Dive into BERT:语言模型与知识
作者:高开远
学校:上海交通大学
研究方向:自然语言处理
知乎专栏:BERT巨人肩膀
写在前面
最近在看的主要是跟知识相关的一些东西,包括回顾了一些知识表示模型呀,一些大规模的语言模型如何锦上添花融入外部知识的方法呀,如果你感兴趣的话可以直接去之前几篇文章里面瞄一眼。今天就以 知识 为切入点来更深入地剖析一下最近比较火的预训练模型。
√ Language Models as Knowledge Bases?
√ Linguistic Knowledge and Transferability of Contextual Representations.
√ What does BERT learn about the structure of language?
还有很多有意思的研究,可以去清华大学整理的PLMpapers仓库找找看。
1、Language Models as Knowledge Bases?(EMNLP2019)
语言模型可以当做是一种知识库吗?
知识库是一种格式化的知识存储与应用的有效方案。在实际的知识库构建或者扩充过程中,我们都会用到一系列复杂的NLP技术,例如实体抽取、指代消解、实体链接和关系抽取等等。这些pipeline的组件不可避免地会需要监督数据(大家都知道在NLP里标注数据有多难得到),而且这个过程很容易产生error propagation。相反,语言模型在pretrain阶段被喂入了大量的数据(无监督),可以从中学习到有效的关系型知识,而且像BERT这样的通过[MASK]操作可以更专注于提取类似知识库的关系知识。

于是,作者通过将预训练语言模型与传统关系抽取方法获得的知识库进行对比,来探索预训练模型在何种程度上存储事实和常识知识。主要有:
预训练语言模型存储多少关系知识?
对于不同类型的知识,例如实体事实、常识和一般性问答,有什么不同?
无需微调的语言模型与传统自动抽取知识创建知识库相比,有什么不同?
为此,作者们提出了LAMA(LAnguage Model Analysis) probe来验证上述问题。用于测试的知识包括:Wikidata 中实体之间的关系;ConceptNet 概念之间的常识知识;回答 SQuAD 中自然语言问题所必需的知识。认为,如果语言模型能够通过完形填空的形式预测出正确三元组则表明其学习到了这个知识。举个栗子,对于三元组(Dante, born-in, Florence),如果语言模型可以预测出给定句子Dante was born in ____中的空格为Florence,则为正确。
语言模型
下图为本文中参选测试的语言模型(HAHA相信大家肯定都非常熟悉啦,ps. 第一个是fairseq库实现的多层门控卷积模型)。最后比较的指标是rank-based metrics,并计算每个关系的结果以及所有关系的平均值。使用precision at k (P@K)

知识来源
为了验证不同的模型不同的存储知识能力,当然需要尽可能地模拟现实中多种多样的知识来源。
Google-RE:~60K事实,文中选取了五类关系中的三类,因为其他两类主要是多token对象;
T-REx:本文选取了40类维基数据关系,每类大概1000事实
ConcepNet:本文从中选取了英文数据的16类关系
SQuDA:本文从中选取305个与上下文无关的问题,并把问题形式转成完形填空形式。例如,
Who developed the theory of relativity?---->The theory of relativity was developed by _.
结论

BERT-Large模型可以获取精确的关系知识,与使用线程关系抽取器和oracle-based 实体链接器构建的知识库,效果相当;
从预训练模型中可以很好地保存事实知识,但是对于某些关系(N对M关系)表现非常差;
BERT-Large模型在获取事实和常识知识方面始终胜过其他语言模型,同时在查询方面更强大;
BERT-Large在开放域质量方面取得了显著成果,其P@10精度为57.1%,而使用任务特定的监督关系提取系统构建的知识库为63.5%。但是从上图中可以看出P@1精度就惨不忍睹….
所以看下来大规模预训练模型和知识库还是可以有抗衡性的(怎么好像跟GPT-V2的思想有点异曲同工),毕竟文中参与对比的模型都是未经过特定任务领域微调的。相比于知识库而言,这种语言模型作为知识存储具有的优势主要在灵活便捷,易于扩展到更多数据,且不需要人工标注语料。但同时也仍然存在很多问题,比如N对M关系。
Code Here
PS. 最近几天新出了一篇研究 BERT is Not a Knowledge Base (Yet): Factual Knowledge vs. Name-Based Reasoning in Unsupervised QA 反对了Language Models as Knowledge Bases的观点,认为BERT等的表现是由于对实体名称(表面形式)进行推理,例如猜测具有意大利语名称的人母语为意大利语,而不是模型保存了事实知识。实验中当过滤掉某些容易猜测的事实时,BERT的精度会急剧下降。
2、Linguistic Knowledge and Transferability of Contextual Representations(NAACL2019)
预训练模型的上下文相关词向量表示(CWR)在广泛的NLP任务中取得良好的性能,表明它们编码了必要的知识。于是作者们对ELMO、GPT、BERT三种具有代表性的语言模型,设计了17种不同的探测任务来研究模型编码的语言知识及其可迁移性。
任务
先来看看都有哪些任务吧
Token Labelling
part-of-speech(POS):测试是否捕获基本语法。数据集为PTB和UD-EWT;
CCG supertagging(CCG):评估向量在上下文中单词的句法角色的细粒度信息。数据集为CCGbank;
syntactic constituency ancestor tagging:探索向量的分层语法信息。数据集为PTB;
semantic tagging:探索语义信息。
Preposition supersense disambiguation:对介词的词汇语义贡献及其介导的语义角色或关系进行分类的任务。
event factuality:用所描述的事件的真实性来标记短语的任务;
Segmentation
Syntactic chunking (Chunk):验证是否编码span和boundary的信息;
Named entity recognition (NER):验证是否编码entity的信息;
等等
Pairwise Relations
探索单词之间关系的信息。
arc prediction
arc classification
等等
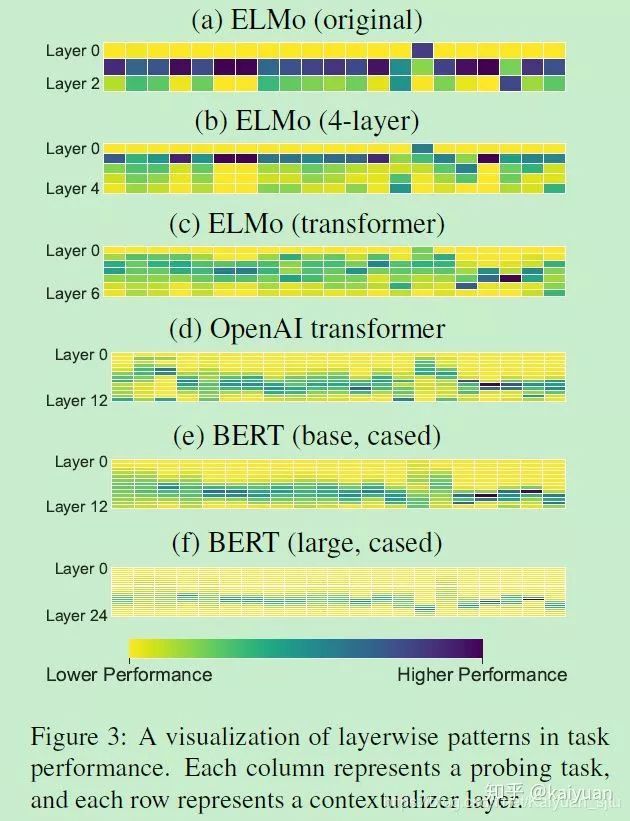
结果与讨论

上图是各个模型在设计的各类任务上的表现,我们结合作者开篇提及的问题来一一分析:
CWR捕获到了哪些语言信息,又遗漏了什么?
在所有任务中,上下文相关词向量都比固定词向量(Glove)效果好;
在ELMO-based模型中,使用transformer的效果最差;
总体来看各类任务,BERT-based > ELMO-based > GPT-based 模型,这说明双向编码所获取的信息更多;而且GPT 预训练语料都是lowercased text, 这也限制了其在NER等对大小写敏感的任务上表现;
CWR并不能准确抓取输入中有关实体和共指现象的可转移信息。
在编码器的表示层中,可转移性如何以及为什么会发生变化?
对于所有模型来说,general 和 task-specific是一个trade-off
LSTM based的模型(ELMO),越靠前的层越general, 越靠后的层越task-specific
transformer based的模型(GPT/BERT),没有表现出特定的最general的层,依据任务的不同而不同,但是基本都中间层;
预训练任务的选择对语言捕获知识和迁移能力有何影响?

作者们研究了基于ELMO模型的不同预训练任务后模型表现发现:
双向语言模型训练得到的平均效果更具有转移性
在相似任务上预训练后的模型,在特定任务上的表现更好
数据越多,模型效果越好
Code Here
3、What does BERT learn about the structure of language?(ACL2019)
看了上面那篇突然又想起尘封在to read list里面的这一篇文章,主要内容是探索BERT的每一层都编码了什么知识信息。
Phrasal Syntax
先前的对LSTM语言模型的研究表明其能够捕获短语级别的知识信息,那么对于BERT这种模型又是怎么样的呢?作者设计实验,给定一个输入序列 ,对每一层的第一个 和最后一个 隐藏表示以及它们的逐元素乘积和差值进行concat,用于表示该层的span representation 。通过t-SNE以及归一化互信息两种途径都发现BERT网络在较底层能更好地捕获短语级别的知识,并且随着网络的变深,短语级别的信息逐渐消失。

Probing Tasks
为了进一步了解BERT每一层捕获的不同类型语言知识,作者们设计了三大类总共十个句子级别的探测任务:Surface(表层),Syntactic(句法)和Semantic(语义),可以发现比较浅层的信息对Surface任务会更有效,中层bert的信息对Syntactic任务比较有效,而高层的信息对semantic任务比较有效。另外,作者发现未经训练的BERT高层网络在预测句子长度任务上效果比经过训练的BERT要好,这说明untrained BERT获取更多的是表层特征知识,而训练之后的BERT获取了更多复杂知识,这是以牺牲表层信息为代价的。

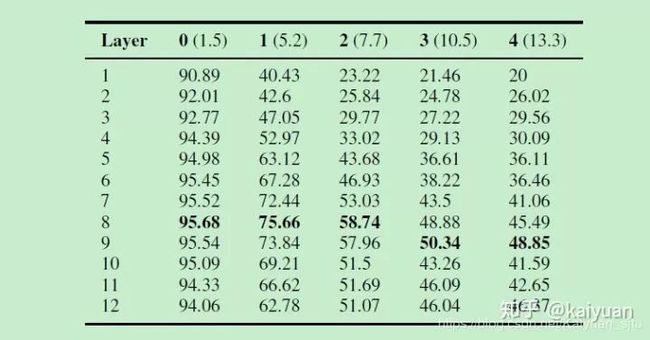
Subject-Verb Agreement
这是一个属于句法级别的任务,主要是根据名词单复数来预测谓语形式是否和主语一致,一般而言主语和谓语之间的名词个数越多,该任务就越难。从下表的试验结果可以看出(每一列是主谓之间的名词个数,每一行是网络层):
中间层的编码信息效果最强,这也和上一部分中探测任务结果一致,也和本文章中介绍的上一篇论文结果一致;
网络层数越深,越能解决长程依赖问题。
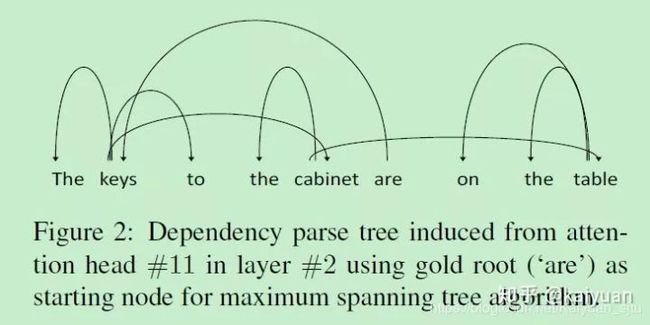
Compositional Structure
作者使用Tensor Product Decomposition Network(TPDN)来探索BERT模型学习到的组合结构信息,发现通过注意力机制可以学习到输入的树形结构,利用attention head的权重,可以重建出dependency tree
Code here
对于一个模型,按照官方README的步骤去应用它仅仅是最基础的一步,还需要去深层次地剖析它,一方面去帮助我们理解为什么它可以work可以成功,另一方面也可以让我们了解其局限性进而研究更多更有效的方法。Enjoy~
本文由作者授权AINLP发布于公众号平台,欢迎投稿,AI、NLP均可。原文链接,点击"阅读原文"直达:
https://zhuanlan.zhihu.com/p/92122312
历史精品文章推荐
1、知否?知否?一文看懂深度文本分类之DPCNN原理与代码
2、CCL“中国法研杯”相似案例匹配评测竞赛 - TOP队伍攻略分享
3、推荐|机器学习入门方法和资料合集
个人微信:加时请注明 (昵称+公司/学校+方向)


