数据可视化实验-多维数据平行坐标可视化(HTML语言)
数据可视化实验4-多维数据平行坐标可视化
平行坐标系常用于高维几何和多元数据的可视化。其在数据的可视化表示上克服了笛卡尔直角坐标系(平面直角坐标系、空间直角坐标系)很容易耗尽空间维度,最多只能进行三个维度数据可视化的缺陷,将多个维度的数据变量用多个平行的坐标轴进行表示,将来自于同一数据源的不同维度曲线连接成折线,在存在多种不同类别的数据源时,也可以通过不同颜色绘制属于不同类别数据源的折线,最终通过绘制出的图像进行相关的数据分析。
一、数据集的介绍
使用的数据集为:heart.csv
来源:(https://www.kaggle.com/competitions/heart-disease-prediction/data)
匈牙利心脏病研究所;
维度:14
数目:303
变量名及详细说明如下表所示:
属性说明表
| 变量名 |
详细说明 |
取值范围 |
| target |
是否患有心脏病(分类变量) |
0=正常,1=患病 |
| age |
年龄(连续变量) |
[29,77] |
| sex |
性别(分类变量) |
1=男,0=女 |
| cp |
胸痛经历(分类变量) |
0=典型心绞痛,1=非典型性心绞痛,2=非心绞痛,3=无症状 |
| trestbps |
静息血压(连续变量Hg) |
[94,200] |
| chols |
人体胆固醇(连续变量mg/dl) |
[126,564] |
| fbs |
空腹血糖(分类变量>120mg/dl) |
1=真,0=假 |
| restecg |
静息心电图测量(分类变量) |
0=正常,1=有ST-T波异常,2=按Estes标准显示可能或明确的左心室肥厚 |
| thalach |
最大心率(连续变量) |
[71,202] |
| exang |
运动诱发心绞痛(分类变量) |
1=是,0=否 |
| oldpeak |
运动相对于休息引起的ST段压低(连续变量) |
[0,6.2] |
| slope |
峰值运动ST段的斜率(分类变量) |
0=上升,1=平坦,2=下降 |
| ca |
主要血管数量(连续变量) |
[0,3] |
| thal |
地中海贫血的血液疾病(分类变量) |
1=正常,2=固定缺陷,3=可逆缺陷 |
可知:连续变量只有age,trestbps,chols,thalach,oldpeak,ca。其他属性均为分类变量。数据集中正常人和患心脏病的比例情况如下图所示:

正常人群和患有心脏病的人数(0:正常,1:患心脏病)
二、心脏数据集平行坐标可视化

因为类别变量画在坐标轴中时线条的聚集现象会很严重,不合适全部展现出来作为变量可视化。所以将连续变量作为平行坐标的坐标轴和cp属性来观察属性之间的关系。
从target属性把数据集分为两类,红色的线代表患有心脏病的数据,绿色的线代表没有患心脏病的数据。实现如下:
定义颜色:
var color = d3.scaleOrdinal()
.domain([0,1])
.range(["#DB7F85", "#50AB84"]);
根据target属性改变其颜色:
ctx.strokeStyle = color(d.target);
发现:
①观察cp(胸痛经历)轴的数据聚集情况(分类变量),可以看出典型心绞痛的人群得心脏病的概率非常大。胸痛和不胸痛来看,胸痛的时候患有心脏病的概率大。
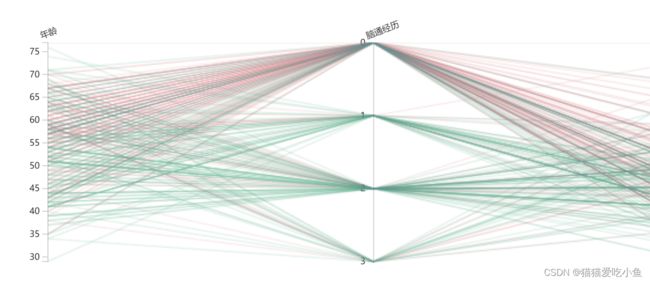
胸痛经历坐标轴上数值小处红色线条密集
筛选数据后,可以很明显的看出有典型心绞痛的在图上表现的大部分线条为红色,非绞痛的在图上表现的大部分线条为绿色。单个对比图如下所示:
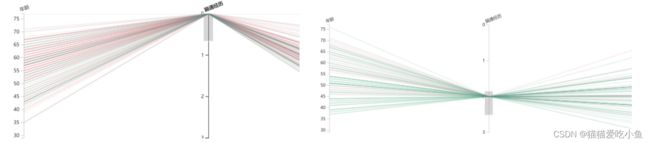
典型心绞痛 非心绞痛
②观察胸痛经历和静息血压之间的关系:胸痛经历不严重的人,其静息血压也低。对比图如下所示:
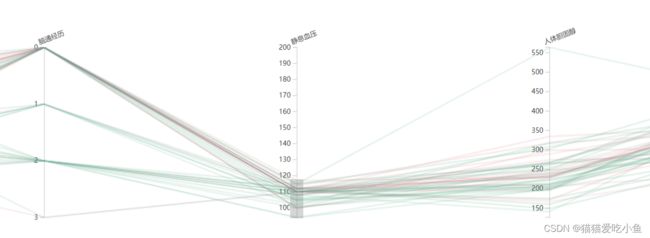
静息血压筛选值(90-127)
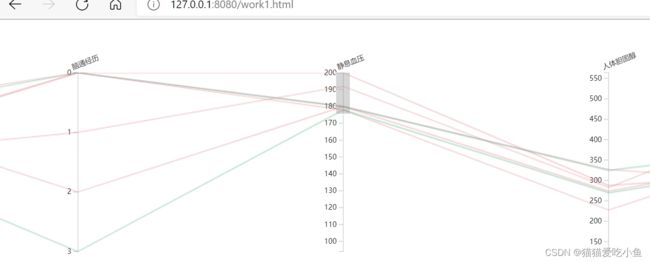
静息血压筛选值(178-200)
静息血压较低处,大部分都正常;而静息血压高的人群中,患病的比例比较高。
③在最大心率值上进行筛选,很明显最大心率小处呈现的线条基本为红色,最大心率大处呈现的线条大部分为绿色。而且最大心率和峰值运动ST段的斜率关联程度比较大,最大心率

最大心率筛选值(174-200)

最大心率筛选值(85-110)
除了在平行坐标中绘制连续变量,还在下方展示了筛选数据的其他属性,但是没有对其进行可视化,所以数据没有这么直观,如下图所示:
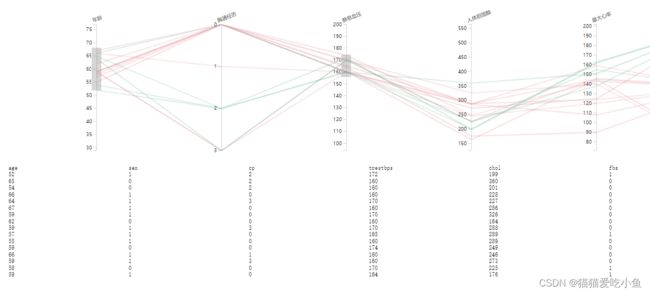
在平行坐标轴下方展示筛选数据的其他属性内容
所以需要将平行坐标和其他可视化方法结合起来分析数据集。
三、平行坐标可视化和柱形图结合使用
因为平行坐标难以呈现多个维度间的关系,显示空间需求大,加上分类变量后会变得十分混乱,而且表现多个维度之间的关系不够清晰,易受图元堆叠的影响,丢失原始维度上的细节信息。所以把分类坐标制作成柱形图,在柱形图上筛选出类别后再在平行坐标上筛选范围,或在平行坐标上筛选出范围后观察类别的分布情况,比较有利于对数据的分析。
患病者折线绘制为黄色,正常人折线绘制为蓝色。
发现:
①在胸痛经历程度小的数据中,可以看出空腹血糖大部分都小于120mg/dl,可知糖尿病与心血管疾病有着紧密联系。

胸痛经历程度小的空腹血糖含量
②运动诱发心绞痛,选中0(不是运行诱发心绞痛),选中1(运动诱发心绞痛),可以看出正常人大部分是运动诱发心绞痛,而患心脏病的人群并不只是心脏病诱发心绞痛:

选中非运动诱发的心绞痛
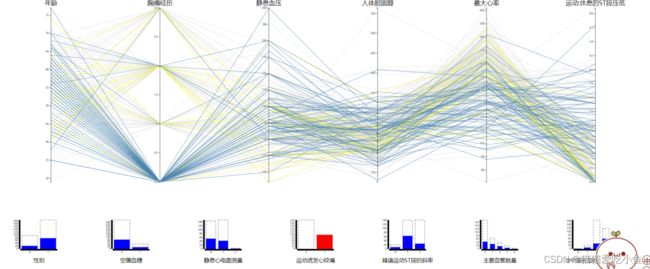
选中运动诱发的心绞痛
③选中患心脏病的人群,观察性别的柱形图:可以看出在年龄60以上女性患病的人数多与男性患病的人数,60岁以下的基本是男性患病人数多于女性患病的人数。猜测原因:女性的平均寿命高于男性的平均寿命,所以老年人中女性的比例比较高。也可能是老年男性患病的可能性比老年女性患病的可能性小。
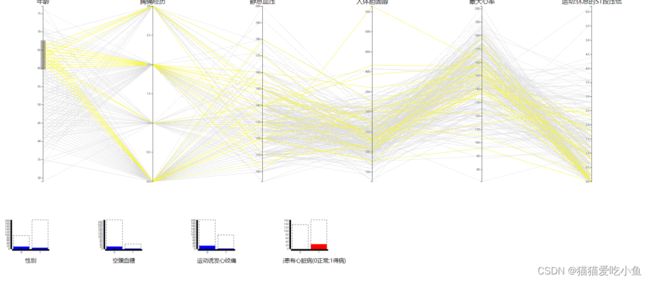
60以上女性患病比例较高
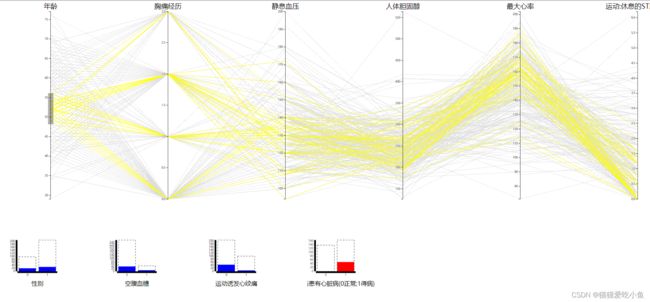
60以下男性患病比例较高
④由上面结论可知,最大的心率较小的人群中其slope指数也比较低,oldpeak指数也在一定范围中,如下图所示。
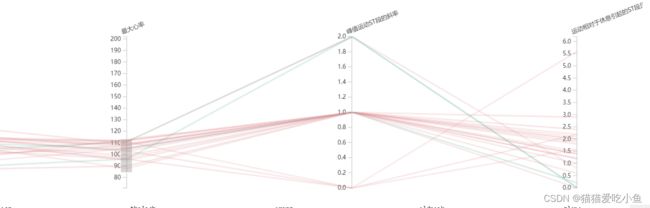
最小心率、slope指数和oldpeak指数观察
交换两个坐标轴的位置(slope和oldpeak),交换位置后,没有那么容易发现这个现象,如下图所示,图中绿色和红色线条没有交换前的明显聚集效果。
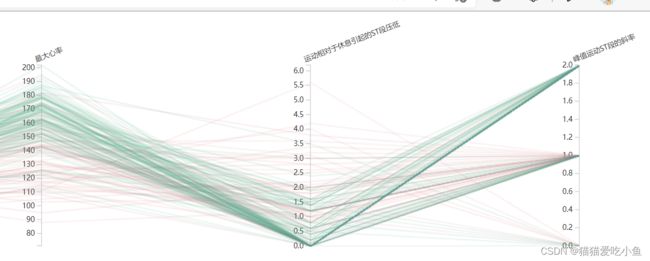
交换slope和oldpeak坐标轴的位置
再交换坐标轴的位置,使得胸痛经历和年龄隔开几个坐标,它们之间的关系也不容易被发现。
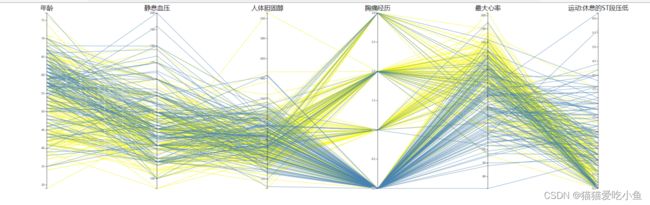
所以平行坐标可视化表现多个维度之间的关系不够清晰,易受图元堆叠的影响。
四、高维数据的降维分析
PCA降维
1.选择连续变量的属性进行降维,降维两维;
df2= df.reindex(columns=['age','trestbps', 'chol','thalach','oldpeak'])
x=df2
pca = PCA(n_components=2)#实例化
pca = pca.fit(x)#拟合模型
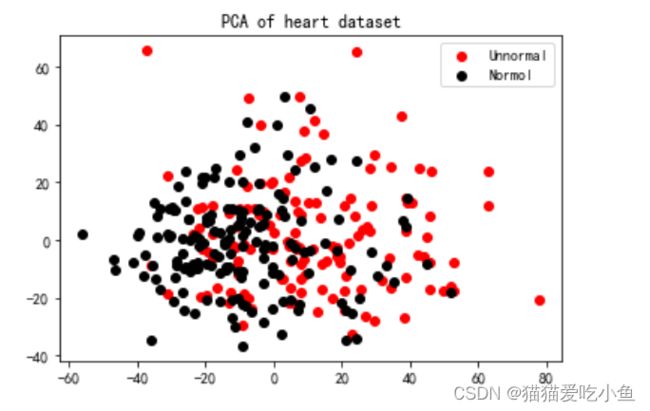
x_dr = pca.transform(x)#获取新矩阵可视化如下,黑色为正常,红色为患有心脏病:
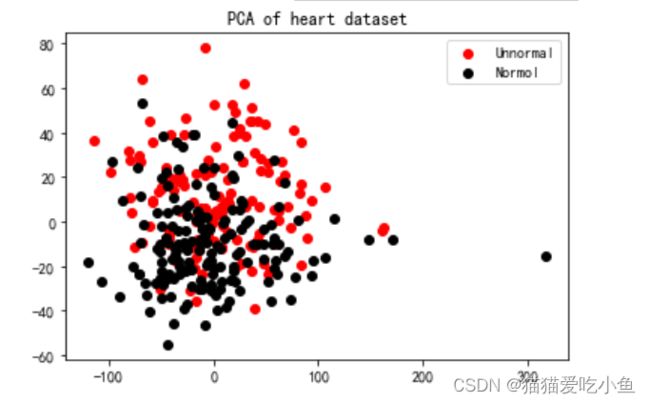
2.根据上述分析,选择和心脏病相关较大的属性降维:
df3= df.reindex(columns=['age', 'cp','trestbps', 'thalach','oldpeak','ca'])可视化如下:
3.全部属性都降维:
df4=df.reindex(columns=['age','sex','cp','trestbps','chol','fbs','restecg','thalach','exang','oldpeak','slope','ca','thal'])可视化如下:

对比可发现,筛选相关性较大的属性进行可视化后可视化图中两个类别比较容易区分。