史上最全GAN综述2020版:算法、理论及应用(A Review on Generative Adversarial Networks: Algorithms, Theory, and Applic)
**
**
史上最全GAN综述2020版:算法、理论及应用**
论文地址:https://arxiv.org/pdf/2001.06937.pdf
**
摘要:生成对抗网络(GANs)是近年来的一个研究热点。自2014年以来,GANs得到了广泛的研究,提出了大量的算法。然而,很少有全面的研究解释不同GANs变种之间的联系,以及它们是如何进化的。在本文中,我们试图从算法、理论和应用的角度对各种GANs方法进行综述。首先,详细介绍了大多数GANs算法的研究动机、数学表示和结构。此外,GANs已经与其他机器学习算法结合用于特定的应用,如半监督学习、迁移学习和强化学习。本文比较了这些GANs方法的共性和差异。其次,研究了GANs的相关理论问题。然后,阐述了GANs在图像处理和计算机视觉、自然语言处理、音乐、语音和音频、医学和数据科学等领域的典型应用。最后,指出了GANs未来的开放性研究问题。
摘要-深度学习,生成对抗网络,算法,理论,应用。
1介绍
生成对抗网络(GANs)是近年来的一个研究热点。深度学习领域的传奇人物Yann LeCun 在Quora上发帖称:“GANs是过去10年机器学习领域最有趣的想法。”从谷歌学术上可以发现,有大量和GANs相关的论文。例如,2018年大约有11800篇关于GANs的论文。也就是说,2018年,每天大约有32篇论文,每小时有超过一篇论文与GANs有关。
GANs有两部分组成:生成器和判别器。这两个模型都由神经网络实现,该系统可以将数据从一个空间映射到另一个空间。生成器尝试捕获真实数据的分布,以生成新的数据。判别器通常是一个二元分类器,要求尽可能准确地从真实的例子中鉴别出生成的例子。GANs的优化是一个最大最小优化问题。优化终止于一个鞍点,该鞍点相对于生成器是最小值,相对于鉴别器是最大值。也就是说,当优化达到纳什均衡[1]的目标时,这时可以认为生成器捕获了真实数据的真实分布。
之前的一些工作采用了让两个神经网络相互竞争的概念。联系最多的是可预测性最小化[2]。可预测性最小化和GANs之间的联系可以在[3]、[4]中找到。
本文和先前的关于GANS的综述之间的区别主要有以下几点:
1)GANs的具体应用:将GANs用于诸如图像合成和编辑,音频增强和合成等具体领域。
2)关于GANs的综合评述:最早关于GANs的相关综述是Wang et al.[7]整理的,该论文主要介绍了2017年以前GANs 的研究进程。2)文献[8]、[9]主要介绍了GANs在2018年之前的进展情况。参考文献[10]介绍了GANs在计算机视觉领域中的各种变体以及变体的损失函数。其他相关工作可以在[11]-[13]中找到。
到目前为止,本文是第一个从算法,理论和应用的角度为GANs提供一个全面的综述,并且介绍了GANs的最新的进展。此外,本文不仅关注GANs在图像处理和计算机视觉上的应用,而且关注了GANs在诸如自然语言处理和其他如医疗领域等相关领域中的序列数据上的应用。
本文其余部分,章节2:介绍相关工作;章节3-5:分别从算法,理论和应用的角度介绍GACNs,并在表1,2展示;章节6:对开放性问题进行探讨;章节7:总结;

2相关工作
GANs属于生成算法。生成算法和判别算法是机器学习算法的两大类。如果机器学习算法是基于观测数据的全概率模型,那么该算法是生成式的。生成算法由于其广泛的实际应用而变得越来越受欢迎和重要。
2.1生成算法
生成算法可分为两类:显式密度模型和隐式密度模型。
2.1.1显式密度模型
显式密度模型假设分布,利用真实数据训练参数模型,参数模型包含分布或拟合分布。完成后,利用所学的模型或分布生成新的例子。显式密度模型包括最大似然估计(MLE)、近似推断[95]、[96]和马尔可夫链法[97]-[99]。这些显式密度模型具有显式分布,但存在局限性。例如,MLE是对真实数据进行的,直接基于真实数据更新参数,导致生成模型过于平滑。通过近似推理学习的生成模型由于难以求解目标函数,只能接近目标函数的下界,而不能直接接近目标函数。马尔可夫链算法可以用来训练生成模型,但计算成本昂贵。此外,显式密度模型存在计算易处理的问题。它可能无法表现真实数据分布的复杂性,无法学习高维数据分布[100]。
2.1.2隐式密度模型
隐式密度模型不能直接估计或拟合数据分布。它在没有明确假设的情况下从分布中产生数据实例[101],并利用产生的实例来修改模型。在GANs之前,隐式密度模型通常需要使用先前采样[102]或基于马尔可夫链的采样进行训练,效率低下,限制了其实际应用。GANs属于有向隐式密度模型范畴。详细的总结和相关文献见[103]。
2.1.3 GANs与其他生成算法的比较
GANs的提出是为了克服其他生成算法的缺点。对抗性学习背后的基本思想是,生成器试图创建尽可能真实的例子来欺骗判别器。判别器试图区分假例子和真例子。生成器和判别器都通过对抗性学习进行改进。这种对抗性过程使GANs比其他生成算法具有明显的优势。更具体地说,GANs相对于其他生成算法有以下优势:
1)GANs可以并行产生样本,这是其他生成算法无法实现的比如PixelCNN[104]和FVBNs[105],[106]。
2)生成函数的设计有很少的限制。
3) GANs被主观地认为比其他方法产生更好的例子。
关于这个问题的详细讨论,请参考[103]。
2.2对抗性的思想
对抗式思想已成功应用于机器学习、人工智能、计算机视觉和自然语言处理等领域。最近AlphaGo[107]击败了世界顶级人类棋手,引发了公众对人工智能的兴趣。
对抗性的例子[108]-[117]也有对抗性的概念。
对抗性例子是指那些与真实数据差很大,却被很自信地归入真实类别的例子,或者是那些与真实例子稍有不同,但被归入错误类别的例子这是最近一个非常热门的研究课题[112],[113]。针对对抗性攻击[118],[119],文献[120],[121]利用GAN进行正确的防御。
对抗性机器学习[122]是一个极大极小问题。防御者,构建我们想要正确工作的分类器,在参数空间中进行搜索并尽可能降低分类器成本的参数,攻击者对模型的输入进行搜索,使代价最大化。对抗性思想存在于对抗性网络、对抗性学习和对抗性例子中,但他们目标不同。
3算法
在本节中,我们首先介绍最原始的 GAN。然后,介绍其具有代表性的变体、训练及评估方式以及任务驱动的 GAN。
3.1生成对抗网络
当模型都是神经网络时,GAN 架构实现起来非常直观。为了学习生成器在数据 x 上的分布 ,首先定义一个关于输入噪声变量的先验分布 Pz(z)[3],其中 z 是噪声变量。接着,GAN 表示了从噪声空间到数据空间的映射 G(z, θg),其中 G 是一个由参数为 θg 的神经网络表示的可微函数。除了 G 之外,另一个神经网络 D(x, θd) 也用参数 θd 定义,D(x) 的输出是单一的标量。D(x) 表示了 x 来自真实数据而不是来自生成器 G 的概率。我们对判别器 D 进行训练,以最大化为训练数据和生成器 G 生成的假样本提供正确标签的概率。同时,我们训练 G,最小化 log(1-D(G(z)))。
3.1.1目标函数
GAN 可以使用各种不同的目标函数。
3.1.1.1最原始的极大极小博弈
GAN [3] 的目标函数是:![]()

3.1.1.2非饱和博弈:
实际上,公式 (1) 可能无法为 G 提供足够大的梯度使其很好地学习。一般来说,G的早期学习情况较差,产生的样本与训练数据有明显的差异。因此,D 可以以高置信度拒绝 G 生成的样本。在这种情况下,log(1-D(G(z))) 是饱和的。我们可以训练 G 最大化 log(D(G(z))),而不是最小化 log(1-D(G(z)))。生成器的损失则变为:![]()
(7)
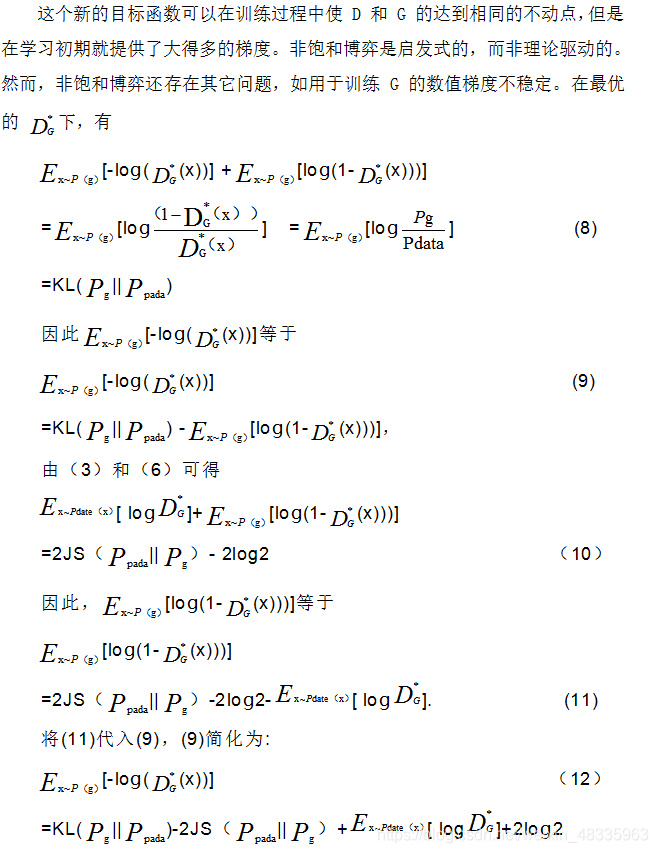
从 (12) 式可以看出,对非饱和博弈中的替代 G 损失函数的优化是矛盾的,因为第一项目标是使生成的分布与实际分布之间的差异尽可能小,而由于负号的存在,第二项目标是使得这两个分布之间的差异尽可能大。这将为训练 G 带来不稳定的数值梯度。此外,KL 散度是非对称度量,这可以从以下两个例子中反映出来

对 G 的两种误差的惩罚是完全不同的。第一种误差是 G 产生了不真实的样本,对应的惩罚很大。第二种误差是 G 未能产生真实的样本,而惩罚很小。第一种误差是生成的样本不准确,而第二种误差是生成的样本不够多样化。基于这个原理,G 倾向于生成重复但是安全的样本,而不愿意冒险生成不同但不安全的样本,这会导致模式崩溃(mode collapse)问题。
3.1.1.3最大似然博弈:
在GANs中有许多近似(1)的方法。假设判别器是最优的,我们想最小化
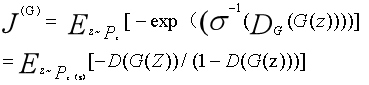
(13)
其中,σ为logistic sigmoid函数,等于最小化(1)[123]。这种等价性的证明可以在[103]的8.3节中找到。在 GAN 框架中有其它可能的方法逼近最大似然 [17]。图 1 展示了对于原始零和博弈、非饱和博弈以及最大似然博弈的比较。
由图 1 可以得到三个观察结果。

图1:“原始”、“非饱和”和“最大似然代价”的三条曲线分别为log(1−D(G(z))、−log (D(G(z)))和−D(G(z))/(1−D(G(z)),在(1)、(7)和(13)中。生成器生成样本G(z)的代价仅由判别器对所产生样本的响应决定。判别器对生成的样本给出真实标签的概率越大,生成代价越低。这个数字是复制自[103],[123]。
首先,当样本可能来自于生成器的时候,即在图的左端,最大似然博弈和原始极大极小博弈都受到梯度弥散的影响,而启发式的非饱和博弈不存在此问题。
最大似然博弈还存在一个问题,即几乎所有梯度都来自曲线的右端,这意味着每个小批量中只有极少一部分样本主导了梯度的计算。这表明减小样本方差的方法可能是提高基于最大似然博弈的 GAN 性能的重要研究方向。
第三,基于启发式的非饱和博弈的样本方差较低,这可能是它在实际应用中更成功的可能原因。
M.Kahng 等人 [124] 提出了 GAN Lab,为非专业人士学习 GAN 和做实验提供了交互式可视化工具。Bau 等人 [125] 提出了一个分析框架来可视化和理解 GAN。
3.2 GANs的代表性变体
与 GAN [126]-[131] 相关的论文有很多,例如 CSGAN [132] 和 LOGAN [133]。在本小节中,我们将介绍一些具有代表性 GAN 变体。
3.2.1 InfoGAN
InfoGAN[14]提出将输入噪声矢量分解为两个部分,而不是利用单一的非结构化噪声矢量z, z理解为不可压缩的噪声,c可以理解为可解释的隐变量 ,将针对真实数据分布的重要结构化语义特征。InfoGAN[14]旨在解决
![]()
(14)
但是互信息I(c;G(z, c))在实际中很难直接优化,因为它需要用到后验分布P(c|x)。幸运的是,我们通过定义一个辅助分布Q(c|x)来协助估计后验分布P(c|x),从而最大化互信息I(c;G(z, c))的下界。最后给出了InfoGAN[14]的目标函数:![]()
(15) 其中,(c;Q)为I(c;G(z, c))的下界。InfoGAN有几个变体,如因果InfoGAN[134]和半监督InfoGAN (ss-InfoGAN)[135]。
3.2.2条件GANs (CGANs)
如果判别器和生成器都引入一些额外信息y为条件,则GANs可扩展为条件模型,条件GANs[15]的目标函数为:![]()
(16)
比较(15)和(16)可知,InfoGAN的生成器与CGANs的生成器相似。但是InfoGAN的隐藏编码c是未知的,是通过训练发现的。此外,InfoGAN还有一个额外引进的网络Q来输出条件变量Q(c|x)。
基于CGANs,我们可以生成关于类标签[30],[136],文本[34],[137],[138],边界框和关键点[139]生成样本条件。在[34]中[140],采用堆叠生成对抗网络(SGAN)进行文本到真实感图像的合成[141]。CGANs被用于卷积人脸生成[142]、人脸老化[143]、图像转换[144]、合成具有特定风景属性的户外图像[145]、自然图像描述[146]和3d感知场景处理[147]。Chrysos等[148]提出了鲁棒的CGANs。Thekumparampil等人[149]讨论了条件GANs对带噪标签的鲁棒性。条件CycleGAN[16]使用具有循环一致性的CGANs。MSGANs[150]提出了一个简单而有效的正则化术语来解决CGANs的模式崩溃问题。
对原始GANs[3]的判别器进行训练,使其分配给正确源[30]的对数最大似然化: ![]()
(17)
AC-GAN [30]的目标函数有两部分:
正确源的逻辑似然值(loglikelihood)和正确的类标签的对数似然值,等于[17]中的L,被定义为:![]()
(18)
AC-GAN,判别器D训练最大化Lc+Ls,而生成器G训练最大化Lc−Ls。AC-GAN是第一个能够在所有ImageNet[151]类中生成可识别的GANs变体。
许多基于CGANs的模型的判别器[31],[41],[152]-[154]通过简单地将(嵌入的)条件信息y与输入或与某个中间层的特征向量连接,将条件信息y输入到判别器中。基于投影方法的鉴别器的CGANs[155]采用条件向量y与特征向量的内积
Isola等[156]将CGANs和稀疏正则化方法用于图像到图像的转换。相应的软件叫做pix2pix。在GANs中,生成器学习从随机噪声z到G(z)的映射。而在pix2pix的生成器中则没有噪声输入。pix2pix的一个新颖之处在于,pix2pix的生成器学习了从观测图像y到输出图像G(y)的映射。例如,从灰度图像到彩色图像。[156] CGANs的目的可以表示为:

3.2.3 循环一致性的生成式对抗网络(CycleGAN)
图像到图像的转换是图形和视觉问题,其目标是使用对齐图像对的训练集学习输出图像和输入图像之间的映射。当有成对的训练数据时,参考文献[156]可以用于图像到图像的翻译任务。但文献[156]不能用于未配对的数据(无输入/输出对),CycleGAN[53]很好地解决了这个问题。CycleGAN是对非配对数据的一个重要进展。证明了循环一致性是条件熵的上界[158]。CycleGAN可以在提出的变分推断(VI)框架[159]中作为一种特例推导出来,自然地与近似贝叶斯推理方法建立了关系。
disco[54]和CycleGAN[53]的基本思想几乎是一样的。他们几乎同时分别被提出。CycleGAN[53]和DualGAN[55]唯一的区别是DualGAN使用的是Wasserstein GAN (WGAN)所提倡的损失格式,而不是CycleGAN使用的s型交叉熵损失。
3.2.4 f-GAN
我们知道,Kullback-Leibler (KL)散度度量了两个给定概率分布之间的差异。一大类分类的散度就是所谓的AliSilvey距离,也称为f发散[160]。f散度是给定两个概率分布P和Q分别有一个绝对连续的密度函数P和Q,关于基准测度dx在定义域X上定义: 
(25)
f不同的选择恢复了常见的散度作为f散度的特殊情况。例如,f (a) = aloga,则f散度变为KL散度。原GANs[3]是基于f散度的f-GAN[17]的一种特殊情况。参考[17]表明,任何f散度都可以用来训练GAN。此外,参考[17]讨论了不同选择的发散函数对生成模型质量和训练复杂度的优势。Im等人[161]用提出的训练差异对GAN进行了定量评估。f-散度在生成器步直接最小化,而在判别步预测真实数据和生成数据分布的比值。
3.2.5积分概率度量(IPMs)
表示P是拓扑空间(M, A)上所有Borel概率测度的集合。定义两个概率分布P∈P和Q∈P之间的整数概率度量(IPM)[163]为:

(26)
其中F是m上的一类实值有界可测函数,在[164]中讨论了GANs在Besov IPM损失下的非参数密度估计和收敛速度。IPMs包括再生希尔伯特空间诱导的最大平均差异(MMD)以及Wasserstein GANs (WGAN)中使用的Wasserstein 距离。
3.2.5.1最大平均差异(MMD):
最大平均差异(MMD)[165]是两个分布P和Q之间的差异的度量,由函数空间F上关于两个分布的期望差异给出。MMD的定义是:
![]()
(27)
MMD被用于深层生成模型[166]-[168]和模型批评[169]。
3.2.5.2Wasserstein GAN(WGAN)
WGAN[18]对期望最大化算法(EM)距离与常用的概率距离和散度(如总变分(TV)距离、KullbackLeibler (KL)散度、以及学习分布上下文中使用的Jensen-Shannon散度)的表现进行了全面的理论分析。EM距离的定义为:

通过比较(1)和式(30),我们可以看到原始GANs的目标函数与WGAN的目标函数有三个不同之处:
•首先,WGAN的目标函数没有log。
•其次,原始GANs中的判别器被用作二元分类器,而WGAN中的D被用来近似Wasserstein距离,是一个回归任务。因此,在WGAN中判别器去掉最后一层sigmoid。原始GAN的鉴别器的输出在0到1之间,而WGAN的鉴别器的输出没有限制。
•第三,对于某些K, WGAN中的D必须是K- lipschitz,因此WGAN使用重量剪裁。
与传统的GANs训练相比,WGAN可以提高学习的稳定性,并提供了对超参数搜索和调试有用的有意义的学习曲线。然而,近似Wasserstein-1度量所要求的K-Lipschitz约束是一项具有挑战性的任务。利用梯度罚进行K-Lipschitz限制,提出了WGAN-GP[19],目标函数为

(31)
第一的目标函数是两项WGAN和ˆx是抽样分布pˆxwhich样品沿着直线均匀采样双点之间真正的数据分布pdata和生成分布pg。还有一些与WGAN-GP密切相关的方法,如DRAGAN。Wu等人[171]提出了一种新的Wasserstein1度量:Wasserstein散度(W-div),它不需要K-Lipschitz限制。Wu等[171]在W-div的基础上引入了GANs的Wasserstein散度目标(WGAN-div),它可以通过优化忠实地近似W-div。CramerGAN[172]认为,Wasserstein距离导致梯度有偏差,这表明两个分布之间存在Cramr距离。[173] -[178]中有其他关于献
3.2.6 Loss Sensitive GAN (LS-GAN)
与WGAN类似,LS-GAN[20]也有一个Lipschitz限制。在LS-GAN中,假定在一组紧支撑的Lipschitz密度中。在LS-GAN中,损失函数Lθ(x)被θ参数化,并且LS-GAN假设产生的样品应该比实际样品有更大的损耗。可以训练损失函数满足以下约束:

3.2.7总结
有一个叫做“The GAN Zoo”的网站(https: //github.com/hindupuravinash/the-gan-zoo)列出了许多GAN的变体。详情请参阅本网站。
3.3GANs训练
尽管理论上存在唯一解,但GANs的训练难度较大,且往往不稳定,原因如下[29],[32],[179]。其中一个困难是GANs的最优权值对应的是鞍点,而不是损失函数的最小值。
关于 GAN 训练的论文很多。Yadav 等人 [180] 用预测方法使 GAN 训练更加稳定。[181] 通过使用独立的学习率,为判别器和生成器提出了两个时间尺度更新规则(TTUR),以确保模型可以收敛到稳定的局部纳什均衡。Arjovsky [179] 为全面了解 GAN 的训练动力学(training dynamics)进行了理论探究,分析了为什么 GAN 难以训练,研究并严格证明了训练 GAN 时出现的损失函数饱和和不稳定等问题,提出了解决这类问题的一个实用且具有理论依据的方向,并引入了新的工具来研究它们。Liang 等人 [182] 认为 GAN 的训练是一个连续的学习问题 [183]。
改善 GAN 训练的一种方法是评估训练中可能发生的问题。这些症状包括:生成器模型崩溃,对于不同的输入只能生成极其相似的样本 [29];判别器损失迅速收敛至零 [179],不能为生成器提供梯度更新;使生成器、判别器这一对模型难以收敛 [32]。
我们将从三个角度介绍GANs的训练:目标函数、训练技巧、架构
3.3.1目标函数
从3.1小节可以看出,利用式(1)中的原始目标函数训练G会遇到梯度消失问题,而利用非饱和博弈中的替代G损失(12)会遇到模式崩溃问题。这些问题是由目标函数引起的,不能通过改变GANs的结构来解决。重新设计目标函数是缓解这些问题的自然解决方案。基于GANs的理论缺陷,在理论分析的基础上提出了许多基于目标函数的变式来改变GANs的目标函数,如最小二乘生成对抗网络[21]、[22]。
3.3.1.1最小二乘生成对抗网络(LSGANs):
为了克服原GANs中的消失梯度问题,提出了LSGANs[21]、[22]。该工作表明,对于那些生成的样本,如果距离原始GAN判别器的决策边界很远,更新生成器的决策边界误差很小。LSGANs采用最小二乘损失代替了原来的交叉熵损失。假设LSGANs的判别器[21]采用a-b编码,其中a和b分别为生成样本和真实样本的标签。LSGANs的判别器损失和生成器损失定义为:
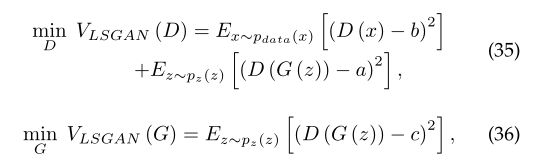
c是生成器为了让判别器认为生成样本是真实数据而定的值 。参考[21]表明LSGANs相对于原始GANs有两个优点:
•由D产生的新的决策边界对那些产生的远离决策边界的样本惩罚较大的误差,使得那些产生的“低质量”的样本向决策边界移动。这有利于生成更高质量的样品。
•对远离决策边界的生成样本进行惩罚,可以在更新生成器时提供更多的梯度,克服了原GANs中梯度消失的问题。
3.3.1.2Hinge loss based GAN:
提出了基于铰链损失的GAN并应用于[23]-[25]中,其目标函数为V (D, G):
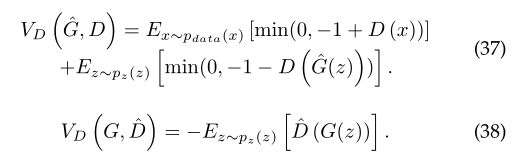
GANs中也使用了softmax交叉熵损失[184]
3.3.1.3Energy-based generative adversarial net-work (EBGAN)
3.3.1.4 Boundary equilibrium generative adversar-ial networks(BEGAN):
与EBGAN[38]类似,dual-agentGAN (DA-GAN)[186]、[187]和GANs的边缘适应(MAGANs) [188], BEGAN也使用自动编码器作为判别器。利用比例控制理论,提出了一种新的方法来平衡生成器和判别器。在训练中,具有快速、稳定和对参数变化的鲁棒性。
3.3.1.5模式正则化的对抗生成网络(MDGAN):
格瓦拉等人[26]认为,GAN“训练不稳定和模型崩溃是由于非常特殊的功能性训练有素的判别器在高维度空间的形状,从而使训练不通畅或导致概率错误,朝着更高的浓度比真正的数据分布。Che等[26]介绍了几种目标正规化的方法,使GAN模型的训练更加稳定。MDGAN的关键思想是利用一个编码器E (x): x→z为生成器G产生潜在变量z,而不是利用噪声。这种方法有两个优点:
•编码器保证了z (E(x))与x的对应,使得G能够覆盖数据空间中的各种模式。因此,它解决了模式崩溃问题。
•由于编码器的重构可以给生成器G增加更多的信息,所以判别器D很难区分真实的样本和生成的样本。
MDGAN的发生器和编码器的损耗函数为:

其中,两种模型1和模型2是自由调节参数,d是距离度量,如欧氏距离,和G◦E (x) = G(E (x))。
3.3.1.6 Unrolled GAN:
Metz等人[27]引入了一种通过定义判别器展开优化相关的生成器目标函数来稳定GANs的方法。这使得训练可以在利用判别器的电流值(通常是不稳定的,导致不好的解决方案)和利用最优判别器解决方案(在生成器的目标是完美的,但在实际应用中不可行)之间进行调整。设f(郎道G,郎道D)表示原GAN的目标函数。
判别器参数的局部最优解可以表示为迭代优化过程的不动点
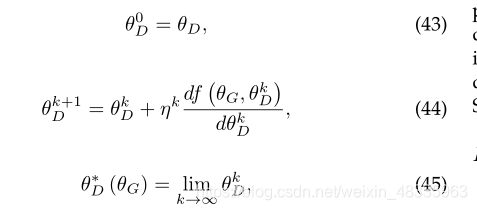
3.3.1.7 谱归一化GANs(SN-GANs)
SN-GANs[23]提出了一种新的权值归一化方法,即频谱归一化,使判别器的训练能够稳定。这种新的标准化技术计算效率高,易于集成到现有方法中。频谱一化[23]使用一种简单的方法使权矩阵W满足Lipschitz约束σ (W) = 1:![]()
(49)
其中,W是D中各层的权值矩阵,σ (W)是W的谱范数。研究表明,[23]SN-GANs与之前的训练稳定方法相比,可以生成质量相等或更好的图像。理论上,频谱归一化可以应用于所有GANs变体。BigGANs[36]和SAGAN[35]都采用了频谱归一化,在Imagenet上都有很好的性能。
3.3.1.8 Relativistic GANs (RGANs):

3.3.2训练技巧
NIPS 2016年举办了一场关于对抗训练的研讨会,邀请了Soumith Chintala作题为《如何训练GAN》的演讲。“这次演讲有各种各样的提示和技巧。例如,这个演讲建议,如果你有标签,训练鉴别器也分类例子:ACGAN[30]。请参考与Soumith演讲相关的GitHub知识库:https://github.com/soumith/ganhacks获取更多建议。
Salimans等人[29]提出了非常有用和改进了的技术来训练GANs,如特征匹配、小批鉴别、历史平均、单边标签平滑和虚拟批归一化。
3.3.3架构
原始的GANs使用多层感知机(MLP)。可能特定类型的结构适合于特定的应用,如用于时间序列数据的递归神经网络(RNN)和用于图像的卷积神经网络(CNN)。
3.3.3.1原始GANs:
原始的GANs使用MLP作为生成器G和鉴别器D。MLP只能用于小型数据集,如CIFAR-10[189]、MNIST[190]和多伦多人脸数据库(Toronto Face Database, TFD)[191]。但是,MLP对于更复杂的图像[10]没有很好的泛化效果。
3.3.3.2 Laplacian生成对抗性网络(LAPGAN)和SinGAN:
LAPGAN[31]的被提出生产比原始GAN更高分辨率的图像。LAPGAN使用Laplacian金字塔框架内CNN的级联[192]来生成高质量的图像。
SinGAN[193]从单张图片中学习生成模型。SinGAN有一个全卷积的GANs金字塔,每个GANs都可以学习图像在不同尺度上的patch分布。与SinGAN相似,InGAN[194]也从单张图片学习生成模型。
3.3.3.3 深度卷积对抗生成网络(DCGANs):
在原始的GANs中,G和D由多层感机(MLP)定义。由于CNN在图像处理方面优于MLP,所以在DCGANs[32]中,G和D由深度卷积神经网络(DCNNs)定义,具有更好的性能。目前大多数GANs至少是松散地基于DCGANs架构[32]。DCGANs体系结构的三个关键特性如下:
:•首先,整体体系结构主要基于全卷积网络[195]。不采用任何池化层。当G需要增加表示的空间维数时,采用步长大于1的转置卷积(反卷积)。
•其次,对生成网络和判别网络的大部分层进行批处理规范化,对G的最后一层和D的第一层不进行批处理规范化,以便神经网络能够学习到正确的数据分布的均值和规模。
•第三,利用Adam优化器代替SGDM。
3.3.3.4 Progressive GAN:
PGGAN[33]提出了一种新的GAN训练方法。PGGAN的结构基于[196]中首次提出的渐进神经网络。渐进GAN的关键思想是逐步发展生成器和判别器:意思是从低分辨率图像开始,然后通过向网络添加层逐步增加分辨率来模拟越来越精细的细节。
3.3.3.5自我关注生成对抗网络(SAGAN):
SAGAN[35]提出图像生成任务中允许用注意力驱动,距离较远的依赖建模。光谱归一化技术仅应用于判别器[23]。SAGAN对生生器和判别器都使用了光谱归一化,这提高了训练的动态性。进一步验证了TTUR[181]在SAGAN中是有效的。
注意AttnGAN[197]在输入序列中利用了对单词嵌入的关注,而不是对内部模型状态的自我关注。
3.3.3.6 BigGANs and StyleGAN:
BigGANs[36]和StyleGAN[37],[198]在GANs的质量上都取得了很大的进步。
BigGANs[36]是GANs的一个大规模张量处理单元(TPU)实现,它与SAGAN非常相似,但扩展很大。BigGANs成功地生成了高达512 * 512像素的高分辨率图像。如果您没有足够的数据,从头复制BigGANs结果将是一项具有挑战性的任务。Lucic等人[199]提出用更少的标签训练BigGANs质量模型。BigBiGAN[200]基于BigGANs,通过添加一个编码器和修改判别器,将其扩展到表征学习。BigBiGAN在ImageNet上的无监督表征学习和无条件生成图像方面都达到了最先进的水平。
在原始GANs中,[3]、G和D由MLP定义。Karras等人[37]提出了一个StyleGAN架构,它赢得了CVPR 2019年最佳论文荣誉奖。StyleGAN的生成器是一个真正高质量的生成器,用于其他生成任务,比如生成人脸。这是特别令人兴奋的,因为它允许分离不同的因素,如头发,年龄和性别,最后一个例子涉及到控制外观,我们可以分开控制它们。StyleGAN[37]也被用于生成穿着定制服装的高分辨率时装模特图像[201]。
3.3.3.7 autoencoders和GANs的混合:
自编码器是一种神经网络,是在无监督情况下学习有效的数据编码的方式。自动编码器包含编码器和解码器。编码器的目标是学习一组数据的表示(编码),z = E(x),通常是为了降维。译码器旨在重建数据。也就是说,减少了编码的译码器试图尽可能生成代表接近原来的输入x。
带有自动编码器的GANs:对抗自编码(AAE)[202]是一种基于GAN的概率自动编码器。提出了对抗变分贝叶斯(AVB)[203],[204]提出了统一变分自编码器(VAEs)和GANs。Sun等人[205]提出了一种基于GANs和VAEs的无监督图像-图像转换(单元)框架。Hu等[206]的目的是通过对GANs和VAEs的一种新的表述,建立它们之间的形式化联系。[207]利用GAN判别器中的学习到的特征表示作为VAE重建的基础。因此,元素方面的错误被特性方面的错误取代,以便更好地捕获数据分布,同时提供对诸如翻译的不变性。Rosca等人[208]提出了自编码GANs的变分方法。通过采用编码器解码器架构的生成器,DR-GAN[68]解决了姿态不变人脸识别这一困难的问题,因为对于每个不同的姿态,图像都会发生剧烈的变化。
GANs与编码器:引用[40],[42]只添加一个编码器到GANs。原始的GANs[3]无法学习逆映射——将数据投射回潜在空间。为了解决这个问题,Donahue等人[40]提出了双向GANs (BiGANs),该方法可以通过编码器学习这个逆映射,并表明所学习到的特征表示是有用的。类似地,Dumoulin等人[41]提出了反向学习推理(ALI)模型,该模型也利用编码器来学习潜在特征分布。BiGAN和ALI的结构如图3(a)所示。除了判别器和生成器,BiGAN还提供了一个用于将数据映射回潜在空间的编码器。

图3:(a) BiGAN和ALI的结构和(b)AGE
判别器的输入是由数据及其对应的潜码组成的一对数据。对于真实数据x,其对为x, E(x),其中E(x)是从编码器E得到的。对于生成的数据G(z),其对为G(z),z。z为通过生成器G生成数据G(z)的噪声向量。与(1)相似,BiGAN的目标函数为:![]()
(57)
[40]、[42]的生成器可以看作是解码器,因为生成器将向量从潜在空间映射到数据空间,其功能与解码器相同。
与利用编码过程对潜在样本的分布建模类似,Gurumurthy等人[209]将潜在空间建模为高斯函数的混合,并学习在数据生成分布下最大可能生成样本的混合成分。
在一个编码-解码模型中,输出(也称为重构),应该与理想情况下的输入相似。利用BiGAN/ALI合成的重建样本的保真度一般较差。在数据样本的分布及其重构上有额外的对抗代价[158],样本的保真度可能会得到改善。其他相关的方法包括如变分鉴别器瓶颈(VDB)[210]和MDGAN(详细在3.3.1.5段)。
生成器和编码器的结合:与之前的自编码器和GANs的混合不同,在生成器和编码器之间直接设置了对抗生成器-编码器(AGE)网络[42],在学习过程中不训练外部映射。AGE结构如图3(b)所示,其中R为重建损失函数。在AGE方面,有两种重建损失:潜在变量z和E(G(z)),数据x和G(E(x))。AGE和CycleGAN相似。
•CycleGAN[53]用于图像的两种模式,如灰度和颜色。AGE在潜在空间和真实数据空间之间起作用。
•每一种CycleGAN模态都有一个判别器,AGE没有判别器。
3.3.3.8 多判别器学习:
GANs由生成器和判别器组成。与GANs不同的是,双判频器GAN (D2GAN)[43]有一个生成器和两个二进制判频器。D2GAN类似于一个极大极小博弈,其中一个判别器对来自生成分布的样本给出较高的分数,而另一个鉴别器则相反,给真实分布的数据高分,生成器生成数据来欺骗两个判别器。文献[43]进行了理论分析,表明在给定最优判别器的情况下,优化D2GAN的生成器可以使真实分布与生成分布之间的KL和反向KL散度最小,从而有效地克服模式崩溃问题。生成式多对抗网络(GMAN)[44]进一步将GANs扩展为一个发生器和多个判别器。Albuquerque等人[211]使用多种判别器对GANs进行了多目标训练。
3.3.3.9多生成器学习:
MGAN[45]采用混合生成器对GANs进行训练,解决了模式崩溃问题。更特别的是,MGAN有一个二进制判别器、K个生成器和一个多类分类器。MGAN的显著特点是生成的样本由多个生成器生成,然后随机选择其中一个作为最终输出,类似于概率混合模型的机制。分类器显示生成的样本来自哪个生成器。
与MGAN关系最密切的是MAD-GAN[46]。MGAN与MAD-GAN的差异可以在[45]中找到。SentiGAN[212]使用生成器和多类判别器的混合来生成情感文本。
3.3.3.10
Multi-GAN学习:
提出了耦合GAN (CoGAN)[47]来学习二域图像的联合分布。CoGAN由一对GANs ,GAN1和GAN2的组成,每一对GANs - GAN1和GAN2合成一个域的图像。文献[213]基于CGANs提出了两种分别考虑结构和风格的GANs。CFGAN[214]使用两个生成器和两个判别器来生成公平(
fair)数据。GANs、D2GAN、MGAN、CoGAN的结构如图4所示。

图四:GAN的结构[3],D2GAN [43], MGAN[45]和CoGAN [47]
3.3.3.11小结:GANs的变体很多,里程碑如图5所示。由于空间的限制,只有有限数量的变型如图5所示。
GANs基于目标函数的变分可以推广到结构变分。与其他基于目标函数的变量相比,SN-GANs和RGANs表现出更强的泛化能力。这两种基于目标函数的变异体可以应用到其他基于目标函数的变体体中。光谱归一化可以推广到任何类型的GANs变体,而RGANs可以推广到任何基于IPM的GANs。

图5:GAN山脉的路线图。该图中显示了里程碑的变体。
3.4 GAN的评价指标
在本小节中,我们说明了用于 GAN 的一些评价指标 [215],[216]:
3.4.1Inception score(IS)

3.4.2Mode score(MS)
mode score (MS)[26],[219]是IS的改进版本。与IS不同的是,MS可以估量真实分布与生成分布之间的差异。
3.4.3 Frechet初始距离(FID)

3.4.4Multi-scale structural similarity (MS-SSIM)
SSIM[221]被提出用来测量两幅图像之间的相似度。不同于单尺度SSIM测度,MS-SSIM[222]被提出用于多尺度图像质量评估。它通过预测人类感知相似性判断来定量评价图像相似性。MS-SSIM值的取值范围在0.0 ~ 1.0之间,MS-SSIM值越低,图像差异越大。文献[30],[223]使用MS-SSIM测度虚假数据的多样性。文献[224]建议MS-SSIM仅应与FID一起考虑,是检测样本多样性的指标
3.4.5总结
如何为 GAN 选择一个好的评价指标仍然是一个难题 [225]。Xu 等人 [219] 提出了对 GAN 评价指标的实证研究。Karol Kurach [224] 对 GAN 中的正则化和归一化进行了大规模的研究。还有一些其它对于 GAN 比较性的研究,例如 [226]。参考文献 [227] 提出了几种作为元度量的度量依据,以指导研究人员选择定量评价指标。恰当的评价指标应该将真实样本与生成的假样本区分开,验证模式下降(mode drop)或模式崩溃,以及检测过拟合。希望将来会有更好的方法来评价 GAN 模型的质量
3.5任务驱动的GANs
本文的重点关注 GAN 模型。目前,对于涉及特定任务的紧密相关的领域,已经有大量的文献
3.5.1 半监督学习
GANs非常成功的一个研究领域是将生成模型应用于半监督学习[228],[229],正如第一篇论文GANs的提出,但它没有显示出来。
自CatGANs[48]以来,GANs已经成功地用于半监督学习。特征匹配GANs[29]在MNIST、SVHN、CIFAR-10等数据集中使用少量标签的情况下取得了良好的性能。
Odena[230]通过强制判别器网络输出类标签,将GANs扩展到半监督学习。一般来说,当我们训练GANs的时候,我们最终没有使用判别器。判别器只是用来指导学习过程,在我们训练了生成器之后,判别器并不用来生成数据,只使用生成器来生成数据。对于传统的GANs,判别器是一个二分类器,真实数据和生成的数据。在半监督学习中,该判别被升级为多类分类器。对于半监督学习,如果我们想了解一个N类分类器,我们让GANs有可以预测N + 1类输入的判别器,额外的类对应的生成器的输出 。因此,假设我们想学习二分类,苹果和橘子。我们可以制作一个有三个不同标签的分类器:第一类是真正的苹果类,第两类是真正的橙子类,第三类是生成的数据类。系统学习三种数据:真实标记数据,未标记真实数据和假数据。
真实的标签数据:我们可以告诉判别器最大化正确类的概率。例如,如果我们有一张苹果照片,它被标记为一个苹果,我们可以在这个最大化判别器苹果类的概率。
未标记的真实数据:假设我们有一张照片,我们不知道它是苹果还是橘子,但我们知道它是一张真实的照片。在这种情况下,我们训练判别器使所有实际类的概率之和最大化。
假数据:当我们从生成器中获得一个生成的示例时,我们训练判别器将其分类为假示例。
Miyato等人[49]提出了虚拟对抗训练(V AT):是一种监督和半监督学习的正则化方法。Dai等人[231]从理论角度表明,给定判别器目标,好的半监督学习确实需要一个不好的生成器,并提出了优先生成器的定义。提出了三角GAN(∆-GAN)[50]用于半监督跨域联合分布匹配,∆-GAN与Triple-GAN[51]关系密切。Madani等人[232]使用半监督学习与GANs进行胸部x线分级。可以预期,未来对GANs的改进有望同时产生对半监督学习和无监督学习(如自监督学习)的进一步改进[233]。
3.5.2迁移学习
Ganin等人[234]介绍了一种针对域自适应的神经网的对抗性训练方法,其中训练数据和测试数据来自相似但不同的分布。Professor Forcing algorithm 算法[235]使用对抗性域自适应来训练递归网络。Shrivastava等人[236]将GANs用于模拟训练数据。一种新的像素级域自适应扩展名为GraspGAN[237],被提出用于机器人抓[238],[239]。通过使用合成数据和领域适应[237],仅利用随机生成的模拟对象,实现给定性能水平所需的真实世界示例数量减少了50倍。
最近的研究表明,在两个领域的图像-图像迁移[240]-[245]取得了显著的成功。然而,现有的方法,如CycleGAN [53], disco[54]和DualGAN[55],不能直接用于两个以上的域,因为应该为每一对域独立构建不同的方法。StarGAN[56]很好地解决了这一问题,它可以只用一个模型在多个领域进行图像到图像的转换。其他相关著作见[246]、[247]。CoGAN[47]也可以用于多个域。
学习中对公平性表示是一个与域迁移密切相关的问题。注意,对抗性目标的不同公式[248]-[251]实现了不同的公平符号。
域适应[61],[252]可以看作迁移学习的子集[253]。视觉域适应(visual domain adaptation, VDA)方法有:视觉外观适应、表示适应和输出适应,它们分别是基于域的原始输入、特征和输出进行域适应。视觉外观适应:CycleGAN[53]是这类方法的代表。CyCADA[57]基于CycleGAN的视觉外观适应算法。表示适应:ADDA(对抗性判别域适应)[58],[59]的关键是学习一个判别器不能区分它们属于哪个域的特征表示。Sankaranarayanan等人[254]重点研究了基于GANs的真实域和合成域分割网络学习到的表示。提出了一种基于全卷积自适应网络(FCAN)[60]的语义分割算法,该算法结合了视觉外观自适应和表示自适应。输出自适应:Tsai[255]使源图像和目标图像的输出具有相似的结构,使鉴别器无法区分它们。其他基于迁移学习的GAN可以在[52],[256]-[262]中找到。
3.5.3强化学习
生成模型可以通过不同的方式集成到强化学习 (RL)中[107][103],[263]。文献[264]已经讨论了GANs和actor-critic method之间的联系。文献[265]研究了GANs、逆强化学习(IRL)和基于能量的模型之间的联系。这些与RL的连接可能对GANs和RL的开发都有用。此外,GANs与强化学习相结合用于图像合成程序[266]。[267]提出的竞争多智能体学习框架也与GANs相关,并致力于学习对手的鲁棒抓取策略。
模仿学习:在[268]中讨论了模仿学习与EBGAN之间的联系。Ho和Ermon[269]表明,他们框架的一个实例将GANs与模仿学习进行了类比,由此他们导出了一种无模型模仿学习方法,在模拟大型高维环境中的复杂行为时,该方法比现有的无模型算法有显著的性能提升。Song等人[62]提出了多智能体生成对抗性模仿学习(GAIL), Guo等人[270]提出了生成对抗性自模仿学习。在去卷积的多智能体环境重建(DEMER)方法[271]中使用了一个多智能体GAIL框架来学习环境。DEMER在滴滴出行的实际应用中进行了测试,取得了良好的性能。
3.5.4 多模态学习
生成模型,特别是GANs,使机器学习能够处理多模态输出。在许多任务中,一个输入可能对应多个不同的正确输出,每一个都是一个可接受的答案。训练机器学习方法的传统方法,如最小化模型的预测输出和期望输出之间的均方误差(MSE),能够产生许多不同的正确输出的模型训练不出。这种情况的一个实例是预测视频序列中的下一帧,如图6所示。[272] -[275]中有多模态图像对图像翻译的相关著作。

图6:Lotter等人[276]很好地描述了能够建模多模态数据的重要性。在这种情况下,一个模型被训练来预测视频中的下一帧。该视频描述了一个移动的3D头部模型的计算机渲染。左边的图像是ground truth,一个视频的实际帧的实例,模型想要预测它。中间的图像是用模型预测的下一帧和实际的下一帧之间的均方误差(MSE)对模型进行训练时发生的情况。模型被迫只能为下一帧选择一个答案。由于存在多个可能的答案,对应于头部的略微不同的位置,所以模型选择的答案是对多个略微不同的图像的平均值。这导致面部有模糊效果。利用额外的GANs损失,右边的图像能够知道有多个可能的输出,每个输出都是可识别的,清晰的真实的,令人满意的图像。图片来自[276]
3.5.5其他任务驱动的GANs
GAN 已被用于特征学习领域,例如特征选择 [277],哈希 [278]-[285] 和度量学习 [286]。
MisGAN [287] 可以通过 GAN 利用不完整数据进行学习。[288] 中提出了进化型 GAN(Evolutionary GAN)。Ponce 等人 [289] 结合 GAN 和遗传算法为视觉神经元演化图像。GAN 还被用于其它机器学习任务 [290],例如主动学习 [291],[292],在线学习 [293],集成学习 [294],零样本学习 [295],[296] 和多任务学习 [297]。
4理论
在这一节中,我们首先介绍极大似然估计。然后,我们引入模态崩溃。最后讨论了逆映射和记忆等理论问题。
4.1最大似然估计(MLE)
最大似然估计(MLE)
并不是所有生成模型都使用 MLE。一些生成模型不使用 MLE,但可以被修改为使用 MLE(GAN 就属于此类)。可以简单地证明,最小化 Pdata(x) 和 Pg(x) 之间的 KL 散度(KLD)等价于最大化样本数 m 增加时的对数似然:

为保证表示法的一致性,用Pg(x)代替模型的概率分布。更多关于MLE和其他统计估计量的信息,请参阅[298]的第5章。
4.2模式崩溃
GAN 很难训练,并且在 [26],[29] 已经观察到它们经常受到模式崩溃[299],[300] 的影响,其中生成器学习到仅仅根据少数几种数据分布模式生成样本,而忽视了许多其它的模式(即使整个训练数据中都存在来自缺失模式的样本)。在最坏的情况下,生成器仅生成单个样本(完全坍塌)[179],[301]。
在本小节中,我们首先引入 GAN 模式坍塌的两种观点:散度观点和算法观点。然后,我们将介绍通过提出新的目标函数或新的架构以解决模式坍塌的方法,包括基于目标函数的方法和基于架构的方法。
4.2.1两种观点:散度和算法
我们可以从散度和算法两个角度来解决和理解GANs模式的崩溃和不稳定性。
散度观点:Roth等人[302]通过正则化稳定了GANs及其变体的训练,如基于f-散度GANs (f-GAN)。
算法观点:文献[303]分析了常用的训练GANs算法的数值,提出了一种收敛性更好的新算法。Mescheder等人[304]证明了GANs的训练方法实际上是收敛的。
4.2.2克服模式崩溃的方法
基于目标函数的方法:DRAGAN[170]认为,由于在非凸问题中出现了伪局部纳什均衡,导致了模式崩溃的存在。DRAGAN通过约束判别器在真实数据流形周围的梯度来解决这个问题。它增加了一个梯度惩罚项,使判别器在真实数据流形周围有一个梯度范数为1。其他方法,如EBGAN和展开GAN(详细见3.3节)也属于这一类。
基于结构的方法:这类方法中有代表性的方法,如MAD-GAN[46]和MRGAN26。
在GANs中还有其他减少模态崩溃的方法。例如,PACGAN[305]通过改变对判别器的输入来减轻模态崩溃的痛苦。
4.3其他理论问题
4.3.1 GANs真的学习了分布吗?
文献[41],[301],[306]从经验上和理论上都揭示了GANs学习的分布存在模态崩溃的问题。相反,Bai等人[307]表明,如果判别器类对特定的生成器类(不是对所有可能的生成器)具有很强的判别能力,那么GANs原则上可以学习具有多项式样本复杂度的Wasserstein距离(或许多情况下的kl -散度)分布。Liang等人[308]研究了GANs学习密度(包括非参数和参数目标分布)的能力。Singh等[309]进一步研究了对抗性损失的非参数密度估计。
4.3.2散度/距离
Arora等[301]表明GAN的训练可能泛化性不是很好;例如,训练可能看起来很成功,但是生成的分布可能与标准度量的真实数据分布相差很远。常用的距离如 Wasserstein and JS可能不能一般化成。然而,确实通过引入分布之间距离的新概念而普遍化,即神经网络距离。还有其他有用的散度吗?
4.3.3逆映射
GANs无法学习逆映射将数据转化到隐空间中。我们提出了BiGANs[40](详见3.3.3.7节)提出了学习这种逆映射的方法。Dumoulin等人[41]介绍了对抗性推断学习(ALI)模型(详细见3.3.3.7节),该模型利用对抗性过程联合推理学习网络和生成网络。Arora等人[310]指出了像BiGANs[40]和ALI[41]这样的编码器-解码器GAN体系结构的理论局限性。Creswell等人[311]对GANs进行生成器反向。
4.3.4数学观点 例如优化
Mohamed等人[312]在隐式生成模型学习算法中框架GANs,该模型只指定生成数据的随机过程。[313]研究了为GANs设计的优化方法,并在一般变分不等式框架下求解了GANs优化问题。文献[314]讨论了正则化最优传输训练GANs的收敛性和鲁棒性。
4.3.5记忆
对于“记忆GANs”,Nagarajan等人[315]认为,让生成器“学会记忆”训练数据比让生成器“学会输出真实但不可见的数据”更加困难。
5应用
如前所述,GANs是一个强大的生成模型,它可以用随机向量z生成逼真的样本。我们既不需要知道显式的真实数据分布,也不需要任何数学假设。这些优点使 GAN 可以被广泛应用于许多领域,例如图像处理和计算机视觉、序列数据等。
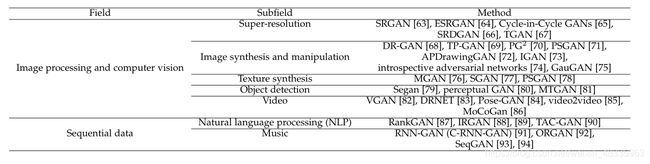
5.1图像处理与计算机视觉
GAN 最成功的的应用是在图像处理和计算机视觉方面,例如图像超分辨率、图像生成与操作和视频处理。
5.1.1超分辨率(SR)
SRGAN[63]是第一个能够推断照片真实的自然图像升级因子的框架。为了进一步提高SRGAN的视觉质量,Wang等人[64]深入研究了SRGAN的三个关键组成部分,并对每个组成部分进行改进,得到了增强的SRGAN (ESRGAN)。例如,ESRGAN使用了来自相对GANs[28]的思想来让判别器估计相对真实性而不是绝对值。得益于这些改进,ESRGAN在PIRM2018-SR挑战赛(区域3)中获得第一名[316],获得了最佳的感知指数。基于CycleGAN[53],提出了用于无监督图像SR的Cyclein-Cycle GANs[65]。SRDGAN[66]提出了利用DualGAN[55]学习SR的噪声先验。深度张量生成对抗网TGAN[67]被提出,通过探索张量结构来生成大量高质量的图像。针对SR有专门的方法[317]-[319]。其他相关方法见[320]-[323]。
5.1.2图像合成和操作
5.1.2.1人脸:
GAN (DR-GAN)[324]被提出用于姿态无关的人脸识别。Huang等人[69]提出了一种双路径GAN (TP-GAN),通过同时感知局部细节和全局结构来合成逼真的正面视图。Ma等人[70]提出了一种新的位姿引导的人物生成网络(PG2),该网络基于一个新的位姿和一个人的图像来合成任意位姿的人图像。Cao等人[325]提出了一种基于GANs的高分辨率人脸正面化高保真度的姿态不变模型。Siarohin等人[326]提出了基于姿态生成人体图像的可变形GANs。在[71]中提出了用于定制化妆转移的姿态鲁棒空间感知GAN (PSGAN)。
与肖像画相关:APDrawingGAN[72]提出了一个层次化的GAN模型,可以有效地将人脸照片生成肖像画。APDrawingGAN有一个基于微信的软件,结果如图8所示。GANs也被用于其他与面部相关的应用,如面部属性更改[327]和肖像编辑[328]-[331]。
人脸生成:GANs生成的人脸质量逐年提高,这一点可以在Sebastian Nowozin的GAN lecture materials1中找到。从图7可以看出,基于原始GANs[3]生成的人脸视觉质量较低,只能作为概念证明。Radford等人[32]使用了更好的神经网络架构:用于生成人脸的深度卷积神经网络。Roth等人[302]解决了GAN培训的不稳定性问题,允许使用更大的架构,如ResNet。Karras等人利用了多尺度训练,实现了高保真度的百万像素人脸图像生成。
人脸生成[332]-[340]比较容易,因为只有一类对象。每个物体都是一张脸,大多数面部数据集往往是由直视镜头的人组成的。大多数人都把鼻子、眼睛和其他地标放在一致的位置。

图7:人脸图像合成

图8:给定照片如(a), APDrawingGAN可以产生相应的艺术肖像图(b)。
5.1.2.2通用对象:
让GANs处理像ImageNet[151]这样有1000个不同对象类的分类数据集有点困难。然而,我们在最近几年看到了迅速的进展。这些图像的质量逐年提高[304]。
大多数论文使用GANs来合成二维图像[341],[342],Wu等人[343]使用GANs和体积卷积合成三维(3-D)样本。Wu等人[343]合成了汽车、椅子、沙发、桌子等新奇物体。Yang等人[345]提出了分层递归生成对抗网络 (LR-GAN)图像生成。
5.1.2.3人与图像生成过程的交互作用:
有许多应用程序涉及到人与图像生成过程之间的交互。逼真的图像操作是困难的,因为它需要以用户控制的方式修改图像,又要使图像看起来逼真。如果用户没有好的技巧,在编辑时很容易偏离自然图像。交互式GAN (IGAN)[73]定义了一类图像编辑操作,并将它们的输出一直限制在所学的流形上。自省对抗网络[74]也提供了这种能力来执行交互式照片编辑,并在面部编辑中应用。GauGAN[75]可以把涂鸦变成令人惊叹的、逼真的风景。
5.1.3 纹理合成
纹理合成是图像领域的一个经典问题。马尔可夫生成对抗网络 (MGAN)[76]是一种基于GANs的纹理合成方法。MGAN通过捕获马尔科夫碎片的纹理数据,可以非常快速地生成程式化的视频和图像,从而实现实时纹理合成。Spatial GAN (SGAN)[77]首先将GANs与完全无监督学习应用于纹理合成。PSGAN[78]是SGAN的一种变体,它可以从单个图像或复杂的大数据集中学习周期纹理。
5.1.4目标检测
如何确定物体检测器能够应对被遮蔽,不同角度或变形的图像?一种方法是使用数据驱动的策略,收集一个巨大的数据集——覆盖所有条件下物体的样子。我们希望最终的分类器可以使用这些实例来学习不变性。是否有可能看到数据集中所有的遮蔽与变形?有些非常少见,在实际应用中很少发生;然而,我们想学习一种不因这种情况而改变的方法。Wang等人[346]使用GANs生成具有遮蔽与变形的实例。对抗的目标是生成物体探测器难以识别的例子。通过使用分割器和GANs, Segan[79]检测到图像中被其他物体遮挡的物体。为了解决小目标检测问题,Li等人[80]提出了感知GAN, Bai等人[81]提出了端到端多任务GAN (MTGAN)。
5.1.5视频应用
文献[82]是第一篇使用GANs进行视频生成的论文。Villegas等人[347]提出了一种深度神经网络,用于使用GANs预测自然视频序列中的未来帧。Denton和Birodkar[83]提出了一种解耦表示网络DRNET的新模型,该模型基于GANs从视频中学习解耦图像表示。在生成对抗学习框架下,提出了一种新的视频到视频合成方法(video2video)[85]。MoCoGan[86]被提出用于分解运动和内容视频生成[348]-[350]。
GANs也被用于其他视频应用,如视频预测[84]、[351]、[352]和视频重定向[353]。
5.1.6其他图像和视觉应用
GANs一直在利用其他图像处理和计算机视觉任务[354],[357],如对象变形[358],[359],语义分割[360],视觉显著预测[361],对象跟踪[362],[363],图像去雾[364],[366],[367]自然图像抠图,图像修复[368],[369],[370]图像融合、图像完成[371],[372]和图像分类。
Creswell等人[373]表明,GANs学到的表示也可以用于检索。GANs也被用于预测人们将会去哪里看[374],[375]。
5.2序列数据
GAN 也在序列数据上取得了一定成就如自然语言、音乐、语音、音频 [376], [377]、时间序列 [378]–[381] 等。
自然语言处理(NLP): IRGAN[88],[89]被提出用于信息检索(IR)。Li等人[382]使用对抗性学习来生成神经对话。GANs还被用于文本生成[87]、[383]-[385]和语音语言处理[94]。Kbgan[386]被提出用于生成高质量的反例,并用于知识图嵌入。对抗性奖励学习(AREL)[387]被提出用于视觉叙事。DSGAN[388]被提出用于远程监控关系抽取。ScratchGAN[389]被提出用于从零开始训练语言GAN——不需要最大似然预训练。
Qiao等人[90]通过重描述学习文本到图像的生成,并提出了用于文本到图像的文本条件辅助分类器GAN (TAC-GAN)[390]。GANs也被广泛应用于图像到文本(图像标题)[391]和[392]。
此外,GANs在其他自然语言处理应用中也得到了广泛的应用,如问题答案选择[393]、[394]、诗歌生成[395]、人才-工作匹配[396]、审查检测与生成[397]、[398]。
音乐:GANs被用于产生音乐,如连续RNN-GAN (C-RNN-GAN) [91], ObjectReinforced GAN (ORGAN) [92], SeqGAN[93],[94]。
语音和音频:GANs被用于语音和音频分析,如合成[399]-[401]、增强[402]和识别[403],。
5.3其他应用程序
医学领域:GANs被广泛应用于医学领域,如DNA的生成与设计[404]、[405]、药物发现[406]、多标签离散患者记录的生成[407]、医学图像处理[408]-[415]、牙齿修复[416]、医生推荐[417]。
数据科学:GANs被用于数据生成[214]、[418]-[426]、神经网络生成[427]、数据增强[428]、[429]、空间表示学习[430]、网络嵌入[431]、异构信息网络[432]和移动用户配置[433]。
GANs已广泛应用于许多其他领域,如恶意软件检测[434]、下棋[435]、隐写术[436]-[439]、隐私保护[440]-[442]、社交机器人[443]和网络修剪[444]、[445]。
6开放性研究问题
由于GANs在整个深度学习领域非常流行,其局限性最近得到了改善[446],[447]。GANs还有一些有待解决的研究问题。
将 GAN 用于离散数据:GAN 依赖于生成参数关于生成样本是完全可微的。因此,GAN 无法直接生成离散数据,例如哈希编码和独热(one-hot)向量。解决此类问题非常重要,因为它可以释放 GAN 在自然语言处理和哈希计算中的潜力。Goodfellow 提出了三种解决这个问题的方法 [103]:使用 Gumbel-softmax [448],[449] 或离散分布 [450];利用强化算法 [451];训练生成器以采样可转换为离散值的连续值(例如,直接对单词的嵌入向量进行采样)。
还有其他方法朝着该研究方向发展。Song 等人 [278] 使用了一个连续函数来近似哈希值的符号函数。Gulrajani 等人 [19] 用连续生成器建模离散数据。Hjelm 等人 [452] 引入了一种用离散数据训练 GAN 的算法,该算法利用来自判别器的估计差异度量来计算生成样本的重要性权重,从而为训练生成器提供了策略梯度。可以在 [453],[454] 中找到其它的相关工作。在这个有趣的领域需要有更多的工作出现。
新的散度:研究者提出了一系列用于训练 GAN 的新的积分概率度量(IPM),如 Fisher GAN [455],[456],均值和协方差特征匹配 GAN(McGan)[457] 和 Sobolev GAN [458]。是否还有其它有趣的散度类别?这值得进一步的研究。
估计不确定性:通常来说,我们拥有的数据越多,估计的不确定性会越小。GAN 不会给出生成训练样本的分布,但 GAN 想要生成和训练样本分布相同的新样本。因此,GAN 既没有似然也没有明确定义的后验分布。目前已经有关于这个方向研究的初步尝试,例如 Bayesian GAN [459]。尽管我们可以利用 GAN 生成数据,但是如何度量训练好的生成器的不确定性呢?这是另一个值得未来研究的有趣问题。
理论:关于泛化问题,Zhang 等人 [460] 提出了在不同评价指标下的真实分布和学习到的分布之间的泛化界。当用神经距离进行评价时,[460] 中的泛化界表明,只要判别器的集合足够小,无论假设集或生成器集合的大小如何,泛化性都是可以保证的。Arora 等人 [306] 提出了一种新颖的测试方法,使用离散概率的「生日悖论」来估计支撑集大小,并且表明即使图像具有较高的视觉质量,GAN 也会受到模式坍塌的影响。更深入的理论分析非常值得研究。我们如何经验性地测试泛化性?有用的理论应当能够选择模型的类别、容量和架构。这是一个值得未来工作深入研究的有趣问题。
其它:GAN 领域还有许多其它重要的研究问题,如评估方式(详见 3.4 小节)和模式崩溃(详见 4.2 小节)。
7结论
本文对GANs的各个方面进行了全面的综述。本文从算法、理论、应用和有待解决的研究问题等几个方面进行了阐述。我们相信这项调查将有助于读者对GANs的研究领域有一个全面的了解。