MAPPO:The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games
MAPPO
- 论文代码
- 1.研究动机是什么
- 2.主要解决了什么问题
- 3.所提方法是什么
-
- MAPPO算法细节
- 提升PPO性能的5个关键
- 4.关键结果及结论是什么
-
- 主要结论
-
- MPE实验
- SMAC实验
- Hanabi实验
- 消融实验
-
- 值归一化
- Agent-Specific Global State
- Training Data Usage
- Action Masking
- Death Masking
- 5.创新点在哪里
- 6.有值得阅读的相关文献吗
- 7.综合评价又如何
-
-
- 参考链接
-
论文代码
- 论文链接:https://arxiv.org/abs/2103.01955
- 代码地址:https://github.com/marlbenchmark/on-policy
- 代码讲解:
1.研究动机是什么
早期的研究表明,在连续控制任务中,on-policy算法TRPO优于off-policy算法DDPG。然而,在最近的off-policy方法SAC和Rainbow中认为,即使是最新的PG算法PPO,采样效率也明显低于off-policy方法。
在许多单智体领域(MuJoCo,Atari和机器人系统),目前off-policy方法在样本复杂度上是SOTA的。
在多智能体领域也有类似的结论:多智体PG方法COMA在MPE和SMAC上的表现均明显优于MADDPG和QMix。
尽管IPPO可以在一些特定的hard SMAC地图上表现出高成功率,但原因尚不清楚,而且IPPO的整体表现仍然比QMix差得多。
作者重新检验了这些关于PPO的结论,并表明MAPPO能够在3个主流的MARL合作试验台上实现SOTA性能。
单智体技巧:input normalization, value clipping, orthogonal initialization, and gradient clipping ,regularization(文中用normalization layer),离散任务使用soft trust-region penalty and discretizing the action space避免连续控制的局部最优问题,以上多智体领域同样适用,文中作者都用了。
2.主要解决了什么问题
3.所提方法是什么
POMDP定义为 ⟨ S , A , O , R , P , n , γ ⟩ \langle\mathcal{S}, \mathcal{A}, O, R, P, n, \gamma\rangle ⟨S,A,O,R,P,n,γ⟩, S \mathcal{S} S是状态空间, A \mathcal{A} A是智能体共享动作空间, o i = O ( s ; i ) o_{i}=O(s ; i) oi=O(s;i)是每个智能体局部观测空间, P ( s ′ ∣ s , A ) P\left(s^{\prime} \mid s, A\right) P(s′∣s,A)是状态转移概率, R ( s , A ) R(s, A) R(s,A)表示智能体共享奖励。算法采用CTDE框架,每个智能体使用共享策略 π θ ( a i ∣ o i ) \pi_{\theta}\left(a_{i} \mid o_{i}\right) πθ(ai∣oi),利用局部观测 o i o_{i} oi生成其动作 o i o_{i} oi,优化自己的折扣累计回报 J ( θ ) = E a t , s t [ ∑ t γ t R ( s t , a t ) ] J(\theta)=\mathbb{E}_{a^{t}, s^{t}}\left[\sum_{t} \gamma^{t} R\left(s^{t}, a^{t}\right)\right] J(θ)=Eat,st[∑tγtR(st,at)]。
作者设计了一个策略网络 π θ \pi_{\theta} πθ和一个中心化值函数网络 V ϕ ( s ) V_{\phi}(s) Vϕ(s),注意使用全局状态而不是局部状态。PPO常见Tricks:GAE with advantage normalization, observation normalization, gradient clipping, value clipping, layer normalization, ReLU activation with orthogonal initialization, and a large batch size under our 1-GPU constraint。超参网格搜索:network architecture,learning rate,entropy coefficient,the initialization scale of the final layer in the policy network.
MAPPO算法细节
MAPPO伪代码

提升PPO性能的5个关键
除了上面讲的,作者还总结提升PPO性能的5个关键:
- 值归一化
建议1:Always use PopArt value normalization - 智能体特定的全局状态
设计全局状态的两种方法:1.每个智能体的局部观测拼接,即 s = ( o 1 , … , o n ) s=\left(o_{1}, \ldots, o_{n}\right) s=(o1,…,on)。该方法会使值网络的输入维度远远高于策略网络,值网络的训练会比较难。反过来,不准确的值函数会损害策略网络学习。2.使用环境提供的全局信息。但是像SMAC环境提供全局状态包含信息比局部观测更少。因为局部观测虽然缺乏“看不见的盟友”和“敌人”的信息,但却包含了智能体特征,比如agent id、可用的动作、与所有敌人和队友的相对距离。作者认为这能解释为什么IPPO只用局部观测效果比中心控制PPO好。
作者为每个智能体设计一个全局状态,包含所有的全局信息和智能体自己的特征。对于SMAC环境,用了一个函数来计算全局状态,该状态包括所有不可见的敌人和代理信息,同时保持智能体特性。注意,特定于每个智能体的全局状态(agent-specific global state作者能不能换个词,好难翻译,就是每个智能体有一个自己的全局状态,每个智能体的全局状态是不一样的)不能在QMix中使用,因为QMix只有一个中心控制网络,因此所有智能体必须共享一个全局状态。
建议2:全局状态要包含单一智能体的特征,并且设计的时候不能使维度过高 - 训练数据使用
PPO使用重要性抽样来修正off-policy,允许样本重复使用。在采集1个batch样本后,把收集到的数据分成几个mini-batches,每个batch训练多个epochs。在连续控制问题,通常的做法是训练几十个epochs,每个epoch大约有64个mini-batches。然而,作者发现在多智能体领域,当样本被重复使用过于频繁时,MAPPO的性能下降,可能是由于环境的非平稳性造成的。因此,对容易的任务使用15个epochs,对困难的任务使用10或5个epochs。
作者发现,使用更多的数据来估计梯度可以提高实际性能;因此,在默认情况下,作者不会将训练数据拆分为mini-batches。在所有的SMAC地图中,避免使用小批量是有用的,只有一个SMAC地图将训练批量分成两个小批量可以提高性能。作者分析,在这种情况下,小批处理有助于避免的局部最优,类似于监督学习设置中观察到的现象。
建议3:避免使用过多的epochs训练,默认不要将数据拆分为mini-batches。 - 动作屏蔽
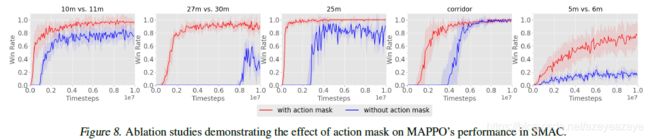
由于游戏约束,一些动作往往无法执行。因此,当计算softmax动作概率 π θ ( a i ∣ o i ) \pi_{\theta}\left(a_{i} \mid o_{i}\right) πθ(ai∣oi)的logits时,在前向和后向传递中屏蔽了不可用动作,因此不可用动作的概率总是0,这大大加速了训练。
建议4:计算动作概率时,屏蔽不可用动作。 - 死亡屏蔽
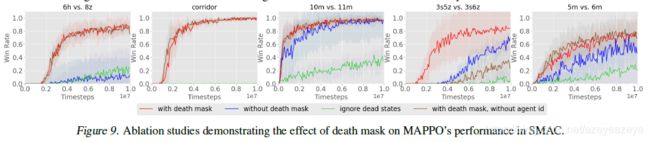
一个智能体可能在游戏结束前死亡(例如SMAC)。在价值学习过程中使用死去智能体信息状态会放大学习价值函数的偏差。因此,在GAE计算期间,智能体死亡时间步中的高值预测错误将会累积,进而阻碍在智能体仍然活着的时间步中的策略学习。作者的建议是使用一个带有代理ID的零向量,作为代理死亡后的值函数的输入。
建议5:使用带有智能体ID的零状态作为死亡智能体的值输入。
4.关键结果及结论是什么
实验环境
MPE、SMAC、Hanabi
对比算法
MADDPG、QMix和IPPO
IPPO使用本地观察作为价值输入,但其他方法遵循前面提到的所有PPO实施建议。
所有基准方法使用与MAPPO相同的超参数调优过程。我们强调,我们在这篇论文中报告的基线数字都与原始论文中相同或超过。此外,我们比较了每个领域的MAPPO和SOTA方法,即SMAC上的RODE 和Hanabi上的SAD。这两种算法的SOTA值均来自于它们的原始论文。
实验设备:256 GB RAM、1个64核CPU、1个GeForce RTX 3090 GPU的台式机。
为了计算wall-clock时间,MAPPO在MPE中运行128个并行环境,在SMAC中运行8个并行环境,而off-policy算法使用单个环境,这与原始论文中使用的实现是一致的。由于机器资源有限,我们在SMAC实验中最多使用5gb GPU内存Hanabi提供13gb GPU内存。
实证结果:在绝大多数环境中,MAPPO结果及样本复杂度,与SOTA相当或更好,大大缩短了训练时间。
本研究证明了一种基于策略的策略梯度多智能体强化学习算法MAPPO。在各种合作的多智能体挑战上,取得了与最新技术相当的强大结果。尽管其在策略上的性质,MA PPO在采样效率方面与无处不在的非策略方法(如MADDPG、QMix和RODE)竞争,甚至在时钟时间方面超过了这些算法的性能此外,在第4和第6节中,我们展示了对MAPPO的性能很重要的5种关键算法和实现技术,并通过各种消融研究来支持我们的发现,这些研究实证地证明了这些技术对MAPPO性能的影响。MAPPO获得的强有力的结果表明,适当配置的MAPPO是MARL任务的竞争性基线。基于这些结果,在未来的工作中,我们的目标是在更广泛的领域测试MAPPO的性能,如竞争游戏和具有连续行动空间的多智能体问题。
主要结论
MPE实验
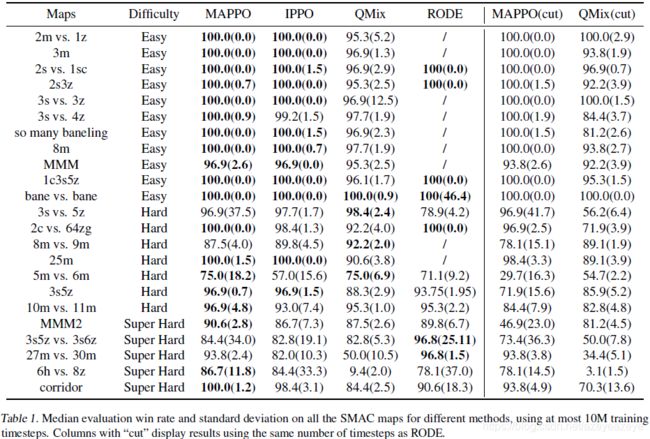
SMAC实验
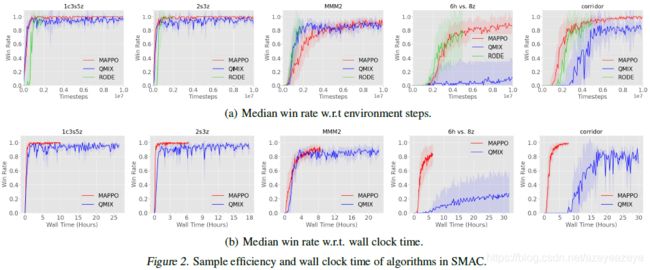
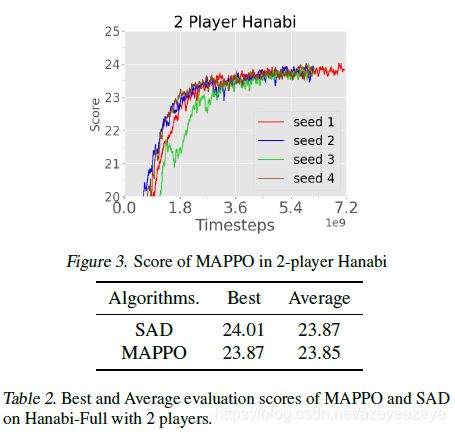
Hanabi实验
消融实验
值归一化

Agent-Specific Global State

Training Data Usage
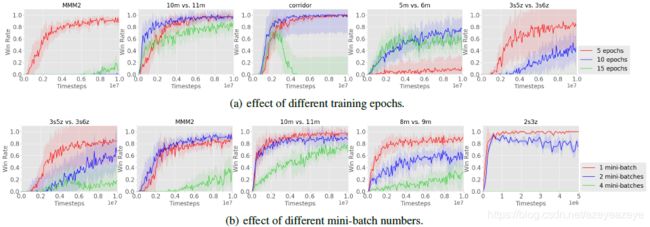

Action Masking
Death Masking
5.创新点在哪里
- 提出centralized value function的多智能体PPO算法,MAPPO(早晚会有人做,恰巧他们做了)
- 总结使得多智体PPO算法有效的5点建议(大家都在用,恰巧他们总结了)
- 重新检验了目前关于PPO的结论,并表明MAPPO能够在3个流行的MARL合作试验台上实现SOTA性能(重塑PPO在多智体强化领域的地位)。
6.有值得阅读的相关文献吗
PopArt:https://arxiv.org/pdf/1809.04474.pdf
7.综合评价又如何
本研究提出了MAPPO。在各种合作的多智能体环境上,取得了与最新技术相当的SOTA结果。在采样效率方面,MAPPO与普遍存在的非策略方法(如MADDPG、QMix和RODE)相比,甚至在wall-clock时间这些算法的性能。此外,在第4节和第6节中,我们展示了总结了对MAPPO性能很重要的5种关键算法和实现技术,并通过各种消融研究来支持我们的发现,这些研究实证地证明了这些技术对MAPPO性能的影响。
这篇文章没有创新性,但是必不可少的。因为单智体目前性能最好的算法是PPO。而多智体的IPPO效果却不好,不是PPO本身的问题,是前人单智体算法迁移到多智体的工作没有做好,MAPPO的提出是多智体强化算法发展的必经之路。
参考链接
参考
[1]: http://baijiahao.baidu.com/s?id=1693377816234538595&wfr=spider&for=pc
[2]: https://blog.csdn.net/deeprl/article/details/114529629
[3]: https://arxiv.org/pdf/1809.04474.pdf