Kaggle Titanic Challenges 生存预测 数据预处理 模型训练 交叉验证 步骤详细解析
本博客所有内容均整理自《Hands-On Machine Learning with Scikit-Learn & TensorFlow》一书及其GitHub源码。
看《Hands-On》一书至第三章,习题里面后两题是实际操作的编程题,自己初步动手效果不错,特此记录一下。
运行环境:Jupyter Notebook 语言:Python3.6.4
0、题目描述
Kaggle的Titanic Challenges经典题源自那次震惊世界的沉船事故,要求你根据一些特征,如Titanic的乘客的年龄,性别,客舱等级,在哪上船等等,来预测某一名乘客最终是否从这次劫难中生还。我是听说根据数据显示,那次沉船事故毕竟是发生在所谓永不沉没的Titanic号上,所以死亡人数并不算多,但大部分死亡人士都是低等级客舱的穷人,而生还的大部分都是高级客舱的富人!所以,接下来让我们一步步来利用机器学习的方法来进行一下数据分析和预测吧!
具体有哪些特征我们需要后续下载了数据集之后自己观察,总之最终的目标就是去预测某一ID的乘客是否在这次沉船事故中生还,将预测的生还情况上传到Kaggle官网就可以得到你的训练得分。
在这里把预测数据生成csv以及上传数据就省略了,主要是详细解析和描述一下数据预处理,模型训练和交叉验证这三个机器学习过程,总体目标是获得80%以上的准确率。(先定一个小目标)
1、数据预处理
首先,我们从Kaggle官网下载train.csv和test.csv,这两个表格分别代表训练集和测试集,将其放在你的工程目录下的合适位置,便于读取;在这里,我是在工程目录下建了一个文件夹名为“datasets”,然后在“datasets”文件夹里再建了一个文件夹名为“titanic”,然后把train.csv和test.csv都放在“titanic”文件夹内。
第一步,当然是读取这两个数据集,读取的方式是采用pandas的read_csv()函数,该函数接受一个文件路径,读取该文件。
import os
TITANIC_PATH = os.path.join("datasets", "titanic")
import pandas as pd
def load_titanic_data(filename, titanic_path=TITANIC_PATH):
csv_path = os.path.join(titanic_path, filename)
return pd.read_csv(csv_path)
train_data = load_titanic_data("train.csv")
test_data = load_titanic_data("test.csv")这里import os是用来获取文件路径的。函数load_titanic_data是用来专门读取数据的,避免使用绝对路径。
其实上面的代码效果类似于:
train_data = read_csv(".../train.csv")
test_data = read_csv(".../test.csv")其中...代表你的文件路径。
读入数据之后,一般来说可以先看一下各个数据的基本情况,使用head()函数来显示前五个数据。
train_data.head()
test_data.head()效果如下图所示:
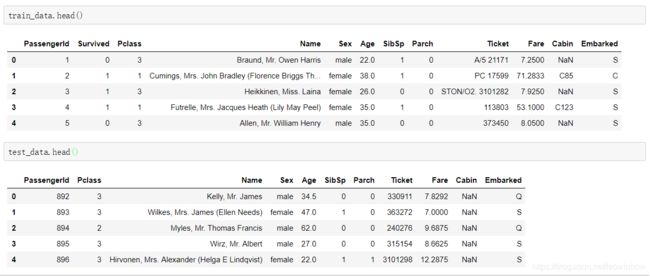
从显示情况来看,训练数据有乘客ID,生还情况(1代表生还,0代表未生还),客舱等级,姓名,性别,年龄,SibSp,Parch,票号,票价,客舱号,上船点,一共12个特征。而训练集则是没有生还情况,只有其他11个特征。
其中,有两个特征我都是直接用的英文,因为英语六级的我并不理解这是个什么意思,其实这种情况很普遍,很多时候我们获取的数据根本就是乱的,很少像上面这样是别人帮你一一校对好的,而且事实证明就算是校对好的数据集,也很可能有特征你根本理解不了。遇到这种情况不要担心,我们可以上网去搜一下,或者索性就让它是英文,管它代表什么呢,拿着训练就是了,说不定机器学习模型会告诉我们这是个什么呢!
其实SibSp和Parch这两个特征读不懂真不怨我英语水平不行,根据搜索,其实这两个特征词是简写拼凑单词,SibSp代表siblings&spouses,即兄弟姐妹和配偶,即该乘客有多少兄弟姐妹和配偶在船上(可能像Rose就会被统计成有两个配偶在船上吧),Parch则代表children&parents,即小孩和父母,即该乘客有多少子女和父母在船上。其实想想也有道理,如果一个人的亲属在船上,该人可能会有更大的欲望去求生。
OK,接下来我们着重关注训练集,因为这种情况下,训练集和测试集已经分好了,我们在训练模型时应单独使用训练集,而把测试集放到一边,最后把模型训练完成之后再去拿测试集预测。
我们观察训练集的第一行就可以发现,编号为0的乘客丧生了,但是,很重要的是,该乘客的cabin特征的取值是NaN,即not a number,一般来说这种情况即说明,该乘客的该特征的取值缺失了。很明显,特征取值缺失将是一个比较重要的事情,所以,在使用head()函数总体预览了一下特征情况之后,我们应该使用info()函数来观察一下特征取值的情况。
train_data.info()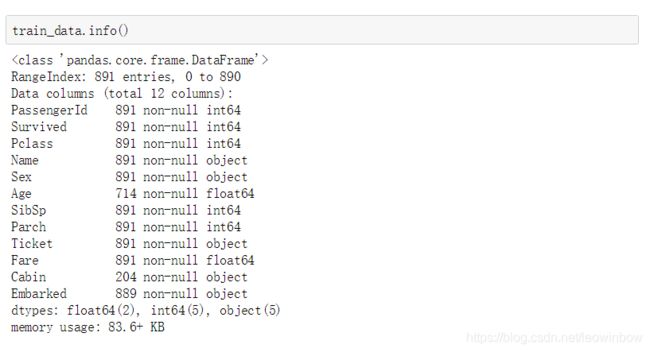
info()函数会返回数据集的特征取值个数和取值类型。我们可以发现,一共有891个乘客情况被记录进了训练集,被编号为0~890;其中,一共有12列数据,即一共有12个特征;每个特征的取值情况都被列了出来,其中,Age, Cabin, Embarked这三个特征均有缺失值的情况,其他特征均是无缺失。在数据类型方面,有2个特征取值是浮点数,有5个特征取值是整数,还有5个特征取值是非数值,即文字型取值,比如姓名特征就肯定是字母变量了。
看到这张情况,我们首先来决定如何处理缺失值的情况。
根据显示结果,我们首先关注Cabin。该特征仅仅只有204个特征取值,跟总量891相比太少了,所以该特征的缺失值填充将很有可能出现偏差导致最终结果不准确,所以,我选择将该特征忽略!
其次,Age特征有714个特征取值,即大概有不到20%的特征取值缺失。考虑到年龄是整数取值,有可能影响到体力等在救生情况下很重要的特征,所以我认为不应该将其忽略。至于缺失值填充,除了使用平均值填充也想不到其他更好的办法了。
最后,对于Embarked这个特征,由于它代表着上船点,感觉挺重要的,而且仅仅缺失了2个取值,所以我认为不能将其简单忽略。至于取值填充,由于它是一个非数值特征,所以理论上来说根本没有现成的好办法来实现,所以暂时不处理。
决定完缺失值情况之后,我们应该继续观察特征,清洗自认为不需要的特征。
对于这个情况,一个人在劫难面前能否生还,我认为起码和他(她)的名字和票号是无关的。在数据面前,还是暂时保持无神论。其他的,我感觉多多少少还是有点关系。性别和年龄有可能预示着有更多的女性和小孩会得到照顾,票价可能预示着该人是否是有钱人,客舱等级和上船点同理,亲属情况我上面说了,是有可能激起一个人的求生欲的,而乘客ID本来是没有什么信息可以展示的,但是因为它是数值信息,我暂时选择不处理。
经过这一番深思熟虑之后,我们对数据集有了全新的认识,基于个人经验。
接下来我们使用describe()函数再来看看数值数据的具体统计情况,该函数会返回数值特征的统计情况。
train_data.describe()
根据结果我们可以看到,训练集当中的891个人当中,有38%的人生还了,理论上来说,我们最终的预测情况应该接近38%的生还率。
我们接下来具体看看有多少人生还,多少人丧生。使用value_counts()函数就可以具体统计某一特征,一般来说我们使用该函数来统计分类特征,因为回归特征的取值太多且很可能是浮点数,结果看起来没有分类特征那么清晰。于是在这里我们索性一起来看看几个分类特征的具体统计情况。
train_data["Survived"].value_counts()

train_data["Pclass"].value_counts()
train_data["Sex"].value_counts()
train_data["Embarked"].value_counts()
根据具体统计情况我们可以看到,一共有342人生还。整个船共有3个客舱等级,按照我的理解应该是3级是最低等级的客舱,因为人多。性别上来说,男性明显更多,有577个男性,314个女性。而上船点则主要集中在S,所以S极有可能是出发点。
分析了这么多,我们对特征的情况应该算是比较了解了,接下来我们就来利用管道来具体进行数据预处理。
首先,我们当然是要把数值特征和分类特征分开,因为分类特征的取值有时候也是数值,但是表示的意义完全不同,比如生活情况的取值,全是0和1,但数据本身和0,1这两个数字没有任何关系,0和1只是代表他们的类别不同而已。这种情况下,数值特征和分类特征混在一起很可能会使训练器产生误会,比如说认为取值为1的比取值为0的更“大”,但其实分类特征的取值并没有这种意义。
为此,我将创建一个类,该类专门用于将数值数据和分类数据分开。
from sklearn.base import BaseEstimator, TransformerMixin
#用于将数值特征和分类特征分开的类
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names]上面这段代码是《Hands-On》一书的第67页给出的,功能就是将数值特征和分类特征分开,具体的BaseEstimator和TransformerMixin是什么,怎么使用,实在是比较复杂这里就不再赘述,请自行百度学习。其实如果只看到该书的第三章,我也不明白这些用法,这里选择将这一步直接引用过来,总之能完成分开数值特征和分类特征的任务。
接下来我们首先来获取处理数值特征的管道。
根据上面对特征的观察,我们肯定在这里是要进行缺失值填充的,填充的具体方式就是使用imputer函数。
所以在数值管道里,我们首先使用上面定义的类选取出数值特征,然后使用imputer函数进行缺失值填充。
from sklearn.pipeline import Pipeline
try:
from sklearn.impute import SimpleImputer # Scikit-Learn 0.20+
except ImportError:
from sklearn.preprocessing import Imputer as SimpleImputer
num_pipeline = Pipeline([
("select_numeric", DataFrameSelector(["Age", "SibSp", "Parch", "Fare"])),
("imputer", SimpleImputer(strategy="median")),
])这里对于imputer函数的导入使用了一个try-except句式,处理Scikit-Learn版本不同的问题。
具体的缺失值填充方式我使用的是均值填充,主要需要填充的也就是年龄了,其他数据都是齐全的。
数值管道做好之后,我们可以调用fit_transform()函数来对训练集数据进行处理。
num_pipeline.fit_transform(train_data)
我们看到,处理完之后数据就齐全了。我们之前在统计情况里看到过,年龄的平均值是29多一点,所以年龄里面取值为29.699118的就很可能是填充的。
至此,数值特征就处理好了。具体来说,选取数值特征之后,其实就只是进行了缺失值的填充。
接下来就要获取处理分类特征的管道。
这里需要注意的是,分类特征也需要填充缺失值,然而缺失值怎么填充却不再是一个简单的问题。
上面对于数值特征,我们可以对已有数据进行计算,通过平均值或者更复杂的处理得到一个比较普遍的数值进行填充。
但是分类特征沿用这个思路就肯定行不通,因为分类数据有可能是非数值的数据,就算是数值数据,数值也不具有数字本身的意义。
这里我们前面说过,需要填充的只有Embarked,而且只缺了2个值!所以呢,我在这里对分类数据的填充选择了一个很好理解的方式,统计所有的已有数据,选择其中最多的种类作为缺失值的填充方式。这很好理解,就好比我们要统计一个草原上的牛的种类,根据已有数据我们算出黄牛占80%,水牛占20%。如果此时发现有一头牛不见了,我们找不到但却没有统计过它的种类,但又明确知道它的存在,那我们就更倾向于认为那头牛是黄牛。
根据这种思路,我们定义一个特定的类来处理分类缺失值。
class MostFrequentImputer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
self.most_frequent_ = pd.Series([X[c].value_counts().index[0] for c in X],
index=X.columns)
return self
def transform(self, X, y=None):
return X.fillna(self.most_frequent_)index[0]就代表种类数目较多的那个种类。
填充了缺失值之后,我们还需要对分类特征进行独热编码,即OneHotEncoder。独热编码的意义很简单,我们现在获取的分类数据很可能不是二分类的,比如说Embarked特征就是三分类的,这种情况下并不利于我们统计以及转换成数值,所以我们采用独热编码,即满足该特征则取值1,否则取值0。这样整个的数据集就全都是由0和1组成的。
据此,我们可以获得处理分类特征的管道。
try:
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import OneHotEncoder
except ImportError:
from future_encoders import OneHotEncoder # Scikit-Learn < 0.20
cat_pipeline = Pipeline([
("select_cat", DataFrameSelector(["Pclass", "Sex", "Embarked"])),
("imputer", MostFrequentImputer()),
("cat_encoder", OneHotEncoder(sparse=False)),
])该管道首先选择分类特征,然后进行缺失值填充,最后进行独热编码,并且不以稀疏矩阵的方式存储。
同样,我们使用fit_transform()函数来看一下管道处理之后的数据。
cat_pipeline.fit_transform(train_data)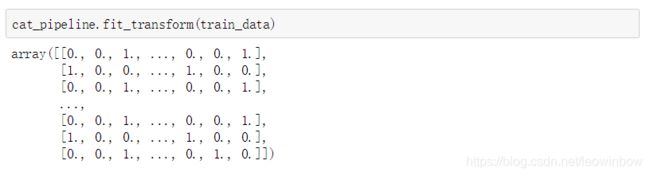
很明显,全都是0和1!
至此,分类特征就处理好了。具体来说,首先选取分类特征,然后进行缺失值填充,最后进行独热编码。
最后,我们将之前做好的数值特征管道和分类特征管道进行组合,获得一个综合管道,该综合管道既可以处理数值特征,又可以处理分类特征。调用FeatureUnion函数来进行特征管道的组合。
from sklearn.pipeline import FeatureUnion
preprocess_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline),
])至此,我们就得到了一个能够一次性对所有特征进行清洗的特征管道。
最后,我们就要对原先有一定缺陷的训练集数据进行数据预处理,也就是数据清洗,清洗之后的训练集数据将只包含有用特征,而且不存在缺失值,并且全部是数值取值。
X_train = preprocess_pipeline.fit_transform(train_data)
X_train
从结果可以看出,经过预处理之后的训练集数据,很明显非常干净。最后,我们将生还情况作为标签。
y_train = train_data["Survived"]至此,我们就得到了一组非常干净的训练集数据,由X_train存储特征,由y_train存储标签。
数据预处理过程,到此结束!
其实大部分的机器学习模型的最终效果,都是取决于数据预处理的情况,数据预处理得越好,模型训练的效果就越好。
而且数据预处理过程基本都是根据人为经验来进行,比如选取哪些特征,摒弃哪些特征,比如选取什么样的计算方式来作为缺失值填充的计算公式,以及选取什么样的决策来实现分类特征值的填充。
2、训练模型
数据预处理完成之后,我们就可以进行模型的训练了。
说起来机器学习应该是从训练模型开始的,因为机器学习的原理就是从训练集训练出模型,然后用该模型去处理测试集,获得对测试集的预测结果。
但是其实,数据预处理非常非常重要,而且人为参与很多,人为经验对结果的影响也很大。
而相反,训练模型这一步呢,人为参与很少,人为经验对结果的影响也很小。
进入正题,很明显,我们这里的目标是训练出一个分类器,更精确地说是一个二分类器,预测0和1,也就是生还还是丧生。
说到分类任务,有很多模型可以使用,比较脍炙人口的莫过于支持向量机和决策树,在这里我就把这两种方法都用一遍,反正最后要进行交叉验证,我们根据交叉验证的结果优劣来决定使用哪一个。
首先,使用支持向量机。
其实训练模型的步骤很简单,导入模型,训练,预测结果。Over!首先导入模型。
from sklearn.svm import SVC
svm_clf = SVC(gamma="auto")
svm_clf.fit(X_train, y_train)其中gamma="auto"表示,如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features。gamma具体表示什么,涉及到支持向量机的计算公式,这里就不详述了。总之,这个参数过大会过拟合,过小会欠拟合,一般都取“auto”。
然后,使用之前的综合管道去清洗测试集数据,再根据训练集获得的模型进行预测。
X_test = preprocess_pipeline.transform(test_data)
y_pred_svm = svm_clf.predict(X_test)至此,y_pred_svm就是我们使用支持向量机预测的结果!
接下来,使用决策树。
步骤非常简单,几乎和使用支持向量机相同。这里我们使用随机森林分类器,因为随机森林是多棵决策树共同决策的结果,效果更佳。
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42)
forest_clf.fit(X_train, y_train)
y_pred_rf = forest_clf.predict(X_test)至此,y_pred_rf就是我们使用随机森林预测的结果。
训练模型的过程到此结束!
3、交叉验证
最后,我们来进行一下交叉验证,来看看效果。
在上一步,我们训练获得了两个模型,一个支持向量机模型,一个随机森林模型。
我们可以去看y_pred_svm和y_pred_rf,然后对比。如果有真实的测试集的结果,就可以获得这两个模型的训练效果优劣了。
但是呢,我们没有。既然是测试集,就是没有结果的。
然而,我们可以使用交叉验证来完成这个效果检测的功能。交叉验证简单来说就是在训练集当中选取一部分作为验证集,训练时只使用除去验证集之后的训练集,然后把验证集拿来做预测,将预测结果与验证集本身的真实结果进行对比,获得模型预测准确率。当然了,也不一定是使用准确率来描述效果,还有f1_score等更均衡的衡量标准,在这里只做最简单的效果对比,准确率足够。
首先是支持向量机模型:
from sklearn.model_selection import cross_val_score
svm_scores = cross_val_score(svm_clf, X_train, y_train, cv=10)
svm_scores.mean()

然后是随机森林模型:
forest_scores = cross_val_score(forest_clf, X_train, y_train, cv=10)
forest_scores.mean()
从结果上可以看出,同样是10折的交叉验证,随机森林的预测准确率明显高于支持向量机!所以对于这个数据集和分类要求,随机森林分类器性能更好!
当然,每个模型都有很多很多的超参数,如果我们细致地去进行超参数调优,肯定能获得比现在的效果好很多的模型。但是具体的模型调优实在复杂,这里忽略。
交叉验证的过程到此结束!
4、总结
至此,我训练了一个支持向量机模型和一个随机森林模型,其中随机森林分类器已经达到了80%以上的准确率,完成了最早初设的小目标!
最后总结一下本项目的基本步骤:
- 数据预处理:包括数据下载,数据读取,数据观察,剔除无用特征,数值特征与分类特征的分离,缺失值填充,独热编码
- 训练模型
- 交叉验证
其实最多的工作都是在数据预处理部分,虽然这部分内容可能还没有开始进行机器学习,但却是最复杂、最重要且可能影响最大的部分。后面对训练结果影响较大的可能就是超参数调优,但调优过程非常复杂且不具有普适性,基本上必须根据实际项目来实际确定调参方法。