chinese-ocr-lite(pytorch) 转 caffe
chinese-ocr-lite 转 caffe
前言
将 https://github.com/DayBreak-u/chineseocr_lite/tree/master 其中的 crnn_lite_dense_dw.pth 转caffe,由于转化是为了支持嵌入式端使用而准备,所以这里只转换 crnn_lite_dense_dw.pth
准备阶段
https://github.com/DayBreak-u/chineseocr_lite/tree/master/models
https://github.com/Wulingtian/yolov5_onnx2caffe
必要环境
1、python
2、onnx
3、caffe
4、pytorch
5、onnx-simplifier
PS:上诉版本全部CPU版本也可以
安装
1、python3::不详讲
2、onnx:pip install onnx
3、pytorch:不详讲
4、caffe:不详讲(pycaffe)
5、onnx-simplifier:pip install onnx-simplifier
修改模型
生成onnx
主要参考:
https://zhuanlan.zhihu.com/p/113338890?utm_source=qq&utm_medium=social&utm_oi=645149500650557440
1、修改config.py
crnn_type = "lite_lstm"
修改为
crnn_type = "lite_dense"
2、修改 crnn_lite.py
这里主要是要把squeeze给替换掉,因为caffe并不支持,所用view来代替(这两个函数,在pytorch上是可以用view来代替squeeze)
修改108行(这里是直接替换定值如果想要知道值是多少,可以直接打印conv.shape看其尺度,再填写)
assert h == 1, "the height of conv must be 1"
print(conv.shape)
#conv = conv.squeeze(2)
conv = conv.view(1,512,-1)
3、修改 CRNN.py
在 class CRNNHandle(): 的 def init(self,model_path , net , gpu_id=None ):最后加入代码(51行),这里需要给模型一个输出的尺度,注意高度一定要32,长度随意。
self.net.eval()
output_onnx = 'crnn_lite_v2.onnx'
# out onnx
input_names = ["input"]
output_names = ["out"]
inputs = torch.randn(1, 1, 32, 243).to(self.device)
torch.onnx._export(net, inputs, output_onnx, export_params=True, verbose=False, \
input_names=input_names, output_names=output_names, keep_initializers_as_inputs=True, opset_version=11)
4、 编写test.py
from config import *
from crnn import FullCrnn,LiteCrnn,CRNNHandle
from PIL import Image
import numpy as np
import cv2
crnn_net = LiteCrnn(32, 1, len(alphabet) + 1, nh, n_rnn=2, leakyRelu=False, lstmFlag=LSTMFLAG)
crnn_handle = CRNNHandle(crnn_model_path , crnn_net , gpu_id=0)
img = cv2.imread("ocr.png")
partImg = Image.fromarray(np.array(img))
partImg_ = partImg.convert('L')
simPred = crnn_handle.predict(partImg_)
print(simPred)
成功运行即可生成onnx,运行成功会输出结果:

5、使用 onnx-simplifier 修改模型
python3 -m onnxsim crnn_lite_v2.onnx crnn_lite_v2-sim.onnx

这样就成功生成onnx
onnx2caffe
这里使用的是 yolov5_onnx2caffe版本进行修改补齐缺失的层
1、修改convertCaffe.py
修改15行为自己的模型位置
#onnx_path = "/home/willer/yolov5-4.0/models/models_not_focus/yolov5s-simple.onnx"
#prototxt_path = "./yolov5s-4.0-not-focus.prototxt"
#caffemodel_path = "./yolov5s-4.0-not-focus.caffemodel"
onnx_path = "./model/crnn_lite_v2-sim.onnx"
prototxt_path = "./model/crnn_lite_v2.prototxt"
caffemodel_path = "./model/ccrnn_lite_v2.caffemodel"
运行convertCaffe.py
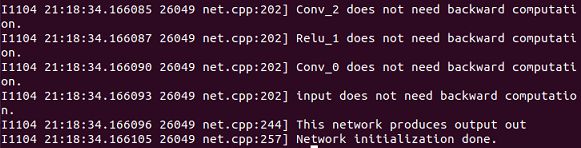
测试模型
编写测试代码test.py
# -*- coding:utf-8 -*-
import io
import sys
import numpy as np
import cv2
import os
from PIL import Image
import caffe
MODEL_FILE = '../crnn_lite_v2.prototxt'
PRETRAINED = '../crnn_lite_v2.caffemodel'
caffe.set_mode_gpu()
net = caffe.Net(MODEL_FILE, PRETRAINED, caffe.TEST)
def predictor(img):
labels = []
with io.open("keys.txt",'r',encoding='utf-8') as f1:
line_list = f1.read()
for line in line_list.split('\n'):
labels.append(line)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2, 0, 1))
im = cv2.imread(img)
partImg = Image.fromarray(np.array(im))
partImg_ = partImg.convert('L')
sequ = partImg_.getdata()
sequ0 = list(sequ)
im2 = np.zeros((im.shape[0],im.shape[1],1), np.uint8)
for i in range(0,im.shape[0]):
for j in range(0,im.shape[1]):
im2[i][j][0] = sequ0[i*im.shape[1] + j]
caffe_img = (np.array(im2)/255.0-0.5)/0.5
net.blobs['data'].data[...] = transformer.preprocess('data', caffe_img)
out = net.forward()
conv = []
fc_num = net.blobs['out'].data.shape[0]
for i in range(0,fc_num):
fc = net.blobs['out'].data[i].flatten()
max = fc[0]
mindex = 0
char_num = net.blobs['out'].data[i].shape[1]
for j in range(0,char_num):
if fc[j] > max:
max = fc[j]
mindex = j
conv.append(mindex)
for i in range(0,fc_num - 2):
if conv[i] == 0:
continue
if conv[i] == conv[i + 1]:
conv[i + 1] = 0
for val in conv:
if val > 0:
print labels[int(val) -1],
else :
continue
print "\n%s"%img
predictor('ocr.png')
![]()
PS:1、 maxpool caffe和pytorch的补齐方式是不同的,所以w(输入长度)的值尽量取maxpool为偶数的值
2、不同的长度会影响准确率,注意我这边把输入层name手动改为了data
3、输入的是灰度图
如何实现多尺度:
把最后输出层改为字符总数为固定值即可
layer {
name: "Reshape_45"
type: "Reshape"
bottom: "108"
top: "out"
reshape_param {
shape {
#dim: 64
dim: -1
dim: 1
#dim: -1
dim: 5530
}
}
}