FaE:基于符号知识的适应性和可解释的神经记忆
©原创作者 | 朱林
论文解读:
Facts as Experts: Adaptable and Interpretable Neural Memory over Symbolic Knowledge
论文作者:
Google Research
论文地址:
https://arxiv.org/abs/2007.00849
收录会议:
NAACL 2021
01 介绍
大规模语言模型,如BERT、Transformer等是现代自然语言建模的核心,其已被证明可以编码进大量的常识和事实(Fact)信息,是许多下游应用的基础。
然而,这些知识只存在于模型的潜在参数中,无法进行检查和解释。更糟糕的是,随着时间和外部环境的变化,从训练语料库中学习并记忆的事实信息可能会过时或出错。
为了解决这些问题,本文作者开发了一种神经语言模型Facts-as-Experts (FaE),其在神经网络语言模型和符号知识库(symbolic KB)之间建立了一个桥梁,将深度神经网络的表达能力优势和符号知识库的推理能力优势进行了有机结合。
实验表明,该模型在两个知识密集型问答任务中显著提高了性能。更有趣的是,该模型可以通过操纵其符号表示来更新模型而无需重新训练,且该模型允许添加新的事实并以早期模型不可能的方式覆盖现有的事实。
02 模型
符号定义

总体架构
Facts-as-Experts(FaE)模型建立在最新提出的专家实体语言模型Entities-as-Experts(EaE)上,EaE是一种可以直接从文本中学习与实体相关Memory的新模型,参数规模小于Transformer模型,但是性能优于Transformer架构。
FaE模型在EaE基础上包含一个称为Fact Memory的附加Memory,它从符号知识库中编码出三元组。每个三元组都是由组成它实体的EaE-learned嵌入组成的。这个Fact Memory用一个键值对表示,可以用来检索知识库中的信息。
如图1所示,虚线内的模型是EaE,右侧是Fact Memory。首先输入一段文本,使用[MASK]作为对Fact Memory的查询,使用Transformer层对其进行上下文编码。
然后,通过上下文查询得到事实的Key(如[Charles Darwin, born in]),以及该Key的Values(如{United Kingdom})。返回被合并回上下文中以进行最终预测。事实中的键值与EaE实体Memory共享。
通过这种组合产生了一个新的神经语言模型,该模型能有效结合符号知识图中的信息。
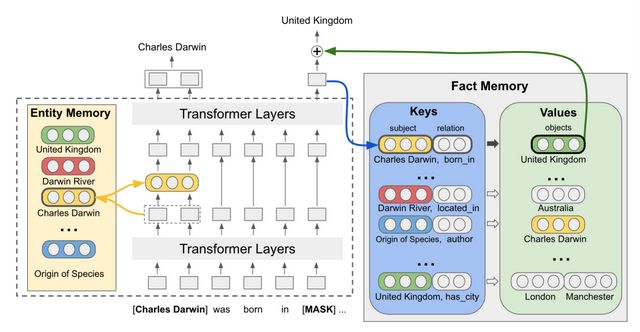
图1 Facts-as-Experts模型架构
附加和集成



03 实验
数据集
本文在两个开放域问答数据集上进行了评估:FreebaseQA和WebQuestionsSP,这两个数据集都是从Freebase创建的。Freebase是个类似Wikipedia的创作共享类网站,所有内容都由用户添加。
结果

表1 两个数据集上的评估
如表1所示,作者将FaE与三个基线模型进行比较:FOFE、EmQL和Entity-as-Expert(EaE)。
FOFE是一种前馈语言模型,旨在对长序列进行编码,并且是FreebaseQA数据集上之前最先进的模型。EmQL是作为知识库上的查询嵌入引入的,是WebQuestionsSP上之前最先进的模型。另外还有上文提到的EaE模型。
结果显示,FaE在FreebaseQA数据集上的准确率高于其他基线模型近10个百分点。在WebQuestionsSP完整数据集上FaE的性能相对较低,但这主要是由于Freebase和Wikidata之间的映射导致知识库不完整导致的。
04 讨论
数据重叠
本文模型主要关注对模型使用外部知识回答问题的能力,而不是学习识别语义相同的问题。
不幸的是,对这两个数据集的分析表明,许多测试答案也显示为某些训练集问题的答案:FreebaseQA测试数据中75.0%的答案和WebQuestionsSP中57.5%的答案都是这种情况。
这表明了一种可能性,即模型的某些高性能可能归因于简单地记住特定的问题/答案对。
为了解决这个问题,作者丢弃了重叠部分查询实验。当应用重叠过滤之后,模型的表现要差得多,并且它们被迫依赖于跨多个示例进行推理的能力,在FaE中指的是Fact Memory。
新事实注入
因为作者的模型只是象征性地定义了事实,原则上它可以注入Memory中新的事实,而无需重新训练模型的任何参数。
为了测试模型执行此任务的能力,作者比对了模型在给定完整知识、过滤知识和注入知识的情况下的结果,如表2所示。过滤知识和注入知识的方法差距证明模型能够很好地结合新引入的事实。
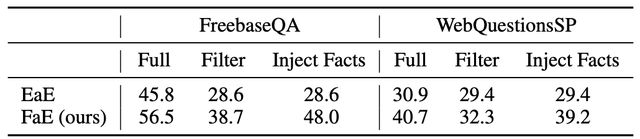
表2 注入新的事实的对比结果
更新陈旧Memory
作者希望模型能很好地对知识进行表示,并且这种知识表示可以通过随外界环境变化而增量更新来避免数据过时。
为了探究这种能力,作者模拟了这个场景的一个极端版本,其中FreebaseQA测试集中对问答对的所有答案都替换为合理的其他值。

05 结论
在本文中,作者提出了一种将神经网络语言模型与可解释的符号知识库相结合的新模型FaE。该模型在事实性问答任务方面表现出与高性能语言模型相当或更好的性能,且该模型可以通过仅修改非参数的Memory部分而无需任何额外训练来更改语言模型的输出,是值得深入研究的一个新方向。
06 思考
本文留给了我们一些启发与思考:
(1) 深度神经网络语言模型实验效果很好,但是依赖于超大的数据集和深度的不可解释的参数空间,是一个典型的黑盒模型,实际应用很难调节和解释。而目前越来越的新方法尝试与符号知识库等有推理能力和解释能力的模型进行结合,以提高可解释性。
(2) 结合符号逻辑或者可解释的严谨的数学模型,我们可以构造出仅仅需要改变外部结构就能泛化到别的应用场景能力,而不用每次都拿新的数据喂给模型重新训练参数,如果这个思路可行,在实际工程中就可以节省很多训练时间和存储空间,是个值得研究的方向。
(3) 目前不少问答数据集存在训练集和测试集重叠的问题,导致了实验结果的“虚高”,值得重新构造恰当的数据集进行实验和探讨,使结果更为严谨。