RoI Pooling可视化
结论:RoI Pooling在映射时原尺寸不能够整除输出尺寸时不同的section有不同的size。
在网上常见的都是RoI Pooling和RoI Align的对比文章,对RoI Align的双线性插值解释的非常清晰。但是对于RoI Pooling的解释让我感到特别困惑,所以自行做了实验去解开疑惑。
RoI Pooling的过程可以划分为3步:
- 将RoI从原图映射到feature map上;
- 将映射后的区域划分成大小相同的section,section的数量等于输出尺寸(fixed size);
- 在每个section内部进行Max Pooling操作。
疑惑的点在于第2步,RoI在feature map转化为fixed feature map时原特征图尺寸无法整除fixed size时(假设商为n),存在一个取整操作,比如说RoI的feature map尺寸为12*12,需要转化为7*7的尺寸,此时商为1,后续产生的feature map每个section的尺寸会是统一的1(此时有12*12-7*7的特征点被舍弃),还是不同的section有不同的size(此时一个特征点参与多个section的计算)。
实验:
>>> import torch
>>> import torchvision.ops as ops
>>> feature = torch.Tensor([i for i in range(25)]).view(1,1,5,5)
>>> feature
tensor([[[[ 0., 1., 2., 3., 4.],
[ 5., 6., 7., 8., 9.],
[10., 11., 12., 13., 14.],
[15., 16., 17., 18., 19.],
[20., 21., 22., 23., 24.]]]])
>>> bboxes = torch.Tensor([[0,0,0,4,4]])
>>> ops.roi_pool(feature,bboxes,5)
tensor([[[[ 0., 1., 2., 3., 4.],
[ 5., 6., 7., 8., 9.],
[10., 11., 12., 13., 14.],
[15., 16., 17., 18., 19.],
[20., 21., 22., 23., 24.]]]])
#设置bboxes size等于feature size, 当bboxes size等于RoI size时(此处为(5,5)),
#得到的RoI feature就是整个feature map
>>> ops.roi_pool(feature,bboxes,3)
tensor([[[[ 6., 8., 9.],
[16., 18., 19.],
[21., 23., 24.]]]])
>>> feature = torch.Tensor([i for i in range(24, -1, -1)]).view(1,1,5,5)
>>> feature
tensor([[[[24., 23., 22., 21., 20.],
[19., 18., 17., 16., 15.],
[14., 13., 12., 11., 10.],
[ 9., 8., 7., 6., 5.],
[ 4., 3., 2., 1., 0.]]]])
>>> ops.roi_pool(feature,bboxes,3)
tensor([[[[24., 23., 21.],
[19., 18., 16.],
[ 9., 8., 6.]]]])根据上述实验,我们能够得到在该特例下的区域映射规则:
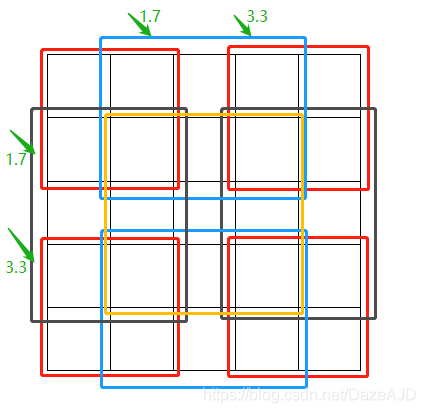
RoI Pooling之后的feature map尺寸为[3, 3],原feature map尺寸为[5, 5],每个section的长宽为5/3 = 1.7,上图绘制了9个颜色的矩形框来表示[5, 5]->[3, 3]的区域映射规则。
其中红色框代表四个角[0][0],[0][2],[2][0],[2][2];蓝色框代表[0][1],[2][1];黑色框代表[1, 0],[1][2];黄色框代表[1][1]。
Proposal的边长为5,RoI的边长为3,5/3=1.7,所以在小数位上三个框的取值应该为[1.7,3.3,5]。小数位取整则变为[0,1],[1,2,3],[3,4]。
结论:RoI Pooling在映射时原尺寸不能够整除映射后尺寸时不同的section有不同的size。