YoloV3 案例
YoloV3 案例
学习目标
- 熟悉TFRecord文件的使用方法
- 知道YoloV3模型结构及构建方法
- 知道数据处理方法
- 能够利用yoloV3模型进行训练和预测

数据获取
根据要实现的业务场景,需要收集大量的图像数据,一般来说包含两大来源,一部分是网络数据,可以是开源数据,也可以通过百度、Google图片爬虫得到,另一部分是用户场景的视频录像,这一部分的数据量会更大。对于开源数据我们不需要进行标注,而爬取的数据和视频录像需要进行标注,这时我们可以使用开源工具labelImg进行标注,该软件截图如下:

具体的操作:[windows下使用labelImg标注图像]https://www.pianshen.com/article/5220613836/
数据标注完成后,我们就可以使用其进行模型训练,在接下来的课程中我们就使用标注好的数据进行模型训练,模型预测。使用的工程如下所示:

主要内容是:
1.config中是网络的配置信息:anchors,类别信息
2.core中是损失函数计算,网络预测的内容
3.dateset中是对数据的处理
4.model是对模型的构建
5.utils是一些辅助文件,包括anchor,类别信息的获取等
6.weights中保存了一个使用coco数据集训练的预训练模型
TFrecord文件
该案例中我们依然使用VOC数据集来进行目标检测,不同的是我们要利用tfrecord文件来存储和读取数据,首先来看一下tfrecord文件的相关内容。
为什么要使用tfrecord文件?
- TFRecord是Google官方推荐使用的数据格式化存储工具,为TensorFlow量身打造的。
- TFRecord规范了数据的读写方式,数据读取和处理的效率都会得到显著的提高。
什么是TFrecord文件
TFRecord 是Google官方推荐的一种数据格式,是Google专门为TensorFlow设计的一种数据格式,利用这种方式存储数据可以使其与网络架构更适配。TFRecord是一种二进制文件,其能更好的利用内存,与csv,hdf5文件是类似的。
TFRecord的文件的内容如下图所示:

TFRecord内部包含多个tf.train.Example,一般来说对应一个图像数据,在一个Example消息体中包含了一系列的tf.train.feature属性,而 每一个feature是一个key-value的键值对,key是特征名称,value是特征值。
TFRecord 并非是TensorFlow唯一支持的数据格式,也可以使用CSV或文本等其他格式,但是对于TensorFlow来说,TFRecord 是最友好的,最方便的,而且tensorflow也提供了丰富的API帮助我们轻松的创建和获取TFRecord文件。
将数据转换为TFRecord文件
对于中大数据集来说,Google官方推荐先将数据集转化为TFRecord数据, 这样可加快在数据读取, 预处理中的速度。接下来我们就将VOC数据集转换为Records格式,将数据写入TFRecords文件中,直接使用write_to_tfrecord即可实现,首先导入工具包:
from dataset.vocdata_tfrecord import load_labels,write_to_tfrecord
import os
将数据写入tfrecord中的流程是:
- 指定要写入的数据集路径
- 获取所有的XML标注文件
- 指定tfrecord的存储位置
- 获取图像的路径
- 将数据写入到tfrecord文件中
实现如下:
# 指定要写入的数据集路径
data_path = '/Users/yaoxiaoying/Desktop/yoloV3-tf2/dataset/VOCdevkit/VOC2007'
# 获取所有的XML标注文件
all_xml = load_labels(data_path, 'train')
# 指定tfrecord的存储位置
tfrecord_path = 'voc_train.tfrecords'
# 获取图像的路径
voc_img_path = os.path.join(data_path, 'JPEGImages')
# 将数据写入到tfrecord文件中
write_to_tfrecord(all_xml, tfrecord_path, voc_img_path)
结果如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZHFNdsaz-1646365296525)(笔记图片/
读取TFRecord文件
VOC数据集已经被写入到TFRecord文件中了,那我们就要从TFrecord文件中将数据读取出来。只使用 getdata就能够轻松的读取数据。
导入工具包:
# 读取tfrecords文件所需的工具包
from dataset.get_tfdata import getdata
# 绘图
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
接下来使用getdata就可以获取文件中的所有数据:
# 指定tfrecord文件的位置,获取tfrecord文件中的数据
datasets = getdata("dataset/voc_val.tfrecords")
我们将从TFRecord文件中读取的数据展示出来:
from matplotlib.patches import Rectangle
# 数据类别
from utils.config_utils import read_class_names
classes = read_class_names("config/classname")
# 将tfrecord中的图像进行展示
plt.figure(figsize=(15, 10))
# 初始化:第几个图像
i = 0
# 从datasets中选取3个样本,获取图像,大小,框的标注信息和类别信息
for image, width, height, boxes, boxes_category in datasets.take(3):
# 进行绘图
plt.subplot(1, 3, i+1)
# 绘制图像
plt.imshow(image)
# 获取坐标区域
ax = plt.gca()
# 遍历所有的框
for j in range(boxes.shape[0]):
# 绘制框
rect = Rectangle((boxes[j, 0], boxes[j, 1]), boxes[j, 2] -boxes[j, 0], boxes[j, 3]-boxes[j, 1], color='r', fill=False)
# 将框显示在图像上
ax.add_patch(rect)
# 显示标注信息
# 获取标注信息的id
label_id = boxes_category[j]
# 获取标准信息
label = classes.get(label_id.numpy())
# 将标注信息添加在图像上
ax.text(boxes[j, 0], boxes[j, 1] + 8, label,color='w', size=11, backgroundcolor="none")
# 下一个结果
i += 1
# 显示图像
plt.show()
结果为:

数据处理
yoloV3模型的输入图像的大小是32的倍数,所以我们需要对图像进行处理。在这里我们将图像的尺度调整为416x416的大小,为了保持长宽比,我将四周为0的像素以灰度值128进行填充,如下图所示:

实现该功能使用dataset.preprocess来完成,如下所示:
# 输入:原图像及图像上的标准框
# 输出:将尺度调整后的图像,及相应的目标框
image,bbox = preprocess(oriimage,oribbox,input_shape=(416,416))
我们对读取的数据进行处理并绘制结果:
# 1.导入工具包,
from dataset.preprocess import preprocess as ppro
# 2.创建画布
plt.figure(figsize=(15,10))
# 3.获取数据遍历
i = 0
for image,width,height,boxes,boxes_category in datasets.take(3):
# 4.进行数据处理
image,boxes = preprocess(image,boxes)
# 5.划分不同的坐标轴subplot()
plt.subplot(1,3,i+1)
# 6.显示图像:plt.imshow()
plt.imshow(image[0])
# 7.显示box,遍历所有的bbox,rectange进行绘制
ax = plt.gca()
for j in range(boxes.shape[0]):
rect = Rectangle((boxes[j, 0], boxes[j, 1]), boxes[j, 2] -boxes[j, 0], boxes[j, 3]-boxes[j, 1], color='r', fill=False)
ax.add_patch(rect)
# 8.显示类别
label_id = boxes_category[j]
label = classes.get(label_id.numpy())
ax.text(boxes[j, 0], boxes[j, 1] + 8, label,color='w', size=11, backgroundcolor="none")
i+=1
plt.show()
模型构建
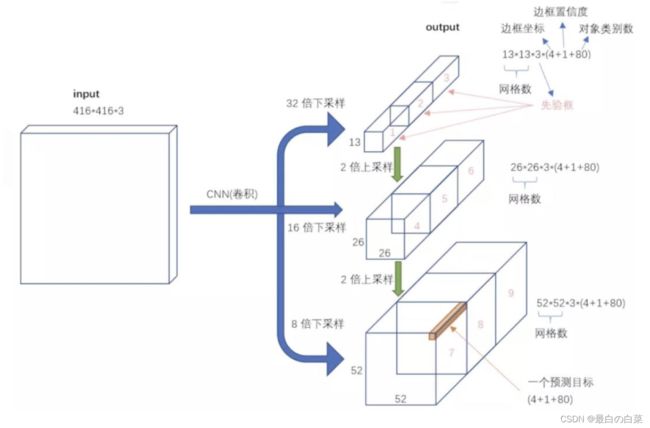
yoloV3的模型结构如下所示:整个v3结构里面,没有池化层和全连接层,网络的下采样是通过设置卷积的stride为2来达到的,每当通过这个卷积层之后图像的尺寸就会减小到一半。
在构建网络时,使用model.yoloV3来进行构建:
# 导入工具包
from model.yoloV3 import YOLOv3
# 模型实例化:指定输入图像的大小,和类别数
yolov3 = YOLOv3((416,416,3),80)
# 获取模型架构
yolov3.summary()

那到这里模型就构建好了。
模型训练
损失函数的计算
YoloV3的损失函数分为三部分:
- box的损失:
只有负责检测的gridcell中的anchor才会计入损失,对x,y,w,h分别求均方误差

- 置信度的损失
置信度的损失是二分类的交叉熵损失函数,所有的box都计入损失计算

- 分类的损失:
分类的损失是二分类的交叉熵损失,只有负责检测目标的才计算损失
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IH5nUYdj-1646365296531)(笔记图片/image-20200923172749873.png)]](http://img.e-com-net.com/image/info8/d2b94fe3e8624a758fe2fcf6563e2e46.jpg)
在计算损失函数时使用core.loss来完成:
# 导入所需的工具包
from core.loss import Loss
# 实例化
yolov3_loss = Loss((416,416,3),80)
我们来看下损失的输入输出:
# 损失输入
yolov3_loss.inputs

# 损失输出
yolov3_loss.outputs
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7Y7XGu5t-1646365296532)(笔记图片/image-20210106160114501.png)]](http://img.e-com-net.com/image/info8/2cc34ad0f25445cc976fae8f2c808adb.jpg)
输出的结果就是网络的损失值,是一个标量,使用它就可以来完成网络的训练。
正负样本的设定
在上述的loss计算中,负责进行目标预测的anchor就是正样本,而不负责进行目标预测的就是负样本,也就是背景,那在这里我们是如何设置正负样本的呢?如下图所示:
- 正样本:首先计算目标中心点落在哪个grid上,然后计算这个grid对应的3个先验框(anchor)和目标真实位置的IOU值,取IOU值最大的先验框和目标匹配。那么该anchor 就负责预测这个目标,那这个anchor就作为正样本,将其置信度设为1,其他的目标值根据标注信息设置。
- 负样本:所有不是正样本的anchor都是负样本,将其置信度设为0,参与损失计算,其它的值不参与损失计算,默认为0。
对于每一个anchor我们都要4+1+80维的目标值,其中前4维是坐标值,正样本是GT的bbox框的值,第5维是置信度,正样本设置为1,负样本设置为0,最后的80是类别数,正样本对应的类别设置为1,其余为0,若使用voc数据集类别数是20 。
可以通过bbox_to_target来完成样本的设置,获取图像及其标注信息,获取目标值,如下:
# 导入目标值设置所需方法
from core.bbox_target import bbox_to_target
# 获取图像及其标注信息
for image, width, height, boxes, labels in datasets.take(1):
# 获取anchor的目标值,label1是13*13的目标值,label2是26*26的目标值,label3是52*52的目标值,
label1,label2,label3 = bbox_to_target(bbox=boxes,label=labels,num_classes=20)

正样本的anchor的置信度为1,所以我们通过置信度为1来获取正样本:
# 导入工具包
import tensorflow as tf
# label1[...,0:4]坐标值,label1[...,4]置信度,label1[...,5:]类别分数
index = tf.where(tf.equal(label1[...,4],1))
# index.numpy(),说明索引为12 12 0 个像素中Anchor是正样本
array([[12, 12, 0]])
它对应的坐标值是:
# label1[12, 12,0,0:4].numpy()
array([209., 318., 88., 108.], dtype=float32)
分类的目标值是:
# label1[12,12,0,5:].numpy()
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0.], dtype=float32)
我们将目标值绘制在图像上:
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
# 1.获取类别信息
from utils.config_utils import read_class_names
classes = read_class_names('config/classname')
# 2.创建画布
plt.figure(figsize=(15,10))
# 3.获取数据遍历
for image,width,height,boxes,boxes_category in datasets.take(1):
# 4.显示图像:plt.imshow()
plt.imshow(image)
# 5.显示box,遍历所有的bbox,rectange进行绘制
ax = plt.gca()
for j in range(boxes.shape[0]):
rect = Rectangle((boxes[j, 0], boxes[j, 1]), boxes[j, 2] -boxes[j, 0], boxes[j, 3]-boxes[j, 1], color='r', fill=False)
ax.add_patch(rect)
# 6.显示类别
label_id = boxes_category[j]
label = classes.get(label_id.numpy())
ax.text(boxes[j, 0], boxes[j, 1] + 8, label,color='w', size=11, backgroundcolor="none")
# 7.绘制正样本的anchor的目标值
anchor = label1[12, 12,0,0:4].numpy()
rect2 = Rectangle((anchor[0]-anchor[2]/2, anchor[1]-anchor[3]/2), anchor[2], anchor[3],color='g', fill=False)
ax.add_patch(rect2)
plt.show()

模型训练
前面我们已经详细介绍了网络模型架构,在网络预测前我们需要对网络进行训练,接下来使用端到端的方式进行模型训练,基本步骤是:
1、加载数据集:我们在这里使用VOC数据集,所以需要从TFrecord文件中加载VOC数据集
2、模型实例化:加载yoloV3模型和损失函数的实现
3、模型训练:计算损失函数,使用反向传播算法对模型进行训练
获取数据集
我们从tfrecords文件中获取训练集数据:
# 导入
from dataset.preprocess import dataset
# 设置batch_size
batch_size=1
# 获取训练集数据,并指定batchsize,返回训练集数据
trainset = dataset("dataset/voc_train.tfrecords",batch_size)
加载模型
将在yoloV3模型和损失函数的计算进行实例化:
# V3模型的实例化,指定输入图像的大小,即目标检测的类别个数
yolov3 = YOLOv3((416, 416, 3,), 20)
yolov3_loss = Loss((416,416,3), 20)
模型训练
模型训练也就是要使用损失函数,进行反向传播,利用优化器进行参数更新,训练的流程是:
1、指定优化器:在这里我们使用加动量的SGD方法
2、设置epoch,进行遍历获取batch数据送入网络中进行预测
3、计算损失函数,使用反向传播更新参数,我们使用tf.GradientTape实现:
- 定义上下文环境:tf.GradientTape
- 计算损失函数loss
- 使用
tape.gradient(loss,model.trainable_variables)自动计算梯度,loss是损失结果,trainable_variables为所有需要训练的变量。 - 使用
optimizer.apply_gradients(zip(grads,model.trainable_variables))自动更新模型参数,zip(grads, trainable_variables)将梯度和参数关联起来,然后apply_gradients会自动的利用梯度对参数进行更新。
接下来我们按照这个流程完成模型训练,并保存模型训练结果。
# 1、定义优化方法
optimizer = tf.keras.optimizers.SGD(0.1,0.9)
# 2.设置epoch,获取batch数据送入网络中进行预测
for epoch in range(300):
loss_history = []
# 遍历每一个batch的图像和目标值,进行更新
for (batch, inputs) in enumerate(trainset):
images, labels = inputs
# 3.计算损失函数,使用反向传播更新参数
# 3.1 定义上下文环境
with tf.GradientTape() as tape:
# 3.2 将图像送入网络中
outputs = yolov3(images)
# 3.3 计算损失函数
loss = yolov3_loss([*outputs, *labels])
# 3.4 计算梯度
grads = tape.gradient(loss, yolov3.trainable_variables)
# 3.5 梯度更新
optimizer.apply_gradients(zip(grads, yolov3.trainable_variables))
# 3.6 打印信息
info = 'epoch: %d, batch: %d ,loss: %f'%(epoch, batch, np.mean(loss_history))
print(info)
loss_history.append(loss.numpy())
yolov3.save('yolov3.h5')
损失函数的变化为:
epoch: 0, batch: 0 ,loss: 701318.312500
epoch: 0, batch: 1 ,loss: 765384.625000
epoch: 0, batch: 2 ,loss: 747363.000000
epoch: 0, batch: 3 ,loss: 708547.187500
epoch: 0, batch: 4 ,loss: 699261.500000
epoch: 0, batch: 5 ,loss: 727906.812500
epoch: 0, batch: 6 ,loss: 696439.875000
epoch: 0, batch: 7 ,loss: 669801.500000
epoch: 0, batch: 8 ,loss: 669526.875000
当我们训练好模型后,就可以使用训练好的模型进行预测了。
模型预测
我们使用训练好的模型进行预测,在这里我们通过yoloV3模型进行预测,并将预测结果绘制在图像上。首先导入工具包,预训练好的模型是使用coco数据集进行训练的,所以指定相应的类别信息:
# 读取图像,绘图的工具包
import cv2
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
# yoloV3的预测器
from core.predicter import Predictor
# coco数据集中的类别信息
classes = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',
'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
'skateboard', 'surfboard','tennis racket', 'bottle', 'wine glass', 'cup', 'fork',
'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli',
'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant',
'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
整个流程是:
1.读取要进行目标检测的图像
2.实例化yoloV3的预测器,并加载预训练模型。
3.利用预测器对图片进行目标检测
4.将检测结果绘制在图像上
实现如下:
# 1. 图像读取
img = cv2.imread("image.jpg")
# 2.实例化,并加载预训练模型
predictor = Predictor(class_num=80, yolov3="weights/yolov3.h5")
# 3.获取检测结果
boundings = predictor.predict(img)
# 4.将检测结果绘制在图像上
# 4.1 显示图像
plt.imshow(img[:, :, ::-1])
# 获取坐标区域
ax = plt.gca()
# 4.2 遍历检测框,将检测框绘制在图像上
for bounding in boundings:
# 绘制框
rect = Rectangle((bounding[0].numpy(), bounding[1].numpy()), bounding[2].numpy(
) - bounding[0].numpy(), bounding[3].numpy()-bounding[1].numpy(), color='r', fill=False)
# 将框显示在图像上
ax.add_patch(rect)
# 显示类别信息
# 获取类别信息的id
label_id = bounding[5].numpy().astype('int32')
# 获取类别
label = classes[label_id]
# 将标注信息添加在图像上
ax.text(bounding[0].numpy(), bounding[1].numpy() + 8,
label, color='w', size=11, backgroundcolor="none")
# 显示图像
plt.show()
预测结果如下图所示:

总结
- 熟悉TFRecord文件的使用方法
TFRecord是Google官方推荐使用的数据格式化存储工具,为TensorFlow量身打造的。TFRecord内部包含多个tf.train.Example,一般来说对应一个图像数据,在一个Example消息体中包含了一系列的tf.train.feature属性,而 每一个feature是一个key-value的键值对。
- 知道YoloV3模型结构及构建方法
基本组件的构建,backbone,output, yoloV3, 输出值的转换
- 知道数据处理方法
知道对图像进行resize,保持宽高比,进行pad的方法
- 能够利用yoloV3模型进行训练和预测
知道损失函数,正负样本设置,进行训练,并预测的过程。