一文看懂推荐系统:物品冷启04:Look-Alike 召回,Look-Alike人群扩散
一文看懂推荐系统:物品冷启04:Look-Alike 召回,Look-Alike人群扩散
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
【10】一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
【11】一文看懂推荐系统:召回09:地理位置召回、作者召回、缓存召回
【12】一文看懂推荐系统:排序01:多目标模型
【13】一文看懂推荐系统:排序02:Multi-gate Mixture-of-Experts (MMoE)
【14】一文看懂推荐系统:排序03:预估分数融合
【15】一文看懂推荐系统:排序04:视频播放建模
【16】一文看懂推荐系统:排序05:排序模型的特征
【17】一文看懂推荐系统:排序06:粗排三塔模型,性能介于双塔模型和精排模型之间
【18】一文看懂推荐系统:特征交叉01:Factorized Machine (FM) 因式分解机
【19】一文看懂推荐系统:物品冷启01:优化目标 & 评价指标
【20】一文看懂推荐系统:物品冷启02:简单的召回通道
【21】一文看懂推荐系统:物品冷启03:聚类召回
提示:文章目录
文章目录
- 一文看懂推荐系统:物品冷启04:Look-Alike 召回,Look-Alike人群扩散
- Look-Alike 召回:Look-Alike起源于互联⽹广告
- Look-Alike⽤于新笔记召回
- 总结
Look-Alike 召回:Look-Alike起源于互联⽹广告
Look like人群扩散,召回look like是互联网广告中常用的一类方法,
这种方法也可以应用在推荐系统,特别是召回低曝光笔记。
look like本身就起源于互联网广告,假设有个广告主想精准的给100万个目标受众投放广告,

假设广告主是特斯拉,他们自己知道model three的典型用户是这样的。
年龄在25到35,
都是年轻人,
受过良好教育,
学历至少都是本科。
特斯拉车主大多关注科技数码,
而且普遍喜欢苹果的电子产品,
把符合全部条件的用户都圈出来,重点在这个人群中投放广告,
满足所有条件的受众,被称作种子用户。
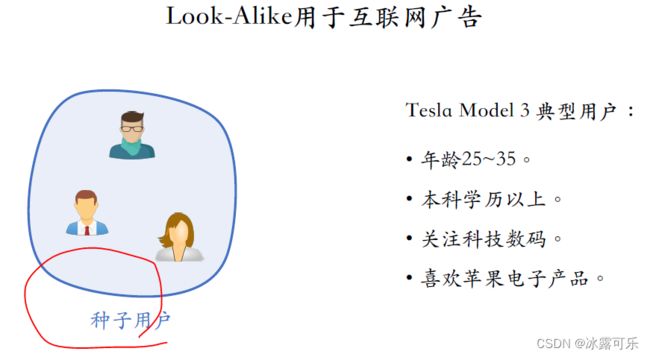
这样的用户数量不会很多,可能只有几万人【很多人是不会给你写标签的】,但是潜在的符合条件的用户可能会很多。
但是我们缺少他们的部分信息,没有办法找到他们。
比方说多数的用户不标自己的学历和年龄,
广告主想给100万用户投放广告,但我们才圈出几万人。
我们该如何发现100万潜在的目标用户?
这就要用到look like人群扩散,寻找跟种子用户相似的用户,把找到的用户称作look like。
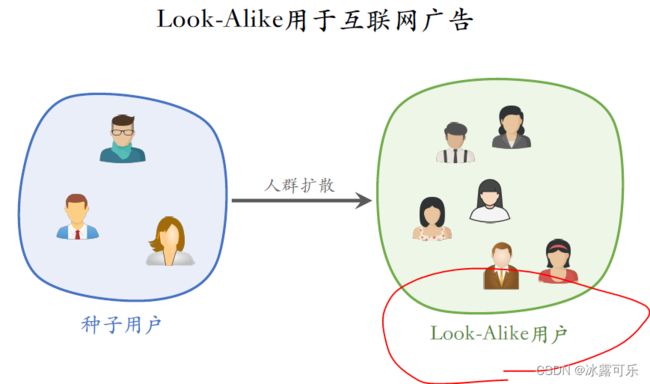
用户通过这种方式可以利用几万个种子用户,找出几十万个look like用户。
look like只是个框架。具体该怎么样扩散,有各种各样的算法,
最重要的问题在于如何定义两个用户之间的相似度。
有很多简单的方法,前面协同过滤课程讲过user cf及两个用户共同兴趣点,
衡量两个用户的相似度,要是两个用户同时对很多相同的物品感兴趣,
说明两个用户的相似度比较大。

还有一种方法是用两个用户的ID embedding向量。
前面介绍双塔模型的时候,我们用向量表征用户,
如果两个用户相似,那么两个夹角的余弦值就会比较大。
Look-Alike⽤于新笔记召回
下面我介绍look like在小红书的落地应用。
小红书把look like用于新笔记召回,各种主要指标都有显著的提升。
在冷启动的场景下,Look like主要思想是这样的,

如果用户有点击、点赞、收藏、转发的行为,说明用户对笔记可能感兴趣
把有点击、点赞、收藏、转发行为的用户作为新笔记的种子用户,
我们知道这些种子用户对新笔记感兴趣。
如果一个用户跟种子用户相似,那么他也可能对这篇新笔记感兴趣,可以把新笔记推荐给他。
这种方法就叫做look like人群扩散,
根据种子用户找出更多兴趣相似的用户,把新笔记从种子用户扩散到更多look like用户。
下面我要具体讲look like怎么用。
在新笔记召回上,用户在小红书上发布一篇新笔记,
系统会把新笔记推荐给很多用户,
少数用户会对笔记感兴趣,会点击、点赞、收藏、转发,把这些用户称作种子用户。
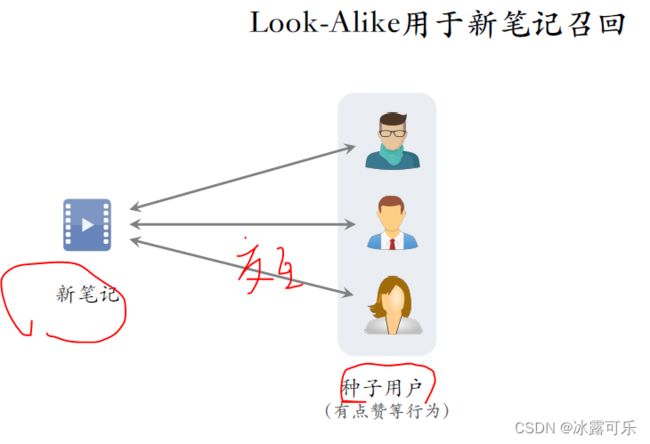
系统对新笔记的推荐通常不太准,有交互行为的用户数量很少。
一旦有交互行为,我们就要充分利用这种信号,让推荐变得更准,
取回每个种子用户的embedding向量。
我们可以复用双塔模型渠道的用户向量,然后取这些用户向量的均值,得到一个向量,
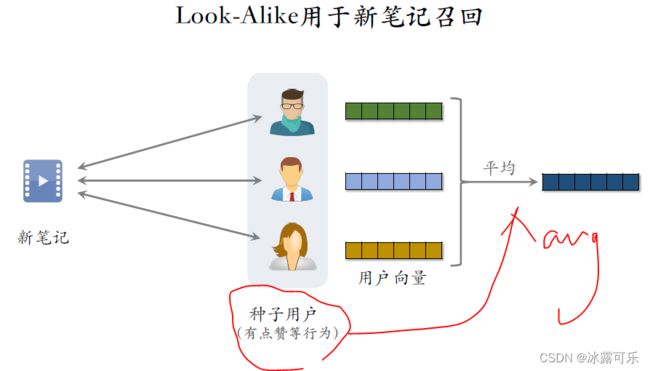
把得到的这个向量作为新笔记的表征,这个向量反映出什么样的用户对该笔记感兴趣。
这个特征向量是要做近线更新的,近线的意思是不用实时更新,能做到分钟级的更新就可以了。
回忆一下这个特征向量是怎么样算出来的。

这个特征向量是有交互的用户的1000向量的平均,
如果有三个用户对该笔记点赞或者收藏,那就对三个用户的1000向量也得加上去。
所以每当有用户交互,该笔记就得更新一下笔记的特征向量。
我们可以做到近线更新,也就是交互发生之后几分钟就能更新笔记的特征向量,在线实时更新还做不到。
也没有必要在几秒内就更新特征向量。
线上召回是这么做的,把新笔记的特征向量都放在向量数据库里,

这些向量数据库都支持最近零查找。
如果有用户刷一下小红书,我们就给这个用户做一次推荐,
用双塔模型计算这个用户的特征向量【这个并是上面咱们求出来的look alike平均用户向量,这就是一个正常用户】,
拿用户的特征向量做QUERY,在向量数据库中做最近零查找。
【这些笔记可能含有新笔记,新笔记是哪些look alike用户向量的平均,你get到了吗???】
【所以最后一个用户和新笔记向量的相似度实际上就是这个用户跟这个笔记交互的用户平均向量的相似度
其实就可以解释,为啥别的用户喜欢新笔记了,因为别的用户和哪些跟新笔记交互的用户很相似哇】
【好好想想这个过程哦】
返回几十篇笔记,这个召回通道就叫做look like。
我已经讲清楚了,Look like是怎么样,
作为推荐系统的召回通道看起来跟广告的look like不太一样,但其实是一回事儿。
最后我再解释一下,左边是新笔记,图中的边表示有交互行为,

有交互行为的用户叫做种子用户,
右边的用户跟种子用户比较相似,
如果中间的用户喜欢这篇新笔记,那么右边的用户很可能也会喜欢这篇新笔记,
这就是look like人群扩散召回通道。
【我们用种子用户向量的平均表征新笔记,去跟右边用户求相似度,
实际上就是求右边用户对新笔记的喜好,也是右边用户跟种子用户的相似计算】
小红书推荐系统的look like其实跟广告中的look like的原理是相同的,
这节介绍了look like召回通道,专门用于物品能启动哦!
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:我们用种子用户向量的平均表征新笔记,去跟右边用户求相似度,实际上就是求右边用户对新笔记的喜好,也是右边用户跟种子用户的相似计算