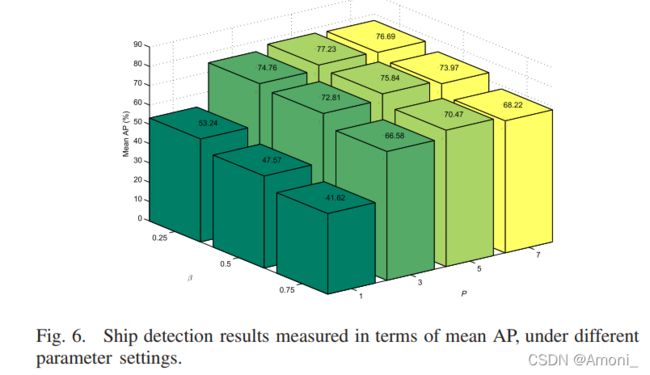
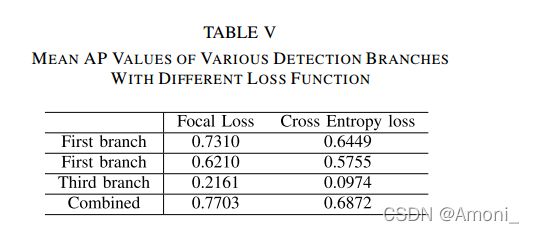
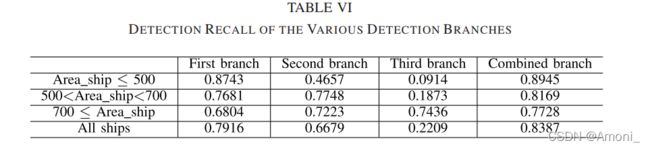
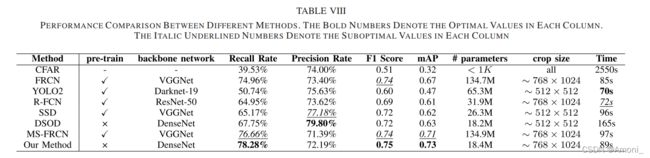
3.实验结果