搜索历史、推理未来:时序知识图谱上的两阶段推理
©原创作者 | 朱林
01 介绍
一个普通的知识图谱只拥有某一时刻的静态事实,常见表示为图的形式,如图1所示,包含了实体e(圆)及其关系r(箭头)。

图1 知识图谱示意图
目前快速增长的数据往往表现出复杂的时间动态特性,可以描述为时序知识图谱(Temporal Knowledge Graphs, TKG),其是在知识图谱的基础上加上了时间信息t。
TKG已经广泛运用于许多不同的领域,具有代表性的TKG数据集包括全球事件、语言和语气数据库(Global Database of Events, Language, and Tone, GDELT)和综合危机预警系统(Integrated Crisis Early Warning System, ICEWS)等等。
图2展示了ICEWS系统的一个外交活动记录子图。

图2 ICEWS外交活动记录子图
TKG的预测问题是在已知过去的历史线索信息(实体及关系在时间上的序列)下推断未来某一潜在事实或事件。
那人类是如何预测未来事件的呢?根据心理学著名的双重过程理论,人类首先是搜索海量记忆,直观地找到一些相关的历史信息(即线索)。
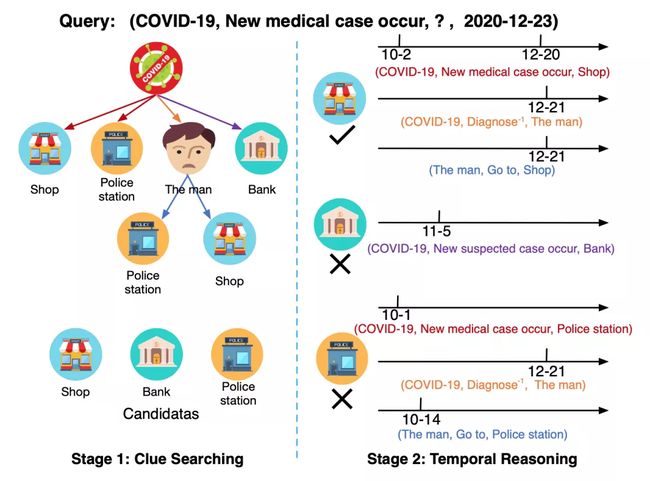
图3 受人类认知启发的推理过程示意图关系
如图3左侧所示,人们需要根据之前线索预测2020年12月23日COVID-19在哪里出现新病例,可以描述为回答查询: (COVID-19, New medical case occur, ?, 2020-12-23)中的?。
其中,找到至关重要的线索有:
1)与查询有相同关系的一跳(1-hop)路径(去除时间信息后直接关联实体和关系)。例如(COVID-19,New medical case occur, Shop);
2)与查询有不同关系的一跳路径,例如(COVID-19, New suspected case occur, Bank);
3)二跳路径,例如(COVID-19, Diagnose-1, The man, Go to, Police station)。其中Diagnose-1表示Diagnose反关系。
人们从他们的记忆中回忆起这些线索,并给出一些直观的候选答案。然后,人们通过深入挖掘线索的时间信息,进行细致的推理过程,得到准确的答案。
如图3右侧所示,该男子比确诊COVID-19的时间早了两个多月去派出所,这表明派出所可能不是答案。所以得出答案为商店。
现有模型主要关注上述第二个过程,但轻视了第一个过程。因此,本文作者提出CluSTeR模型,以两阶段的方式来预测未来,包括线索搜索(Clue Searching)和时序推理(Temporal Reasoning)。
具体而言,在线索搜索阶段,CluSTeR将线索搜索过程形式化为马尔可夫决策过程(MDP)并通过学习Beam Search策略来求解。
在时序推理阶段,CluSTeR将在前一阶段找到的线索重新组织成一系列图,然后使用图卷积网络(GCN)和门控循环单元(GRU)从图中推断出准确的答案。
在四个数据集上的实验证明了CluSTeR模型与目前最先进的方法相比有巨大优势。此外,CluSTeR模型发现的线索可以进一步为推理结果提供可解释性。
02 CluSTeR模型
符号定义

模型概述
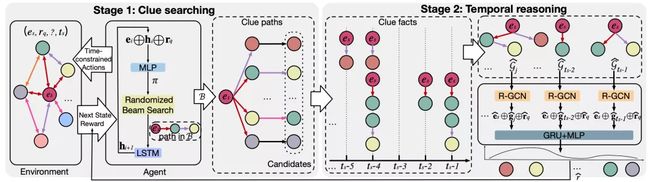
图4 CluSTeR模型的说明图
如图所示,该模型由两个阶段组成,线索搜索和时序推理。具体而言,第一阶段主要侧重于在时序限制下搜索与给定查询相关的组合语义信息的线索路径。
然后,提供线索路径和随之生成的候选实体用于第二阶段的推理。
第二阶段主要侧重于对线索事实之间的时序信息进行建模,并得到最终结果。
在CluSTeR模型中,这两个阶段在训练阶段相互作用,在推断阶段共同决定最终答案。
第一阶段:线索搜索
强化学习系统
作者将第一阶段视为一个顺序决策问题,由强化学习系统解决。
作者的强化学习系统采用的是马尔可夫决策过程(MDP),这是一个从Agent和Environment之间的交互中学习以找到B条有希望线索路径的框架。由以下部分组成:

语义策略网络

Randomized Beam Search
在TKG的场景中,一个事实的发生可能是由多种因素造成的。因此,预测需要多条线索路径。此外,第一阶段的候选应该尽可能多地找到正确的答案。
因此,作者采用Randomized Beam Search作为Agent的动作采样策略,它按顺序向Beam Search注入随机噪声增加Agent的探索能力。
训练时通过最大化训练集中所有查询的预期奖励来训练Beam Search策略网络,如以下公式所示:
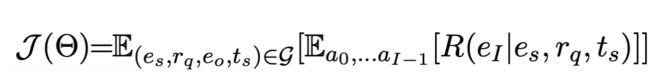
第二阶段:时序推理
为了更深入地了解不同时间戳的线索事实之间的时间信息以及并发线索事实之间的结构信息,第二阶段将所有线索事实重组为一系列图
![]()
其中每个
![]()
是一个多关系图,
由时间戳
![]()
处的线索事实组成。
作者使用w层RGCN进行建模,
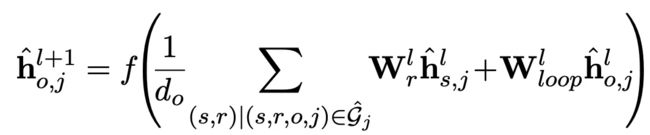
并将
![]()
的串联
(第二阶段中
![]()
的嵌入)送入GRU,

GRU的最终输出,表示为
![]()
,
被送入一个用
![]()
参数化的MLP解码器,
以获得所有实体的最终分数,即:
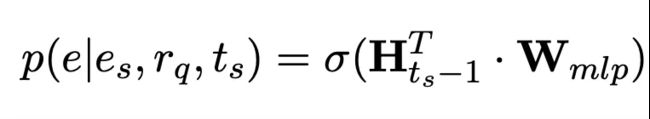
其中
![]()
是sigmoid激活函数。
最后,作者对候选实体重新排序得到结果。
训练时,作者使用交叉熵定义目标函数,
如以下公式所示:

03 实验
推理结果

表1 与静态模型(上)和时序模型(下)相比,TKG推理的实验结果(百分比)
TKG推理的结果如表1所示。CluSTeR在所有ICEWS数据集上的表现始终优于基线。特别是在ICEWS14上,CluSTeR甚至在最佳基线上各个指标上实现了巨大的改进。
具体分析来看,CluSTeR显著优于静态模型是因为它捕获了一些重要历史的时间信息。而性能明显优于那些时序模型,则是因为它专注于更重要的线索,对更长的历史线索进行建模,采用了强化学习以找到更明确可靠的线索。
消融研究
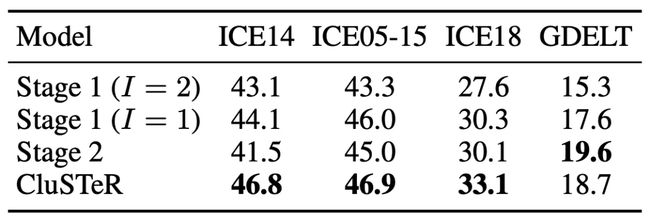
表2 CluSTeR的不同变体在所有数据集上的结果(百分比)
表2显示消融研究的结果,前两行展示了仅使用第一阶段模型的结果,其中最大步长I分别设置为1和2。
可以观察到,仅使用第一阶段时结果会变差,因为忽略了事实之间的时间信息。
第三行显示了仅使用第二阶段提取的一跳重复线索作为输入的结果,所有ICEWS数据集的结果都会变差,这表明仅重复线索不足以进行预测。
对于GDELT,只有第二阶段达到了最好的结果,这是因为在第二阶段中只使用最直接的重复线索可以减轻抽象概念产生噪声的影响。
04 结论
在本篇论文中,作者从人类认知的角度提出了一个两阶段模型,命名为CluSTeR,用于TKG推理。
CluSTeR模型由基于RL的线索搜索阶段和基于GCN的时序推理阶段组成。
在第一阶段,CluSTeR从历史中找到可靠的线索路径,并通过RL生成直观的候选实体。
第二阶段,以找到的线索路径为输入,将线索路径导出的线索事实重组为一系列图,并对其进行推导得到答案。
通过这两个阶段,该模型在TKG推理上表现出巨大的优势。
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。