论文阅读笔记——Attention is all you need
(!!!!事先声明!这不是技术分享贴!CSDN虽说都是大佬们的分享平台,但是我只是想把它当做是我的云笔记,内容不敢保证全部正确,风格也都只用自己能懂的大白话,写的时候当做日记记录心情,所以请不要随便评价别人日记写的如何如何,作者童心未泯脾气大,不接受批评,只接受表扬与讨论,不想看请移步大佬贴,谢谢)
前言
2021年,研一下学期,这是我在CSDN上写的第一个博客
其实对于人生这漫漫长路而言,研究生学习时间真的很短暂,上学期就想着多读读论文,多跑跑实验,不要浪费大好青春,可这一学期下来感觉自己越发的懒惰。好不容易读的那些文章统统忘了个差不多,寒假因疫情原因没回家,每天浑浑噩噩虚度光阴。
感觉不能再这样下去了!既然自己懒惰,那就逼着自己写写代码写写博客好了,并且给自己定个小目标:至少一周阅读两篇论文,其中一篇要精读+写笔记(瞎tmd立flag,看看我能坚持多久吧哈哈哈)
对这篇文章的看法:
Transformer在我看来,可是具有夸时代意义的文章(如今AI大佬们打的水深火热,一个时代也就一年时间吧),attention机制的提出让NLP领域有着飞速的进展。其实最早我接触attention机制的时候还是个连CNN都不懂的小萌新,除了NB也说不出什么别的话来。现在是2021年初,学术届的研究方向已经到了将attention应用到CV上来,我也要紧随时代潮流才可以。然而看来看去发现,这篇文章是基础,看不懂这最经典的,怎么继续深造?
(于是乎写个笔记怕自己以后忘)
OK 废话连篇,开始正题
论文原址:https://arxiv.org/abs/1706.03762
带领我入门transformer的大佬贴:https://www.cnblogs.com/baobaotql/p/11662720.html
1.模型结构
模型结构看似复杂其实简单,它就是一个encoder+decoder的结构

- 输入是positional embedding和word embedding 结合
- 接下来走过N个encoder
对于每个encoder而言,里面包含了
a.Multi-head attention
b.Feed forward network - 紧接着把N个encoder输出来的东西,作为输入,传入N个decoder中(是每一个!如简化图所示)
对于每个decoder而言,里面包含了
a.Masker Multi-head attention
b.Multi-head attention
c.Feed forward network - 最后Linear+softmax预测概率作为output
后面所讲内容,均按照上述模型顺序排列(我觉得好多文章难以读懂的原因,就是因为论文它讲述顺序有问题,让人脑海里无法构建一个模型框架@_@)
借鉴一下别人的模型简化图
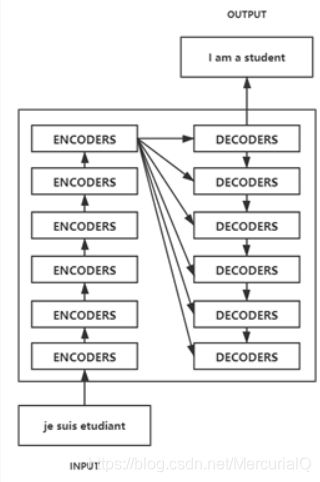
2.结构内部细节
2.1 positional embedding + word embedding
首先是word embedding(词嵌入),可以理解为是词向量,对于NLP领域的任务来说,所有的单词或者文本,都对应着一个向量,这个向量被称为word embedding。词嵌入是有很多前辈们已经设计好了的向量,对于一段文本,里面的每个单词都会被设计成一个向量,所以一句话可以看作是好多 词向量 的序列。类似one-hot 编码,word2vec都是可以应用的word embedding。
至于positional embedding,很早以前就有学者尝试把单词的位置作为信息,用在任务中,毕竟语言这种东西错综复杂,位置也是很重要的一个方面。而在这片文章中,attention机制,位置关系更加重要,因此文章中提出了一个计算positional embedding的方法,计算出来的positional embedding再和word embedding进行简单加和,作为后续模型的input。这样一来,用作训练的数据,包含了(文本内容)和(位置信息)。
文章中提到的计算方法,实在是难以看懂,我就照搬好了。一个sin一个cos,作者实验证明两个方法差不多,最后选择了sin函数,因为这样训练出来的sequence更长??不太懂

2.2 Encoder
这篇文章使用了6个一样的encoder和6个一样的decoder,直接堆叠l
单独拿出其中一个encoder,里面包含了两个子层,multi-head attention和feed forward network

这是我用文章中三个小图拼接出来的大图
图一是一个encoder,其中下面这个子层单独拿出来,是图二。
图二里面是h个小结构堆叠,进行concat然后输出结果向上传,这个小结构就是图三。
2.2.1 Multi-head Attention
Attention(对应小图图三)
先说图三,继续网上盗图

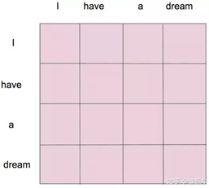
QKV从哪里来?就是将输入X 进行三种不同的线性变换(可以用三个不同的小网络层)得到的query, key, value。其中把当前输入X 生成的Q(如图中的thinking)和每一个单词的K进行乘积,分别得到当前输入X (thinking)和每一个单词(thinking machines)的关联程度,再softmax处理得到概率,最后按照这个概率矩阵乘以V,得到最后的Z。
有一点点复杂,表述不清也是因为能力有限,我实在是理解不到位,总之QKV可以理解为是一个如下图所示的attention map,最后的输出Z,就包含了词与词之间的关联度,最终达到attention,注意力机制的算法初衷。
直接把文章中的公式放下来

Multi-head (对应小图图二)
多头注意力,其实就是有h个这样的小结构,一共产生了h个z,接着把这些z整合成一个大Z,向上传送。论文中一共使用了8个。使用多头注意力机制的原因,我暂时也很难理解,为什么Transformer 需要进行 Multi-head Attention? 这个大佬的回答讲的应该很清楚(目前看不懂),总之就是能更全面的感受一个单词和其他位置的关联程度。

如公式所示,将这些小z直接依次拼接成一个长长的大Z,即公式中的concat,再乘以一个矩阵W0做线性变换,得到最终输出,传入上面的feed forward net中。
2.2.2 Feed Forward Net (FFN)
这个FFN层,翻译过来叫前馈神经网络,结构简单,如图,xW1+b1做线性变换之后,通过relu得到结果,再次进行xW2+b2,只是非常简单的变化,然而这种繁琐的步骤意义是什么呢?
通过查阅我发现,将FFN与CNN想比,它的作用和1×1卷积核作用一样的。其实一个FFN层,主要目的是提取特征,线性变换+RELU再+线性变换,等同于一个1×1的CNN层。这个FFN在每一个encoder或decoder都作为最后一个sub layer,达到提取特征的效果。至于为什么叫这个名字,可能得问作者本人了。

2.3Decoder
Decoder 的结构和Encoder差不多,但是多了一个Masked Multi-head Attention目的主要是不给模型看到未来的信息,详细来说,第一个单词只能和第一个单词有attention,第二个单词可以有连个attention以此类推,如图(疯狂盗图)
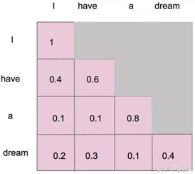
(文章原话:This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i)
2.4最后的linear和softmax
模型会最终输出一个实数向量,我们要把这种浮点数变成单词,就是最终这个线性变换层来实现,进行结果预测。
3.总结
最后就是作者做的实验和一些实验细节等等,总之transformer这篇文章,我认为是NLP领域,甚至是深度学习领域的一个重要转折点,后面继续阅读的模型,都以此为基础(主要是如何将transformer应用到CV领域中,目前已经在图像分类、图像分割、目标检测三种类型的任务中,有了显著的性能提升,也是我接下来比赛或者做项目计划尝试的方法。)