《Redis系列》第八章:高可用之Redis Cluster集群
一、为什么要使用Redis Cluster
redis最开始使用主从模式做集群,但主从复制不能实现高可用,并且主从复制中单机的QPS可能无法满足业务需求,而且master宕机需要手动配置slave转为master;
后来为了高可用提出来哨兵模式,该模式下有一个哨兵监视master和slave,若master宕机可自动将slave转为master,但它也有一个问题,就是不能动态扩充;所以在3.x提出cluster集群模式,可以使用分布式来进行分流
并发量
Redsi官方提供的数据为10W/秒,我们不去计较它的准确性,但是实际使用中是可以完全达到上万,已经可以满足我们很大一部分的需求,但是有些业务可能需要更高的QPS,比如百万级的。
数据量
Redis是基于内存的数据库,机器的内存普遍在16~256G之间,如果我们的数据量有500G,比如个性化推荐系统,将用户相关的数据都存到Redis中。
解决方案
- 配置强悍的机器,超大内存,顶级CPU等,但是成本非常高,一台节点总归有极限。
- 分布式,添加节点
二、数据分布
2.1 为什么要做数据分布
全量数据,单机Redis节点无法满足要求,按照分区规则把数据分到若干个子集当中
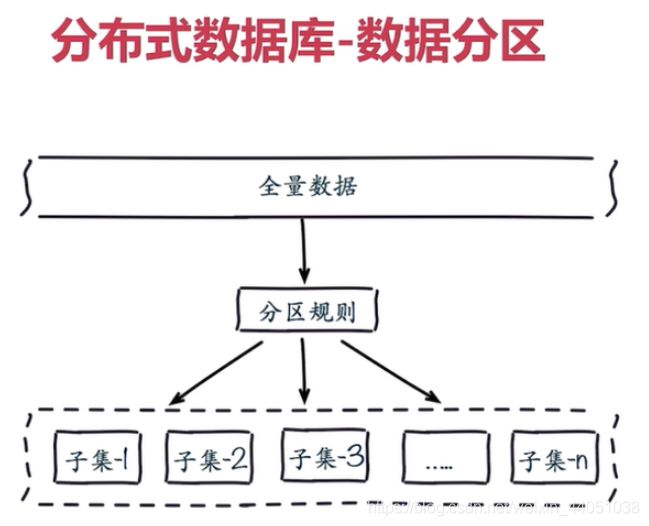
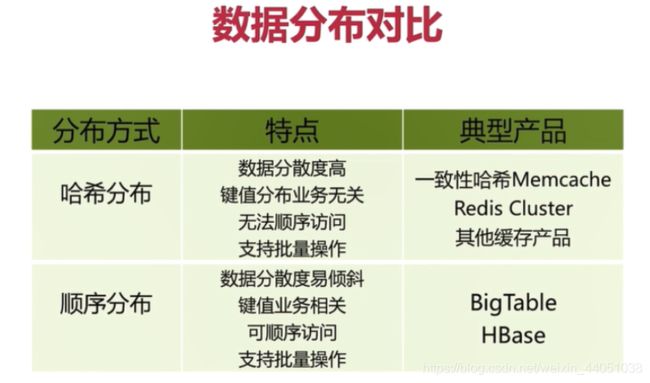
2.2 常用数据分布之顺序分布
比如:1到100个数字,要保存在3个节点上,按照顺序分区,把数据平均分配三个节点上 1号到33号数据保存到节点1上,34号到66号数据保存到节点2上,67号到100号数据保存到节点3上
顺序分区常用在关系型数据库的设计
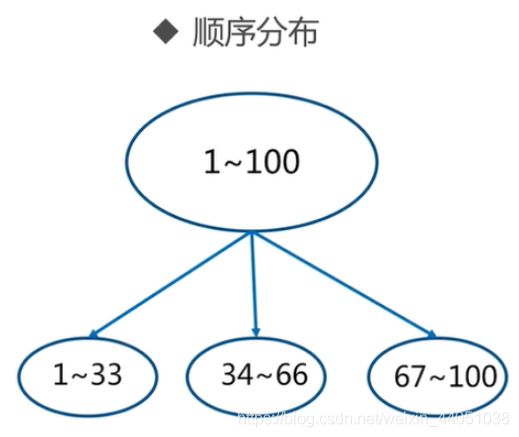
2.3 常用数据分布之哈希分布
例如1到100个数字,对每个数字进行哈希运算,然后对每个数的哈希结果除以节点数进行取余,余数为1则保存在第1个节点上,余数为2则保存在第2个节点上,余数为0则保存在第3个节点,这样可以保证数据被打散,同时保证数据分布的比较均匀
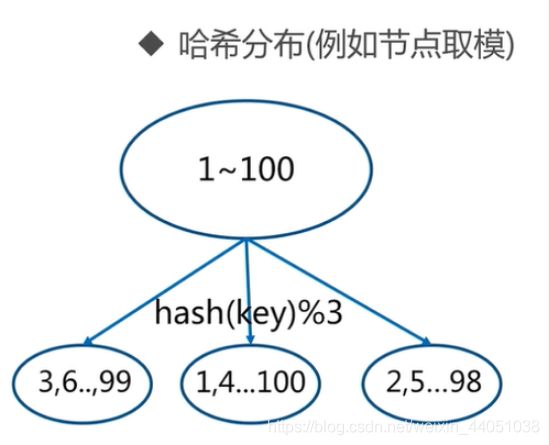
哈希分布方式又分为3个分区方式
2.3.1 哈希分布方式一: 节点取余分区
比如有100个数据,对每个数据进行hash运算之后,与节点数进行取余运算,根据余数不同保存在不同的节点上
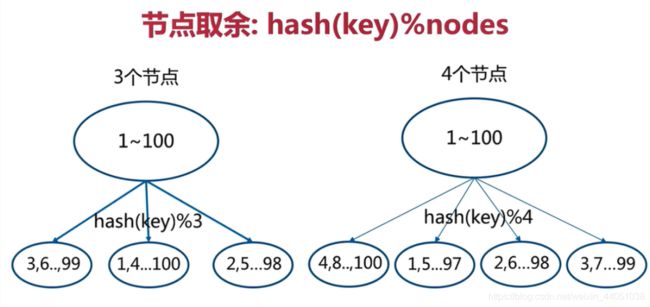
节点取余方式是非常简单的一种分区方式
节点取余分区方式有一个问题,即当增加或减少节点时,原来节点种的80%的数据会进行迁移操作,对所有数据重新进行分布
节点取余分区方式建议使用多倍扩容的方式,例如以前用3个节点保存数据,扩容为比以前多一倍的节点即6个节点来保存数据,这样只需要适移50%的数据。数据迁移之后,第一次无法从缓存中读取数据,必须先从数据库中读取数据,然后回写到缓存中,然后才能从缓存中读取迁移之后的数据
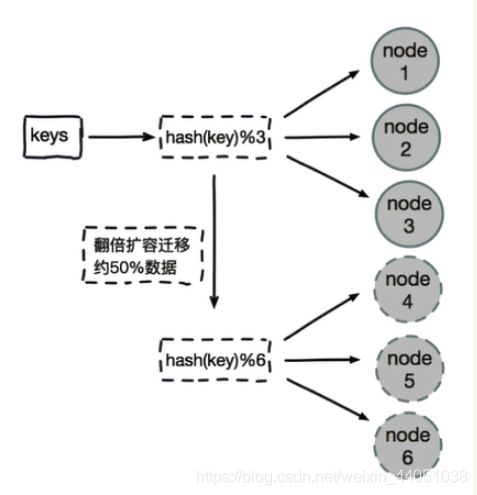
节点取余方式优点:
客户端分片
配置简单:对数据进行哈希,然后取余
节点取余方式缺点:
数据节点伸缩时,导致数据迁移
迁移数量和添加节点数据有关,建议翻倍扩容
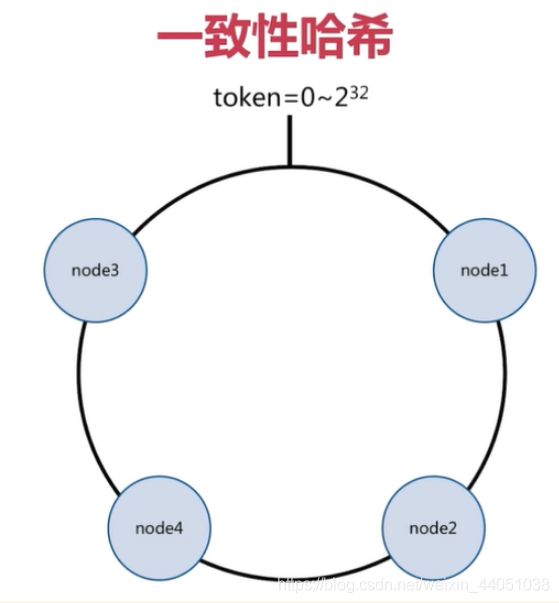
2.3.2 哈希分布方式二: 一致性哈希分区
原理:
将所有的数据当做一个token环,token环中的数据范围是0到2的32次方。然后为每一个数据节点分配一个token范围值,这个节点就负责保存这个范围内的数据。
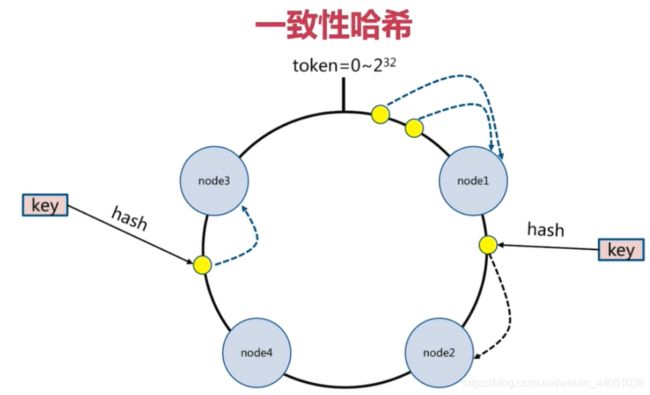
对每一个key都进行hash运算,被哈希之后的结果在哪个token的范围内,则按照顺时针去找最近的节点,这个Key将会被保存在这个节点上
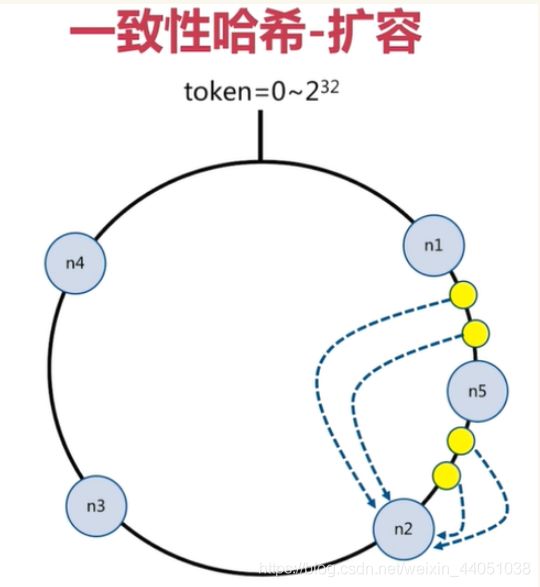
一致性哈希扩容的代价很小
在上面的图中,有4个key被hash之后的值在在n1节点和n2节点之间,按照顺时针规则,这4个key都会被保存在n2节点上, 如果在n1节点和n2节点之间添加n5节点,当下次有key被hash之后的值在n1节点和n5节点之间,这些key就会被保存在n5节点上面了 在上面的例子里,添加n5节点之后,数据迁移会在n1节点和n2节点之间进行,n3节点和n4节点不受影响,数据迁移范围被缩小很多
同理,如果有1000个节点,此时添加一个节点,受影响的节点范围最多只有千分之2 一致性哈希一般用在节点比较多的时候
一致性哈希分区优点
采用客户端分片方式:哈希 + 顺时针(优化取余)
节点伸缩时,只影响邻近节点,但是还是有数据迁移
一致性哈希分区缺点
翻倍伸缩,保证最小迁移数据和负载均衡
2.3.3 哈希分布方式三: 虚拟槽分区
虚拟槽分区是Redis Cluster采用的分区方式
预设虚拟槽,每个槽就相当于一个数字,有一定范围。每个槽映射一个数据子集,一般比节点数大
Redis Cluster中预设虚拟槽的范围为0到16383
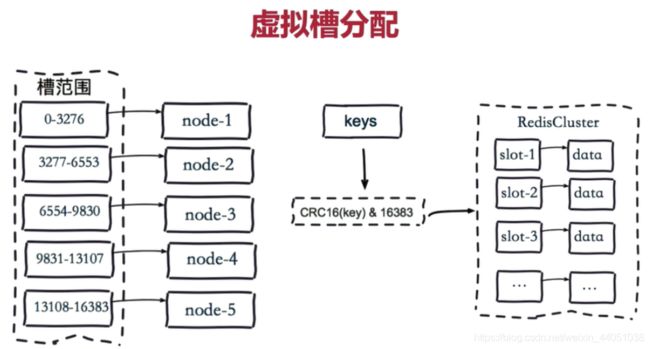
分区步骤:
1) 把16384个槽按照节点数量进行平均分配,由节点进行管理,
2) 对每个key按照CRC16规则进行hash运算
3)把hash结果对16383进行取余
4)把余数发送给Redis节点
5) 节点接收到数据,验证是否在自己管理的槽编号的范围
如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
如果不在自己管理的槽编号范围内,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
2.4 顺序分布与哈希分布的对比
三、Redis Cluster
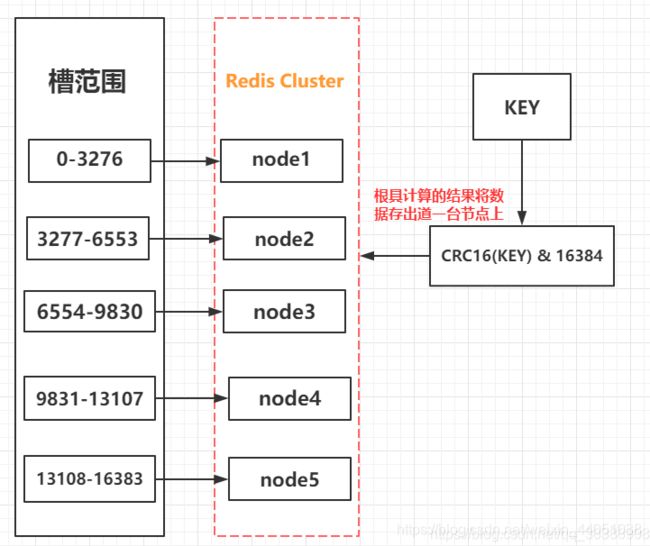
3.1 虚拟槽分区
上文我们提到了Redis Cluster是按照哈希槽进行分区,Redis内置16384个槽,从 0 ~ 16383 ,每个节点都维护一个范围的哈希槽,当有新的key需要添加时, 会使用CRC16算法并且对 16384 进行取余,公式:CRC16(key) % 16384。得到一个值,去找Redis集群中的节点,看看这个槽是哪个节点维护的,就将 key存储到哪个节点上。
3.2 节点
Redis Cluster 是分布式架构,即Redis Cluster中有多个节点,每个节点都负责进行数据读写操作
每个节点之间会进行通信
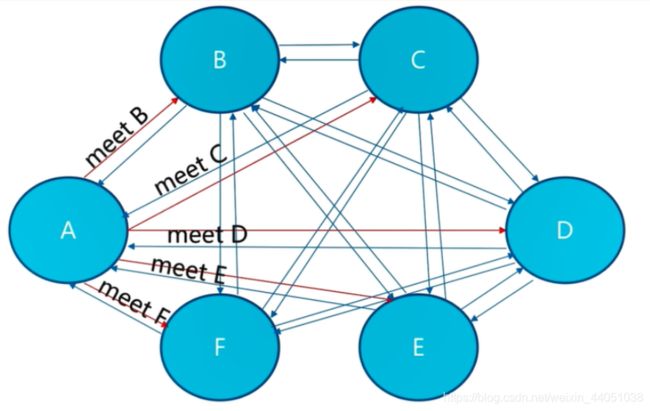
3.3 meet操作
节点之间会相互通信
命令:
redis-cli -p port cluster meet 目标节点ip 目标节点portmeet操作是节点之间完成相互通信的基础,meet操作有一定的频率和规则
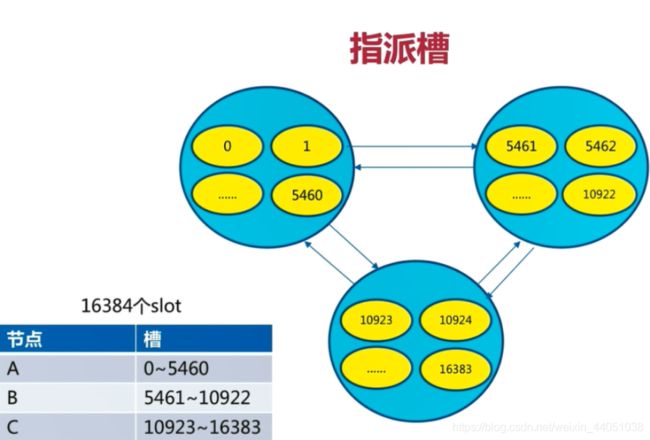
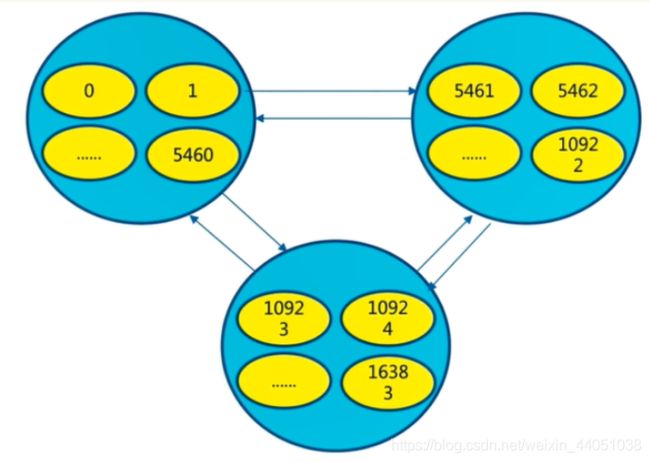
3.4 分配槽
把16384个槽平均分配给节点进行管理,每个节点只能对自己负责的槽进行读写操作
命令:
redis-cli -p port端口号 cluster addslots slot槽数由于每个节点之间都彼此通信,每个节点都知道另外节点负责管理的槽范围
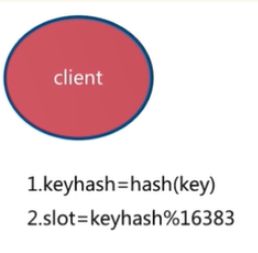
3.5 获取数据
客户端访问任意节点时,对数据key按照CRC16规则进行hash运算,然后对运算结果对16383进行取作,如果余数在当前访问的节点管理的槽范围内,则直接返回对应的数据
如果不在当前节点负责管理的槽范围内,则会告诉客户端去哪个节点获取数据,由客户端去正确的节点获取数据
四、Redis Cluster 配置和命令
4.1 配置文件
Redis Cluster是Redis官网推荐的集群方式,所以它的配置方式在redis.conf中提供了
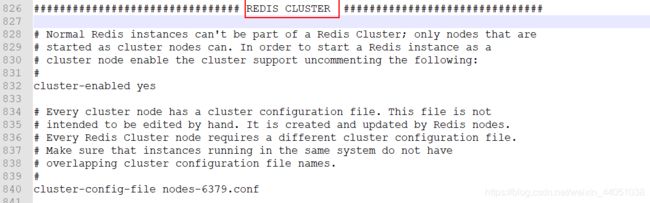
在这里提供了关于Redis Cluster的配置方式
| 配置项 | 配置 | 说明 |
|---|---|---|
| 开启Cluster | cluster-enabled yes | 默认为注释状态,如果想在特定的Redis实例中启用Redis集群支持就设置为yes。 否则,实例通常作为独立实例启动。 |
| 集群超时时间 | cluster-node-timeout 15000 | 1、节点超时多久则认为它宕机了。 2、如果主节点master超过指定的时间不可达,它将由其从属slave进行故障切换。 3、 此参数控制Redis集群中的其他重要事项。 4、每个无法在指定时间内到达大多数主节点的节点将停止接受查询。 |
| 槽是否全覆盖 | cluster-require-full-coverage no | 默认是yes,只要有结点宕机导致16384个槽没全被覆盖,整个集群就全部停止服务,所以一定要改为no。 如果将其设置为yes,则默认情况下,如果key的空间的某个百分比未被任何节点覆盖,则集群停止接受写入。 如果该选项设置为no,则即使只处理关于keys子集的请求,群集仍将提供查询。 |
| 集群配置文件 | cluster-config-file nodes-7001.conf | 1、这个配置文件不是要我们去配的,而是Redis运行时保存配置的文件,所以我们也不可以修改这个文件。 4、不同的redis节点,配置文件名字要不同 |
| 启动故障切换的时间系数 | cluster-replica-validity-factor | 1、如果设置为0,无论主节点和从节点之间的链路断开连接的时间长短,从节点都将尝试故障切换为主节点。 2、 如果该值为正值,则计算最大断开时间作为节点超时值乘以此选项提供的系数,如果该节点是从节点,则在主链路断开连接的时间超过指定的超时值时,它不会尝试启动故障切换。 例如,如果节点超时设置为5秒,并且有效因子设置为10,则与主节点断开连接超过50秒的从节点将不会尝试对其主节点进行故障切换。 3、请注意,如果没有从服务器节点能够对其进行故障转移,则任何非零值都可能导致Redis集群在主服务器出现故障后不可用。 在这种情况下,只有原始主节点重新加入集群时,集群才会返回可用。 |
| cluster-migration-barrier | 主节点将保持连接的最小从节点数量,以便另一个从节点迁移到不受任何从节点覆盖的主节点。有关更多信息,请参阅本教程中有关副本迁移的相应部分。 |
4.2 Cluster 命令
| 作用 |
命令 |
描述 |
| 集群信息 |
cluster info |
打印集群的信息 |
| 集群节点 |
cluster nodes |
打印集群当前已知的所有节点,以及这些节点的相关信息 |
| 节点添加 |
cluster meet |
将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子 |
| 节点删除 |
cluster forget |
从集权中移除node_id指定的节点 |
| 节点转移 |
cluster replicate |
将当前节点设置为node_id指定的master节点的slave节点,只能针对slave节点操作 |
| 节点保存 |
cluster saveconfig |
将节点的配置文件保存到硬盘里面 |
| 槽添加 |
cluster addslots |
将一个或多个槽(slot)之指派给当前节点 |
| 槽删除 |
cluster delslots |
移除一个或多个槽对当前节点的指派 |
| 槽清空 |
cluster flushslots |
移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点 |
| 槽转移 |
cluster setslot |
将槽指派给node_id指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽,然后在进行指派 |
| 槽 |
cluster setslot |
将本节点的槽 slot 迁移到 node_id 指定的节点中 |
| 槽 |
cluster setslot |
从 node_id 指定的节点中导入槽 slot 到本节点 |
| 槽 |
cluster setslot |
取消对槽 slot 的导入( import)或者迁移( migrate) |
| 键 |
cluster keyslot |
计算键key应该被放置在哪个槽上 |
| 键 |
cluster countkeysinslot |
返回槽slot目前包含的键值对数量 |
| 键 |
cluster getkeysinslot |
返回count个slot槽中的键 |
五、Redis Cluster集群配置和启动
5.1 步骤
1) 配置开启Redis, 这种情况每台节点都是独立的
2) 执行meet操作,让Redis集群之间感知其他节点的存在
3) 分配槽
4) 设置主从关系,我们这里一共6台节点,3主3从
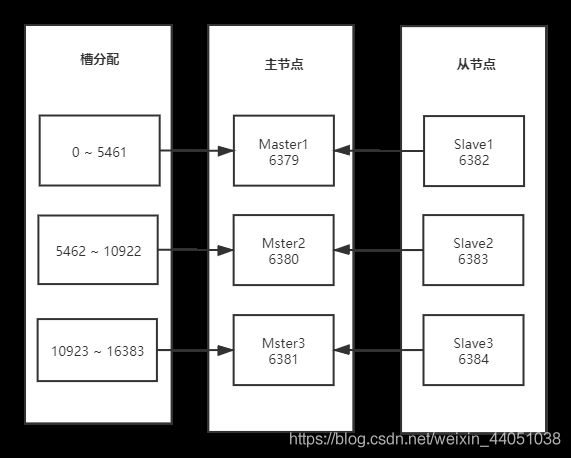
5.2 节点分配
| 序号 |
节点角色 |
IP地址 |
Port端口号 |
| 1 |
Master1 |
192.168.146.137 |
6379 |
| 2 |
Master2 |
192.168.146.137 |
6380 |
| 3 |
Master3 |
192.168.146.137 |
6381 |
| 4 |
Slave1 |
192.168.146.137 |
6382 |
| 5 |
Slave2 |
192.168.146.137 |
6383 |
| 6 |
Slave3 |
192.168.146.137 |
6384 |
5.3 redis.conf配置文件并启动
修改redis.conf配置文件,我这里只列出了一个示例,因为要启动6个节点,所以不同的节点,配置文件肯定不同,主要是端口号和日志地址不同,其它都是相同
port 6379
daemonize yes
logfile "/var/redis/logs/6379.log"
dir "/var/redis/data"
protected-mode no
dbfilename dump-6379.rdb
# 开启集群
cluster-enabled yes
# 集群运行时文件
cluster-config-file nodes-6379.conf
# 是否集群所有的节点都正常集群才可使用,改为no
cluster-require-full-coverage no启动6个Redis进程,发现端口后面都有 cluster 标记
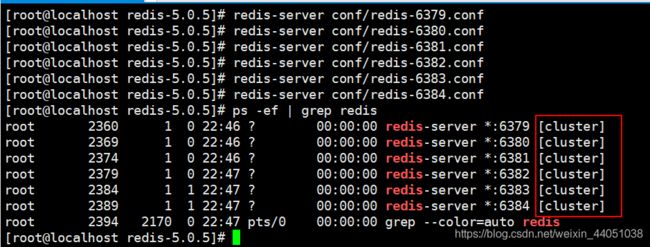
我们随便进入一个节点添加数据会发现,提示我们集群下线,没有提供哈希槽!请回头看我们的步骤。至此我们第一步和第二步就完成

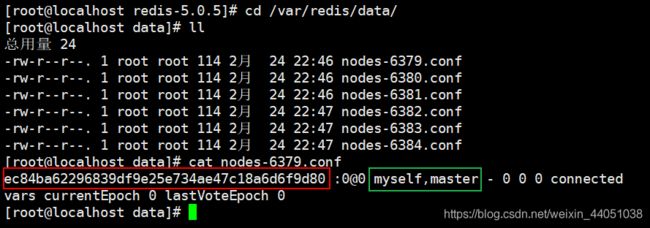
接下来我们查看 /var/redis/data 目录下发现由nodes开头的文件,这就是我们在redis.conf配置的,这个文件不需要手动修改,由Redis节点自动编辑,我们查看一下文件内容,红色下划线为当前节点的ID和自己的状态为master
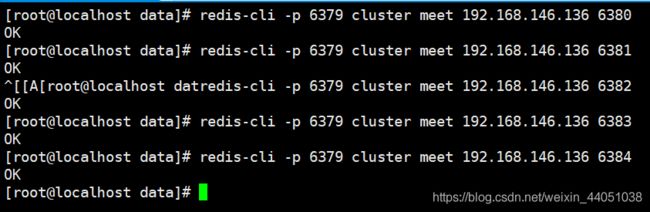
5.4 开启集群
我们通过meet 命令,将该节点与其它节点进行通信,从而达到开启集群的目的
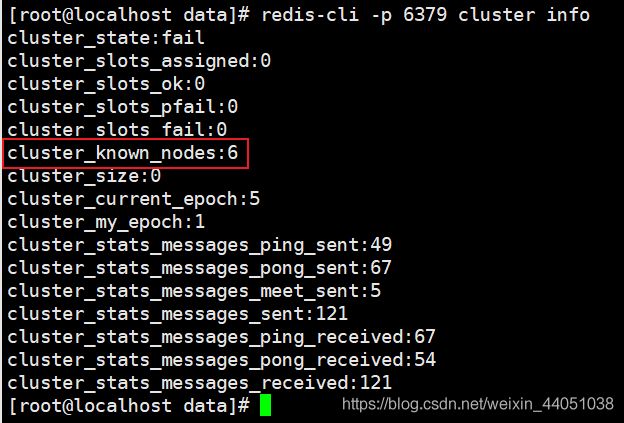
查看开启状态,通过 cluster info 命令查看发现节点个数为6个
5.5 分配槽
首先通过 cluster nodes 查看节点的状态
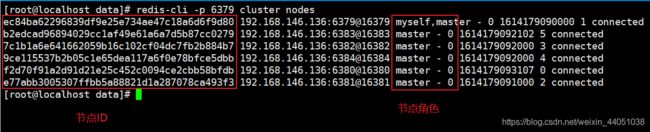
然后我们将Redis Cluster 提供的16384个槽分配给3个主节点,下图为分配图
我们通过 redis-cli -p
创建脚本文件
touch addslots.sh
分配槽脚本
start=$1
end=$2
port=$3
for slot in `seq ${start} ${end}`
do
echo "slot:${slot}"
redis-cli -p ${port} cluster addslots ${slot}
done给脚本添加执行权限
chmod u+x addslots.sh执行命令
./addslots.sh 0 5461 6379
./addslots.sh 5462 10922 6380
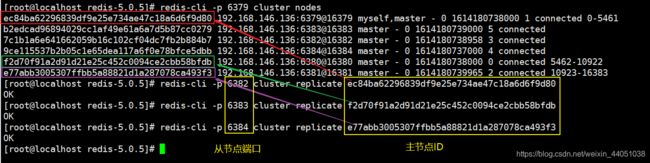
./addslots.sh 10923 16383 6381 分配成功以后,我们再次通过 cluster nodes 查看节点信息,发现槽已经分配成功了

5.6 主从分配
通过 cluster replicate
六、Redis 集群快速配置
6.1 配置文件
配置文件跟上面相同即可
6.2 启动节点
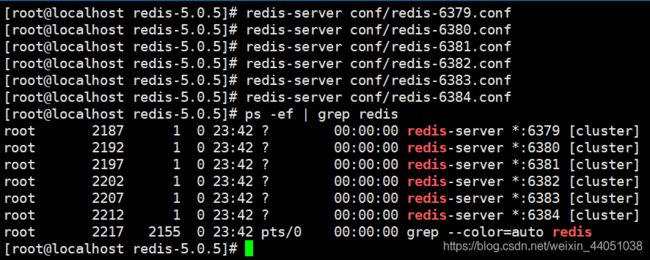
6.3 配置集群
我们通过命令一键启动,注意修改自己的IP地址和端口号
redis-cli --cluster create 192.168.146.136:6379 192.168.146.136:6380 192.168.146.136:6381 192.168.146.136:6382 192.168.146.136:6383 192.168.146.136:6384 --cluster-replicas 1过程有点长,我这里截了两张图
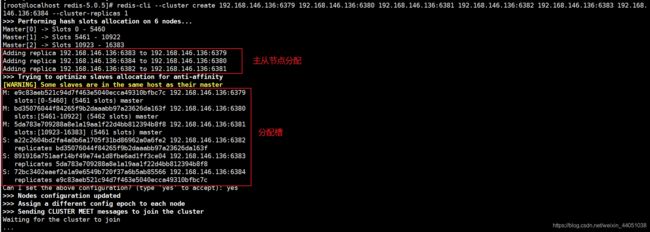
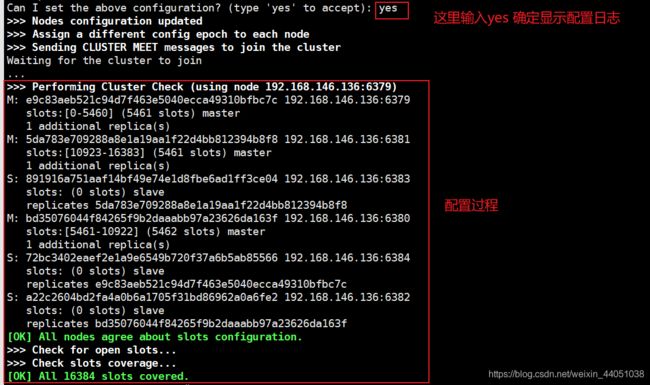
6.4 查看结果
可以看出3主3从,操作和之前都一样

七、Redis 客户端存储数据
7.1 存储数据示例
我们在以 Cluster 集群的方式启动集群的时候,需要在启动参数里面添加一个 -c 参数,代表以集群的方式启动,这样我们在登录成功以后存储数据的时候,如果当前存储的key通过CRC16计算应该归属的槽不在当前节点范围,Cluster会自动进行重定向,将数据存储到对应的节点
命令: redis-cli -c -p
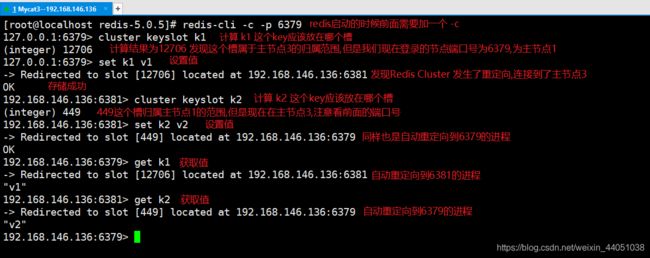
7.2 客户端路由
7.2.1 moved重定向
1.每个节点通过通信都会共享Redis Cluster中槽和集群中对应节点的关系
2.客户端向Redis Cluster的任意节点发送命令,接收命令的节点会根据CRC16规则进行hash运算与16383取余,计算自己的槽和对应节点
3.如果保存数据的槽被分配给当前节点,则去槽中执行命令,并把命令执行结果返回给客户端
4.如果保存数据的槽不在当前节点的管理范围内,则向客户端返回moved重定向异常
5.客户端接收到节点返回的结果,如果是moved异常,则从moved异常中获取目标节点的信息
6.客户端向目标节点发送命令,获取命令执行结果
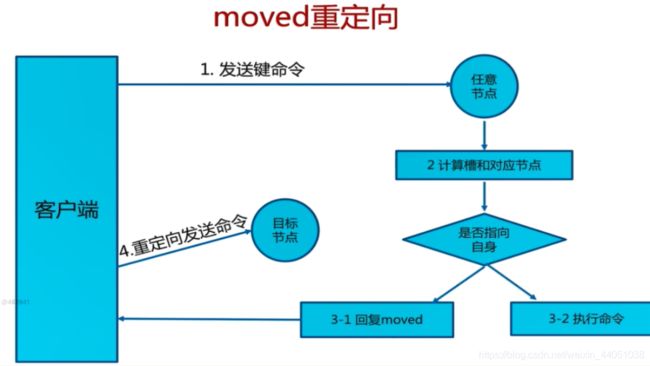
主要注意的是:客户端不会自动找到目标节点执行命令
如果槽命中,则直接返回
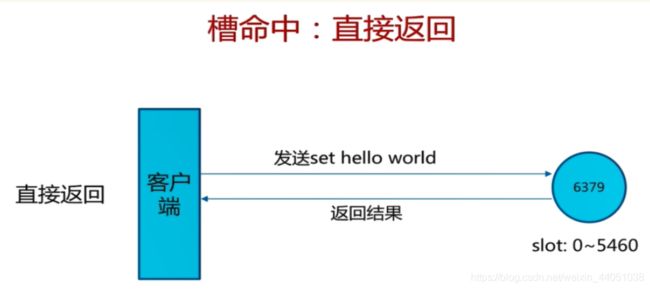
如果槽不命中:moved异常

7.2.2 ask重定向
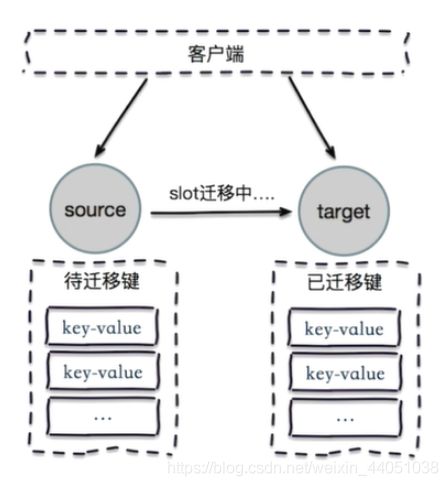
在对集群进行扩容和缩容时,需要对槽及槽中数据进行迁移
当客户端向某个节点发送命令,节点向客户端返回moved异常,告诉客户端数据对应的槽的节点信息
如果此时正在进行集群扩展或者缩空操作,当客户端向正确的节点发送命令时,槽及槽中数据已经被迁移到别的节点了,就会返回ask,这就是ask重定向机制

步骤:
1.客户端向目标节点发送命令,目标节点中的槽已经迁移支别的节点上了,此时目标节点会返回ask转向给客户端
2.客户端向新的节点发送Asking命令给新的节点,然后再次向新节点发送命令
3.新节点执行命令,把命令执行结果返回给客户端
7.2.3 moved异常与ask异常的相同点和不同点
两者都是客户端重定向
moved异常:槽已经确定迁移,即槽已经不在当前节点
ask异常:槽还在迁移中
八、Jedis-Cluster
静态方法测试
@Test
public void m1(){
// 1 创建Jedis的配置文件
JedisPoolConfig config = new JedisPoolConfig();
// 设置最大连接数,默认为8
config.setMaxTotal(1024);
// 设置最大空闲连接数,默认为8
config.setMaxIdle(100);
// 设置等待可用连接的最大时间,单位为毫秒,默认值为-1 表示永不超时
// 如果超过等待时间,则直接抛出JedisConnectionExecption
config.setMaxWaitMillis(10000);
// 在借用一个Redis连接实例的时候,是否提前进行Test(测试)操作,默认为false
// 如果为true,则代表得到的jedis都是可用的
config.setTestOnBorrow(true);
// 在jedis实例idle(空闲)时,是否进行Test(检测)
config.setTestWhileIdle(true);
config.setTestOnReturn(true);
// 2 创建Redis Cluster节点信息
HashSet jedisClusterNodes = new HashSet<>();
jedisClusterNodes.add(new HostAndPort("192.168.146.136",6379));
jedisClusterNodes.add(new HostAndPort("192.168.146.136",6380));
jedisClusterNodes.add(new HostAndPort("192.168.146.136",6381));
jedisClusterNodes.add(new HostAndPort("192.168.146.136",6382));
jedisClusterNodes.add(new HostAndPort("192.168.146.136",6383));
jedisClusterNodes.add(new HostAndPort("192.168.146.136",6384));
// 3 创建Jedis连接实例
// 参数1: cluster节点
// 参数2: connectionTimeout连接超时时间,
// 参数3: soTimeout读取数据超时
// 参数4: 密码,我这里没有设置密码
// 参数5: config 上面设置的配置文件
JedisCluster jedis = new JedisCluster(jedisClusterNodes, 1000, 1000, 5, config);
// 4 测试
// 设置数据
String res = jedis.set("k1", "v1");
// 如果设置成功,会返回ok
System.out.println(res);
// 读取数据
String v1 = jedis.get("k1");
System.out.println(v1);
Boolean res1 = jedis.exists("k1");
System.out.println(res1);//true
} 九、Redis Cluster 扩容与缩容
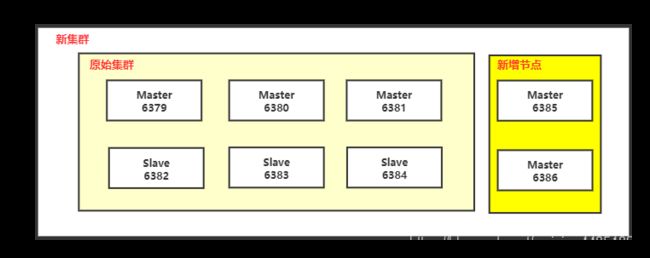
集群伸缩说白了就是在Redis中上线和下线节点,比如我们在上面测试的时候用了6台节点,如果公司业务蒸蒸日上6台节点不够用我们就需要新增节点,这个叫做集群扩容 ,如果有点凉或者高峰期过了就需要下线节点,这个叫做集群缩容。
9.1 集群扩容
原始节点
节点扩容
配置文件
配置文件和之前的相同,只需要修改端口号和文件名
port 6385
daemonize yes
logfile "/var/redis/logs/6385.log"
dir "/var/redis/data"
protected-mode no
dbfilename dump-6385.rdb
# 开启集群
cluster-enabled yes
# 集群运行时文件
cluster-config-file nodes-6385.conf
# 是否集群所有的节点都正常集群才可使用,改为no
cluster-require-full-coverage no启动节点
[root@localhost redis-5.0.5]# redis-server conf/redis-6385.conf
[root@localhost redis-5.0.5]# redis-server conf/redis-6386.conf查看节点启动状态

将新节点添加到集群中
1 使用 redis-cli --cluster help 命令查看帮助
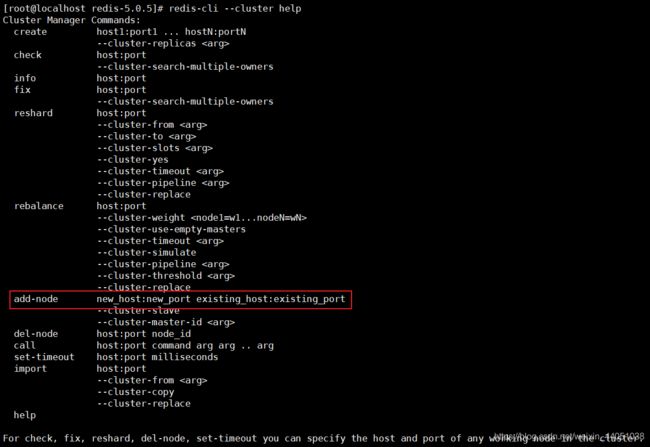
create 创建一个集群
check:检查集群状态
call 可以执行redis命令
reshard:重新分片
add-node: 将一个节点添加到集群里,第一个参数为新节点的ip:port,第二个参数为集群中任意一个已经存在的节点的ip:port
del-node:移除一个节点
help 帮助
2 使用 add-node 参数添加节点
[root@localhost redis-5.0.5]# redis-cli --cluster add-node 192.168.146.136:6385 192.168.146.136:6379
[root@localhost redis-5.0.5]# redis-cli --cluster add-node 192.168.146.136:6386 192.168.146.136:6379我添加的时候遇到了错误
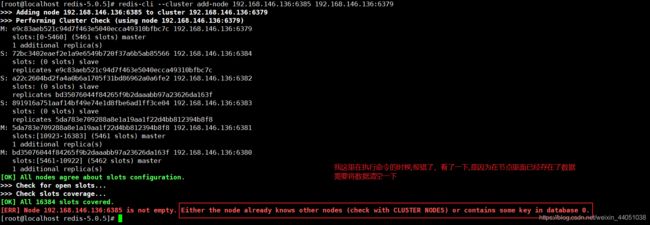
正确添加
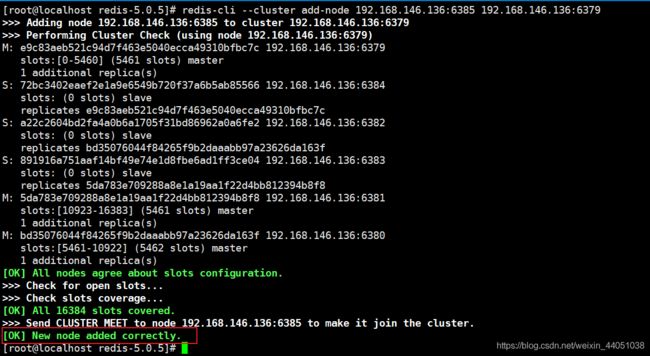
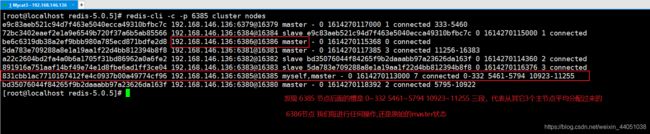
查看节点状态

给新节点分配槽
通过以下命令分配槽
IP和port需要分出槽的节点,从这个节点取出槽分配到新节点
redis-cli --cluster reshard : 执行过程
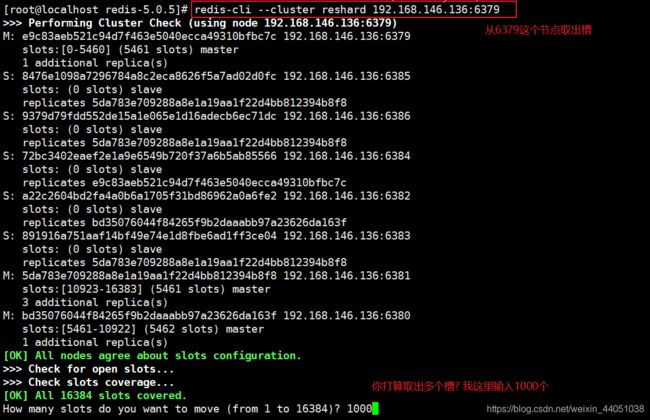
中间在执行的时候,过程会挨条执行命令,例如转移1000个槽,就会执行1000条命令,所以没有截图成功,所以这里采用了文字的样式
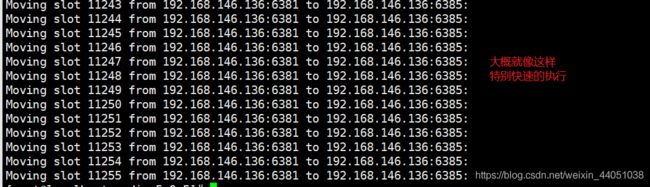
| How many slots do you want to move (from 1 to 16384)? 1000 输入all为从所有主节点中分别抽取相应的槽数指定到新节点中,抽取的总槽数为1000个;也就是平均抽 或者输入原节点ID然后输入done,意思将输入的节点ID,抽取的总槽数为1000个,就是只从1个节点上取1000个槽分配到新节点 我这里输入的是all。 |
查看新的节点状态
配置主从状态
将 6386 节点配置为 6385 节点的从节点,命令在上面可以查到,执行完成之后,发现 6386节点变成了 slave 
打完收工
9.2 集群缩容
下线 6386 从节点
下线节点,我们使用上面的查看到的 del-node 命令(可以通过 redis-cli --cluster help 查看到)
del-node host:port node_id
查看集群状态

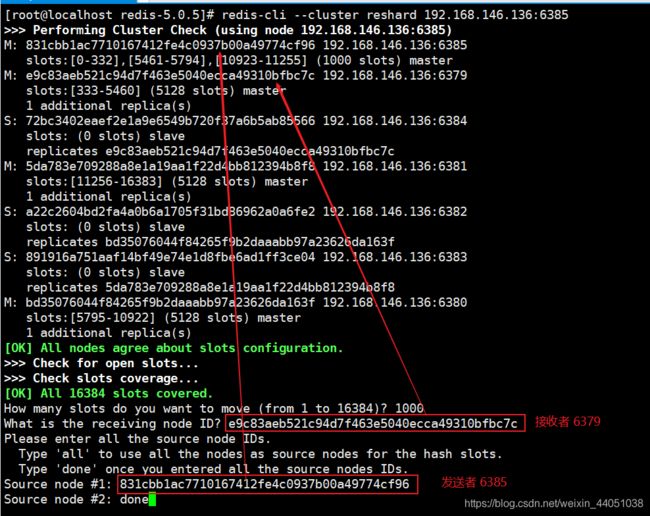
下线 6385 主节点
这个稍微有点麻烦,因为主节点上有数据槽,需要归还槽,然后在执行下线操作,否则就有可能造成数据丢失,这也是里边的小细节需要大家牢记!
执行:redis-cli --cluster reshard 192.168.146.136:6386
归还槽
然后就是走执行命令的流程了
查看集群状态

6385主节点下线

查看集群状态
