Linux运维基础知识——开发人员可以掌握的常识
文章目录
- 一、Linux磁盘管理
-
- 1.磁盘管理命令
- 2.磁盘分区命令
- 3.SWAP 交换分区
- 二、shell脚本入门
-
- 1.Bash基础
- 2.条件判断、循环
- 3.常用命令
- 三、Linux日志管理简单介绍
- 四、文本处理三剑客
-
- 1.简介
- 2.awk基础
- 3.grep基础
- 4.sed基础
- 五、ftp文件共享
-
- 1.基础命令
- 2.samba资源共享
- 六、防火墙
-
- 1.iptables 基础
- 2.firewalld 基础
- 七、内核入门
-
- 1.简介
- 2.内核管理
- 3.内核优化
- 八、数据同步rsync
- 附:参考
一、Linux磁盘管理
1.磁盘管理命令
- 打开root权限:
sudo -i
- 磁盘管理命令:
使用 df 命令可以查看文件系统类型,空间大小,使用情况以及磁盘上可使用的磁盘空间。
几个重要参数:
-a: 显示全部的文件系统
-h: 以可读性较高的方式显示,采用KB,MB,GB,作为单位
-t: 显示文件系统的类型
-k: 将输出的空间大小缩小2^10倍,即将默认显示单位调整为MB
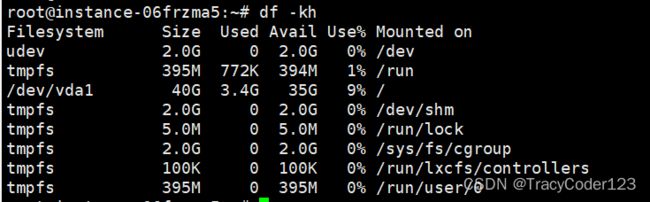
我们用以下命令来查看文件系统的信息:
df -kh
输出清单的第一列显示的是文件系统以及路径,第二列显示的是分区包含的数据的大小,用 -h 参数以 M 为单位显示会更符合我们的阅读习惯,第三列和第四列则分别显示已用以及可用的空间大小,同时,我们可以在最后一列中看出该文件系统的挂载点:
- 另外,我们还可以执行以下命令来查看当前文件夹下的信息:
du -h
2.磁盘分区命令
- 显示分区信息:
fdisk -l

可以看到,这个分区只有一个40GB的vda分区。
- 进入分区交互界面:
fdisk /dev/vda
- 使用p命令查看分区表:
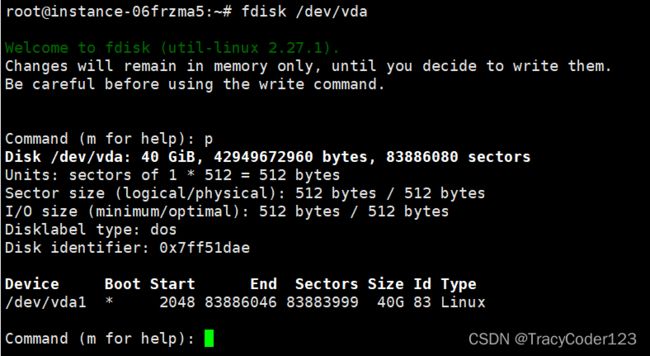
另外,在此交互界面还有以下命令可使用:
n:创建新分区
d:删除已有分区
t:修改分区类型
l:查看所有已经ID
w:保存并退出
q:不保存并退出
m:查看帮助信息
p:显示现有分区信息
- 如果在 fdisk 命令中修改了分区,还需要通过 Partprobe 命令让内核重新识别分区 /proc/partitions:
partprobe
3.SWAP 交换分区
在 Linux 系统中,Swap 分区是用来模拟内存的,简单的来说,就是当内存不太够的时候,将调用 SWAP 分区。这跟 Windows 系统的虚拟内存很像。两者的技术原理都是将磁盘当作内存条来读写,但是我们知道磁盘的读写速度要比内存条慢很多,所以 SWAP 分区只是一种替代手段,并不能达到实际内存的效果。
- 查看目前的内存以及 SWAP 分区大小:
free -m

Swap 分区设置为如下大小最合适:
内存 推荐分区大小
<2GB 内存的两倍
2GB-8GB 与内存一样大
8GB-64GB 最少 4GB
>64GB 最少 4GB
事实上,Swap 分区并不是越多越好,在性能越好的设备上,Swap 分区设置的越少。因为当内存足够多的时候,磁盘的读写速度反而会成为累赘。例如可能会出现内存还剩下很多,系统却在使用 Swap 分区的情况。
- 可以通过以下命令来修改swap配置,优化swap:
vi /etc/sysctl.conf
# 添加如下配置:
# vm.swapiness :60 改成 10
# vm.dirty_ratio:90 改成 10
# vm.dirty_background_ratio:60 改成 5
# vm.dirty_expire_centisecs:3000 改成500
# vm.vfs_cache_pressure:100 改成 500
解释:
vm.swapiness,swapiness 表示系统有多积极的使用 Swap 分区,取值从 0 到 100,当值为 0的时候,表示首先使用物理内存,其次 Swap 分区。
vm.dirty_ratio这里规定了当写缓存达到了系统内存的多少的时候,开始向磁盘写出数据。也就是说我们的缓存数据积累的足够多的,这时候不得不开始清理缓存。
vm.dirty_background_ratio该参数与 dirty_ratio 类似,但是区别在于,dirty_ratio规定的是缓存达到多少,我们开始阻塞进程并且写入到磁盘,但是 dirty_background_ratio规定的是缓存达到多少,我们开始写入到磁盘。
vm.dirty_expire_centises这个参数声明 Linux内核中写缓存超时了之后,我们就开始写入到磁盘中,默认情况下,我们设置为 3000,这里的单位是 1/100s,所以缓存只能存在最多 30s。
vm.vfs_cache_pressure它设置了 Swap 分区回收 VFS 缓存的倾向,在vfs_cache_pressure=100 的默认值下,内核将尝试以相对于页面缓存的“公平”速率回收 dentry 和 inode交换缓存回收。
二、shell脚本入门
Linux Shell 是一个比 Windows 强大的多的交互式命令系统,允许用户执行对文件的 CURD 操作以及对系统做出的修改。
Shell是用来用户和内核交互的程序,它提供一个与用户对话的环境,这个环境被称之为 CLI(Command Line Interface,命令行界面),我们能够在 CLI 中输入命令让系统执行。
目前使用较为广泛的 Shell 类型:
Bourne Shell
Cshell
Korn
Bash(Linux 系统上最流行的 Shell 版本)
- 查看当前操作系统安装的所有 Shell:
cat /etc/shells
在 Linux 系统中,Bash 文件是以 .sh 为后缀名的可执行文件,类似于 Windows 下面的 .bat 文件。通常情况下,编写 Bash 的工具使用 Vim 写好代码后即可直接运行。一个 Bash 文件就是一个 Bash 程序。
1.Bash基础
- 创建hello.sh程序:
vim hello.sh
- 在其中插入以下内容:
先按i然后回车,进入插入模式。第一行的注释用于声明这是一个使用Bash的程序,第二行是程序的内容。
#!/bin/bash
echo Hello World
插入后按Esc,再键入英文小写冒号,后面写wq,然后回车。
- 运行程序:
./hello.sh
遇到了权限不够的问题:

- 通过chmod增加权限:
chmod +x ./hello.sh
再次运行,成功!

2.条件判断、循环
- if语法:
#! /bin/bash
var="Linux"
if var==Linux
then
echo "match"
else
echo "do not match"
fi
- for循环:
#!/bin/bash
cd /
mkdir test_dir
cd test_dir
for ((counter=0; counter<5; counter++)) # 另一种写法for counter in 0,1,2,3,4
do
touch test_$counter.txt
done
- while循环写法:
#!/bin/bash
cd /
mkdir test_dir2
cd test_dir2
counter=0
while (($counter<5))
do
let "counter++"
touch test_$counter.txt
done
无限循环:
while :
# 或者
while true
3.常用命令
- shopt命令:
shopt 内置命令用于设置和取消设置 shell 选项。
直接使用 shopt 命令可以查看各项参数以及他们的开闭状态:
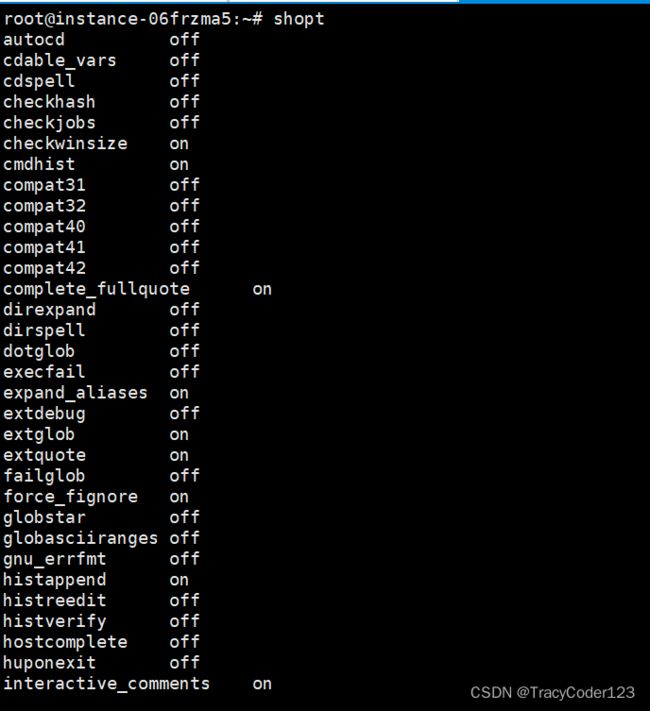
如果要查找某项特定的参数,我们也可以在 shopt 后面接上参数名。
- readonly 命令:
通过 read only 命令,我们可以将变量等等内容的属性编辑为只读,无法做出任何修改。
var_read=1
readonly var_read
var_read=2
- trap 命令:
trap 命令可以在我们执行脚本的时候与用户进行交互,对于我们书写交互式代码非常有帮助。我们可以使用 -l 参数来查看所有的系统信号:
trap -l

trap 'rm -f "$test"' EXIT
脚本遇到 EXIT 信号时,就会执行 rm -f “$test”。
三、Linux日志管理简单介绍
rsyslog 是实现日志管理的一个工具。
几乎所有的系统日志都存储在 /var/log 目录下面,我们通过ll命令查看目录下的所有内容:
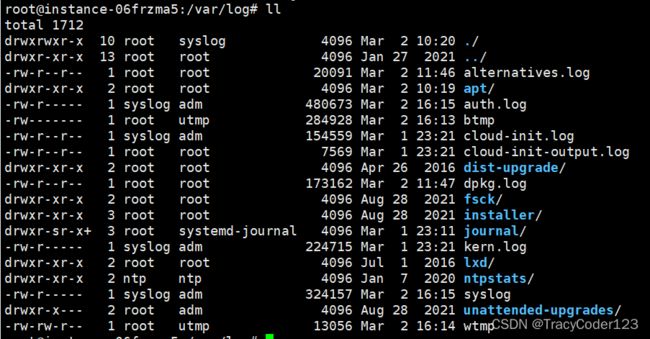
几个比较重要的日志文件:
/var/log/cron
/var/log/cups/
/var/log/dmesg
/var/log/secure
/var/log/btmp
/var/log/lastlog
/var/log/message
首先是 cron,你可能用到过 cron 来设置定时任务,它记录了和定时任务相关的日志。cups 文件则记录了打印信息的日志,而 dmesg 记录了开机时候内核自检的文件。此外,还有 btmp 以及 lastlog 文件,这两个文件是二进制的形式,我们不能直接打开,前者要用 lastb 命令来查看,后者要用 lastlog 命令来查看。
lastb 命令输出的是尝试登陆但失败的日志,如果你某一次忘记输入密码,那么你这一次登录的行为可能就被 btmp 文件记录了下来。lastlog 能够列出系统当中所有的用户,包括端口以及 IP。
具体怎么操作日志请自行学习。
四、文本处理三剑客
1.简介
linux文本处理三剑客:awk,grep 和 sed。他们功能不仅强大,而且和彼此相互配合,实现复杂的文本处理功能。
- awk:
awk 的功能和正则表达式有些类似,都是基于模式匹配,并且 awk 完美支持正则表达式。更重要的一点是 awk 支持函数以及类 C 语言的流程控制。它的操作逻辑是会依次处理文本文件的每一行。因此,awk 最适合处理像 CSV 之类的文本文件。
- grep:
grep 也是一种强大的文本搜索工具,最常用使用的例子是与 Linux 下面的各种命令结合,例如我们经常用到的查看进程的命令:
ps -ef | grep xx
查看grep工具可以使用的参数:
grep --help
- sed:
sed 主要是利用脚本来处理文本文件,通常情况下可以通过脚本来大规模的处理大量文件。
2.awk基础
- 基本语法格式:
awk [命令] [操作对象]
- 生成awk文件:
echo 'this is a test!' > awk.txt
其中内容为this is a test!
- 输出文件的文本内容:
awk '{print $0}' awk.txt
{print $0}为要执行的命令,print 为打印,$0 代表的是当前行,因此执行上面的命令,就会把内容原样打印出来。
默认情况下,awk 中的分隔符为空格和制表符,如果想要指定其他符号为分隔符,也可以使用-F 参数来说明。分割后的第一部分用1 来表示,第二部分则用1来表示,第二部分则用2 表示,以此类推。

3.grep基础
- 语法格式:
grep [命令] [操作对象]
简单示例:
grep -i This awk.txt
忽略大小写匹配awk.txt文本中的This。
- 常用参数:
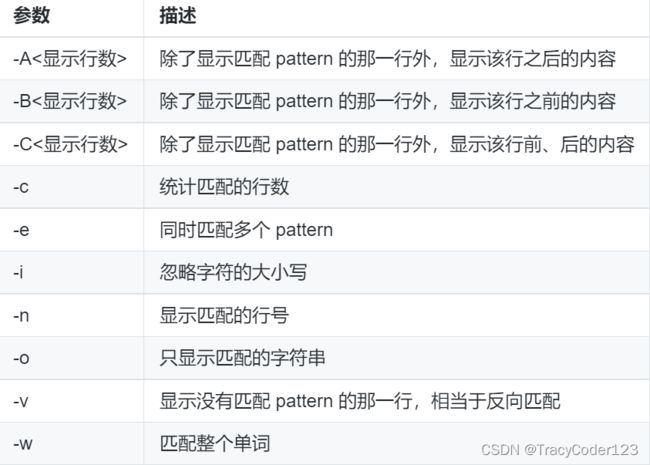
4.sed基础
- 基本语法:
sed [命令] [操作对象]
- 替换并打印:
sed -n 's/this/This/p' awk.txt
-n表示只显示匹配处理的行,s表示搜索后替换,this表示匹配的内容,This表示替换的内容,p表示替换后打印。
- 写入数据:
sed 's/this/This/' awk.txt > awk1.txt
- 删除:
sed 's/this//' awk.txt > awk2.txt
- 添加:
sed '/this/ a "The line after this line"' awk.txt > awk3.txt
sed '/this/ i "The line before this line"' awk.txt > awk4.txt
a 参数表示我们要将文本加到匹配行之后,i 参数表示我们要将文本加到匹配行之前。
五、ftp文件共享
1.基础命令
- 使用apt命令安装ftp服务器:
sudo apt update
sudo apt install vsftpd
- 设置 vsftp 每次开机启动:
systemctl enable vsftpd
- 启动vsftp:
systemctl start vsftpd
- 查看 ftp 服务器端口号:
netstat -antup | grep ftp
- 关闭防火墙对ftp默认端口20和21的限制:
sudo apt-get install ufw
sudo ufw allow 20/tcp
sudo ufw allow 21/tcp
2.samba资源共享
- 安装samba:
sudo apt update
sudo apt install samba
- 设置一个文件夹来供 samba 进行共享:
mkdir sambashare
- 告诉配置文件我们新设置的这个目录是 samba 的共享目录:
sudo vi /etc/samba/smb.conf
并添加如下内容:
[sambashare]
comment = Samba on Ubuntu
path = /usr/local/sambashare
read only = no
browsable = yes
- 重启samba:
/etc/init.d/samba restart
- 打开防火墙允许 samba 流量通过:
sudo ufw allow samba
- 设置一个 samba 的共享账号:
//先在系统中新增专门用来使用samba的用户sambauser
adduser sambauser
//然后将此用户添加为samba的用户
sudo smbpasswd -a sambauser
- 给文件夹赋予权限:
sudo chmod 777 /usr/local/sambashare
- windows访问服务器共享文件夹:
\\ip-address\sambashare
我的系统是win11,访问不了,可能和网络设置有关,至今还未解决。
六、防火墙
防火墙配置了一系列规则来规范流量,允许接受或者发送来自某个端口乃至协议的数据包。比如我们常说的,开放 80 端口,开放 443 端口之类的话语,这就是对防火墙进行配置。iptables 和 firewall 是我们常用的管理防火墙规则的工具。两者都是管理工具,都是对底层流量模块 netfilter 的封装。
1.iptables 基础
iptables 是 Linux 上一个强大且易用的防火墙工具,它不仅可以实现黑名单,白名单控制流量,端口开闭而且可以实现流量转发等等复杂的命令。需要注意的是,在 iptables 上可以设置针对流量的多条规则,这些规则甚至有可能互相违。在 iptables 表中位置越靠上的规则权重越高,权重高的规则可以抵消权重低的规则。
关于iptables这位老哥的博客将来龙去脉讲得很清楚了:https://www.zsythink.net/archives/1199,感兴趣的可以了解一下。
2.firewalld 基础
firewalld 也是对 Linux 内部模块 netfilter 模块的封装的另一种防火墙管理工具,它的最大的特点是简约,不需要像 iptables 一样了解很多命令。
- 查看版本号:
firewalld -v
- 安装命令:
sudo apt-get install firewalld
- 启动:
# 开机自启
systemctl enable firewalld
# 启动
systemctl start firewalld
- 配置文件:
# 在/usr/lib/firewalld/zones/目录下面,每个文件对应一个工作区
block.xml、dmz.xml、drop.xml、external.xml、 home.xml、internal.xml、public.xml、trusted.xml、work.xml
如果我们在使用 firewalld 的时候,不使用参数指定是哪个工作区,那么我们的操作将会默认对于 public 生效。
- 添加可访问端口:
firewall-cmd --permanent --add-port=80/tcp
firewall-cmd --permanent --add-port=443/tcp
- 添加smtp:
firewall-cmd --add-service=smtp
- 移除smtp:
firewall-cmd --add-service=smtp
- 端口转发:
firewall-cmd --add-forward-port=port=80:proto=tcp:toport=8080
- 允许防火墙伪装IP:
firewall-cmd --add-masquerade
- 禁止防火墙伪装IP:
firewall-cmd --remove-masquerade
七、内核入门
1.简介
Linux 系统采用经典的冯诺依曼架构,内核的作用是连接软件和硬件并且充当底层驱动。内核是操作系统的核心,一个内核的好坏直接决定了系统运行的效率以及稳定性。
内核的功能:
充当软件和硬件之间的中间件
管理系统的进程,内存,驱动以及文件
提供了一系列面向操作系统的命令
在应用开发的过程中抽象了相关细节
内核中提供了一系列基本的功能,例如时钟功能,进程调度功能,它就像在编写代码的时候引入的库文件,程序会调用库中的函数,而软件则会调用内核中实现的基本函数。
- 查看 CPU 的型号以及物理 ID:
cat /proc/cpuinfo | grep "model name" && cat /proc/cpuinfo | grep "physical id"
- 查看机器的内存信息:
cat /proc/meminfo | grep MemTotal
- 查看内核信息:
uname -a
- 查看内核版本:
head -n 1 /etc/issue
2.内核管理
- 进入内核伪目录:
cd /proc/sys
- 查看目录下的所有文件夹:
我们需要修改的只有 net 目录下面的内容,其他目录要么和硬件相关,要么和 Linux 系统的架构有关。
- 临时性修改:
# 设置 tcp_tw_recycle 的值为 0
echo "1" > /proc/sys/net/ipv4/tcp_fastopen
- 永久性修改:
查看当前系统生效的所有参数:
sysctl -a
直接修改配置文件:
vi /etc/sysctl.conf
3.内核优化
- 以下这些设置告诉 Linux 内核不接收或发送 ICMP 重定向数据包。攻击者可以使用这些 ICMP 重定向来修改路由表。所以禁用它听起来很合理(设置为零/假/0):
net.ipv4.conf.all.accept_redirects = 0
net.ipv4.conf.all.secure_redirects = 0
net.ipv4.conf.all.send_redirects = 0
- 以下设置了 TCP 连接的最大套接字的值,当达到此阈值时,孤立连接会立即丢弃并发出警告。此阈值仅有助于防止简单的 DoS 攻击。最好不要降低阈值(而是增加以满足系统要求——例如,在增加内存之后):
参数 tcp_fin_timeout 决定我们的 tcp 连接在多久之后关闭连接,fin 是 tcp 连接中用于确认对方收到消息的消息,如果我们不设置 timeout 的话,我们的服务器可能会一直保持 tcp 连接,这会占用我们的服务器资源。后面几条关于 keepalive 的则设置了关于断开连接的内容。
net.ipv4.tcp_max_orphans = 65536
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_keepalive_time = 1800
net.ipv4.tcp_keepalive_intvl = 15
net.ipv4.tcp_keepalive_probes = 5
- 以下设置了服务器保存在内存中允许的最大连接数,以及数据传输确认失败以后最多的确认信号重传次数:
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.tcp_synack_retries = 1
- retries 确定了重传次数,当我们的服务器荷载较高的时候,减少重传次数能够有效的降低资源占用:
net.ipv4.tcp_orphan_retries = 0
- 这些选项使得我们的服务器不会被虚假的 IP 地址欺骗:
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.lo.rp_filter = 1
net.ipv4.conf.eth0.rp_filter = 1
net.ipv4.conf.default.rp_filter = 1
- 重启使配置生效:
/sbin/sysctl -p
八、数据同步rsync
作为一个增量备份的工具,rsync 在 Linux 中得到了广泛的应用,最终能够实现两机的文件同步。rsync 在同步过程中主要有两部分组成:第一部分是对需要同步的文件的检查,第二部分是文件同步模式的确定。默认情况下,会使用 quick check 模式进行检查。
- 安装rsync:
sudo apt install rsync
- 查看版本:
rsync -h
- 可用参数:

- 基本语法:
rsync -a [source] [destination]
举例:
# 把rsyncfile文件夹备份至/tmp目录下去,tmp下会出现一个叫rsyncfile的文件夹
rsync -a /opt/rsyncfile /tmp
也可以指定不同的命名:
rsync -a /opt/backup.zip /tmp/newbackup.zip
同步目录:
sudo rsync -a /home /opt/home
- 远程同步语法:
把本机的home目录同步至远程机器的backup目录:
rsync -a /home [remote_user]@[remote_host]:/opt/backup
把远程机器的backup目录同步至本地的home目录:
rsync -a [remote_user]@[remote_host]:/opt/backup /home
附:参考
https://www.lanqiao.cn/courses/4838