Read, Attend and Comment: A Deep Architecture for Automatic News Comment Generation 读书笔记
Read, Attend and Comment: A Deep Architecture for Automatic News Comment Generation 读书笔记
介绍
论文引用:
Yang Z, Xu C, Wu W, et al. Read, Attend and Comment: A Deep Architecture for Automatic News Comment Generation[J]. arXiv preprint arXiv:1909.11974, 2019.
下载地址:https://arxiv.org/pdf/1909.11974.pdf
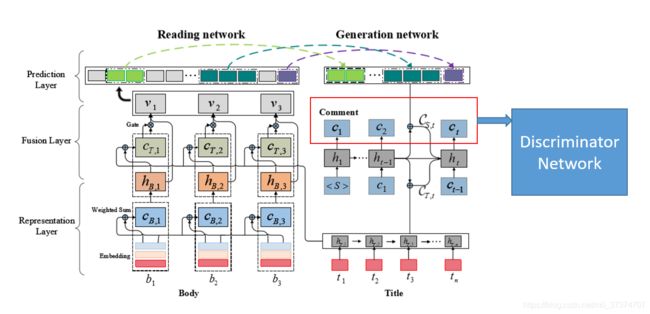
论文中设计了一个自动生成新闻评论的深层架构 DeepCom,包括一个阅读网络和一个生成网络,其中阅读网络主要有三层:表示层、融合层、预测层,生成网络使用阅读网络提取的片段和注释生成评论。使用了两个数据集进行测试,并且比对了其他六种生成评论的模型,其结果明显优于其他模型。
主要工作
- 提出了包含一个阅读网络和一个生成网络的新闻评论生成的“阅读-参与-评论”过程;
- 采用端到端学习方法对两个网络进行联合优化;
- 在两个数据集上验证了所提模型的有效性。
使用的数据集
-
腾讯新闻数据集(2018年)
数据集地址为 :https://ai.tencent.com/upload/PapersUploads/article_commenting.tgz
关于数据集的介绍在以下这篇论文中有提及
Qin, Lianhui, et al. “Automatic article commenting: the task and dataset.” arXiv preprint arXiv:1805.03668 (2018).
该论文地址:https://arxiv.org/pdf/1805.03668v1.pdf
以下是我截取这篇论文中作者对一个新闻下评论的类型判定标准,分为1-5分,分数越高,内容越丰富且清晰。详细信息见表1。
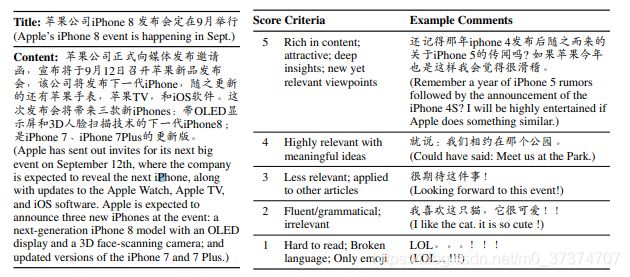
表1 腾讯新闻数据集类型评判标准
| 类别 | 标准 |
|---|---|
| 5 | 内容丰富 有吸引力 深刻的洞察力 新的相关观点 |
| 4 | 与有意义的想法相关性高 |
| 3 | 不太相关、适用于其他新闻 |
| 2 | 流利/合乎语法的,但是不相关 |
| 1 | 很难去读的、只有符号表情、存在错误的评论 |
- 通过从雅虎抓取的新闻文章和评论的英文数据集
方法
问题定义
有一个数据集如下 D = { ( T i , B i , C i ) } i = 1 N D = {\{(T_i,B_i,C_i)\}} _{i=1}^N D={(Ti,Bi,Ci)}i=1N
表示数据集D中有N个三元组 ,其中第i个三元组为 ( T i , B i , C i ) (T_i,B_i,C_i) (Ti,Bi,Ci)。 T i T_i Ti为新闻标题 , B i B_i Bi为新闻正文, C i C_i Ci为评论。
目标 为从D中估计 P ( C ∣ T , B ) P(C|T,B) P(C∣T,B)的概率分布,然后输入为 ( T , B ) (T,B) (T,B),根据 P ( C ∣ T , B ) P(C|T,B) P(C∣T,B) 生成一个评论C
模型

该模型由一个阅读网络和一个生成网络组成。阅读网络首先在表示层(representation layer)中分别表示新闻标题(title)和新闻正文(body),然后通过融合层将标题融合到正文中,形成对整篇文章的表示,最后通过预测层从文章中提取出一些明显的片段,然后将明显的片段和新闻标题反馈到生成网络以合成评论。
将问题中的 P ( C ∣ T , B ) P(C|T,B) P(C∣T,B)进一步扩展为
P ( C ∣ T , B ) = P ( S ∣ T , B ) ⋅ P ( C ∣ S , T ) P(C|T,B) = P(S|T,B)·P(C|S,T) P(C∣T,B)=P(S∣T,B)⋅P(C∣S,T)
其中 S = ( s 1 , … , s w ) S=( s_1,…,s_w ) S=(s1,…,sw)表示新闻正文B中的片段, P ( S ∣ T , B ) P(S|T,B) P(S∣T,B)表示阅读网络, P ( C ∣ S , T ) P(C|S,T) P(C∣S,T)表示生成网络。
阅读网络
一、表示层
-
标题 T = ( t 1 , . . . , t n ) T = (t_1,...,t_n) T=(t1,...,tn) tj表示第j个单词
内容 B = ( b 1 , . . . , b m ) B = (b_1,...,b_m) B=(b1,...,bm) bk表示第k个单词相关联的新闻内容
将标题T和正文内容B分别做Embedding,将tj 和 bk分别表示为 eT,j 和 eB,k -
为了保留单词在新闻正文中的位置,使用oB,k 和sB,k 扩展eB,k ,其中oB,k 表示bk在句子中的位置,sB,k 表示句子在整个正文中的位置。所以将新的正文Embedding表示为 e ^ \widehat{e} e B,k = MLP([eB,k ;oB,k ;sB,k ]),其中MLP() 指具有两层的多层感知器
-
如模型图所示,首先处理初始的新闻标题和正文的表示 : ξ T = ( e T , 1 , . . . , e T , n ) \xi_T=(e_{T,1},... ,e_{T,n} ) ξT=(eT,1,...,eT,n)和 ξ B = ( e ^ T , 1 , . . . , e ^ T , 1 ) \xi_B=(\widehat{e}_{T,1},... ,\widehat{e}_{T,1}) ξB=(e T,1,...,e T,1)
使用RNN-GRUs处理新闻标题T,得到一个隐藏层 H T = ( h T , 1 , . . . , h T , n ) H_T = (h_{T,1},...,h_{T,n}) HT=(hT,1,...,hT,n) ,将新闻正文B转换为 H B = ( h B , 1 , . . . , h B , m ) H_B = (h_{B,1},...,h_{B,m}) HB=(hB,1,...,hB,m),其中 h B , k h_{B,k} hB,k定义为MLP([ e ^ \widehat{e} e B,k ;c B,k ]),c B,k 是attention-pooling层的第k个向量, 其计算表示为 dot-att( ξ B , e ^ B , k \xi_B,\widehat{e}_{B,k} ξB,e B,k),具体计算过程如下:
c B , k = ∑ j = 1 m α k , j e ^ B , j c_{B,k} = \sum_{j=1}^m \alpha_{k,j} \widehat{e}_{B,j} cB,k=j=1∑mαk,je B,j 其中 α B , k \alpha_{B,k} αB,k为
α B , k = e s k , j / ∑ l = 1 m e s k , l \alpha_{B,k} = e^{s_{k,j}} / \sum_{l=1}^m e^{s_{k,l}} αB,k=esk,j/l=1∑mesk,l其中 s k , j s_{k,j} sk,j为词与词之间的位置
s k , j = ( e ^ B , k T , e ^ B , j ) / d 1 s_{k,j} = (\widehat{e}_{B,k}^T,\widehat{e}_{B,j})/ \sqrt {d1} sk,j=(e B,kT,e B,j)/d1
二、融合层
融合层将上述生成的 H T H_T HT和 H B H_B HB作为输入,并将 H T H_T HT与 H B H_B HB融合,生成 V = ( v 1 , … , v m ) V=(v_1,…,v_m) V=(v1,…,vm)作为整个新闻文章的新表示.
v k = h B , k + g k ⨀ c T , k v_k = h_{B,k}+g_k \bigodot c_{T,k} vk=hB,k+gk⨀cT,k 其中 g k g_k gk为门(Gate)
g k = σ ( W g [ h B , k ; c T , k ] ) g_k = \sigma(W_g[h_{B,k};c_{T,k}]) gk=σ(Wg[hB,k;cT,k])
三、预测层

如图所示,基于融合层生成的 V = ( v 1 , … , v m ) V=(v_1,…,v_m) V=(v1,…,vm),使用 S = ( ( a 1 , e 1 ) , … , ( a w , e w ) ) S=((a_1,e_1),…,(a_w,e_w)) S=((a1,e1),…,(aw,ew))表示显著性分段其中 a i a_i ai 和 e i e_i ei 指代第 i 个分段的开始点和终止点的位置。将 V = ( v 1 , … , v m ) V=(v_1,…,v_m) V=(v1,…,vm)作为输入,最后将输出 L = ( l 1 , … , l m ) L=(l_1,…,l_m) L=(l1,…,lm),如果第k个词为片段的起始点,则 l k = 1 l_k =1 lk=1,否则 l k = 0 l_k =0 lk=0
给定 a k a_k ak,终止位置 e k e_k ek 可以通过指针网络 ( α α k , 1 , . . . , α α k , m ) ( \alpha_{\alpha_k,1} ,...,\alpha_{\alpha_k,m}) (ααk,1,...,ααk,m)得到
α α k , j = e s α k , j / ∑ l = 1 m e s α k , l \alpha_{\alpha_k,j} = e^{s_{\alpha_k,j}} / \sum_{l=1}^m e^{s_{\alpha_k,l}} ααk,j=esαk,j/l=1∑mesαk,l s α k , j s_{\alpha_k,j} sαk,j计算词之间的联系
s α k , j = V T t a n h ( W v v j + W h h a k , 1 ) s_{\alpha_k,j} = V^T tanh(W_vv_j+W_hh_{a_k,1}) sαk,j=VTtanh(Wvvj+Whhak,1)
h a k , 1 = G R U ( h 0 , [ c 0 ; v a k ] ) h_{a_k,1} =GRU(h_0,[c_0;v_{a_k}]) hak,1=GRU(h0,[c0;vak]) 其中GRU为门控循环单元, h 0 = a t t ( V , r ) h_0 = att(V,r) h0=att(V,r)是注意力池化矢量,计算如下:
h 0 = ∑ j = 1 m β j ⋅ v j h_0 = \sum_{j=1}^m \beta_j \cdot v_j h0=j=1∑mβj⋅vj
β j = e β j ′ / ∑ l = 1 m e ( β j ′ ) \beta_j = e^{\beta_j^{'}} / \sum_{l=1}^m e^{(\beta_j^{'})} βj=eβj′/l=1∑me(βj′)
β j ′ = V 1 T t a n h ( W v , 1 v j + W h , 1 r ) \beta_j^{'} = V_1^T tanh(W_{v,1}v_j+W_{h,1}r) βj′=V1Ttanh(Wv,1vj+Wh,1r)
用 start 表示显著性分段的起始位置$(a_1,…,a_w) $,用 p i p_i pi 表示 P ( l i = 1 ) P(l_i=1) P(li=1),于是阅读网络的输出 P(S|T,B) 可以表示为:
P ( S ∣ T , B ) = ∏ k = 1 w [ p a k ⋅ α α k , e k ] ∏ i ∉ s t a r t , 1 ≤ i ≤ m [ 1 − p i ] P(S|T,B) = \prod_{k=1}^w [p_{a_k} \cdot \alpha_{\alpha_k,e_k}] \quad \quad \prod_{i\notin start, 1 \leq i \leq m} [1 - p_i] P(S∣T,B)=k=1∏w[pak⋅ααk,ek]i∈/start,1≤i≤m∏[1−pi]
生成网络
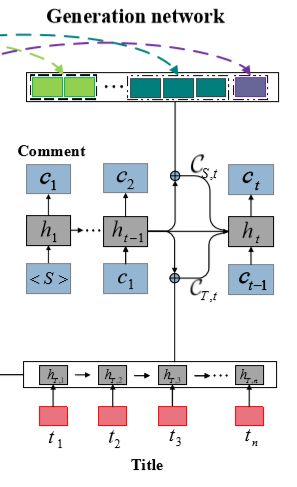
在阅读网络中得到了
- 显著性片段 S = ( ( a 1 , e 1 ) , … , ( a w , e w ) ) S=((a_1,e_1),…,(a_w,e_w)) S=((a1,e1),…,(aw,ew))
- 新闻标题表示 H T = ( h T , 1 , . . . , h T , n ) H_T = (h_{T,1},...,h_{T,n}) HT=(hT,1,...,hT,n)
- 新闻正文表示 V = ( v 1 , … , v m ) V=(v_1,…,v_m) V=(v1,…,vm)
- 阅读网络 P(S|T,B)
可以得到显著性片段S的隐藏层表示 H S = ( v a 1 , v a 1 + 1 , . . . , v e 1 , . . . , v a w , v a w + 1 , . . . , v e w ) . H_S = (v_{a_1},v_{a_1+1},...,v_{e_1},...,v_{a_w},v_{a_w+1},...,v_{e_w}). HS=(va1,va1+1,...,ve1,...,vaw,vaw+1,...,vew).
向生成网络输入 HT 和 HS,然后按词解码输出评论。在第 t 步,其隐状态为:
h t = G R U ( h t − 1 , [ e C , t − 1 ; C T , t − 1 ; C S , t − 1 ] ) h_t =GRU(h_{t-1},[e_{C,t-1};C_{T,t-1};C_{S,t-1}]) ht=GRU(ht−1,[eC,t−1;CT,t−1;CS,t−1])
通过att()来计算 C T , t − 1 和 C S , t − 1 C_{T,t-1}和C_{S,t-1} CT,t−1和CS,t−1 即 C T , t − 1 = a t t ( H T , h t ) C S , t − 1 = a t t ( H S , h t ) C_{T,t-1} = att(H_T,h_t) \quad C_{S,t-1}=att(H_S,h_t) CT,t−1=att(HT,ht)CS,t−1=att(HS,ht)
进一步得到单词表的概率分布: P ˉ t = s o f t m a x ( V [ h t ; C T , t ; C S , t ] + b ) \bar P_t = softmax(V[h_t;C_{T,t};C_{S,t}] + b) Pˉt=softmax(V[ht;CT,t;CS,t]+b)
定义评论 C = ( c 1 , … , c o ) C = (c_1,…,c_o) C=(c1,…,co),其中 c k c_k ck为整个评论词汇中的第k个单词的索引
最终生成网络P(C|S,T)可以定义为:
P ( C ∣ S , T ) = P ( c 1 ∣ S , T ) ∏ t = 2 o P ( c t ∣ c 1 , . . . , c t − 1 , S , T ) \qquad \qquad \qquad \qquad \qquad P(C|S,T) = P(c_1|S,T) \prod_{t=2}^o P(c_t|c_1,...,c_{t-1},S,T) P(C∣S,T)=P(c1∣S,T)t=2∏oP(ct∣c1,...,ct−1,S,T)
= P ˉ 1 ( c 1 ) ∏ t = 2 o P ˉ t ( c t ) =\bar P_1(c_1) \prod_{t=2}^o \bar P_t(c_t) =Pˉ1(c1)t=2∏oPˉt(ct)
学习方法
模型的目标是从 D={(Ti,Bi,Ci)}中学习 P(S|T,B) 和 P(C|S,T),但是在实际情况中,S 很难得到。为了解决这个问题,作者将 S 视为一个隐变量,然后考虑如下的目标函数:
J = ∑ i = 1 N l o g P ( C i ∣ T i , B i ) = ∑ i = 1 N l o g ( ∑ S i ∈ S P ( S i ∣ T i , B i ) P ( C i ∣ S i , T i ) ) J= \sum_{i=1}^N logP(C_i|T_i,B_i) = \sum_{i=1}^N log (\sum_{S_i \in S} P(S_i|T_i,B_i)P(C_i|S_i,T_i)) J=i=1∑NlogP(Ci∣Ti,Bi)=i=1∑Nlog(Si∈S∑P(Si∣Ti,Bi)P(Ci∣Si,Ti))
S 指分段集的空间,Si 为 (Ti,Bi) 的隐分段集。尝试最大化 J 的下界:
ζ = ∑ i = 1 N ∑ S i ∈ S P ( S i ∣ T i , B i ) l o g P ( C i ∣ S i , T i ) < J \zeta = \sum_{i=1}^N \sum_{S_i \in S}P(S_i|T_i,B_i) log P(C_i|S_i,T_i) < J ζ=i=1∑NSi∈S∑P(Si∣Ti,Bi)logP(Ci∣Si,Ti)<J
引入一个 Θ \Theta Θ设为模型的所有参数,求 ζ \zeta ζ关于 Θ \Theta Θ的偏导 , 即 ∂ ζ i ∂ Θ \frac{\partial \zeta_i}{\partial \Theta} ∂Θ∂ζi,求解如下:
∂ ζ i ∂ Θ = ∑ S i ∈ S P ( S i ∣ T i , B i ) [ ∂ l o g P ( C i ∣ S i , T i ) ∂ Θ + l o g P ( C i ∣ S i , T i ) ∂ l o g P ( S i ∣ T i , B i ) ∂ Θ ] \frac{\partial \zeta_i}{\partial \Theta} = \sum_{S_i \in S}P(S_i|T_i,B_i)[\frac{\partial logP(C_i|S_i,T_i) }{\partial \Theta} + log P(C_i|S_i,T_i) \frac{\partial logP(S_i|T_i,B_i)}{\partial \Theta}] ∂Θ∂ζi=Si∈S∑P(Si∣Ti,Bi)[∂Θ∂logP(Ci∣Si,Ti)+logP(Ci∣Si,Ti)∂Θ∂logP(Si∣Ti,Bi)]
为了计算梯度,需要找到 ( T i , B i ) (T_i, B_i) (Ti,Bi)对应的所有分段 Si,但这是很难实现的。因此作者采用蒙特卡洛采样方法来近似 ∂ ζ i ∂ Θ \frac{\partial \zeta_i}{\partial \Theta} ∂Θ∂ζi。假设有 j 个样本,那么 ∂ ζ i ∂ Θ \frac{\partial \zeta_i}{\partial \Theta} ∂Θ∂ζi的近似为: 1 j ∑ n = 1 j [ ∂ l o g P ( C i ∣ S i , n , T i ) ∂ Θ + l o g P ( C i ∣ S i , n , T i ) ∂ l o g P ( S i , n ∣ T i , B i ) ∂ Θ ] \frac{1}{j} \sum_{n=1}^j[\frac{\partial logP(C_i|S_{i,n},T_i) }{\partial \Theta} + log P(C_i|S_{i,n},T_i) \frac{\partial logP(S_{i,n}|T_i,B_i)}{\partial \Theta}] j1n=1∑j[∂Θ∂logP(Ci∣Si,n,Ti)+logP(Ci∣Si,n,Ti)∂Θ∂logP(Si,n∣Ti,Bi)]
实验
基线模型
- IR-T 和 IR-TC:这两个模型通过 TF-IDF 矢量的余弦角检索候选文章以及相关评论,然后使用卷积神经网络对评论进行排序,返回排在最前的评论。IR-T 只利用新闻标题信息,IR-TC 利用新闻标题和正文。
- Seq2Seq:基础的序列转换模型,从标题中生成评论。
- Att 和 Att-TC:注意力机制的序列转换模型。Att 只利用新闻标题信息,Att-TC 利用新闻标题和正文。输入为标题(Att)或标题和新闻主体(Att-TC)。
- GANN:门控注意力神经网络。
实验结果
以下是对两个数据集进行的自动测量和人工判断的评估结果。对比了七种不同的模型,在大多数自动评价指标上,DeepCom 超过了基线方法,并且提升程度很高(加粗字体的部分 )。

阅读总结
目前DeepCom中包含了阅读网络和生成网络,从而模拟人对新闻进行评论时的“阅读 - 关注 - 评论”行为。从实验结果来看,在这两个数据集上该模型要优于Seq2Seq、Att、GANN等模型
想到的应用方面有:
- 聊天机器人
- 舆论引导
- 文章摘要生成
进一步扩展模型, 在生成网络后面再增加一层网络:判别网络,将生成的评论再次阅读后传入判别网络,检测生成的结果是否符合一定的标准,如果不符合,调整参数重新生成。