【机器学习基础】数学推导+纯Python实现机器学习算法28:CRF条件随机场
Python机器学习算法实现
Author:louwill
Machine Learning Lab
本文我们来看一下条件随机场(Conditional Random Field,CRF)模型。作为概率图模型的经典代表之一,CRF理解起来并不容易。究其缘由,还是在于CRF模型过于抽象,大量的概率公式放在一起时常让人犯晕。还有就是即使理解了公式,很多朋友也迷惑CRF具体用在什么地方。
所以在本文的开头,我们先具体化一个应用场景,明确一下CRF的用途。就拿笔者来举例:假设现在有笔者从早到晚的一系列照片,现在我们想根据这些照片对笔者日常活动进行分类,比如说吃饭、上班、学习等等。要达到这个目的我们可以训练一个图像分类模型来对图片所对应的活动进行分类。在训练数据足够的情况下,我们是可以达到这个分类目的的。但这种方法一个最大的缺陷在于忽略了笔者这些照片之间是存在时序关系的,如果能确定某一张照片的前一张或者后一张的活动状态,那对于我们做分类工作大有帮助。而CRF模型就是一种能够考虑相邻时序信息的模型。比如说词性标注就是CRF最常用的一个场景之一。另外在早期深度学习语义分割模型中,CRF也被作为的一种后处理技术来优化神经网络的分割结果。
概率无向图
概率图模型是一种用图来表示概率分布的模型。而概率无向图模型(Probabilistic Undirected Graphical Model)也叫马尔可夫随机场(Markov Random Field),是一种用无向图来表示联合概率分布。
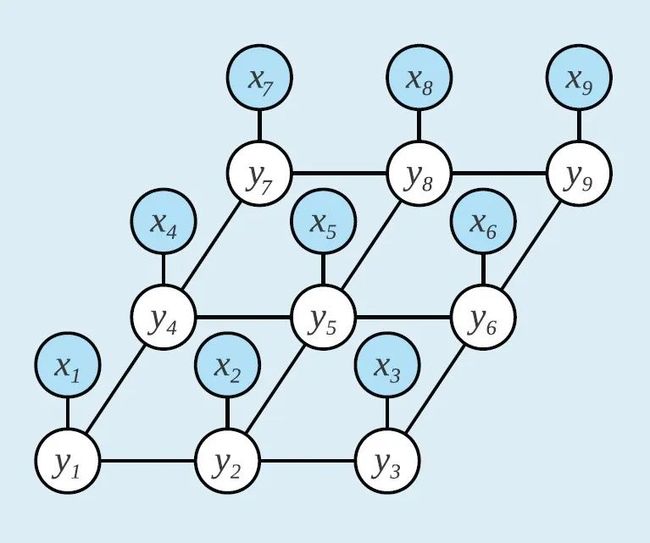
假设有联合概率分布 ,由无向图 表示,其中图的结点表示随机变量,边表示为随机变量之间的依赖关系。如果联合概率分布 满足成对、局部或者全局马尔可夫性,则该联合概率分布为概率无向图模型。所谓马尔可夫性,即在给定一组随机变量的条件下,另外两个随机变量之间的条件独立性。
无向图 中任何两个结点均有边连接的结点子集称为团,若 为 的一个团,且不能再加进任何一个结点使其成为更大的团,则 称为 的最大团。基于最大团,概率无向图模型的联合概率分布 可写作图中所有最大团 上的函数 的乘积形式:
其中 为规范化因子:
花一点篇幅说一下概率无向图,主要在于CRF是一种概率无向图模型。所以它满足概率无向图的一些特征,包括上述最大团函数乘积条件。
CRF详解
CRF定义
CRF就是在给定随机变量 的条件下,随机变量 的马尔可夫随机场。假设 和 为随机变量, 是给定 的条件下 的条件概率分布。并且当该条件概率分布 能够构成一个由无向图 表示的马尔可夫随机场,即:
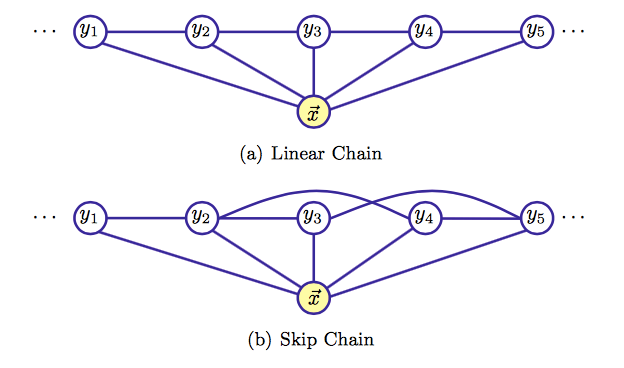
其中 表示在图中与结点 有边连接的所有结点 , 表示结点 以外的所有结点。从CRF的定义我们大致能够明白它就是一个满足马尔可夫随机场的条件概率分布,我们以线性链CRF为例来看其参数化表达方法。
CRF参数化表达
假设 为线性CRF,在随机变量 取值为 的条件下,随机变量 取值为 的条件概率具备如下形式:
其中:
上式中 和 为特征函数, 和 为对应的权值, 为规范化因子,求和是在所有可能的输出序列上进行的。为了加深对上述式子的理解,我们以一个例子来说明:假设我们要进行一个词性标注任务,那么上式中 就是输入的整个句子, 为当前位置, 和 为当前位置和前一位置的标签,以上四项作为特征函数的输入。其中 为转移特征函数, 为状态特征函数。当满足特征条件时特征函数取值为1,不满足时取值为0。
线性CRF的三个问题
线性CRF需要解决三个核心问题,包括基于前向-后向的概率估计算法、基于极大似然和牛顿优化的学习算法以及基于维特比算法的预测算法。
前向-后向算法
所谓CRF的概率估计算法,即给定条件概率分布 和输入输出序列 和 时,计算条件概率 和 以及对应的期望。
要计算条件概率 和 ,我们可以使用前向-后向算法。先看前向计算过程。定义 表示当序列位置 的标记为 时,在位置 之前的部分标记序列的非规范化概率,下式定义了给定 下从 转移到 的非规范化概率:
相应的可以得到序列位置 的标记为 时,在位置 之前的部分标记序列的非规范化概率 的递推公式:
在序列起点处定义:
假设可能标记的总数为 ,则 的取值有 个,用 表示这 个值组成的前向向量如下:
用矩阵 表示由 构成的 阶矩阵:
最后的递推公式可以由矩阵表达为:
同理可定义后向计算过程,即定义 为序列位置 的标记 时,在位置 之后的部分标记序列的非规范化概率 的递推公式:
在序列终点处定义:
其向量化表达为: ,而规范化因子 为:
最后 的向量表达为:
。
按照前向-后向算法,我们可计算标记序列在位置 是标记 的条件概率和在位置 与 是标记 和 的条件概率:
CRF模型学习算法
线性CRF是如何训练的呢?在给定训练数据集 和对应标记序列 以及 个特征函数 ,需要学习的包括模型参数 和条件概率 ,且条件概率 和模型参数 满足如下关系:
这个式子是不是有点眼熟?其实就是softmax表达式。当训练得到模型参数 之后,我们就可以根据上式计算出条件概率 。
线性CRF的学习模型实际上是定义在时序数据上的对数线形模型,其学习方法包括极大似然估计和正则化的极大似然估计方法。模型优化算法包括梯度下降法、牛顿法、拟牛顿法以及迭代尺度法等。具体的优化算法求解这里略过。
CRF模型预测算法
CRF的预测问题是给定条件随机场 和输入序列 ,求条件概率最大的输出序列 ,即要对观测序列进行标注。CRF使用维特比(Viterbi)算法进行标注预测。
我们先看一下维特比算法的输入输出和基本流程。维特比算法的输入是模型的特征向量 和权值向量 以及观测序列 ,输出为最优路径 。其算法流程如下:
初始化
递推。对于 ,有:
终止:,
返回路径:
按照上述维特比算法可球的最优路径 。
可以看到维特比算法本质上是一种求最优路径的动态规划算法,但上述流程理解起来过于抽象,是否有更加具体的方式来理解呢。
假设我们要在下述有向图中找出一条从 到 的最短路径。最简单粗暴的方法莫过于遍历所有路径然后比较一条最短的,但这么做时间复杂度太高。而维特比算法就是一种可以高效寻找最优路径的算法。
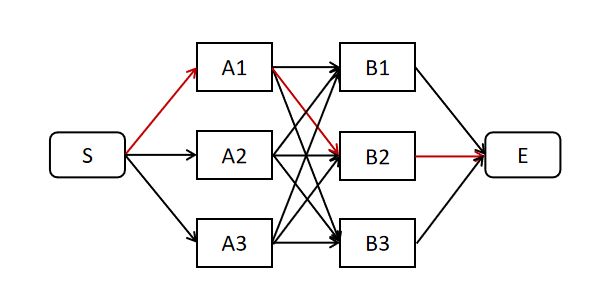
我们将该图从左至右来看。先看起点 到第一列的可能路径有三种: 、 、 。仅从第一列我们尚不能确定某一段就是最终最优路径中的某一段,所以我们接着看 列。经过 的所有路径有三条: 、 、 ,比较这三个路径,选择一个最短的,因为其他两条不再可能是最优路径,我们可以将其他两条路径删掉。假设这里我们保留的 是最短路径。同理我们再对 和 进行路径比较,假设经过 和 保留下来的最短路径分别为 和 。最后我们到达终点 点,将上述三条路径链接 点后分别比较 、 和 ,假设 路径最短,那么它就是最优路径。从这个过程我们可以体会到维特比算法是一个典型的动态规划算法。
CRF实现
实现一个完整的CRF模型包括权重初始化、参数化表达、概率得分计算以及维特比解码算法等模块。完整的CRF实现参考:
https://github.com/lancifollia/crf/blob/master/crf.py
下面给出维特比算法的一个参考实现代码。
import numpy as np
def viterbi(y, A, B, Pi=None):
"""
Return the MAP estimate of state trajectory of Hidden Markov Model.
Parameters
----------
y : array (T,)
Observation state sequence. int dtype.
A : array (K, K)
State transition matrix. See HiddenMarkovModel.state_transition for
details.
B : array (K, M)
Emission matrix. See HiddenMarkovModel.emission for details.
Pi: optional, (K,)
Initial state probabilities: Pi[i] is the probability x[0] == i. If
None, uniform initial distribution is assumed (Pi[:] == 1/K).
Returns
-------
x : array (T,)
Maximum a posteriori probability estimate of hidden state trajectory,
conditioned on observation sequence y under the model parameters A, B,
Pi.
T1: array (K, T)
the probability of the most likely path so far
T2: array (K, T)
the x_j-1 of the most likely path so far
"""
# Cardinality of the state space
K = A.shape[0]
# Initialize the priors with default (uniform dist) if not given by caller
Pi = Pi if Pi is not None else np.full(K, 1 / K)
T = len(y)
T1 = np.empty((K, T), 'd')
T2 = np.empty((K, T), 'B')
# Initilaize the tracking tables from first observation
T1[:, 0] = Pi * B[:, y[0]]
T2[:, 0] = 0
# Iterate throught the observations updating the tracking tables
for i in range(1, T):
T1[:, i] = np.max(T1[:, i - 1] * A.T * B[np.newaxis, :, y[i]].T, 1)
T2[:, i] = np.argmax(T1[:, i - 1] * A.T, 1)
# Build the output, optimal model trajectory
x = np.empty(T, 'B')
x[-1] = np.argmax(T1[:, T - 1])
for i in reversed(range(1, T)):
x[i - 1] = T2[x[i], i]
return x, T1, T2
参考资料:
李航 统计学习方法 第二版
https://www.zhihu.com/question/20136144/answer/763021768
https://stackoverflow.com/questions/9729968/python-implementation-of-viterbi-algorithm/9730083
https://github.com/lancifollia/crf/blob/master/crf.py
往期精彩:
数学推导+纯Python实现机器学习算法27:EM算法
数学推导+纯Python实现机器学习算法26:随机森林
数学推导+纯Python实现机器学习算法25:CatBoost
数学推导+纯Python实现机器学习算法24:LightGBM
数学推导+纯Python实现机器学习算法23:kmeans聚类
数学推导+纯Python实现机器学习算法22:最大熵模型
数学推导+纯Python实现机器学习算法21:马尔科夫链蒙特卡洛
数学推导+纯Python实现机器学习算法20:LDA线性判别分析
数学推导+纯Python实现机器学习算法19:PCA降维
数学推导+纯Python实现机器学习算法18:奇异值分解SVD
数学推导+纯Python实现机器学习算法17:XGBoost
数学推导+纯Python实现机器学习算法16:Adaboost
数学推导+纯Python实现机器学习算法15:GBDT
数学推导+纯Python实现机器学习算法14:Ridge岭回归
数学推导+纯Python实现机器学习算法13:Lasso回归
数学推导+纯Python实现机器学习算法12:贝叶斯网络
数学推导+纯Python实现机器学习算法11:朴素贝叶斯
数学推导+纯Python实现机器学习算法10:线性不可分支持向量机
数学推导+纯Python实现机器学习算法8-9:线性可分支持向量机和线性支持向量机
数学推导+纯Python实现机器学习算法7:神经网络
数学推导+纯Python实现机器学习算法6:感知机
数学推导+纯Python实现机器学习算法5:决策树之CART算法
数学推导+纯Python实现机器学习算法4:决策树之ID3算法
数学推导+纯Python实现机器学习算法3:k近邻
数学推导+纯Python实现机器学习算法2:逻辑回归
数学推导+纯Python实现机器学习算法1:线性回归

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑获取一折本站知识星球优惠券,复制链接直接打开:https://t.zsxq.com/yFQV7am本站qq群1003271085。加入微信群请扫码进群: