python字符串和切片操作
python字符串和切片操作
- 1.去掉字符串中所有的空格
- 2. 获取字符串中汉字的个数
- 3.将字母全部转换为大写和小写
- 4.根据标点符号对字符串进行分行
- 5. 去掉字符串数组中每个字符串的空格(循环)
- 6.随意输入心中想到的一个书名,然后输出它的字符串长度(len属性)
- 7.用户输入一个日期格式如‘’2021/03/28“,将输入的日期转换为”2021年-3月-28日“
- 8.接收用户输入的字符串,将其中的字符进行排序,并以逆序输出。
- 9.. 用户输入一句英文,将其中的单词以反序输出
- 10. 用户输入一句话,找出所有”呵“的位置
- 11.有个字符串数组,存储了10个书名,书名有长有短,现在将他们统一处理,若长度大于10,则截取长度为8的子串,将统一处理后的结果输出
- 12.用户输入一句话,找出所有”呵呵“的位置
- 13.如何判断一个字符串是否是另一个字符串的子串
- 14.如何验证一个字符串中的每一个字符均在另一个字符串中出现
- 15.如何生成无数字的全字母的字符串
- 16.如何随机生成带数字和字母的字符串
- 17.如何判定一个字符串中既有数字又有字母
- 18.python中不可变对象有哪些?
- 19.判断一个数是否是回文数字
- 20. L = [‘Adam’, ‘Lisa’, ‘Bart’, ‘Paul’]取前三个元素
- 21. range()函数可以创建一个数列:range(1, 101)
- 22.利用倒序切片对 1 - 100 的数列取出:最后10个数;最后10个5的倍数
- 23. 请设计一个函数,它接受一个字符串,然后返回一个仅首字母变成大写的字符串(切片upper())
- 24.利用切片操作,实现一个trim()函数,去除字符串首尾的空格,注意不要调用str的strip()方法
- 25.从键盘上输入自己或同学的身份证号,从中取出出生年份、月份、日期以及性别信息
1.去掉字符串中所有的空格
我们可以适用replace(m,n)方法来实现去掉字符串中的所以的空格
下面是代码实现
// 将字符串中所有的空格删除
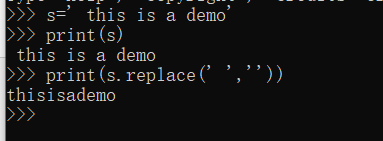
s=' This is a demo '
print(s.replace(' ',''))
运行结果如下图所示
2. 获取字符串中汉字的个数
首先要获取汉字的话我们要了解Unicode里的字符编码,
\u0020 空格
\u0040 ~ \u005A 大写字母A~Z
\u0061 ~ \u007A 小写字母a~z
\u4E00 ~ \u9FFF 中文字符
\u0030 ~ \u0039 数字
了解了这些字符编码后我们就可以用isalpha()函数来判断字符串中的汉字个数了。
下面是代码实现
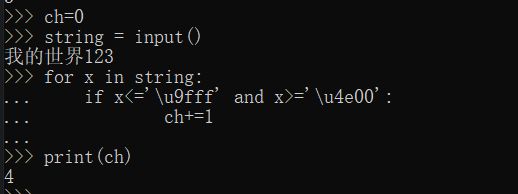
ch=0;
string = input()
for x in string:
if x <='\u9fff' and x>='u4e00':
ch+=1
print(ch)
运行结果如下图所示
3.将字母全部转换为大写和小写
将字母转换大小写我们可以用swapcase()函数来实现
下面是代码实现
str = "This Is String Example....Wow!!!"
print (str.swapcase())
运行结果如下图所示

4.根据标点符号对字符串进行分行
根据标点符号分割我们可以用split()函数
split() 默认是以空格进行分割,如果在其中添加 逗号,如: split(’,’) 则是以逗号进行分割
下面是代码实现
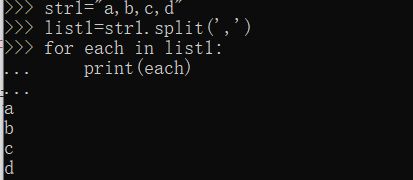
str1='a,b,c,d'
list1=str1.split(',')
//因为split()分割出来的是一个list类型,
//所以用一个list来装
for each in list1:
print(each)
以下是运行结果
5. 去掉字符串数组中每个字符串的空格(循环)
代码如下
ls=[" hh 12 "," 卧底 是谁 " ,"A you ok"]
ls1=[]
for i in range(0,len(ls)):
ls1.append(ls[i].replace(" ",""))
print(ls1)
运行结果如下

6.随意输入心中想到的一个书名,然后输出它的字符串长度(len属性)
代码实现
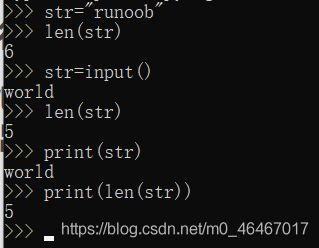
str=input()
print(len(str))
运行结果
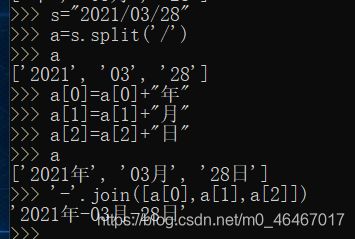
7.用户输入一个日期格式如‘’2021/03/28“,将输入的日期转换为”2021年-3月-28日“
代码如下
s="2021/03/28"
a=s.split('/')
a[0]=a[0]+"年"
a[1]=a[1]+"月"
a[2]=a[2]+"日"
'-'.join([a[0],a[1],a[2]])
运行结果如下
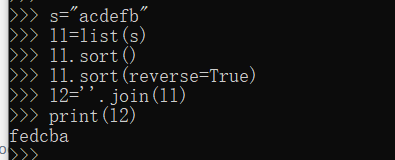
8.接收用户输入的字符串,将其中的字符进行排序,并以逆序输出。
例如:acdefb - abcdef-fedcba
由于python里没有字符数组这个概念,但我们可以用列表来存储我们的字符串并用列表里的sort函数来实现排序。
代码如下
s="acdefb"
ll=list(s)//将字符串存入列表中
ll.sort()
ll.sort(reverse=True)
//缺省为升序排序,通过reverse = True参数实现降序排列,
l2=''.join(ll)
//把列表中的元素放在空串中
print(l2)
运行结果如下
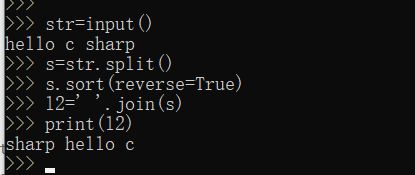
9… 用户输入一句英文,将其中的单词以反序输出
例如:hello c sharp — sharp c hello
代码如下
str=input()
s=str.split()//以空格来分开字符串
s.sort(reverse=True)//缺省为升序排序,通过reverse = True参数实现降序排列,
l2=' '.join(s)//把列表中的元素放在空串中,元素间用空格隔开
print(l2)
运行结果如下
10. 用户输入一句话,找出所有”呵“的位置
这题可以先建立一个空列表,然后再遍历字符串
如果找到"呵"就给空列表添加i的值。
代码如下
s = input("请输入一段话!")
ls = []
for i in range(0,len(s)):
if s[i] == "呵":
ls.append(i)
print("呵的位置是:{}".format(ls))
运行结果如下

11.有个字符串数组,存储了10个书名,书名有长有短,现在将他们统一处理,若长度大于10,则截取长度为8的子串,将统一处理后的结果输出
代码如下
ls = ["我的世界冲冲冲啊冲啊啊","遥远的老天爷","红尘往市不在回首嘿嘿黑","活着","白鹿原之青青草原112"] //10个书名太多了,我只存了几个
for i in range(0,len(ls)):
s=ls[i]
if(len(s)>10):
s=s[0:9]
ls=[i]=s
print(ls)
运行结果如下

12.用户输入一句话,找出所有”呵呵“的位置
这题直接在第十题的基础上加一个判断条件就好了
代码如下
s = input("请输入一段话!")
ls = []
for i in range(0,len(s)-1):
if s[i] == "呵"and s[i+1] =="呵":
ls.append(i)
print("呵的位置是:{}".format(ls))
运行结果如下
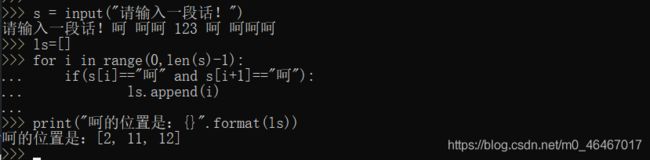
13.如何判断一个字符串是否是另一个字符串的子串
代码如下
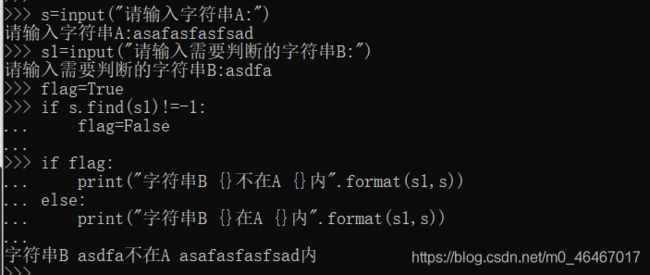
s = input("请输入字符串A:")
s1 = input("请输入需要判断的字符串B:")
flag = True
if s.find(s1) != -1:
flag = False
if flag:
print("字符串B {}不在A {}内".format(s1,s))
else:
print("字符串B {}在A {}内".format(s1,s))
运行结果如下
14.如何验证一个字符串中的每一个字符均在另一个字符串中出现
这题在上一题的基础上加一个循环判断每一个元素就好了
代码如下
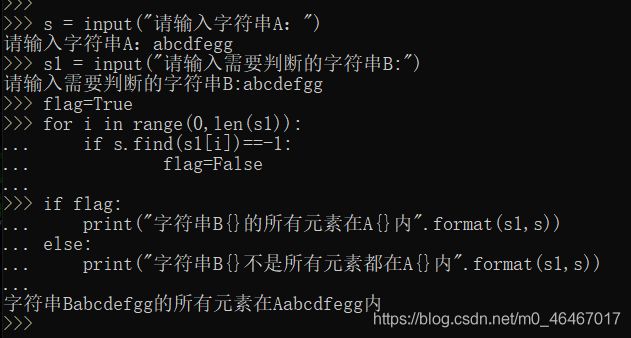
s = input("请输入字符串A:")
s1 = input("请输入需要判断的字符串B:")
flag = True
for i in range(0,len(s1)):
if s.find(s1[i]) == -1:
flag = False
if flag:
print("字符串B{}的所有元素在A{}内".format(s1,s))
else:
print("字符串B{}不是所有元素都在A{}内".format(s1,s))
运行结果如下
15.如何生成无数字的全字母的字符串
代码如下
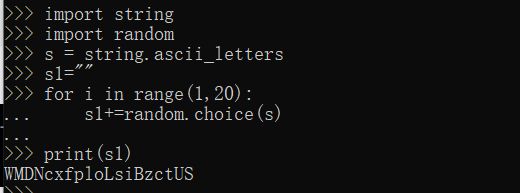
import string
import random
s = string.ascii_letters
//前为生成字母,后为生成数字
s1 = ""
for i in range(1,20):
s1 += random.choice(s)
print(s1)
运行结果如下
16.如何随机生成带数字和字母的字符串
代码如下
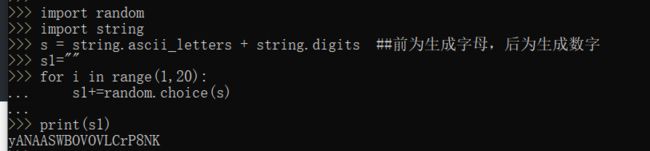
import string
import random
s = string.ascii_letters + string.digits
//前为生成字母,后为生成数字
s1 = ""
for i in range(1,20):
s1 += random.choice(s)
print(s1)
运行结果如下
17.如何判定一个字符串中既有数字又有字母
代码如下
import string
s = input("输入需要判断的字符串:")
if (s.isalnum()and not s.isalpha()) and not s.isdigit():
print("字符串{}里包含数字和字母".format(s))
else:
print("字符串{}里并不是既包含字母又包含数字".format(s))
运行结果如下

18.python中不可变对象有哪些?
在Python中,数值(整型,浮点型),布尔型,字符串,元组属于值类型,本身不允许被修改(不可变类型),数值的修改实际上是让变量指向了一个新的对象(新创建的对象),所以不会发生共享内存问题。 这种方式同Java的不可变对象(String)实现方式相同。
a = 1
b = a
a = 2
print(b) //输出的结果是1 修改值类型的值,只是让它指向一个新的内存地址,并不会改变变量b的值。
19.判断一个数是否是回文数字
这题我们可以利用pyhton中的切片操作来判断
代码如下
n=input()
m=n[::-1]//将n倒序
if(n==m):
print("yes")
else:
print("no")
运行结果如下

20. L = [‘Adam’, ‘Lisa’, ‘Bart’, ‘Paul’]取前三个元素
代码如下
L = ["Adam", "Lisa", "Bart", "Paul"]
n=L[0:3]
print(n)
运行结果如下

21. range()函数可以创建一个数列:range(1, 101)
[1, 2, 3, …, 100]
请利用切片,取出:
- 前10个数;
- 3的倍数;
- 不大于50的5的倍数。
代码如下
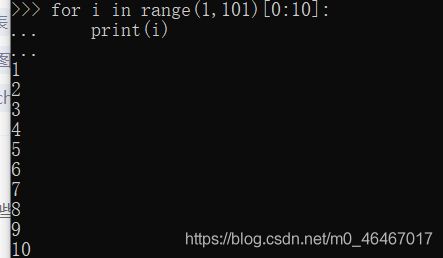
for i in range(1,101)[0:10]:
//前10个数
print(i)
for i in range(1,101)[2::3]:
//3的倍数
print(i)
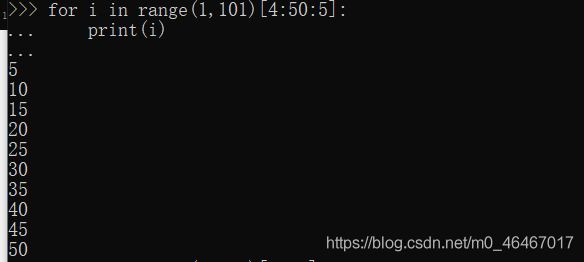
for i in range(1,101)[4:50:5]:
//不大于50的5的倍数
print(i)
运行结果如下

22.利用倒序切片对 1 - 100 的数列取出:最后10个数;最后10个5的倍数
代码如下
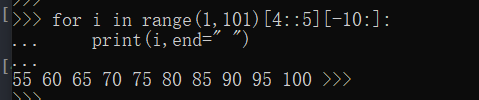
for i in range(1,101)[-10:]:
//最后10个数
print(i,end=" ")
for i in range(1,101)[4::5][-10:]:
//最后10个5的倍数
print(i,end=" ")
运行结果如下

23. 请设计一个函数,它接受一个字符串,然后返回一个仅首字母变成大写的字符串(切片upper())
代码如下
def firstCharUpper(s):
y=s.lower()
y=y[0:1].upper()+y[1:]
return y
print firstCharUpper(('hello'))
print firstCharUpper(('sunday'))
print firstCharUpper(('september'))
运行结果如下

24.利用切片操作,实现一个trim()函数,去除字符串首尾的空格,注意不要调用str的strip()方法
代码如下
def Trim(s):
while s[:1]==' ':
s=s[1:]
while s[-1:]==' ':
s=s[:-1]
return s
x=" hello "
print(Trim(x))
运行结果如下
![]()
25.从键盘上输入自己或同学的身份证号,从中取出出生年份、月份、日期以及性别信息
代码如下
a=input("请输入您的身份证号:")
year=a[6:10]
month=a[10:12]
day=a[12:14]
sex=a[16:17]
sex=int(sex)
if sex % 2:
sex='男'
else:
sex='女'
print("您是%s年%s月%s日出生的%s孩."%(year,month,day,sex))
运行结果如下
